消息队列入门 —— 以 Kafka 为例(一)
概述
当我们的应用逐步变得庞大,各层应用之间调用关系越来越复杂,对系统的可用性以及可扩展性要求也越来越高。消息队列作为分布式系统架构中的一个关键中间件,提供了“消息传递”和“消息排队模型”,可以应用在系统解耦、异步处理、流量削峰等多个场景,有着举足轻重的地位。
流行消息队列目前有 Kafka、RocketMQ、RabbitMQ 等,其功能特性有些不同,但核心的基础能力是重叠的,因此今天所讲的虽然是以 Kafka 为基础,但也可以类比到其他的消息队列中。
什么是消息队列
类比
消息队列可以理解为一个邮局。
邮局每天都需要处理庞大数量的邮件,对接邮局的有“寄信人”,也有“收信人”,邮局负责将寄信人寄出的信件送到收信人手中。
这其实就是消息队列的工作机制。
生产者(Producer)发出消息到某个主题(Topic),每个主题有 n 个分区(Partition),消息落到某个分区之后,由这个分区的邮递员发送到接收该分区消息的“收信人”手中——也就是消费者(Consumer)手中。
这里的诸多概念可能难以理解,但我们可以先不求甚解,将整个过程想象为邮局的工作流程即可。
场景理解
接下来我们聊一聊常见的消息队列场景。
削峰
消息队列削峰,实际上是利用消息队列来缓冲和平衡流量或请求,从而防止系统因为瞬时高流量而过载。
这个过程可以通过一个购物中心的比喻来理解:
- 高峰时段(流量峰值):想象一下,在节假日或特殊促销活动期间,购物中心会遇到大量顾客涌入,这就像系统在特定时刻遭遇高流量或高请求。
- 入口控制(消息队列的引入):为了防止购物中心过于拥挤,导致服务质量下降或安全问题,管理者可能会在入口处设置控制,比如让顾客分批进入。这就像引入消息队列来控制请求的流入。
- 等候区域(消息队列的缓冲作用):顾客到达后并不是直接进入购物中心,而是先在等候区域(类似于消息队列)等待。这个区域可以容纳大量的顾客,防止他们同时涌入商场。
- 分批进入(逐步处理请求):顾客从等候区域按顺序、分批进入购物中心。这样做可以确保商场内的顾客数量始终保持在一个可管理的水平。类似地,系统从消息队列中逐步、有序地处理请求,避免了一次性处理大量请求的压力。
- 避免系统崩溃(保护后端系统):通过这种方式,购物中心避免了因为顾客过多而导致的混乱和潜在的安全问题。同理,消息队列通过平衡请求的处理,保护了后端系统不被突然的高流量压垮。
- 提升用户体验(服务质量):虽然顾客需要在等候区稍作等待,但这确保了他们进入购物中心后能有更好的体验,不会遇到过于拥挤的情况。同样,通过消息队列平衡处理请求,系统可以更稳定地运行,提供更好的用户体验。
应用场景解耦
消息队列用于应用场景解耦。
例如我们常见的电商系统。
当用户下单之后,订单系统需要调用库存系统。此时一旦库存系统挂掉,订单就会出现异常。但如果使用了消息队列,订单系统只需要将订单创建完成的消息发往队列,库存系统就可以消费到该条信息。这种设计之下,即使库存系统挂掉,订单系统还是可以持续往队列中写入消息,等到库存队列恢复之后,再慢慢消化掉堆积的消息即可。
异步处理
有时候某些操作我们不需要关系返回值,也不需要处理他的错误,碰巧该操作的耗时还很长。这时候就可以用到消息队列进行异步处理。虽然在该操作不占用 CPU 的情况下,代码里面单开一个函数处理也不是不可以。
消息通讯
消息队列支持一对一发送消息,也支持一对多广播消息。典型的应用就是聊天室,既可以群发消息、又可以私发消息。
Kafka 的基础架构
接下来我们来具体介绍 Kafka。
Kafka 是由 LinkedIn 公司开源的一个消息队列,使用 Scala 和 Java 编写,目前也是 Apache 的顶级项目。
Kafka 为了获得极致的性能,在设计方面做了很多牺牲,比如不保证消息可靠性,可能会丢失消息。同时在多 topic 的情况下,写性能会出现明显下降,适合大数据,日志处理等离线业务场景。
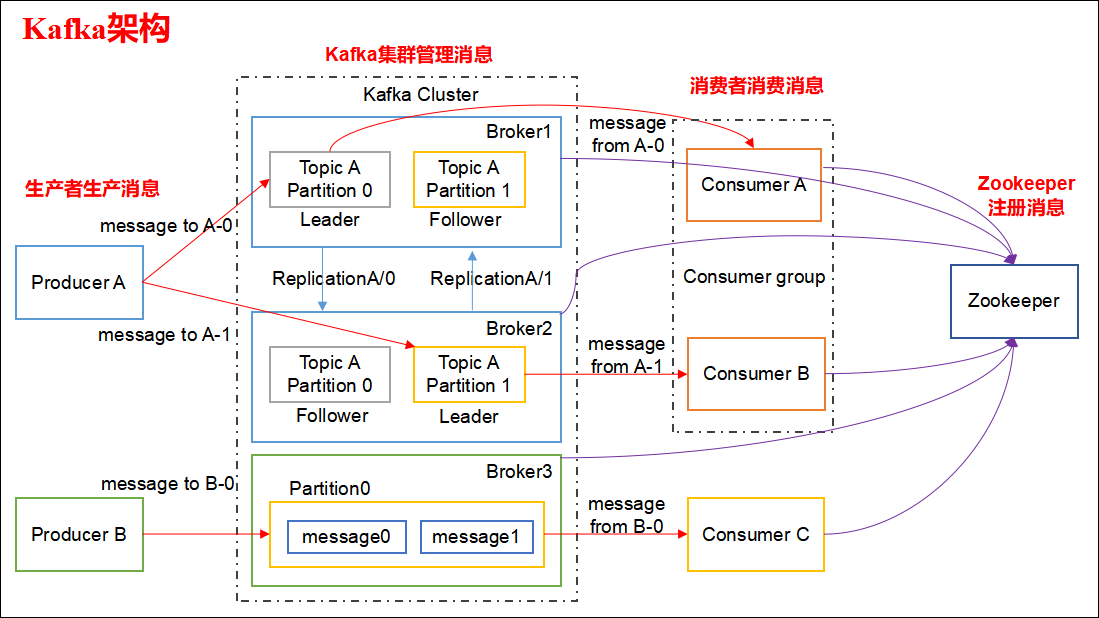
- 主题(Topic):Kafka 中的消息是按主题分类的。主题可以被看作是消息的类别或者名称。生产者将消息发布到特定的主题,而消费者则从主题订阅并消费消息。一个主题可以有多个订阅者,并且可以跨多个服务器或集群进行分区和复制。
- 分区(Partition):为了提高可扩展性和并行处理能力,每个主题可以分为多个分区。每个分区是一个有序的、不可变的消息序列,并且可以独立地存储在 Kafka 集群的不同服务器上。分区还允许在多个消费者之间并行处理数据。
- 消息(Message):消息是 Kafka 通信的基本单元。每个消息都包含一个键(key)、一个值(value)和一个时间戳。消息被生产者发送到主题的特定分区,并由消费者读取。
- 生产者(Producer):生产者是发布消息到 Kafka 主题的客户端应用程序。生产者负责确定将消息发布到哪个主题和分区。
- 消费者(Consumer):消费者是从 Kafka 主题读取消息的客户端应用程序。消费者可以订阅一个或多个主题,并从中读取数据。消费者群组(Consumer Groups)中的消费者可以共享对主题的订阅,提供了消息的负载均衡和容错功能。
- 消费者群组(Consumer Group):消费者可以组成一个群组来共同订阅一个主题。Kafka 确保每个分区只被群组中的一个消费者读取,这样可以在群组内部实现负载均衡,并确保每个消息只被处理一次。(多个 ConsumerGroup 就可以同时收到消息)
- Broker:Kafka 集群由多个服务器组成,每个服务器被称为 Broker。Broker 负责存储数据并处理客户端的读写请求。在一个健康的 Kafka 集群中,Broker 之间会同步数据,以保证高可用性和容错性。
- ZooKeeper:Kafka 使用 ZooKeeper 来管理集群配置、选举领导者以及在分区和消费者群组之间进行负载均衡。ZooKeeper 是一个分布式协调服务,它为 Kafka 提供了稳定和可靠的集群管理功能。
本篇完。下一篇具体讲解 Kafka 为什么会丢失消息,以及如何保证消息可靠性。