小小科普一下泄露相关知识:
服务进程泄露
服务进程泄露指的是服务进程中的敏感信息(例如,用户凭据、业务数据等)被未经授权的第三方获取或窃取的情况。泄露可能是有意或无意的,例如,服务进程被黑客攻击,或者员工疏忽将敏感信息保存在不安全的设备或网络中。泄露可能会对组织造成严重的财务损失、声誉损害、法律责任等风险,因此,保护服务进程和其中的数据非常重要。
systemd 是一个系统管理守护进程,用于启动、停止和管理系统上的服务。它可以监控服务进程,并在必要时重新启动它们,以确保它们保持运行状态。虽然 systemd 本身不会导致服务进程泄露,但它可能会因为一些配置或使用不当的情况下导致服务进程泄露。
预防
组织应该采取措施来防止服务进程泄露,例如,加强访问控制、使用加密保护数据、及时更新软件和系统补丁、加强员工安全意识培训等。
在使用 systemd 管理服务时,需要仔细检查和配置相关选项以避免以上问题的发生。同时,定期检查系统的资源使用情况和日志记录,以及审查服务脚本的编写质量,可以及早发现并解决服务进程泄露的问题。
泄露原因:
操作系统漏洞:操作系统中的漏洞可能会导致服务进程被攻击者利用,并从中获取敏感信息。
系统配置不当:服务进程在配置不当的情况下可能会泄露数据,例如,如果管理员没有正确配置文件权限或网络访问控制,则攻击者可能能够访问敏感数据。
人为错误:服务进程可能会因为员工疏忽或错误操作而被泄露,例如,如果员工在公共场所使用未加密的设备来访问敏感信息,则攻击者可能能够从中窃取信息。
僵木蠕虫:僵木蠕虫可以利用服务进程的漏洞来传播自己,并将受害者的敏感信息发送到攻击者的服务器。
社会工程学攻击:攻击者可以通过诈骗或欺骗手段来获取服务进程的访问权限,例如,通过钓鱼邮件或假冒管理员的方式获取密码或其他敏感信息。
systemd服务泄露进程的原因
资源限制不当:如果您没有正确地配置 systemd 服务的资源限制,如内存、CPU 使用率等,服务进程可能会占用过多的系统资源而导致泄露。
配置错误:如果您在编写 systemd 服务文件时存在错误或不当的配置,例如未正确设置 Restart、RestartSec 等选项,会导致服务进程无限重启而占用系统资源。
日志记录不当:如果您启用了系统日志记录,但没有配置正确的日志轮换和清理机制,可能会导致日志文件占用过多的磁盘空间并影响系统运行。
脚本编写错误:如果您在编写 systemd 服务脚本时存在错误,例如未正确关闭文件描述符、未清理临时文件等,会导致服务进程泄露。
资源泄露
当一个进程占用过多的系统资源时,可能会导致系统无法正常运行。比如,当一个进程占用过多的内存资源时,系统的其它进程可能无法获得足够的内存,从而导致系统变得缓慢或崩溃。同样的,当一个进程占用过多的 CPU 资源时,系统的其它进程可能无法获得足够的 CPU 时间,从而导致系统变得不稳定。
如果一个进程持续占用过多的系统资源,而且没有得到正确的处理或限制,就可能导致资源泄漏。这是因为系统资源是有限的,如果一个进程一直占用系统资源而不释放,这些资源将无法用于其它进程或任务,最终会导致系统崩溃或变得不可用。
例如,如果一个进程不断地分配内存而不释放,系统的可用内存将逐渐减少,直到系统没有足够的内存来支持其它进程或任务。这就是内存泄漏的一种情况。同样地,如果一个进程不断占用 CPU 资源而不释放,系统的 CPU 时间将逐渐减少,可能会导致其它进程无法正常运行。
因此,当一个进程占用过多的系统资源时,必须及时采取措施限制其资源使用,以避免资源泄漏的发生。
内存泄露:内存泄漏是指程序中分配的内存空间在使用完毕后没有被正确释放,导致内存使用量不断增加,最终导致系统资源耗尽或崩溃。
文件句柄泄露:当程序打开文件或网络连接时,会创建文件句柄或网络连接句柄等系统资源,如果这些句柄没有被正确关闭,将导致系统资源的耗尽和系统运行缓慢。
数据库连接泄露:当程序使用数据库连接池时,如果连接没有正确释放,将导致连接池资源的耗尽,从而导致程序崩溃或运行缓慢。
线程泄露:当程序创建线程时,如果没有正确终止线程,将导致线程资源的耗尽,从而导致程序崩溃或运行缓慢。
资源竞争:当多个进程或线程同时访问同一资源时,如果没有正确的同步机制,将导致资源竞争,最终导致资源泄露和程序崩溃。
资源泄露预防
为了避免资源泄露,开发人员应该编写高质量的代码,遵循编程规范和最佳实践,及时释放不再使用的资源,使用资源池等优化技术,以及进行有效的测试和调试。同时,系统管理员应该监控系统资源使用情况,定期检查系统资源配置,及时发现和修复资源泄露问题。
正文
处理原因:
某一天巡检发现在kubelet日志中发现了大量的该日志
Failed to get system container stats for "/system.slice/docker.service": failed to get cgroup stats for "/system.slice/docker.service": failed to get container info for "/system.slice/docker.service": unknown container "/system.slice/docker.service"
后来查询到有两种方式可以解决该问题
1、kubelet配置文件中加如下参数:
--runtime-cgroups=/systemd/system.slice --kubelet-cgroups=/systemd/system.slice
kubelet-cgroups是Kubernetes集群中的一个配置参数,它指定kubelet在使用cgroups时应该使用哪个驱动程序。kubelet是在每个节点上运行的主要“节点代理”,它管理节点上的容器和Pod。[1]
当kubelet使用Docker等容器运行时,它应该使用与容器运行时相同的cgroups驱动程序,以确保容器与Kubernetes节点之间的资源管理一致。您可以通过配置kubelet的--kubelet-cgroups参数来指定cgroups驱动程序。[1]
要配置kubelet的cgroups驱动程序,请按照以下步骤操作:
- 了解Kubernetes容器运行时的要求。[1]
- 配置容器运行时cgroups驱动程序。在Kubernetes集群中,推荐使用systemd驱动程序而不是cgroupfs。[1]
- 配置kubelet的--kubelet-cgroups参数以匹配容器运行时的cgroups驱动程序。[1]
- 验证kubelet的cgroups驱动程序是否正确配置。您可以通过kubelet的日志或kubectl describe node命令来检查kubelet的cgroups驱动程序。[1][2]
总之,--kubelet-cgroups参数是配置kubelet在使用cgroups时应该使用哪个驱动程序的重要参数,它与容器运行时的cgroups驱动程序相匹配,以确保容器与Kubernetes节点之间的资源管理一致。
2、修改kubelet.service的unit文件增加如下参数:
[Unit]
After=docker.service
Requires=docker.service
[service]
CPUAccounting=true
MemoryAccounting=true
systemd.unit中的Requires=选项用于配置其他单元的依赖关系。如果该单元被激活,这里列出的单元也将被激活。如果其他单元之一被停用或其激活失败,该单元也将被停用。此外,Wants=是Requires=的一种弱化版本,如果列出的单元无法启动或无法添加到事务中,对整个事务的有效性没有影响,推荐将一个单元的启动与另一个单元的启动钩子连接起来。
Wants关键字指定需要在启动该服务之前启动指定的那个服务,以确保其处于稳定状态。
此外,.slice是与Linux Control Group节点相关联的一个单元,允许将资源限制或分配给与slice相关的任何进程。该名称反映了它在cgroup树中的分层位置。根据它们的类型,默认情况下将单元放置在某些切片中。
通过添加 Requires 字段,我们确保了 kubelet在启动之前,必须要保证 docker.service 这个 Unit 已经启动。这样可以避免 kubelet在docker服务未准备好的情况下启动导致的错误,提高了服务的稳定性[1][3]。
我们指定了该服务依赖于 docker.service这个 Unit。如果这个服务没有启动,kubelet 将无法启动。在 [Service] 区块中,我们定义了服务的启动命令。在 [Install] 区块中,我们定义了服务在 multi-user.target 启动级别下应该被启动。
After字段是用于定义启动单元之后需要启动的其他单元的选项。如果在一个服务单元的配置文件中添加了After=B,意味着在启动当前服务单元之前,需要先启动B单元。同时,需要注意的是,Wants和Requires选项与After选项的含义是不同的,它们并不意味着After,如果没有指定After选项,这些单元将被并行启动。总的来说,在systemd的unit文件中,通过添加After字段,可以实现控制服务单元启动顺序的需求。
出现该问题的处理过程
初步查看这个错误表明错误Failed to get system container stats for "/system.slice/docker.service"是合法的代码如下:
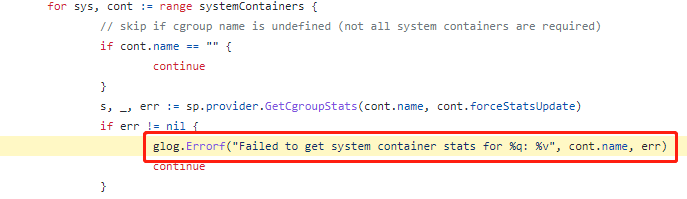
然而,某些情况下可能会导致CentOS的systemd不会为每个服务创建memory/cpu cgroups,因此/sys/fs/cgroup/memory/system.slice cgroup没有任何子进程
[root@test ~]# ls -ld /sys/fs/cgroup/* /system.slice/kubelet.service/ drwxr-xr-x. 2 root root 0 Jun 20 13:33 /sys/fs/cgroup/systemd/system.slice/kubelet.service/
[root@test ~]# cat /proc/$(pidof kubelet)/cgroup 11:devices:/system.slice 10:cpuset:/ 9:pids:/system.slice 8:memory:/system.slice 7:cpuacct,cpu:/system.slice 6:freezer:/ 5:perf_event:/ 4:blkio:/system.slice 3:hugetlb:/ 2:net_prio,net_cls:/ 1:name=systemd:/system.slice/kubelet.service
可能后续kubelet记录的错误更改为CPUAccounting not enabled for pid
Jun 20 13:39:01 test kubelet[27723]: W0620 13:39:01.499937 27723 container_manager_linux.go:791] CPUAccounting not enabled for pid: 27213 Jun 20 13:39:01 test kubelet[27723]: W0620 13:39:01.503987 27723 container_manager_linux.go:794] MemoryAccounting not enabled for pid: 27213
在systemd中,每个pid都在一个统一的cgroup层级结构中(名称为systemd,如systemd-cgls所示)。默认情况下,CPU和内存帐户记录是关闭的,用户可以选择在每个单元或全局范围内启用它。用户可以通过编辑/etc/systemd/system.conf文件来全局启用CPU和内存帐户记录(DefaultCPUAccounting=true DefaultMemoryAccounting=true)。用户还可以通过在单个单元中启用CPUAccounting=true和MemoryAccounting=true来在单元级别上启用CPU和内存帐户记录。当Kubelet在终端中启动时,我们只会发出警告,如果未启用CPU或内存账户记录,以不破坏本地开发流程。例如,用户会话的cgroup将是/user.slice/user-X.slice/session-X.scope之类的东西,但是在启动Docker容器的系统上,CPU和内存cgroup将是最近的祖先,而且只有在其单元(或全局范围)上启用了账户记录才能获得Kubelet的CPU或内存帐户记录统计信息。
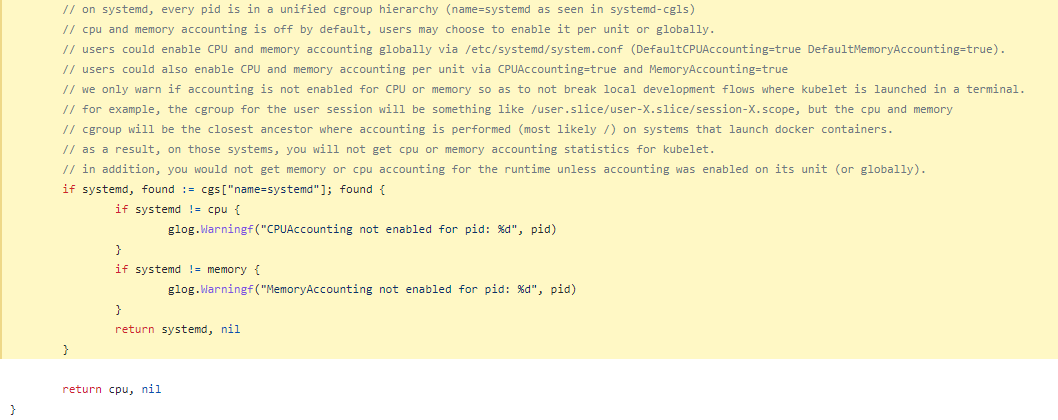
实际这也算合法因为cgroup并没有为kubelet的两个进程启用cgroup
测试一下修改kubelet配置的方式处理该问题,因为默认的kubelet配置文件中没有--kubelet-cgroups这个参数。
如果您想在 Kubernetes 中使用相同的 /system.slice 容器组(cgroup),则可以使用 --runtime-cgroups=/system.slice --kubelet-cgroups=/system.slice,但是 kubelet 仍然会逃逸出 /system.slice/kubelet.service cgroup的管理组。
--runtime-cgroups=/systemd/system.slice --kubelet-cgroups=/systemd/system.slice
下面命令查看容器状态信息时使用
curl -k --key /etc/kubernetes/ssl/client.key --cert /etc/kubernetes/ssl/client.crt \ --cacert /etc/kubernetes/ssl/ca.crt https://kubeletIP:port/stats/summary
在没使用--kubelet-cgroups前
{ "name": "kubelet", "startTime": "2018-06-18T14:53:27Z", "cpu": { "time": "2018-06-21T07:55:13Z", "usageNanoCores": 26266701, "usageCoreNanoSeconds": 6484569033001 }, "memory": { "time": "2018-06-21T07:55:13Z", "usageBytes": 43307008, "workingSetBytes": 41459712, "rssBytes": 39514112, "pageFaults": 33329266, "majorPageFaults": 67 }, "userDefinedMetrics": null }, { "name": "runtime", "startTime": "2018-06-18T12:32:06Z", "cpu": { "time": "2018-06-21T07:55:10Z", "usageNanoCores": 8736395, "usageCoreNanoSeconds": 2045752364513 }, "memory": { "time": "2018-06-21T07:55:10Z", "usageBytes": 464941056, "workingSetBytes": 280064000, "rssBytes": 55271424, "pageFaults": 283147, "majorPageFaults": 511 }, "userDefinedMetrics": null }, { "name": "pods", "startTime": "2018-06-18T12:32:07Z", "cpu": { "time": "2018-06-21T07:55:13Z", "usageNanoCores": 22365065, "usageCoreNanoSeconds": 5086801961322 }, "memory": { "time": "2018-06-21T07:55:13Z", "availableBytes": 1738805248, "usageBytes": 512602112, "workingSetBytes": 358572032, "rssBytes": 152924160, "pageFaults": 0, "majorPageFaults": 0 }, "userDefinedMetrics": null }
使用--kubelet-cgroup前,检查Kubernetes中的容器的CPU和内存使用情况,可以使用cgroup和一些命令来执行
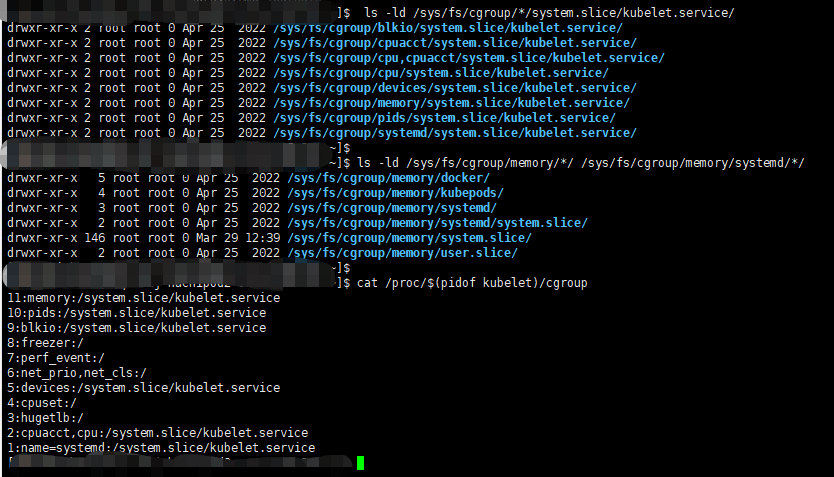
/sys/fs/cgroup/systemd: ├─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 22 ├─kubepods │ 。。。。省略不重要的部分 ├─systemd │ └─system.slice │ └─35993 /usr/bin/dockerd ├─docker │ ├─。。。。 ├─。。。。 └─system.slice ├─etcd.service │ └─3625 /usr/bin/etcd --max-request-bytes=4718592 ├─kube-apiserver.service │ └─12876 /usr/bin/kube-apiserver --insecure-bind-address=0.0.0.0 --insecure-port=1180 --authorization-mode=RBAC --anonymous-auth=false --log-dir=/apps/log/k ├─kube-scheduler.service │ └─62346 /usr/bin/kube-scheduler --logtostderr=false --log-dir=/apps/log/kubernetes --v=0 --tls-cipher-suites=TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,TLS_EC ├─kube-controller-manager.service │ └─57550 /usr/bin/kube-controller-manager --leader-elect=true --service-account-private-key-file=/etc/kubernetes/ssl/apiserver.key --service-cluster-ip-rang ├─rsyslog.service │ └─18971 /usr/sbin/rsyslogd -n ├─network.service │ ├─20964 /sbin/dhclient -1 -q -lf /var/lib/dhclient/dhclient--bond1.lease -pf /var/run/dhclient-bond1.pid -H dzqz-hlj-hachipod2-core-128-203 bond1 │ └─21147 /sbin/dhclient -6 -1 -lf /var/lib/dhclient/dhclient6--bond1.lease -pf /var/run/dhclient6-bond1.pid bond1 -H dzqz-hlj-hachipod2-core-128-203 。。。。 ├─kubelet.service │ └─35789 /usr/bin/kubelet --root-dir=/apps/kubernetes --v=0 --pod-infra-container-image=10.187.128.195:1121/google_containers/pause:3.1 --kubeconfig=/etc/ku ├─crond.service │ └─34065 /usr/sbin/crond -n ├─kube-proxy.service │ └─33578 /usr/bin/kube-proxy --proxy-mode=iptables --logtostderr=false --log-dir=/apps/log/kubernetes --v=0 --kubeconfig=/etc/kubernetes/ssl/kubeconfig --ho ├─containerd.service │ ├─ 。。。。 └─systemd-journald.service └─17563 /usr/lib/systemd/systemd-journald
使用--kubelet-cgroup后,检查Kubernetes中的容器的CPU和内存使用情况,可以使用cgroup和一些命令来执行
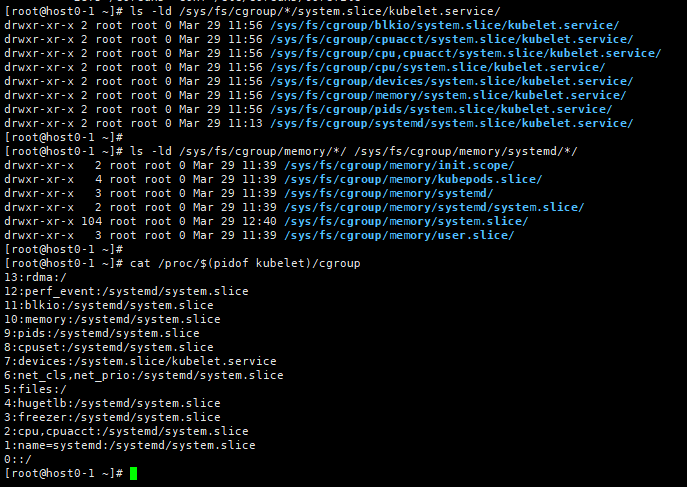
/sys/fs/cgroup/systemd/: ├─user.slice │ └─。。。。 ├─systemd │ └─system.slice │ ├─ 882 /usr/bin/containerd │ ├─ 961 /usr/bin/dockerd │ ├─。。。。 │ └─64641 /usr/bin/kubelet --root-dir=/apps/kubernetes --v=0 --pod-infra-container-image=192.168.123.172:1121/kube_system/pause:3.1 --kubeconfig=/etc/kubern> ├─init.scope │ └─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 16 ├─system.slice │ ├─rngd.service │ │ └─820 /sbin/rngd -f │ ├─irqbalance.service │ │ └─831 /usr/sbin/irqbalance --pid=/var/run/irqbalance.pid │ ├─kube-scheduler.service │ │ └─815 /usr/bin/kube-scheduler --logtostderr=false --log-dir=/apps/log/kubernetes --v=0 --tls-cipher-suites=TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,TLS_ECD> │ ├─containerd.service │ │ ├─1675 /usr/bin/containerd-shim-runc-v2 -namespace moby -id dd65853128dfe7296d029732af4ba803002e46a68d1c63b019c09c4bcfe6b257 -address /run/containerd/cont> │ │ └─1690 /usr/bin/containerd-shim-runc-v2 -namespace moby -id b5d32291ee947a77219bf108582e8c9362c596bcc7725b8e43d77719dd4ef0d1 -address /run/containerd/cont> │ ├─systemd-networkd.service │ │ └─716 /usr/lib/systemd/systemd-networkd │ ├─systemd-udevd.service │ │ └─711 /usr/lib/systemd/systemd-udevd │ ├─nfs-mountd.service │ │ └─1006 /usr/sbin/rpc.mountd │ ├─kube-apiserver.service │ │ └─874 /usr/bin/kube-apiserver --bind-address=0.0.0.0 --secure-port=6443 --authorization-mode=RBAC --anonymous-auth=false --log-dir=/apps/log/kubernetes --> │ ├─polkit.service │ │ └─818 /usr/lib/polkit-1/polkitd --no-debug │ ├─chronyd.service │ │ └─827 /usr/sbin/chronyd │ ├─tuned.service │ │ └─880 /usr/bin/python3 -Es /usr/sbin/tuned -l -P │ ├─nfsdcld.service │ │ └─805 /usr/sbin/nfsdcld │ ├─systemd-journald.service │ │ └─687 /usr/lib/systemd/systemd-journald │ ├─sshd.service │ │ └─878 sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups │ ├─crond.service │ │ └─909 /usr/sbin/crond -n │ ├─kube-controller-manager.service │ │ └─876 /usr/bin/kube-controller-manager --leader-elect=true --service-account-private-key-file=/etc/kubernetes/ssl/sa.key --service-cluster-ip-range=169.16> │ ├─NetworkManager.service │ │ └─811 /usr/sbin/NetworkManager --no-daemon │ ├─etcd.service │ │ └─1488 /usr/bin/etcd │ ├─rpc-statd.service │ │ └─967 /usr/sbin/rpc.statd │ ├─docker-b5d32291ee947a77219bf108582e8c9362c596bcc7725b8e43d77719dd4ef0d1.scope │ │ ├─1725 /usr/bin/python3 -u /container/tool/run --copy-service │ │ ├─1834 /usr/local/sbin/keepalived -f /usr/local/etc/keepalived/keepalived.conf --dont-fork --log-console --log-detail --dump-conf │ │ └─1867 /usr/local/sbin/keepalived -f /usr/local/etc/keepalived/keepalived.conf --dont-fork --log-console --log-detail --dump-conf │ ├─gssproxy.service │ │ └─879 /usr/sbin/gssproxy -D │ ├─rsyslog.service │ │ └─965 /usr/sbin/rsyslogd -n -i/var/run/rsyslogd.pid │ ├─rpcbind.service │ │ └─966 /usr/bin/rpcbind -r -w -f │ ├─kube-proxy.service │ │ └─877 /usr/bin/kube-proxy --proxy-mode=iptables --logtostderr=false --log-dir=/apps/log/kubernetes --v=0 --kubeconfig=/etc/kubernetes/ssl/kubeconfig --hos> │ ├─nfs-idmapd.service │ │ └─802 /usr/sbin/rpc.idmapd │ ├─docker-dd65853128dfe7296d029732af4ba803002e46a68d1c63b019c09c4bcfe6b257.scope │ │ ├─1719 haproxy -W -db -f /usr/local/etc/haproxy/haproxy.cfg │ │ └─1745 haproxy -W -db -f /usr/local/etc/haproxy/haproxy.cfg │ ├─dbus.service │ │ └─810 /usr/bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation --syslog-only │ ├─system-getty.slice │ │ └─getty@tty1.service │ │ └─910 /sbin/agetty -o -p -- \u --noclear tty1 linux │ └─systemd-logind.service │ └─894 /usr/lib/systemd/systemd-logind └─kubepods.slice └─kubepods-burstable.slice ├─kubepods-burstable-pode62f4ff6_c7a3_415d_b7f2_65519485f1b2.slice │ ├─docker-bb1f3fe911fb4f5da0d0ba8e1bc6cf504cd05a2d5baeeadc1cf7c8e850d15ffc.scope │ │ └─2255 /pause │ └─docker-e6f04e204ed2208239570f9e0109f84be599d8af97e30c105a30d69db3c7705a.scope │ └─2628 /coredns -conf /etc/coredns/Corefile ├─kubepods-burstable-pod3019e921_1bcd_452a_9d79_a46748ef5fb6.slice │ ├─docker-5180414bbecc17ac09f6587093c199e22f7d9a311d42b32b2d9cf7b9d967d091.scope │ │ ├─2730 /usr/local/bin/runsvdir -P /etc/service/enabled │ │ ├─2945 runsv allocate-tunnel-addrs │ │ ├─2946 runsv felix │ │ ├─2947 runsv monitor-addresses │ │ ├─2948 calico-node -allocate-tunnel-addrs │ │ ├─2949 calico-node -felix │ │ └─2950 calico-node -monitor-addresses │ └─docker-a9788d889187bfd13e2d752fd51cda0a04caa33186ea11de0e077c27cc7514b3.scope │ └─2195 /pause └─kubepods-burstable-podf376ed6b_c3a7_4ef2_a355_d52d34c6e55e.slice ├─docker-104743f4381f8387b30255c2db2c0b609915fbe2167591c86aadb1102fb96270.scope │ └─2774 /pause └─docker-8ecdd501bc0f0393413f7820ef1d8b892137009e6284b332548212f573ed6600.scope └─2879 /coredns -conf /etc/coredns/Corefile
解释对比结果:
--kubelet-cgroups和--runtime-cgroups的解决方法会破坏systemd cgroups,导致kubelet/docker进程逃离服务cgroups,且kubelet /stats/summary会错误地报告运行时与kubelet systemContainers的CPU/内存利用率。相比之下,kubelet日志中的“Failed to get system container stats for ...”消息还算是好的。这只意味着kubelet /stats/summary API会忽略系统容器的任何CPU/内存指标,这是正常结果,因为它们缺少自己按服务划分的cgroups来进行计算。因此,建议不要使用--kubelet-cgroups和--runtime-cgroups的解决方法来处理/systemd/system.slice问题。
使用--runtime-cgroups=/systemd/system.slice --kubelet-cgroups=/systemd/system.slice”解决方法 处理system.slice问题是不推荐的... 这最终会为所有cgroup控制器创建全新的顶级/systemd cgroups。就如cat /proc/$(pidof kubelet)/cgroup所展示的结果。
尽管 kubelet 进程已经从 systemd cgroup 中逃逸出来,但是 systemctl stop kubelet 命令似乎仍然有效。我想 systemd 仍然记得主 PID,并以此作为后备方式来终止进程。然而,如果这样做可能会导致 systemd 表现不正常,泄漏服务进程(算是配置问题导致kubelet接管了资源管理如果kubelet有漏洞被攻击就有可能导致服务泄露被获取敏感信息),那么我也不会感到惊讶。整个概念是让 kubelet 操作 systemd 管理的服务进程的 cgroups,这只会引发麻烦。
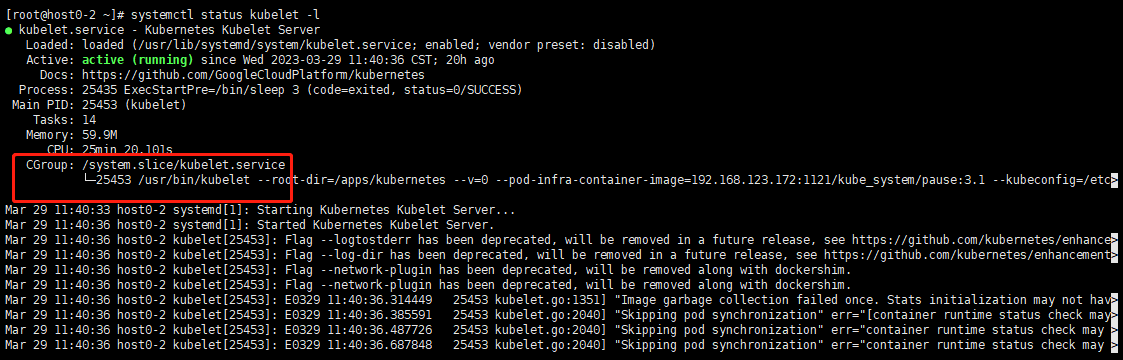
请注意,systemctl status kubelet 以不同于正常的方式呈现 cgroup 下的进程。因为使用--kubelet-cgroups=/systemd/system.slice后重启服务,查看状态发现cgroup不是直接在/sys/fs/cgroup/systemd/system.slice/kubelet.service而是多了多了一个箭头意思就是还有一级结构,这个需要通过systemd-cgls查看,上边已经查过了就不再查了。
这是使用前的
这是使用后的
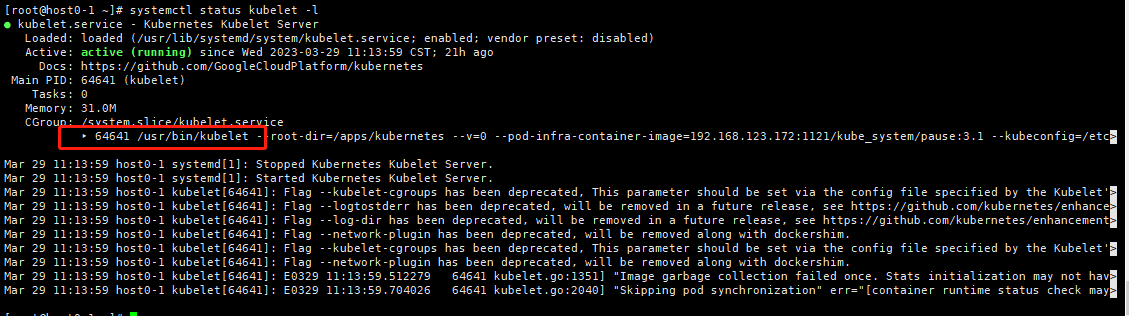
此问题的正确修复是配置systemd为 kubelet 创建所需的每服务 CPU/内存 cgroups
[Service] CPUAccounting=true MemoryAccounting=true [Unit] After=docker.service
Requires=docker.service
[root@host0-2 ~]# cat /proc/$(pidof kubelet)/cgroup 13:perf_event:/ 12:memory:/system.slice/kubelet.service 11:pids:/system.slice/kubelet.service 10:rdma:/ 9:hugetlb:/ 8:files:/ 7:net_cls,net_prio:/ 6:devices:/system.slice/kubelet.service 5:freezer:/ 4:cpuset:/ 3:blkio:/system.slice/kubelet.service 2:cpu,cpuacct:/system.slice/kubelet.service 1:name=systemd:/system.slice/kubelet.service 0::/
[root@host0-2 ~]# curl -k --key /etc/kubernetes/ssl/client.key --cert /etc/kubernetes/ssl/client.crt --cacert /etc/kubernetes/ssl/ca.crt https://192.168.123.62:10250/stats/summary | grep -A 10 runtime % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 13319 0 13319 0 0 684k 0 --:--:-- --:--:-- --:--:-- 684k "name": "runtime", "startTime": "2023-03-29T00:57:58Z", "cpu": { "time": "2023-03-30T01:57:43Z", "usageNanoCores": 17929435, "usageCoreNanoSeconds": 1524511411400 }, "memory": { "time": "2023-03-30T01:57:43Z", "usageBytes": 347926528, "workingSetBytes": 112685056, -- "runtime": { "imageFs": { "time": "2023-03-30T01:57:37Z", "availableBytes": 26077618176, "capacityBytes": 36718542848, "usedBytes": 1643582323, "inodesFree": 2177992, "inodes": 2293760, "inodesUsed": 115768 } },
[root@host0-2 ~]# curl -k --key /etc/kubernetes/ssl/client.key --cert /etc/kubernetes/ssl/client.crt --cacert /etc/kubernetes/ssl/ca.crt https://192.168.123.62:10250/stats/summary | grep -A 10 kubelet % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 13319 0 "name": "kubelet", 13319 "startTime": "2023-03-29T03:40:36Z", "cpu": { "time": "2023-03-30T01:57:46Z", 0 "usageNanoCores": 20974321, "usageCoreNanoSeconds": 1637795101143 }, "memory": { "time": "2023-03-30T01:57:46Z", "usageBytes": 63250432, 0 "workingSetBytes": 56721408, 812k 0 --:--:-- --:--:-- --:--:-- 867k [root@host0-2 ~]# cat /sys/fs/cgroup/memory/system.slice/kubelet.service/memory.usage_in_bytes
63250432
启用任何服务单元的 CPU/内存控制似乎会导致同一切片中所有服务的 CPU/内存控制都被启用... 因此,docker.service 现在也拥有了自己的 CPU/内存控制组。kubelet /stats/summary API 现在报告 kubelet 和运行时系统容器的度量指标。
在启用某个服务单元的 CPU/内存账户时,会同时启用同一切片中所有服务的 CPU/内存账户。因此,docker.service 等其他服务也会拥有自己的 CPU/内存控制组。此外,kubelet /stats/summary API 现在可以提供有关 kubelet 和运行时系统容器的度量指标。
- quot container unknown service dockerquot container unknown service docker logs container service quot signature unknown linux quot fastcgi primary unknown container镜像service情况 应用服务container镜像service quot错误builder unknown lightsail container services来源 module quot container rmi shorthand compose unknown docker