A Tour Through TREE_RCU's Expedited Grace Periods
通过TREE_RCU的加速宽限期进行一次旅行
Introduction
引言
This document describes RCU's expedited grace periods. Unlike RCU's normal grace periods, which accept long latencies to attain high efficiency and minimal disturbance, expedited grace periods accept lower efficiency and significant disturbance to attain shorter latencies.
本文介绍了RCU的加速宽限期。与RCU的正常宽限期不同,加速宽限期为了达到更短的延迟而接受较低的效率和显著的干扰。
There are two flavors of RCU (RCU-preempt and RCU-sched), with an earlier third RCU-bh flavor having been implemented in terms of the other two. Each of the two implementations is covered in its own section.
RCU有两种类型(RCU-preempt和RCU-sched),还有一种早期的RCU-bh类型已经通过其他两种类型实现。每种实现都在自己的部分中进行了介绍。
Expedited Grace Period Design
加速宽限期设计
The expedited RCU grace periods cannot be accused of being subtle, given that they for all intents and purposes hammer every CPU that has not yet provided a quiescent state for the current expedited grace period. The one saving grace is that the hammer has grown a bit smaller over time: The old call to try_stop_cpus() has been replaced with a set of calls to smp_call_function_single(), each of which results in an IPI to the target CPU. The corresponding handler function checks the CPU's state, motivating a faster quiescent state where possible, and triggering a report of that quiescent state. As always for RCU, once everything has spent some time in a quiescent state, the expedited grace period has completed.
加速RCU宽限期可以说是毫不含糊的,因为它们实际上会对每个尚未为当前加速宽限期提供静止状态的CPU进行干扰。唯一的好处是随着时间的推移,这种干扰变得更小了:旧的try_stop_cpus()调用已被一组smp_call_function_single()调用所取代,每个调用都会向目标CPU发送IPI。相应的处理函数会检查CPU的状态,尽可能地促使其进入更快的静止状态,并触发对该静止状态的报告。对于RCU来说,一旦所有事物都在静止状态下花费了一些时间,加速宽限期就完成了。
The details of the smp_call_function_single() handler's operation depend on the RCU flavor, as described in the following sections.
smp_call_function_single()处理程序的操作细节取决于RCU类型,如下面的部分所述。
RCU-preempt Expedited Grace Periods
RCU-preempt加速宽限期
CONFIG_PREEMPTION=y kernels implement RCU-preempt. The overall flow of the handling of a given CPU by an RCU-preempt expedited grace period is shown in the following diagram:
配置了CONFIG_PREEMPTION=y的内核实现了RCU-preempt。下图显示了RCU-preempt加速宽限期对给定CPU的处理的整体流程:
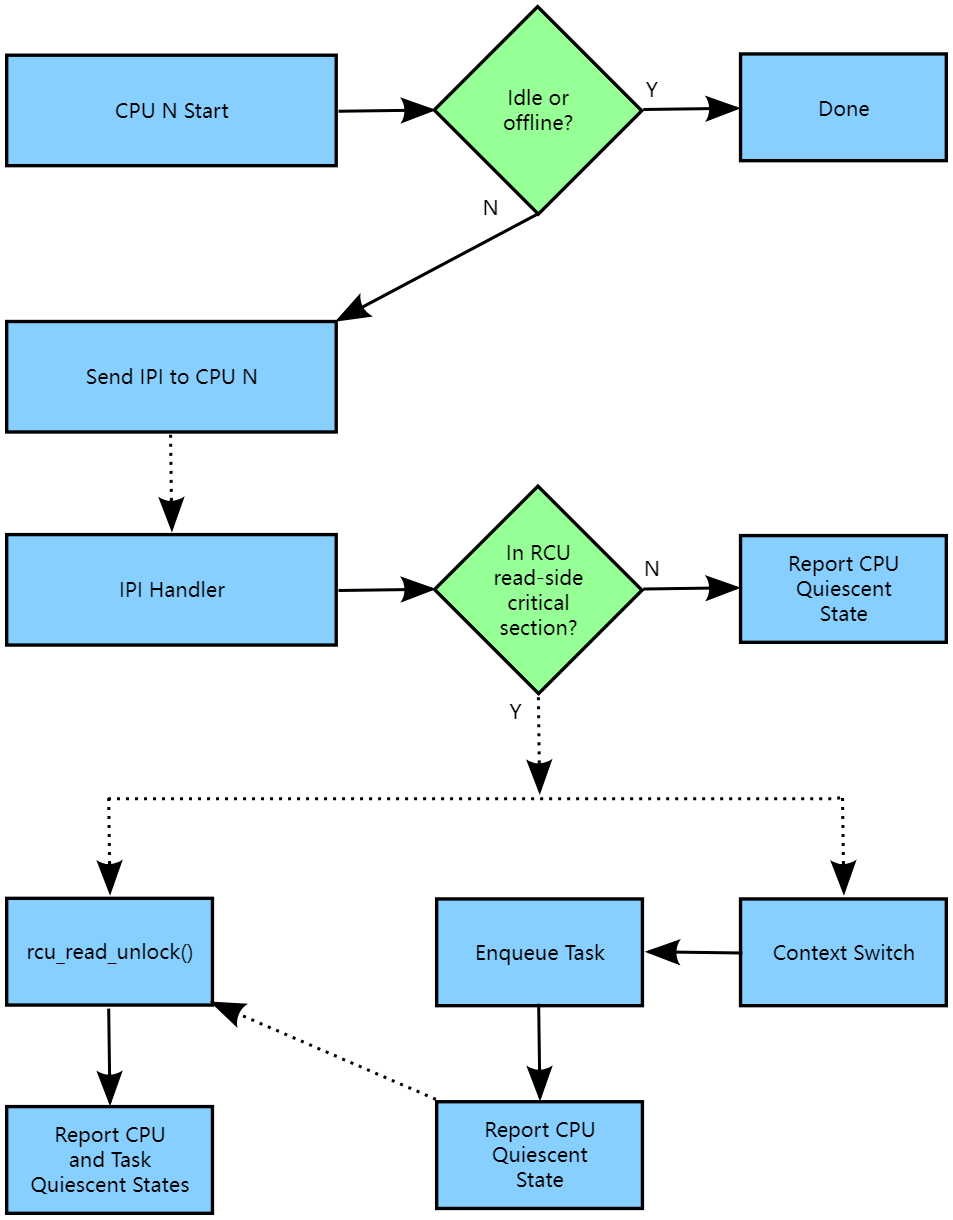
The solid arrows denote direct action, for example, a function call. The dotted arrows denote indirect action, for example, an IPI or a state that is reached after some time.
实线箭头表示直接操作,例如函数调用。虚线箭头表示间接操作,例如IPI或经过一段时间后达到的状态。
If a given CPU is offline or idle, synchronize_rcu_expedited() will ignore it because idle and offline CPUs are already residing in quiescent states. Otherwise, the expedited grace period will use smp_call_function_single() to send the CPU an IPI, which is handled by rcu_exp_handler().
如果给定的CPU处于离线或空闲状态,synchronize_rcu_expedited()将忽略它,因为空闲和离线的CPU已经处于静止状态。否则,加速宽限期将使用smp_call_function_single()向CPU发送IPI,由rcu_exp_handler()处理。
However, because this is preemptible RCU, rcu_exp_handler() can check to see if the CPU is currently running in an RCU read-side critical section. If not, the handler can immediately report a quiescent state. Otherwise, it sets flags so that the outermost rcu_read_unlock() invocation will provide the needed quiescent-state report. This flag-setting avoids the previous forced preemption of all CPUs that might have RCU read-side critical sections. In addition, this flag-setting is done so as to avoid increasing the overhead of the common-case fastpath through the scheduler.
然而,由于这是可抢占的RCU,rcu_exp_handler()可以检查CPU当前是否在RCU读取侧临界区中运行。如果不是,则处理程序可以立即报告一个静止状态。否则,它会设置标志,以便最外层的rcu_read_unlock()调用提供所需的静止状态报告。这种标志设置避免了可能具有RCU读取侧临界区的所有CPU之前的强制抢占。此外,这种标志设置是为了避免增加调度程序中常见情况快速路径的开销。
Again because this is preemptible RCU, an RCU read-side critical section can be preempted. When that happens, RCU will enqueue the task, which will the continue to block the current expedited grace period until it resumes and finds its outermost rcu_read_unlock(). The CPU will report a quiescent state just after enqueuing the task because the CPU is no longer blocking the grace period. It is instead the preempted task doing the blocking. The list of blocked tasks is managed by rcu_preempt_ctxt_queue(), which is called from rcu_preempt_note_context_switch(), which in turn is called from rcu_note_context_switch(), which in turn is called from the scheduler.
同样由于这是可抢占的RCU,RCU读取侧临界区可以被抢占。当发生这种情况时,RCU将将任务入队,该任务将继续阻塞当前的加速宽限期,直到它恢复并找到最外层的rcu_read_unlock()。CPU将在将任务入队后立即报告一个静止状态,因为CPU不再阻塞宽限期,而是被抢占的任务在阻塞。阻塞任务的列表由rcu_preempt_ctxt_queue()管理,该函数从rcu_preempt_note_context_switch()调用,后者又从rcu_note_context_switch()调用,后者又从调度程序调用。
Quick Quiz:
Why not just have the expedited grace period check the state of all the CPUs? After all, that would avoid all those real-time-unfriendly IPIs.
为什么不只是让加速宽限期检查所有CPU的状态呢?毕竟,这样可以避免所有那些实时不友好的IPI。
Answer:
Because we want the RCU read-side critical sections to run fast, which means no memory barriers. Therefore, it is not possible to safely check the state from some other CPU. And even if it was possible to safely check the state, it would still be necessary to IPI the CPU to safely interact with the upcoming rcu_read_unlock() invocation, which means that the remote state testing would not help the worst-case latency that real-time applications care about.
因为我们希望RCU读取侧临界区运行得快,这意味着没有内存屏障。因此,不可能安全地从其他CPU检查状态。即使可以安全地检查状态,仍然需要IPI CPU才能安全地与即将到来的rcu_read_unlock()调用进行交互,这意味着远程状态测试无法帮助实时应用程序关心的最坏情况延迟。
One way to prevent your real-time application from getting hit with these IPIs is to build your kernel with CONFIG_NO_HZ_FULL=y. RCU would then perceive the CPU running your application as being idle, and it would be able to safely detect that state without needing to IPI the CPU.
防止您的实时应用程序收到这些IPI的一种方法是使用CONFIG_NO_HZ_FULL=y构建内核。然后,RCU将认为运行您的应用程序的CPU处于空闲状态,并且可以在不需要IPI CPU的情况下安全地检测到该状态。
Please note that this is just the overall flow: Additional complications can arise due to races with CPUs going idle or offline, among other things.
请注意,这只是整体流程:由于与CPU空闲或离线等情况的竞争,还可能出现其他复杂情况。
RCU-sched Expedited Grace Periods
RCU-sched加速宽限期
CONFIG_PREEMPTION=n kernels implement RCU-sched. The overall flow of the handling of a given CPU by an RCU-sched expedited grace period is shown in the following diagram:
当不支持内核抢占时,内核实现了RCU-sched。下图展示了RCU-sched加速宽限期处理给定CPU的整体流程:
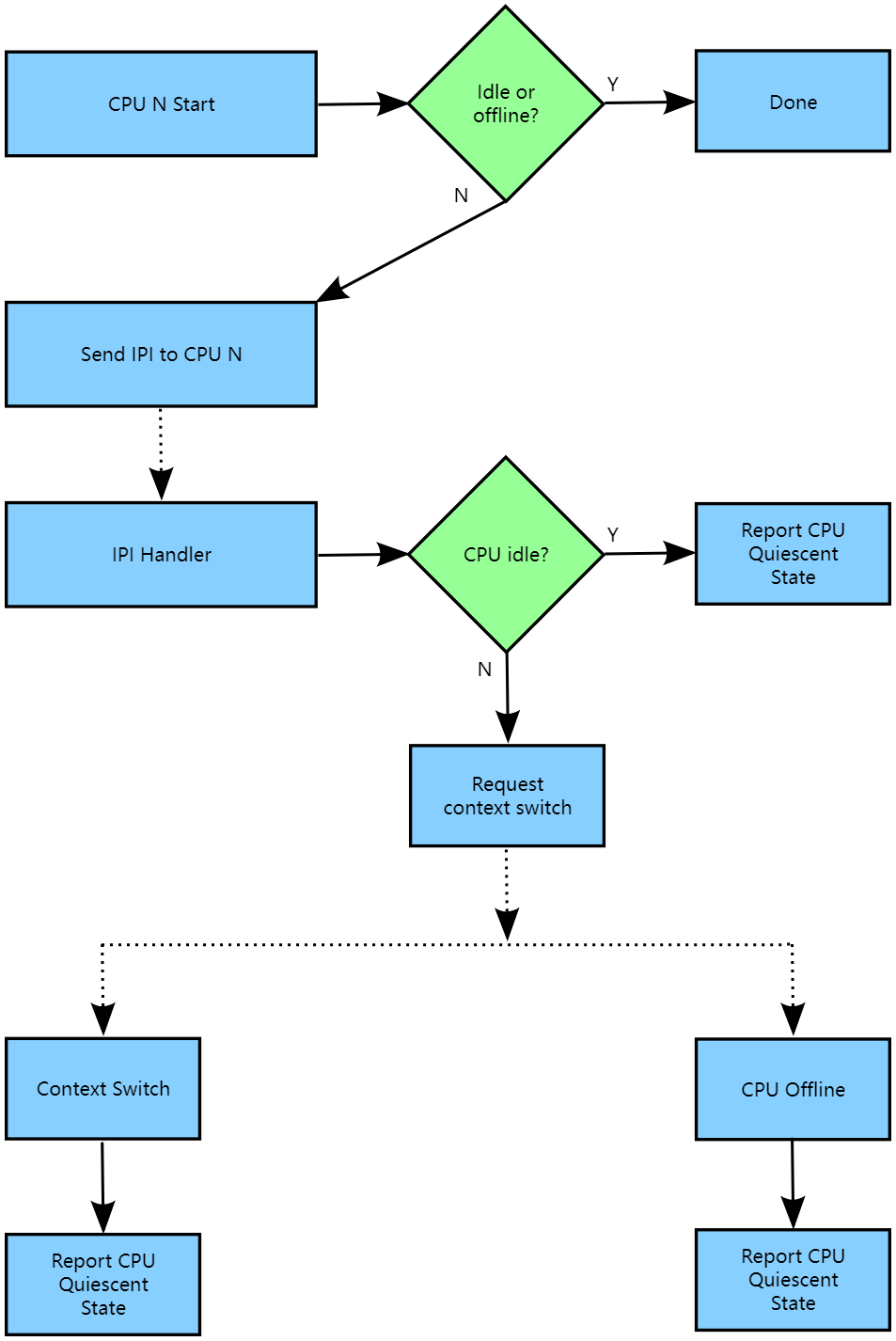
As with RCU-preempt, RCU-sched's synchronize_rcu_expedited() ignores offline and idle CPUs, again because they are in remotely detectable quiescent states. However, because the rcu_read_lock_sched() and rcu_read_unlock_sched() leave no trace of their invocation, in general it is not possible to tell whether or not the current CPU is in an RCU read-side critical section. The best that RCU-sched's rcu_exp_handler() can do is to check for idle, on the off-chance that the CPU went idle while the IPI was in flight. If the CPU is idle, then rcu_exp_handler() reports the quiescent state.
与RCU-preempt一样,RCU-sched的synchronize_rcu_expedited()忽略离线和空闲的CPU,因为它们处于远程可检测的静止状态。然而,由于rcu_read_lock_sched()和rcu_read_unlock_sched()没有留下它们调用的痕迹,通常无法确定当前CPU是否处于RCU读取侧临界区。RCU-sched的rcu_exp_handler()能做的最好的事情就是检查空闲状态,以防万一CPU在IPI飞行时变为空闲状态。如果CPU处于空闲状态,则rcu_exp_handler()报告静止状态。
Otherwise, the handler forces a future context switch by setting the NEED_RESCHED flag of the current task's thread flag and the CPU preempt counter. At the time of the context switch, the CPU reports the quiescent state. Should the CPU go offline first, it will report the quiescent state at that time.
否则,处理程序通过设置当前任务的线程标志和CPU抢占计数器的NEED_RESCHED标志来强制进行未来的上下文切换。在上下文切换时,CPU报告静止状态。如果CPU首先离线,它将在那时报告静止状态。
Expedited Grace Period and CPU Hotplug
加速宽限期需要与CPU热插拔
The expedited nature of expedited grace periods require a much tighter interaction with CPU hotplug operations than is required for normal grace periods. In addition, attempting to IPI offline CPUs will result in splats, but failing to IPI online CPUs can result in too-short grace periods. Neither option is acceptable in production kernels.
加速宽限期需要与CPU热插拔操作进行更紧密的交互,比正常宽限期所需的交互更紧密。此外,尝试IPI离线CPU将导致splats,但未能IPI在线CPU可能导致宽限期过短。在生产内核中,这两种选项都是不可接受的。
The interaction between expedited grace periods and CPU hotplug operations is carried out at several levels:
加速宽限期和CPU热插拔操作之间的交互在几个级别上进行:
-
The number of CPUs that have ever been online is tracked by the rcu_state structure's ->ncpus field. The rcu_state structure's ->ncpus_snap field tracks the number of CPUs that have ever been online at the beginning of an RCU expedited grace period. Note that this number never decreases, at least in the absence of a time machine.
rcu_state结构的->ncpus字段跟踪曾经在线的CPU数量。rcu_state结构的->ncpus_snap字段跟踪在RCU加速宽限期开始时曾经在线的CPU数量。请注意,这个数字永远不会减少,至少在没有时间机器的情况下是这样的。 -
The identities of the CPUs that have ever been online is tracked by the rcu_node structure's ->expmaskinitnext field. The rcu_node structure's ->expmaskinit field tracks the identities of the CPUs that were online at least once at the beginning of the most recent RCU expedited grace period. The rcu_state structure's ->ncpus and ->ncpus_snap fields are used to detect when new CPUs have come online for the first time, that is, when the rcu_node structure's ->expmaskinitnext field has changed since the beginning of the last RCU expedited grace period, which triggers an update of each rcu_node structure's ->expmaskinit field from its ->expmaskinitnext field.
rcu_node结构的->expmaskinitnext字段跟踪曾经在线的CPU的标识。rcu_node结构的->expmaskinit字段跟踪在最近的RCU加速宽限期开始时至少在线一次的CPU的标识。rcu_state结构的->ncpus和->ncpus_snap字段用于检测新CPU是否首次上线,即当rcu_node结构的->expmaskinitnext字段自上一个RCU加速宽限期开始以来发生了变化时,触发每个rcu_node结构的->expmaskinit字段从其->expmaskinitnext字段更新。 -
Each rcu_node structure's ->expmaskinit field is used to initialize that structure's ->expmask at the beginning of each RCU expedited grace period. This means that only those CPUs that have been online at least once will be considered for a given grace period.
每个rcu_node结构的->expmaskinit字段用于初始化该结构的->expmask。这意味着只有那些至少在线一次的CPU才会考虑给定的宽限期。 -
Any CPU that goes offline will clear its bit in its leaf rcu_node structure's ->qsmaskinitnext field, so any CPU with that bit clear can safely be ignored. However, it is possible for a CPU coming online or going offline to have this bit set for some time while cpu_online returns false.
任何离线的CPU都将清除其叶rcu_node结构的->qsmaskinitnext字段中的位,因此可以安全地忽略该位清除的任何CPU。但是,可能会出现CPU上线或离线时该位设置了一段时间,而cpu_online返回false。 -
For each non-idle CPU that RCU believes is currently online, the grace period invokes smp_call_function_single(). If this succeeds, the CPU was fully online. Failure indicates that the CPU is in the process of coming online or going offline, in which case it is necessary to wait for a short time period and try again. The purpose of this wait (or series of waits, as the case may be) is to permit a concurrent CPU-hotplug operation to complete.
对于RCU认为当前在线的每个非空闲CPU,宽限期调用smp_call_function_single()。如果这成功了,则CPU完全在线。失败表示CPU正在上线或离线的过程中,此时需要等待一段短时间并重试。这个等待(或一系列等待,视情况而定)的目的是允许并发的CPU热插拔操作完成。 -
In the case of RCU-sched, one of the last acts of an outgoing CPU is to invoke rcu_report_dead(), which reports a quiescent state for that CPU. However, this is likely paranoia-induced redundancy.
在RCU-sched的情况下,一个即将离开的CPU的最后一个行动之一是调用rcu_report_dead(),该函数报告该CPU的静止状态。然而,这很可能是由于偏执引起的冗余。
Quick Quiz:
Why all the dancing around with multiple counters and masks tracking CPUs that were once online? Why not just have a single set of masks tracking the currently online CPUs and be done with it?
为什么要在多个计数器和跟踪曾经在线的CPU的掩码之间跳来跳去呢?为什么不只使用一个集合的掩码来跟踪当前在线的CPU,然后就可以了呢?
Answer:
Maintaining single set of masks tracking the online CPUs sounds easier, at least until you try working out all the race conditions between grace-period initialization and CPU-hotplug operations. For example, suppose initialization is progressing down the tree while a CPU-offline operation is progressing up the tree. This situation can result in bits set at the top of the tree that have no counterparts at the bottom of the tree. Those bits will never be cleared, which will result in grace-period hangs. In short, that way lies madness, to say nothing of a great many bugs, hangs, and deadlocks. In contrast, the current multi-mask multi-counter scheme ensures that grace-period initialization will always see consistent masks up and down the tree, which brings significant simplifications over the single-mask method.
维护一个单一的集合来跟踪在线的CPU听起来更容易,至少在你尝试解决优雅期初始化和CPU热插拔操作之间的竞争条件时是这样。例如,假设初始化正在树的下方进行,而一个CPU离线操作正在树的上方进行。这种情况可能导致在树的顶部设置了没有对应的底部的位。这些位将永远不会被清除,这将导致优雅期挂起。简而言之,这条路通向疯狂,更不用说很多错误、挂起和死锁了。相比之下,当前的多掩码多计数器方案确保优雅期初始化始终能够看到树上下一致的掩码,这相对于单一掩码方法带来了显著的简化。
This is an instance of deferring work in order to avoid synchronization. Lazily recording CPU-hotplug events at the beginning of the next grace period greatly simplifies maintenance of the CPU-tracking bitmasks in the rcu_node tree.
这是为了避免同步而推迟工作的一种实例。在下一个优雅期开始时延迟记录CPU热插拔事件极大地简化了在rcu_node树中维护CPU跟踪位掩码的工作。
Expedited Grace Period Refinements
加速宽限期改进
Idle-CPU Checks
空闲CPU检查
Each expedited grace period checks for idle CPUs when initially forming the mask of CPUs to be IPIed and again just before IPIing a CPU (both checks are carried out by sync_rcu_exp_select_cpus()). If the CPU is idle at any time between those two times, the CPU will not be IPIed. Instead, the task pushing the grace period forward will include the idle CPUs in the mask passed to rcu_report_exp_cpu_mult().
每个加速宽限期在初始形成要IPI的CPU掩码时和在IPI CPU之前再次检查空闲CPU(两个检查都由sync_rcu_exp_select_cpus()执行)时都会检查空闲CPU。如果CPU在这两个时间之间的任何时间处于空闲状态,则不会IPI该CPU。相反,将推动宽限期向前的任务将在传递给rcu_report_exp_cpu_mult()的掩码中包括空闲CPU。
For RCU-sched, there is an additional check: If the IPI has interrupted the idle loop, then rcu_exp_handler() invokes rcu_report_exp_rdp() to report the corresponding quiescent state.
对于RCU-sched,还有一个额外的检查:如果IPI中断了空闲循环,则rcu_exp_handler()调用rcu_report_exp_rdp()报告相应的静止状态。
For RCU-preempt, there is no specific check for idle in the IPI handler (rcu_exp_handler()), but because RCU read-side critical sections are not permitted within the idle loop, if rcu_exp_handler() sees that the CPU is within RCU read-side critical section, the CPU cannot possibly be idle. Otherwise, rcu_exp_handler() invokes rcu_report_exp_rdp() to report the corresponding quiescent state, regardless of whether or not that quiescent state was due to the CPU being idle.
对于RCU-preempt,IPI处理程序(rcu_exp_handler())中没有特定的空闲检查,但由于在空闲循环中不允许RCU读侧临界区,因此如果rcu_exp_handler()看到CPU在RCU读侧临界区内,则CPU不可能处于空闲状态。否则,rcu_exp_handler()将调用rcu_report_exp_rdp()报告相应的静止状态,无论该静止状态是否由CPU处于空闲状态引起。
In summary, RCU expedited grace periods check for idle when building the bitmask of CPUs that must be IPIed, just before sending each IPI, and (either explicitly or implicitly) within the IPI handler.
总之,RCU加速宽限期在构建必须IPI的CPU位掩码时检查空闲,在发送每个IPI之前以及在IPI处理程序中(显式或隐式)检查空闲。
Batching via Sequence Counter
通过序列计数器进行批处理
If each grace-period request was carried out separately, expedited grace periods would have abysmal scalability and problematic high-load characteristics. Because each grace-period operation can serve an unlimited number of updates, it is important to batch requests, so that a single expedited grace-period operation will cover all requests in the corresponding batch.
如果每个宽限期请求都单独执行,加速宽限期将具有可怕的可扩展性和问题高负载特性。因为每个宽限期操作可以服务于无限数量的更新,所以批处理请求非常重要,以便单个加速宽限期操作将覆盖相应批次中的所有请求。
This batching is controlled by a sequence counter named ->expedited_sequence in the rcu_state structure. This counter has an odd value when there is an expedited grace period in progress and an even value otherwise, so that dividing the counter value by two gives the number of completed grace periods. During any given update request, the counter must transition from even to odd and then back to even, thus indicating that a grace period has elapsed. Therefore, if the initial value of the counter is s, the updater must wait until the counter reaches at least the value (s+3)&~0x1. This counter is managed by the following access functions:
这个批处理由rcu_state结构中的名为->expedited_sequence的序列计数器控制。当存在加速宽限期时,该计数器的值为奇数,否则为偶数,因此将计数器值除以2会给出已完成的宽限期数量。在任何给定的更新请求期间,计数器必须从偶数转换为奇数,然后再次转换为偶数,从而指示已经过了一个宽限期。因此,如果计数器的初始值为s,则更新程序必须等待计数器达到至少值(s+3)&~0x1。该计数器由以下访问函数管理:
-
rcu_exp_gp_seq_start(), which marks the start of an expedited grace period.
rcu_exp_gp_seq_start(),标记加速宽限期的开始 -
rcu_exp_gp_seq_end(), which marks the end of an expedited grace period.
rcu_exp_gp_seq_end(),标记加速宽限期的结束 -
rcu_exp_gp_seq_snap(), which obtains a snapshot of the counter.
rcu_exp_gp_seq_snap(),获取计数器的快照 -
rcu_exp_gp_seq_done(), which returns true if a full expedited grace period has elapsed since the corresponding call to rcu_exp_gp_seq_snap().
rcu_exp_gp_seq_done(),如果自相应调用rcu_exp_gp_seq_snap()以来已经过了完整的加速宽限期,则返回true
Again, only one request in a given batch need actually carry out a grace-period operation, which means there must be an efficient way to identify which of many concurrent requests will initiate the grace period, and that there be an efficient way for the remaining requests to wait for that grace period to complete. However, that is the topic of the next section.
同样,在给定批次中,只有一个请求实际上需要执行宽限期操作,这意味着必须有一种有效的方法来识别哪些并发请求将启动宽限期,并且必须有一种有效的方法让其余请求等待该宽限期完成。但是,这是下一节的主题。
Funnel Locking and Wait/Wakeup
漏斗锁定和等待/唤醒
The natural way to sort out which of a batch of updaters will initiate the expedited grace period is to use the rcu_node combining tree, as implemented by the exp_funnel_lock() function. The first updater corresponding to a given grace period arriving at a given rcu_node structure records its desired grace-period sequence number in the ->exp_seq_rq field and moves up to the next level in the tree. Otherwise, if the ->exp_seq_rq field already contains the sequence number for the desired grace period or some later one, the updater blocks on one of four wait queues in the ->exp_wq[] array, using the second-from-bottom and third-from bottom bits as an index. An ->exp_lock field in the rcu_node structure synchronizes access to these fields.
自然的方法来解决一批更新器中哪一个将启动加速宽限期的问题是使用rcu_node合并树,由exp_funnel_lock()函数实现。对于给定的宽限期,第一个对应的更新器到达给定的rcu_node结构,在->exp_seq_rq字段中记录其所需的宽限期序列号,并向树的下一级移动。否则,如果->exp_seq_rq字段已经包含所需宽限期或某个更晚的序列号,更新器将在->exp_wq[]数组中的四个等待队列之一上阻塞,使用第二个和第三个从底部开始的位作为索引。rcu_node结构中的->exp_lock字段同步访问这些字段。
An empty rcu_node tree is shown in the following diagram, with the white cells representing the ->exp_seq_rq field and the red cells representing the elements of the ->exp_wq[] array.
下面的图示展示了一个空的rcu_node树,其中白色单元格表示->exp_seq_rq字段,红色单元格表示->exp_wq[]数组的元素。
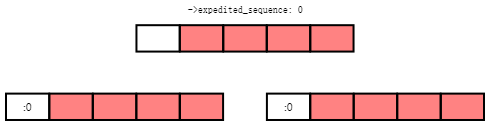
The next diagram shows the situation after the arrival of Task A and Task B at the leftmost and rightmost leaf rcu_node structures, respectively. The current value of the rcu_state structure's ->expedited_sequence field is zero, so adding three and clearing the bottom bit results in the value two, which both tasks record in the ->exp_seq_rq field of their respective rcu_node structures:
下一个图示展示了任务A和任务B到达最左边和最右边的叶子rcu_node结构后的情况。rcu_state结构的->expedited_sequence字段的当前值为零,因此将其加三并清除底部位将得到值二,这两个任务都将其记录在其各自的rcu_node结构的->exp_seq_rq字段中:
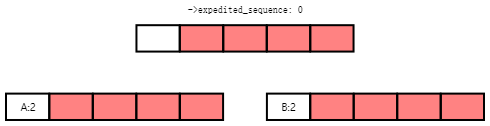
Each of Tasks A and B will move up to the root rcu_node structure. Suppose that Task A wins, recording its desired grace-period sequence number and resulting in the state shown below:
任务A和任务B中的每一个都将向上移动到根rcu_node结构。假设任务A获胜,记录其所需的宽限期序列号,并导致状态如下所示:
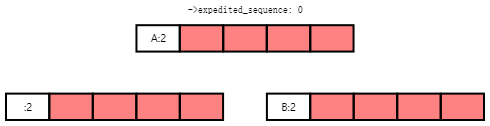
Task A now advances to initiate a new grace period, while Task B moves up to the root rcu_node structure, and, seeing that its desired sequence number is already recorded, blocks on ->exp_wq[1].
现在,任务A将前进以启动新的宽限期,而任务B将向上移动到根rcu_node结构,并看到其所需的序列号已经记录,因此在->exp_wq[1]上阻塞。
Quick Quiz:
Why ->exp_wq[1]? Given that the value of these tasks' desired sequence number is two, so shouldn't they instead block on ->exp_wq[2]?
为什么是->exp_wq[1]?考虑到这些任务所需的序列号的值为2,所以它们不应该阻塞在->exp_wq[2]上吗?
Answer:
No. Recall that the bottom bit of the desired sequence number indicates whether or not a grace period is currently in progress. It is therefore necessary to shift the sequence number right one bit position to obtain the number of the grace period. This results in ->exp_wq[1].
不是。请记住,所需序列号的底部位指示当前是否正在进行宽限期。因此,需要将序列号向右移动一位,以获取宽限期的编号。这将导致->exp_wq[1]。
If Tasks C and D also arrive at this point, they will compute the same desired grace-period sequence number, and see that both leaf rcu_node structures already have that value recorded. They will therefore block on their respective rcu_node structures' ->exp_wq[1] fields, as shown below:
如果此时任务C和任务D也到达,则它们将计算相同的所需宽限期序列号,并看到两个叶子rcu_node结构已经记录了该值。因此,它们将在各自的rcu_node结构的->exp_wq[1]字段上阻塞,如下所示:
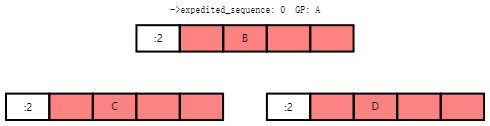
Task A now acquires the rcu_state structure's ->exp_mutex and initiates the grace period, which increments ->expedited_sequence. Therefore, if Tasks E and F arrive, they will compute a desired sequence number of 4 and will record this value as shown below:
现在,任务A获取rcu_state结构的->exp_mutex并启动宽限期,该宽限期增加->expedited_sequence。因此,如果任务E和任务F到达,则它们将计算所需的序列号为4,并将此值记录如下所示:
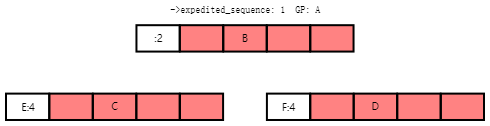
Tasks E and F will propagate up the rcu_node combining tree, with Task F blocking on the root rcu_node structure and Task E wait for Task A to finish so that it can start the next grace period. The resulting state is as shown below:
任务E和任务F将向上传播rcu_node合并树,任务F将在根rcu_node结构上阻塞,而任务E则等待任务A完成,以便它可以开始下一个宽限期。结果状态如下所示:
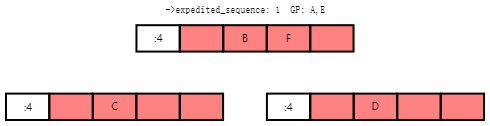
Once the grace period completes, Task A starts waking up the tasks waiting for this grace period to complete, increments the ->expedited_sequence, acquires the ->exp_wake_mutex and then releases the ->exp_mutex. This results in the following state:
一旦宽限期完成,任务A开始唤醒等待此宽限期完成的任务,增加->expedited_sequence,获取->exp_wake_mutex,然后释放->exp_mutex。这将导致以下状态:
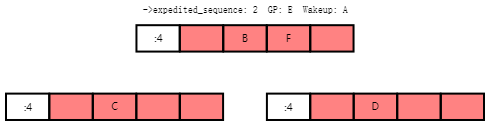
Task E can then acquire ->exp_mutex and increment ->expedited_sequence to the value three. If new tasks G and H arrive and moves up the combining tree at the same time, the state will be as follows:
任务E现在可以获取->exp_mutex并将->expedited_sequence增加到值三。如果新的任务G和任务H同时到达并向上移动合并树,则状态将如下所示:
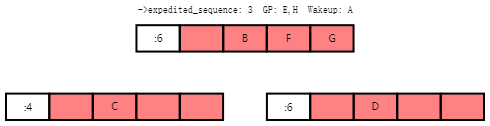
Note that three of the root rcu_node structure's waitqueues are now occupied. However, at some point, Task A will wake up the tasks blocked on the ->exp_wq waitqueues, resulting in the following state:
请注意,根rcu_node结构的三个等待队列现在都被占用。但是,某个时刻,任务A将唤醒阻塞在->exp_wq等待队列上的任务,导致以下状态:
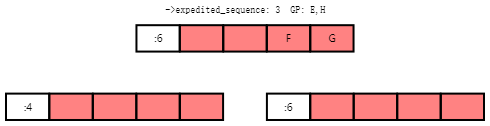
Execution will continue with Tasks E and H completing their grace periods and carrying out their wakeups.
执行将继续,任务E和任务H完成其宽限期并执行唤醒。
Quick Quiz:
What happens if Task A takes so long to do its wakeups that Task E's grace period completes?
如果任务A花费太长时间来执行唤醒,任务E的宽限期会发生什么?
Answer:
Then Task E will block on the ->exp_wake_mutex, which will also prevent it from releasing ->exp_mutex, which in turn will prevent the next grace period from starting. This last is important in preventing overflow of the ->exp_wq[] array.
然后,任务E将在->exp_wake_mutex上阻塞,这也将防止它释放->exp_mutex,从而防止下一个宽限期的开始。这最后一点很重要,以防止->exp_wq[]数组溢出。
Use of Workqueues
使用工作队列
In earlier implementations, the task requesting the expedited grace period also drove it to completion. This straightforward approach had the disadvantage of needing to account for POSIX signals sent to user tasks, so more recent implementations use the Linux kernel's workqueues (see Workqueue).
在早期的实现中,请求加速宽限期的任务也会驱动其完成。这种直接的方法的缺点是需要考虑发送给用户任务的POSIX信号,因此较新的实现使用Linux内核的工作队列(参见工作队列)。
The requesting task still does counter snapshotting and funnel-lock processing, but the task reaching the top of the funnel lock does a schedule_work() (from _synchronize_rcu_expedited() so that a workqueue kthread does the actual grace-period processing. Because workqueue kthreads do not accept POSIX signals, grace-period-wait processing need not allow for POSIX signals. In addition, this approach allows wakeups for the previous expedited grace period to be overlapped with processing for the next expedited grace period. Because there are only four sets of waitqueues, it is necessary to ensure that the previous grace period's wakeups complete before the next grace period's wakeups start. This is handled by having the ->exp_mutex guard expedited grace-period processing and the ->exp_wake_mutex guard wakeups. The key point is that the ->exp_mutex is not released until the first wakeup is complete, which means that the ->exp_wake_mutex has already been acquired at that point. This approach ensures that the previous grace period's wakeups can be carried out while the current grace period is in process, but that these wakeups will complete before the next grace period starts. This means that only three waitqueues are required, guaranteeing that the four that are provided are sufficient.
请求任务仍然进行计数器快照和漏斗锁处理,但是到达漏斗锁顶部的任务会执行schedule_work()(来自_synchronize_rcu_expedited()),这样工作队列的内核线程就会执行实际的宽限期处理。由于工作队列的内核线程不接受POSIX信号,宽限期等待处理不需要考虑POSIX信号。此外,这种方法允许前一个加速宽限期的唤醒与下一个加速宽限期的处理重叠。由于只有四组等待队列,必须确保前一个宽限期的唤醒在下一个宽限期的唤醒开始之前完成。这通过使用->exp_mutex保护加速宽限期处理和->exp_wake_mutex保护唤醒来处理。关键点是,直到第一个唤醒完成,->exp_mutex才会被释放,这意味着在那一点上->exp_wake_mutex已经被获取。这种方法确保了在当前宽限期处理过程中可以执行前一个宽限期的唤醒,但是这些唤醒将在下一个宽限期开始之前完成。这意味着只需要三个等待队列,确保提供的四个队列足够使用。
Stall Warnings
停滞警告
Expediting grace periods does nothing to speed things up when RCU readers take too long, and therefore expedited grace periods check for stalls just as normal grace periods do.
当RCU读者花费过长时间时,加速宽限期无法加快速度,因此加速宽限期和普通宽限期一样会检查停滞情况。
Quick Quiz:
But why not just let the normal grace-period machinery detect the stalls, given that a given reader must block both normal and expedited grace periods?
但是,为什么不让普通宽限期机制检测停滞,考虑到给定的读者必须同时阻塞普通和加速宽限期?
Answer:
Because it is quite possible that at a given time there is no normal grace period in progress, in which case the normal grace period cannot emit a stall warning.
因为在某个时间点上很可能没有正在进行的普通宽限期,这种情况下普通宽限期无法发出停滞警告。
The synchronize_sched_expedited_wait() function loops waiting for the expedited grace period to end, but with a timeout set to the current RCU CPU stall-warning time. If this time is exceeded, any CPUs or rcu_node structures blocking the current grace period are printed. Each stall warning results in another pass through the loop, but the second and subsequent passes use longer stall times.
synchronize_sched_expedited_wait()函数循环等待加速宽限期结束,但是设置了当前RCU CPU停滞警告时间的超时。如果超过了这个时间,将打印出阻塞当前宽限期的任何CPU或rcu_node结构。每个停滞警告都会导致循环再次执行,但是第二次和后续的执行会使用更长的停滞时间。
Mid-boot operation
启动中的操作
The use of workqueues has the advantage that the expedited grace-period code need not worry about POSIX signals. Unfortunately, it has the corresponding disadvantage that workqueues cannot be used until they are initialized, which does not happen until some time after the scheduler spawns the first task. Given that there are parts of the kernel that really do want to execute grace periods during this mid-boot “dead zone”, expedited grace periods must do something else during this time.
使用工作队列的优点是加速宽限期代码不需要考虑POSIX信号。不幸的是,它的相应缺点是在初始化之前无法使用工作队列,而初始化在调度程序生成第一个任务之后的一段时间才会发生。鉴于内核中确实有一些部分希望在这个启动中的“死区”期间执行宽限期,加速宽限期在此期间必须执行其他操作。
What they do is to fall back to the old practice of requiring that the requesting task drive the expedited grace period, as was the case before the use of workqueues. However, the requesting task is only required to drive the grace period during the mid-boot dead zone. Before mid-boot, a synchronous grace period is a no-op. Some time after mid-boot, workqueues are used.
它们所做的是回退到使用工作队列之前的旧做法,要求请求任务驱动加速宽限期,就像在使用工作队列之前的情况一样。然而,只有在启动中的死区期间,才需要请求任务驱动宽限期。在启动之前,同步宽限期是一个空操作。在启动后的一段时间之后,开始使用工作队列。
Non-expedited non-SRCU synchronous grace periods must also operate normally during mid-boot. This is handled by causing non-expedited grace periods to take the expedited code path during mid-boot.
非加速的非SRCU同步宽限期在启动期间也必须正常运行。这通过在启动期间使非加速宽限期采用加速代码路径来处理。
The current code assumes that there are no POSIX signals during the mid-boot dead zone. However, if an overwhelming need for POSIX signals somehow arises, appropriate adjustments can be made to the expedited stall-warning code. One such adjustment would reinstate the pre-workqueue stall-warning checks, but only during the mid-boot dead zone.
当前代码假设在启动中的死区期间没有POSIX信号。然而,如果出现对POSIX信号的压倒性需求,可以对加速停滞警告代码进行适当调整。这样的调整将恢复工作队列之前的停滞警告检查,但仅在启动中的死区期间进行。
With this refinement, synchronous grace periods can now be used from task context pretty much any time during the life of the kernel. That is, aside from some points in the suspend, hibernate, or shutdown code path.
通过这种改进,同步宽限期现在可以在内核的生命周期中的任何时间从任务上下文中使用。也就是说,除了在挂起、休眠或关机代码路径中的某些点。
Summary
总结
Expedited grace periods use a sequence-number approach to promote batching, so that a single grace-period operation can serve numerous requests. A funnel lock is used to efficiently identify the one task out of a concurrent group that will request the grace period. All members of the group will block on waitqueues provided in the rcu_node structure. The actual grace-period processing is carried out by a workqueue.
加速宽限期使用序列号方法来促进批处理,以便单个宽限期操作可以服务多个请求。漏斗锁用于高效地识别并发组中的一个任务,该任务将请求宽限期。组中的所有成员都将阻塞在rcu_node结构中提供的等待队列上。实际的宽限期处理由工作队列执行。
CPU-hotplug operations are noted lazily in order to prevent the need for tight synchronization between expedited grace periods and CPU-hotplug operations. The dyntick-idle counters are used to avoid sending IPIs to idle CPUs, at least in the common case. RCU-preempt and RCU-sched use different IPI handlers and different code to respond to the state changes carried out by those handlers, but otherwise use common code.
CPU热插拔操作被延迟通知,以避免加速宽限期和CPU热插拔操作之间需要紧密同步。动态节拍空闲计数器用于避免向空闲CPU发送IPI,至少在常见情况下是如此。RCU-preempt和RCU-sched使用不同的IPI处理程序和不同的代码来响应这些处理程序执行的状态更改,但是其他方面使用相同的代码。
Quiescent states are tracked using the rcu_node tree, and once all necessary quiescent states have been reported, all tasks waiting on this expedited grace period are awakened. A pair of mutexes are used to allow one grace period's wakeups to proceed concurrently with the next grace period's processing.
通过rcu_node树跟踪静止状态,一旦报告了所有必要的静止状态,就会唤醒等待此加速宽限期的所有任务。一对互斥锁用于允许一个宽限期的唤醒与下一个宽限期的处理并发进行。
This combination of mechanisms allows expedited grace periods to run reasonably efficiently. However, for non-time-critical tasks, normal grace periods should be used instead because their longer duration permits much higher degrees of batching, and thus much lower per-request overheads.
这些机制的组合使得加速宽限期可以运行得相当高效。然而,对于非时间关键的任务,应该使用普通宽限期,因为它们较长的持续时间允许更高程度的批处理,从而降低每个请求的开销。