Pre
title: Diffusion Models Beat GANs on Image Synthesis
accepted: NeurIPS 2021
paper: https://arxiv.org/abs/2105.05233
code: https://github.com/openai/guided-diffusion
ref: https://sunlin-ai.github.io/2022/05/30/guided-diffusion.html
ref: https://blog.csdn.net/NGUever15/article/details/128269098
ref: https://zhuanlan.zhihu.com/p/376669628
关键词:image synthesis, diffusion models, classifier guidance
阅读理由:看看GAN跟扩散模型的差距,试图找一些图像合成上的idea
Target
目前 GANs 在大部分的图像生成任务上取得 SOTA,衡量指标通常为 FID,Inception Score 和 Precision,然而其中部分指标无法很好地体现多样性,GAN的生成多样性不如likelihood-based 模型,同时它难训练,没有合适的超参数或正则很容易坍塌 。
同时GAN难以缩放scale/应用到新的domain上,而 likelihood-based 模型生成结果多样、能scale且训练简单,但生成质量不如GAN,且采样速度慢。
扩散模型也是一类 likelihood-based 模型,且具备distribution coverage(分布覆盖率?应该是指生成结果多样)、静态训练目标(stationary training objective)、易扩展(easy scalability)的优点,在CIFAR-10能取得SOTA,而困难点的数据如LSUN和ImageNet则不如GAN。作者认为这种差距来自以下两点:
- GAN的架构已被充分地探索研究
- GAN能够权衡多样性跟真实性(fidelity),用分布上的不完全覆盖来换取更高的生成质量
因此本文将以上两点加入扩散模型中,便取得了SOTA,超越了GAN
Idea
以DDPM为基础,通过实验得到最优的架构,然后加入分类器引导(Classifier Guidance)给予扩散模型条件生成能力。
Background
粗略介绍扩散模型,详细公式推导看附录B。不过看这个入门也不大现实,私以为annotated-diffusion应该是更好的选择
提到后文的噪声\(\epsilon\)均来自 diagonal Gaussian distribution,这适合自然图片且简化了各种推导过程(derivations)
Improvements
Nichol and Dhariwal(《Improved denoising diffusion probabilistic models》)发现DDPM中固定方差在扩散步骤较少的时候是一个次优的方案,并且提出了参数化方差:
其中\(v\)是神经网络的输出,两个\(\beta\)是DDPM的用到的方差。
此外,Nichol and Dhariwal还提出了一个加权目标函数,混合训练两个模型(\(\epsilon_{\theta}(x_{t},t),\; \Sigma_{\theta}(x_{t},t)\))。用混合目标学习反向过程的方差可以采用更少的采样步骤,且样本质量不会过度下降。本文采用了这个目标函数。
DDIM 制定了一个替代的非马尔可夫噪声过程,具有与DDPM相同的forward marginals,但允许通过改变反向噪声的方差产生不同的反向采样器。通过将该噪声设置为0,他们提供了一种方法,将任何模型转换为从latents到图片的确定性映射,并发现这提供了一种步骤更少的采样替代方法。当采样步骤小于50,就用这种采样方法,Nichol and Dhariwal发现它是有效的。
Architecture Improvements
以DDPM的UNet架构为基础,本文探索了如下架构改进方案:
- 相对于宽度(通道多),增加模型的深度(堆叠的block多),并保持模型大小不变(因此需适当减少宽度)
- 增加 attention heads 的数量
- 在 32×32, 16×16 和 8×8 分辨率上使用 attention
- 使用 BigGAN 的残差块进行上采样和下采样
- 对残差连接使用 \(\frac{1}{\sqrt{2}}\) 因子缩放
本节实验batch size为256,共250个采样步骤

表1 在700K、1200K iterations 时各种架构变化消融

表2 各种注意力设置的消融。更多的head、每个head更少的通道都有助于减少FID

图2 各种架构变化消融,效率起见在10k样本上计算FID而非50k

表3 消融将timestep和类嵌入投影到每个残差块时使用的逐元素操作,把AdaGN换掉会增大FID
可以看到表1中除了调节(rescaling)残差连接外,其余修改都有积极作用。看图2左半部分,蓝色的线是更浅更深的模型,通道少堆叠的残差块时多,虽有助于改善效果(helps performance),但增加了训练时间而且要花更久才能有宽模型的效果,因此不采用。
也研究了更匹配Transformer架构的注意力设置,尝试固定head数量或者固定每个head的通道数量。架构的其余部分,使用128基础通道,每个分辨率2个残差块,多分辨率注意力,BigGAN的上下采样,训练700k轮。
如表2所示,更多的head或每个head更少的通道都能降低FID。图2可以看到,考虑现实世界的时间(wall-clock time),64个通道最合适,这符合现代Transformer架构,并在最终FID方面与其他配置相同(on par with)。
Dataset
ImageNet 128×128
Metrics
- Inception Score (IS) : 它衡量一个模型覆盖ImageNet分布的程度,并且产生的单个样本是否符合ImageNet其中某个类。这个指标的一个缺点是,它不能覆盖整个分布或捕获类内的多样性。而且一个模型如果只记住完整数据集的一个子集,仍然具有较高的分数。
- FID: 提供了Inception-V3潜空间中两个图像分布之间距离的对称度量,比IS更符合人的感知。
- sFID: 使用空间特征而不是标准池化特征的FID版本,可以更好地捕捉空间关系,获得(rewarding)连贯高层结构的图像分布。
- Improved Precision and Recall,以分别测量样本真实性(作为落入数据流形manifold的模型样本比例(精度))和多样性(作为落入样本流形manifold的数据样本比例)(召回)
用FID作为总体样本质量比较的默认度量,因为它同时捕捉多样性和真实性,并且是SOTA generative modeling work 的事实标准度量。使用精度或IS来测量真实性,使用召回率来测量多样性或分布覆盖率。
Adaptive Group Normalization

几种Norm的比较
实验了Nichol and Dhariwal论文中的一个层,称之为AdaGN(adaptive group normalizatio),它在group normalization 之后,将 timestep 和 class embedding 加进每个残差块,类似于AdaIN跟FiLM。将该层定义为 \(AdaGN(h,y)=y_s GroupNorm(h)+y_b\),其中h表示残差块第一个卷积后的激活函数,\(y=[y_s,y_b]\) 由 timestep 和 class embedding 线性投影而来。
表3验证了AdaGN的有效性,两个模型都使用128基础通道,每个分辨率2个残差块,每个head里64通道的多分辨率注意力,BigGAN的上下采样,训练700k轮。
在本文的其余部分中,我们使用这个最终改进的模型架构:可变宽度,每个分辨率有2个残差块,多个head,每个head里64通道,在32、16、8分辨率层使用注意力,用BigGAN残差块进行上采样和下采样的,以及用AdaGN将时间步长和类嵌入注入残差块中。
Classifier Guidance
作者认为在 conditional image synthesis 上,GAN大量利用了类别标签,这是它生成结果质量高的原因。前面已经用AdaGN将类别信息注入扩散模型,但这里给出了另一种方式:使用不同时步的噪声图像\(x_t\)训练一个分类器\(p_{\phi}(y\mid x_t,t)\),之后使用分类器对\(x_t\)的梯度信息\(\nabla_{x_t} \log p_{\phi}({x_t} \mid {y})\)指导预训练扩散模型对任意类别\(y\)的采样过程。
这部分涉及扩散模型的一系列公式推导,不大懂,暂时也用不上,不打算细究。

算法1、2 分别对应下面两个小节,是分类器引导的两种细分方法
Conditional Reverse Noising Process
首先原本无条件的扩散模型(降噪过程)可以表示为\(p\left(x_{t} \mid x_{t+1}\right)\),它根据\(x_{t+1}\)推出\(x_t\)。那么加入条件\(y\)的模型可以记为\(p\left(x_{t} \mid x_{t+1}, y\right)\),推导如下:
由于类别\(y\)跟\(x_{t+1}\)无关,大概可以理解为\(x_{t+1}\)是\(x_t\)加噪声来的,而噪声不包含信息,对于得出\(y\)没有帮助,因此:
因此带入上面\(p\left(x_{t} \mid x_{t+1}, y\right)\)的推导:
又因为每个样本的类别\(y\)已知,因此\(p(y \mid x_{t+1})\)可看作常数,将它记为\(Z\)带入上式便得到论文中的公式2:
作者说\(Z\)是标准化常数,难以准确从分布中采样,但可近似为扰动高斯分布(perturbed Gaussian distribution)。下面就是分别推导公式2右侧的两个非常数项。
扩散模型使用高斯分布根据\(x_{t+1}\)预测\(x_t\):
当扩散时间步无限时,\(\|\Sigma\| \rightarrow 0\),可以假设\(\log_{\phi} p(y\mid x_{t})\)曲率比\(\Sigma^{-1}\)更低,因此可以对它在\(x_{t}=\mu\)处进行泰勒展开:
其中\(g=\left. \nabla_{x_{t}} \log p_{\phi}\left(y \mid x_{t}\right)\right|_{x_{t}=\mu}\),且\(C_1\)为常数。综上,公式2取对数近似看作:
上式四行分别记作公式7~10,可以看出给原本的无条件模型加上条件后仍然近似一个高斯分布,只是这时需要给均值加上一个偏移量\(\Sigma g\),见上面的算法1,实际用的时候会给梯度g添加一个算法因子\(s\)
该方法看起来是扩散模型预测分布的均值跟方差,用分类器修正均值后直接采样得到上一时间步的样本
Conditional Sampling for DDIM
上述推导的条件采样仅适用于随机扩散采样过程(stochastic diffusion sampling process),不适合DDIM那样的确定性采样方法(deterministic sampling method),为此这里吸纳了前人基于分数的条件调节技巧(score-based conditioning trick)。给定一个模型\(\epsilon_{\theta}\left(x_t\right)\),它预测加入样本里的噪声,可推导出一个得分函数:
这玩意其实没看懂,主要是不知道\(p_\theta\)是干嘛的,感觉用于表示整个生成模型,此时没有条件,能够生成样本\(x\)。那么根据贝叶斯公式,条件生成模型就可以表示为:
两边同时对x求导有:
那么当加入类别y之后也会有一个得分函数:
参照公式11,可以用得分函数来表示模型预测的噪声:\(\epsilon_{\theta}\left(x_{t}\right) = -\sqrt{1-\bar{\alpha}_t} \nabla_{x_{t}} \log p_{\theta}\left(x_{t}\right)\)。那么同样给公式13两边乘上一项\(\sqrt{1-\bar{\alpha}_t}\),可以定义一个新噪声:
那么就可以将公式14的新噪声带入 DDIM 的常规采样流程,具体做法见算法2。该方法看起来是扩散模型预测给定样本在上一时间步到当前时间步所添加的噪声,用分类器修正该噪声,并通过去除该噪声得到上一时间步的样本。
Scaling Classifier Gradients

图3 给无条件扩散模型添加分类器引导(classfier guidance)后,条件“Pembroke Welsh Corgi”下生成的样本。左图使用1.0的分类器因子,FID:33.0,并不符合该类别;而右图使用10.0的分类器因子,FID:12.0,生成结果与类别更一致。
分类模型在ImageNet上训练,分类器网络使用 UNet 模型的下采样部分, 在 8x8 特征层上使用 attention pool 产生最后的输出。
分类器使用跟相应扩散模型一样的噪声分布进行训练,并添加随机裁剪(random crops)以减少过拟合。训练完后,根据公式10(算法1)加进扩散模型的采样过程生成样本。
在实验中,作者发现分类器梯度需要乘以一个大于1的常数因子,记为\(s\),如果\(s=1\),分类器会赋予期望的类 约50% 的概率生成最后的样本,但生成的样本看起来并不符合预期的类别;如果提高\(s\),可以让分类器的类别概率提高到将近100%,图3显示了这个效果。
为了探究\(s\)的作用,可记\(s\cdot \nabla_x \log p(y \mid x)=\nabla_x \log \frac{1}{Z}p(y\mid x)^s\),其中\(Z\)是任意常数。当\(s>1\),分布\(p(y \mid x)^s\)会更加陡峭,相当于更重视分类器,生成的样本更真实但不那么多样。

表4 classfier guidance对样本质量的影响。两种模型都训练了2M轮次,使用ImageNet 256x256,batchsize=256

图4 改变分类器梯度因子对样本质量的改变,基于具有类别条件的ImageNet 128x128模型
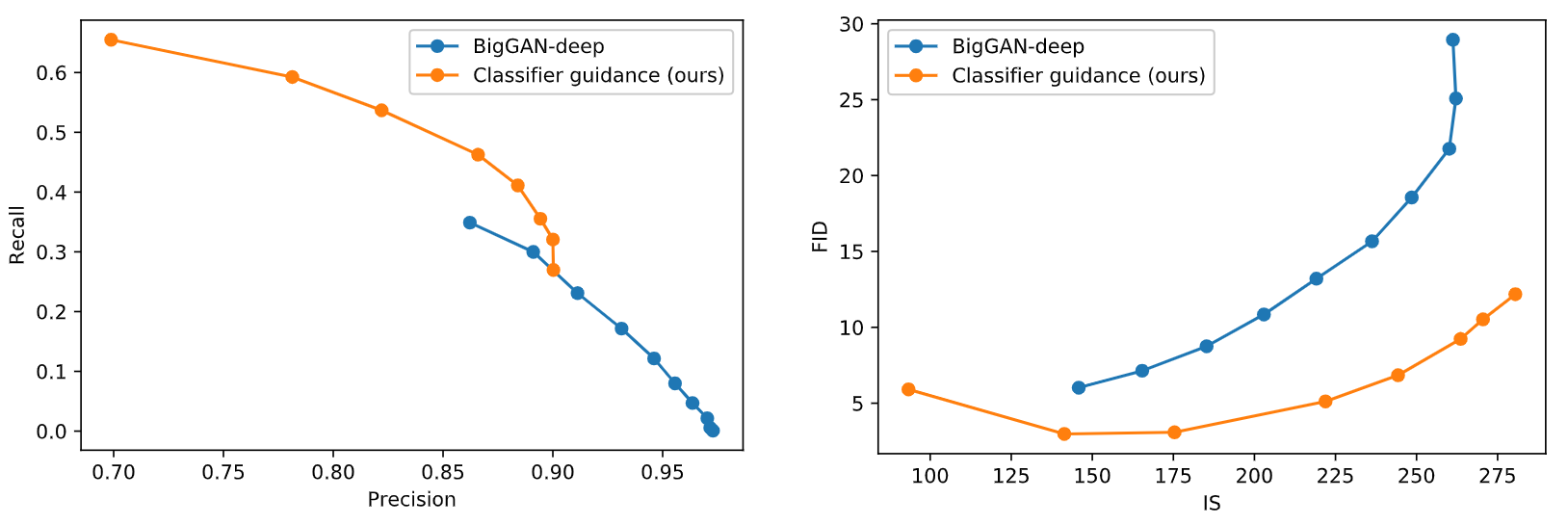
图5 改变BigGAN-deep的截断阈值(truncation)跟分类器梯度因子的平衡变化。模型用ImageNet 128x128评估。BigGAN-deep结果用的是TFHub的模型,分别尝试[0.1, 0.2, 0.3,..., 1.0]的截断级别。
上面的推导基于使用无条件扩散模型的假设,实际上条件扩散模型也能以完全一样的方式使用分类器引导。表4表明这两种模型的样本质量都可以用分类器引导极大提升,更大的\(s\)会引导无条件模型得到接近无引导的条件模型的FID值,而训练时直接加入类别标签仍然有帮助。
表4展示了分类器引导将以召回率的代价提升精度,因此需要权衡真实性跟多样性。图4是\(s\)变化对指标的影响,recall可看作多样性,而IS看作真实性,由于FID同时取决于多样跟真实,因此最小值在中间取到。图5则比较分类器引导跟BigGAN-deep的截断技巧,可看到分类器引导更擅长平衡FID跟IS(右图),然而精度跟召回率的平衡比较则不大明确(左图),分类器引导只有在某个精度阈值之前才是好选择,无法取得比阈值更高的精度。
Results
在无条件图像生成方面评估改进的模型架构,使用数据集 LSUN(bedroom, horse 和 cat)分别训练三个扩散模型,评估 classifier guidance 性能使用数据集 ImageNet (分辨率分别为 128×128, 256×256 和 512×512)训练条件扩散模型。
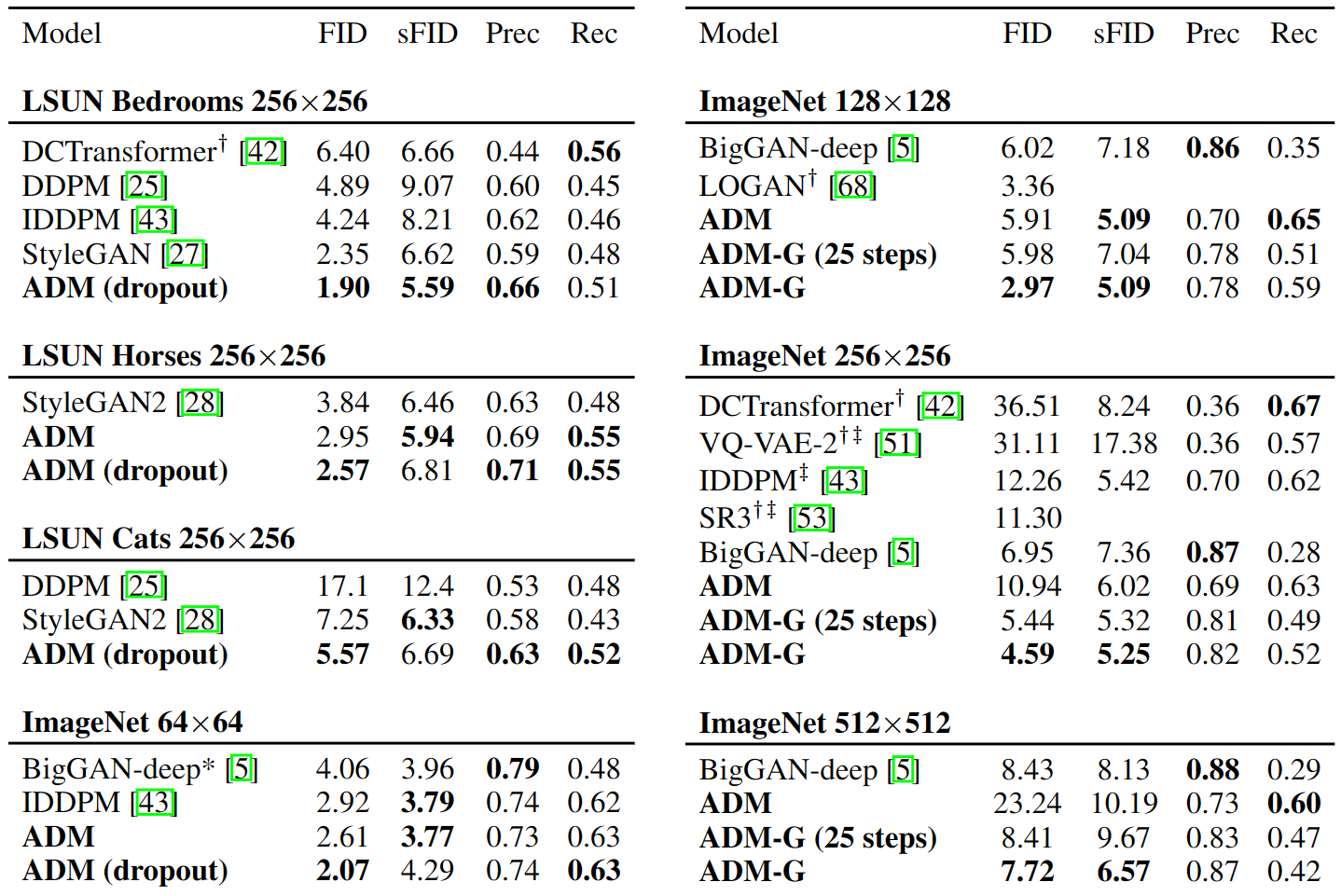
表5 每个任务上跟SOTA生成模型比较样本质量。ADM指本文的"**a**blated **d**iffusion **m**ode",ADM-G则额外用了classifier **g**uidance。LSUN扩散模型使用1000步采样,ImageNet扩散模型使用250步采样,除了显式标出的、使用DDIm采样器时只需25步。*标识的BigGAN-deep没有该分辨率现成的权重,作者自行训练而来。†标识的值来自之前的论文,因为缺少公开模型或样本(无法测试)。‡标识的值使用 two-resolution stacks 而来

图6 左边是BigGAN-deep的样本,截断阈值1.0(FID 6.95),中间是本文有引导的扩散模型(FID 4.59),右边则是训练集的样本。
State-of-the-art Image Synthesis
总之看图5,本文的模型基本都达到SOTA,这些模型都能达到跟GAN类似的感知质量,同时根据recall结果,能覆盖更多的分布,甚至只需要25个扩散步就能达成。
图6可以看出扩散模型比GAN的结果包含更多的模式(更多样),如远近不同的鸵鸟头、单只的火烈鸟、不同朝向的芝士汉堡跟不是人托着的丁鱥。
Comparison to Upsampling
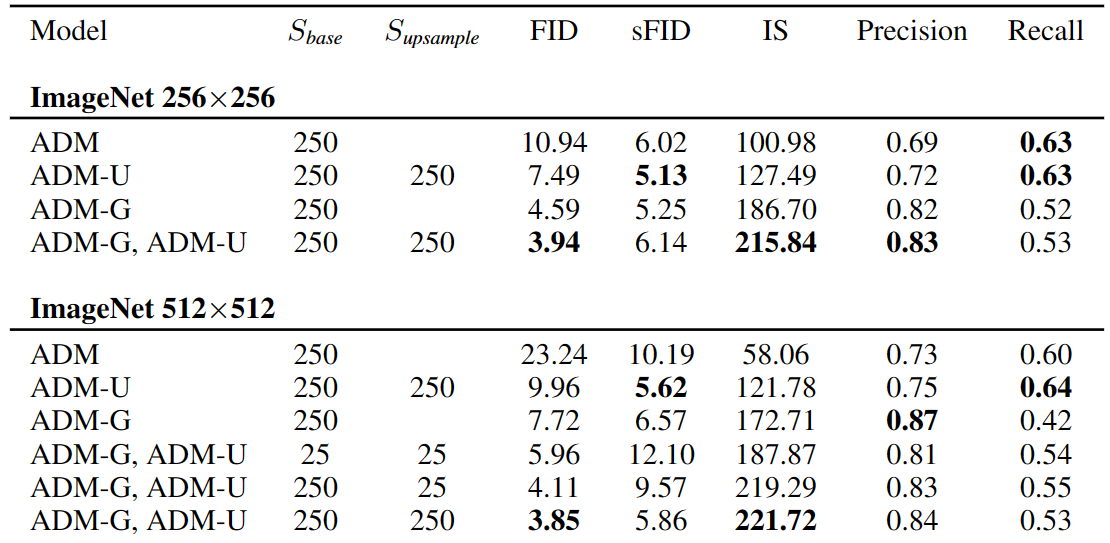
表6 ADM-U是本文改进后的架构结合 **u**psampling stack,二阶段上采样模型的两个基础分辨率分别是64、128。当上采样结合分类器引导,仅引导低分辨率模型。
如表5所示,IDDPM跟SR3是两阶段的扩散模型,先由低分辨率模型生成样本,再送入上采样模型增大分辨率,这极大降低了ImageNet 256x256上面的FID,但还是达不到SOTA。
表6可以看出两种方式会在不同的轴(axes)上提高样本质量,upsampling提高精度的同时会保留较高的召回率,而引导方式会为了更高的精度舍弃一些多样性。最佳FID是两种技巧一起用,在上采样前的低分辨率模型上用分类器引导,说明两种方法能够相得益彰。
Conclusion
总之展示了扩散模型可以比SOTA GAN有更好的采样质量,本文的改进架构足以在无条件图片生成任务上达到这一点,分类器引导技术使得在类别条件任务上也能SOTA。后面发现分类器梯度的缩放可以用于平衡多样性跟真实性。
这些引导的扩散模型能够减少跟GAN的采样时间差距,但采样仍需要多个前向步骤。最后将引导与上采样结合,进一步在高分辨率条件图片合成任务上改进了采样质量。
限制方面,一个是采样仍比GAN慢,这方面有《Knowledge distillation in iterative generative models for improved sampling speed》希望通过蒸馏将DDIM采样过程简化为一步,虽然性能比不上GAN,但比之前的单步likelihood-based模型好了不少。将来该方向的任务可能是完全追平GAN的速度,同时不牺牲图片质量。
另一个是分类器引导目前仅限于标记的数据集,并且无法权衡未标记数据集的多样性和保真度。未来,方法可以拓展到未标记的数据,通过聚类样本以产生合成标签或通过训练判别模型来预测样本何时处于真实数据分布或来自采样分布。
分类器引导的有效性表明分类函数的梯度有助于获得强力的生成模型,可以用于以多种方式调节(condition)预训练模型,比如使用噪声版本(noisy version)的CLIP训练,并用上文本说明(text caption),类似于近来用文本prompt引导GAN的方法。
这也表明大规模的为标注数据集将来能用于预训练强大的扩散模型,并通过有所需属性(desirable properties)的分类器进一步改进该模型。
Critique
44页的论文有点哈人,不多好在大部分都是附录。感觉这篇更注重的是大量的实验,以及对前人工作的整合、比较,亮点在于提出了classifier guidance,可以利用预训练好的无条件扩散模型进行条件生成任务,而不用重新训练。全文阅读有一定难度,特别是分类器引导那部分的推导。不够分类器引导的思想真的很厉害,效果也确实好,直觉上似乎是在降噪的每一步利用分类器的信息向着生成目标类别图片的方向努力。
实验部分非常充足,提出的ADM-G架构仍然高居榜首,ImageNet128的FID已经刷到了3以下:https://paperswithcode.com/sota/conditional-image-generation-on-imagenet 但这个榜按IS分数排的话应该是Omni-INR-GAN最强,而且比ADM高了100分,FID仅比BigGAN-deep低一些,这样不算SOTA的GAN吗?此外附录还有更多非常多的实验结果、详细的实验设置、公式推导等,十分良心。使用PyTorch,V-100训练,训练所需的计算量以 V100-days 计算,动不动就是几十几百,不是一般人能玩的,事实上作比较的StyleGAN2、BigGAN-deep也要不小的开销。
比较有意义的是通过它了解到扩散模型的一些发展,以及条件图片合成领域的前沿,学到一些图片生成中有效的模型架构。此外用作比较的SOTA GAN是18年的BigGAN-deep,这么看GAN也挺久没发展了?
Unknown
- Diffusion Synthesis Models 论文 Imagediffusion synthesis models论文 cvpr_high-resolution resolution diffusion synthesis text-to-image conditional diffusion control language survey models论文 论文翻译adaptation low-rank models word-as-image typography semantic论文 diffusion文本 论文 harmonization painterly diffusion论文 论文翻译diffusion-based mel-spectrogram synthesis