本章内容较多预警
Intro
我们写过一个两层的神经网络, 但是梯度是在loss内计算的, 因此对网络的架构相关的修改难免比较困难. 为此, 我们需要规范化网络设计, 设计一系列函数. , 后面我们还会封装一个类, 这也是最希望的方式了.
环境搭建
又到了工科生最上头(bushi 的搭环境环节. 我们重新建立python3.7的conda环境, 按照requirements.txt指示安装. 注意, 直接执行会报错, 例如torch, tensorflow安装不上. 为此我们需要手动寻找相对应的版本, 直接搜索tensorflow whl这样的字眼, 就可以按需下载需要的包:

随后第一次执行jupyter会要求你执行一句代码, 就可以了. 这里我没记录, 不过也不难
affine
作业前面给出的代码中,输入数据的尺寸为2*4*5*6, W尺寸为120*3, b尺寸为3. 题目的要求是将X转化为行向量(长度120,也就是2*120). 所以forward也就不难:
D = w.shape[0]
new_x = x.reshape(-1,D) # 行维度自动决定
out = new_x.dot(w) + b
对backward来说, 这个函数输入上一层的dout,要求求出dx,dw和db. dx就是本层的变化量. 从out = X * W + b, 就知道了
(推导见CS231N assignment 1 _ 两层神经网络 学习笔记 & 解析 - 360MEMZ - 博客园 (cnblogs.com))
db = dout(广播机制求和)
dw = dout * X (别忘了比对规模, 因为dout是结果层的,所以应修正为X^T * dout)
dx = dout * W^T
别忘了X是没有调整过shape的,所以应校正.
db = np.sum(dout, axis=0)
new_x = x.reshape(dout.shape[0], -1)
dw = new_x.T.dot(dout)
dx = dout.dot(w.T).reshape(x.shape) ReLU
这里设计中,ReLU作为独立的一层,从而使得代码极其简单:
out = np.maximum(0, x)倒着就是值不为0则为1, 否则就是0, 只需要简单的逻辑矩阵即可.
dx = (x > 0) * doutaffine + ReLU
PPAP
将上面两层结合. 这部分代码我们不需要写. 由此我们看到了各层的组织形式:
a, fc_cache = affine_forward(x, w, b) # 第一个参数不断推演
out, relu_cache = relu_forward(a)
cache = (fc_cache, relu_cache) # 利用元组保存结果类似反推有这样的拆解元组过程,代码就不额外写了.
模块化的两层神经网络
我们按照前面的PPAP的思路, 注意别忘了初始化权重矩阵W1,W2,b1,b2.
初始化:
W1 = np.random.randn(input_dim, hidden_dim) * weight_scale # 注意看要求注释对于权重和bias初始化的要求!
b1 = np.zeros((1, hidden_dim))
W2 = np.random.randn(hidden_dim, num_classes) * weight_scale
b2 = np.zeros((1, num_classes))
self.params['W1'] = W1
self.params['b1'] = b1
self.params['W2'] = W2
self.params['b2'] = b2推演与求loss:
#省略了取param
h, cache = affine_forward(X, W1, b1)# 一层一层调用
h1, cache1 = relu_forward(h)
out, cache2 = affine_forward(h1, W2, b2)
scores = out
data_loss, dscores = softmax_loss(scores, y)# 通过softmax函数求出损失
reg_loss = self.reg * (np.sum(W1 * W1) + np.sum(W2 * W2))
loss = data_loss + reg_loss
# 反向传播
dh1, dW2, db2 = affine_backward(dscores, cache2) # 一点一点反推, 其中X作为链式传参
dh = relu_backward(dh1, cache1)
dX, dW1, db1 = affine_backward(dh, cache)
grads['W2'] = dW2 + self.reg * W2 # 不要忘记加上正则化
grads['b2'] = db2
grads['W1'] = dW1 + self.reg * W1
grads['b1'] = db1SOLVER API
实际上我们需要简单化操作, 将训练简化为一个API.
调用方法(下面是其他博客的实例):
solver = Solver(model,data,
update_rule='sgd',
optim_config={
'learning_rate':4e-4
},
lr_decay=0.95,
num_epochs=10, batch_size=100,
print_every=100)
solver.train()这里面的要求我们认真阅读注释就可以了, model导入网络模型class(符合__init__和loss函数规范), data, 随后我们利用kwargs读取可变参数:
self.update_rule = kwargs.pop('update_rule', 'sgd') # 从kwargs读取键值,如果读取到就按照读入值,否则默认sgd
self.optim_config = kwargs.pop('optim_config', {}) # 可以在输入利用字典等高阶特性
# 上述读取所有kwargs之后,kwargs的参数会减少, 最终应当是0,否则需要报错我们再来深入了解具体信息. 在前面的操作当中, 我们一直是随机输入一批数据(batch_size)作为迭代, 现在我们引入epoch的概念, 上面我们选定了49000图片,batch_size=100, 所以我们定义一次过完数据集为一个epoch, 因此一个epoch就是490次iteration. 我们执行10个epoch. 我们可以在每个epoch开始/结束的时候对验证集/训练集做一次验证.
还有值得注意的是, 我们利用pickle包来保存实时的模型文件, 来防止意外情况的发生.(_save_checkpoint函数)
上面的代码遵循了模块化设计, 不拖泥带水, 很值得认真阅读参考.
可视化结果如下:
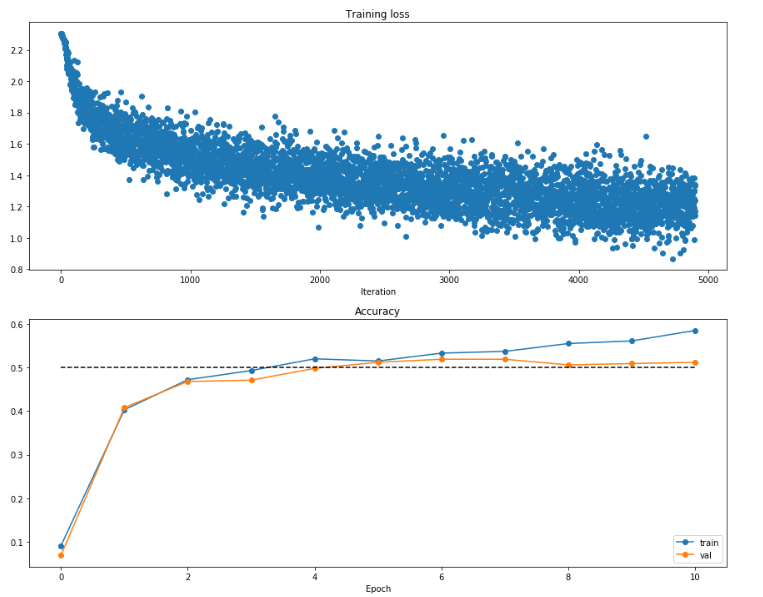
这个结果再次说明发生了过拟合的情况, 也再次说明loss波动不等于误差不再收敛,要看整体趋势和综合指标.(讲义提到可能是batch size太小了)
插播 : 梯度验证
做到这里, 我突然发现作业有这么一句话:

数值误差为什么数量级并不固定? 对此, 除了之前的部分不可导的点(relu)之外, 在神经网络讲义3上面总结了这样的结论:
- 一般情况下理想情况是相对误差1e-7数量级, 1e-4对于个别不可微分的点可接受
- 如果网络深度比较大, 那么可能1e-2相对误差也可以接受
- 其他目前涉及不到的因素, 包括: 单独对正则化项进行验证, 关闭dropout等不确定因素等.
考虑到作业内部还有许多技巧在讲义内提到, 后续我可能会专门总结出来.
多层神经网络
- 省流大师 : 一定要记得阅读作业给的注释!!!
实际上我们需要将模块化设计应用到任意多层的网络之上, 而且我们未来需要实现dropout/正则化功能, 现在需要给届时的函数预留空间. 但我们目前并不懂, 为此需要查看这些函数的定义, 了解其用法. 其被定义在了layers.py内:
def batchnorm_forward(x, gamma, beta, bn_param):
pass
def batchnorm_backward(dout, cache): # 所有backward层定义类似, 故这里不重复了
pass
def layernorm_forward(x, gamma, beta, ln_param):
pass
def dropout_forward(x, dropout_param):
pass这里多出来的param我们认真阅读代码, 发现其在TODO区域后面已写好:
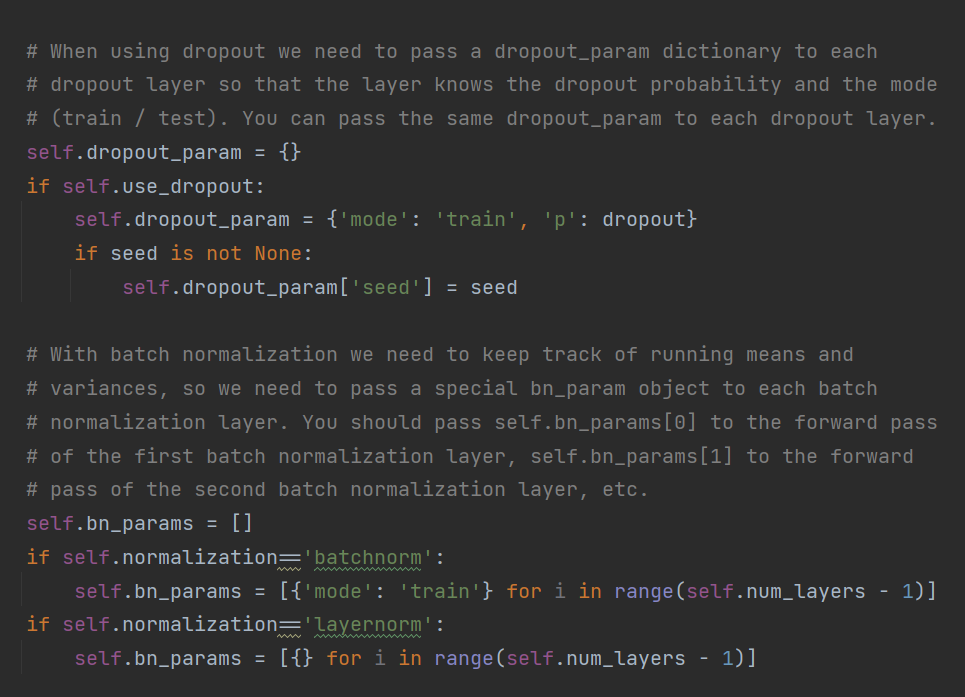
所以可以知道,正则化参数均为bn_params, 这些参数的初始化均使用了推导式, 也就是由数个字典组成的列表. 初始化参数, 题目要求我们按照params['W1']这样的格式表示第一层的权重等, 且要求正则化的beta和gamma参数. 这样的代码:
for i in range(len(hidden_dims)): # hidden_dims就是隐含层的元素, 暗含了神经网络层数
dim = hidden_dims[i] # input_dim为上一层接收的维度, dim为输出维度. 初始input_dim
self.params['W'+str(i+1)] = weight_scale * np.random.randn(input_dim,dim) # W维度.也可以self.params['W%s'%(i+1)]
self.params['b'+str(i+1)] = np.zeros(dim)
# 当mode是batch_norm需要维护均值(β)和方差(γ)
if self.normalization is not None: # 从前面分析我们已经看出需要正则化就这样维护
self.params['gamma'+str(i+1)] = np.ones(D)
self.params['beta'+str(i+1)] = np.zeros(D)
input_dim = dim # 迭代
pass
# 单独讨论输出层.这里输出dim为类别数
self.params['W'+str(self.num_layers)] = weight_scale * np.random.randn(hidden_dims[-1],num_classes) # [-1]表示最后一个元素
self.params['b'+str(self.num_layers)] = np.zeros(num_classes)下面是前向推导的操作:
scores = X # 图方便这里直接拿score迭代,本来就是输出层结果,迭代最终就是正确的
caches = list()
for i in range(self.num_layers - 1):
cache = list() # 存储cache
scores, fc_cache = affine_forward(scores, self.params['W' + str(i + 1)], self.params['b' + str(i + 1)])
cache.append(fc_cache)
# 正则化在relu之前, 不明白请看类最开始注释有写到组织方式
# {affine - [batch/layer norm] - relu - [dropout]} x (L - 1) - affine - softmax
if self.normalization is not None:
if self.normalization == 'batchnorm':
scores, bn_cache = batchnorm_forward(scores, self.params['gamma' + str(i + 1)], # 按照用法正则化,当作独立一层
self.params['beta' + str(i + 1)], bn_param[i])
cache.append(bn_cache)
elif self.normalization == 'layernorm':
scores, ln_cache = layernorm_forward(scores, self.params['gamma' + str(i + 1)],
self.params['beta' + str(i + 1)], bn_param[i])
cache.append(ln_cache)
pass
scores, relu_cache = relu_forward(scores)
cache.append(relu_cache)
if self.use_dropout: # dropout层
scores, droupout_cache = dropout_forward(scores, self.dropout_param)
cache.append(droupout_cache)
caches.append(cache)
pass
# for循环结束
scores, fc_cache = affine_forward(scores, self.params['W' + str(self.num_layers)], # 最后一层直接affine即可
self.params['b' + str(self.num_layers)])
caches.append(fc_cache)下面是计算loss和梯度的操作:
loss, dx = softmax_loss(scores, y) # softmax直接能给出本层的loss和dx
for i in range(self.num_layers):
loss += 0.5 * self.reg * np.sum(self.params['W' + str(i + 1)] ** 2) # 加上正则项
pass
# 计算梯度
for i in range(self.num_layers, 0, -1):
if i == self.num_layers: # 最后一层直接计算梯度即可,其他的还需要计算dropout层等
dx, dw, db = affine_backward(dx, caches[i - 1]) # 推导
# 保存梯度并加上正则项
grads['W%s' % i] = dw + self.reg * self.params['W' + str(i)]
grads['b%s' % i] = db
pass
else:
j = -1
if self.use_dropout: # 按照注释给出的顺序反向操作
dx = dropout_backward(dx, caches[i - 1][j])
j -= 1
pass
dx = relu_backward(dx, caches[i - 1][j]) # relu
j -= 1
if self.normalization is not None:
if self.normalization == 'batchnorm':
dx, dgamma, dbeta = batchnorm_backward(dx, caches[i - 1][j])
j -= 1
elif self.normalization == 'layernorm':
dx, dgamma, dbeta = layernorm_backward(dx, caches[i - 1][j])
j -= 1
# 保存梯度
grads['gamma%s' % i] = dgamma
grads['beta%s' % i] = dbeta
pass
dx, dw, db = affine_backward(dx, caches[i - 1][j])
# 保存梯度并加上正则项
grads['W%s' % i] = dw + self.reg * self.params['W' + str(i)]
grads['b%s' % i] = db随后作业要求我们对简单的两层隐含层100元素的网络(三层神经网络)产生过拟合. 在默认的参数下, 误差下不去, 产生明显的欠拟合. 缩小扩大尝试,发现scale在0.1下已经可以达到100%准确率(训练集而非验证集). 我们尝试增大lr使收敛变快. 最终在两个参数都扩大10倍下(scale=0.1,lr=0.001), 用6个epoch就可以满足要求.
对于五层神经网络, 默认出现了一样的情况, 我们用和上面完全一致的参数尝试过(scale=0.1,lr=0.001), 发现效果已经不错. 值得注意的是,继续增大scale, 出现了几乎类似的欠拟合问题, 但是减小lr可以抵消(scale=0.2,lr=0.0001), 效果和前面类似. 因此答案不唯一.
SGD with momentum
下面让我们开启船新内容 - 新的梯度下降算法. 之前的SGD是最简单的方法, 其有下面的问题:
- 靠近极小值收敛速度减慢
- 可能会在鞍点(凸函数的不稳定平衡点)而非最小值停下(局部极小值是所有方法都逃不掉的)
原本我们的下降是直接对数据下降梯度. 现在我们设想这个场景, 比如说我们放一个球在下坡上, 那么球的初速度为0, 随后加速, 加速度和坡度有关. 梯度可以看作是坡度, 它会影响当前的速度(注意是通过加速度影响速度). 不过除此之外, 如果坡度消失, 速度需要慢慢下降, 这是因为摩擦力的作用, 所以我们引入了mu超参数来让梯度消失之后速度下降. 虽然mu被称为动量, 但实际上就是速度的衰减系数, 和摩擦因数很像 ( ※这里不要拿受力分析来杠 ) 伪代码如下:
v = mu * v - learning_rate * dx # 速度受梯度影响
x += v # 位置受速度影响这里的mu某种意义上和学习率退火有点像.一般合法取值为[0.5,0.9,0.95,0.99], 这里是0.9. 我们将dx,v,x变成向量. 因此作业的代码就不难了:
v = config['momentum'] * v - config['learning_rate'] * dw # 从config取出数据
next_w = w + v可以看出,引入动量之后收敛能够更快, 这个就是因为速度的积累效应导致的.
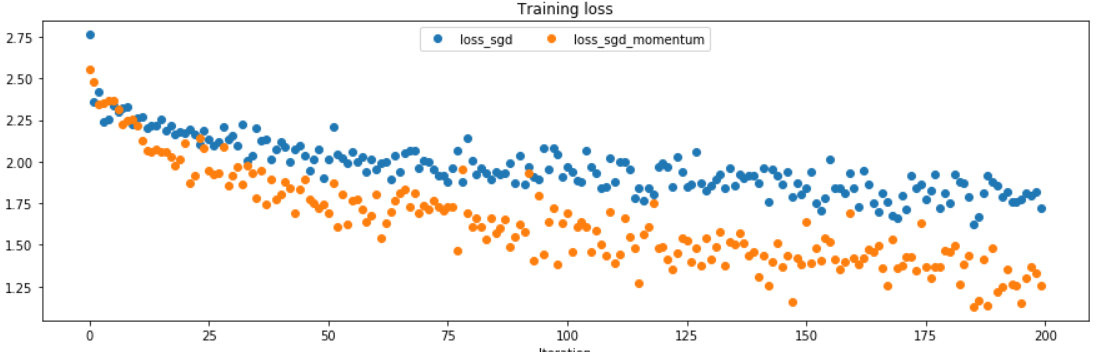
值得注意的是,这里没有提到Nesterov动量. 下面进行简单解释: 大概意思就是我们预测我们要到达的那个点的梯度, 就按照那里的梯度为准, 而不是目前位置的梯度.伪代码如下:
x_ahead = x + mu * v # 预测即将到达位置
# 在这个位置求出梯度代替原本的dx
v = mu * v - learning_rate * dx_ahead
x += v但是重新求出dx_ahead有种多此一举的感觉, 所以贴近SGD表达形式, 只变化位置的形式:
v_prev = v # 存储备份
v = mu * v - learning_rate * dx # 速度仍然用SGD估计
x += -mu * v_prev + (1 + mu) * v # 位置更新变了形式,dx差值估计为了mu(v-v_prev)
# 因为根据求导法则, d(x_ahead) = dx + vd(mu) + (mu)dv , dmu = 0这就是所谓NAG(Nesterov's Accelerated Momentum).
RMSprop
这里同样有点快了, 因为rmsprop是adagrad的改进, 我们需要先解释adagrad.
adagrad代码很好理解, 就是公式的直接复制, 即
cache += dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)上面的做法就是: 如果对于梯度很大的dx某个元素, 则迭代速度快速下降, 而梯度小元素需要相应上升. eps是一个很小的正数, 是为了防止除0异常. 按照讲义说法, 其可能会容易过快停止学习.
rmsprop就是将cache求和变成了指数平滑.
cache = decay_rate * cache + (1 - decay_rate) * dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)decay_rate可以选择[0.9,0.99,0.999], 衰减速率变快可以更好反应当前的梯度状况.
另外指数平滑之后同样dx绝对大小不一样, 所以lr需要相应补偿.
adam是RMSprop的小改进. 这个算法可以说真的神, 新手几乎是开箱即用, 效果杠杠的, 虽然有吐槽, 但的确算是近年来最主流的方式了, 课程也是首推adam. 讲义代码如下:
m = beta1*m + (1-beta1)*dx # 除了dx变成平滑版本其他完全一致
v = beta2*v + (1-beta2)*(dx**2)
x += - learning_rate * m / (np.sqrt(v) + eps)推荐的数值为: eps=1e-8, beta1=0.9, beta2=0.999.
这还不是完整的adam, 完整版本如下:
# t为迭代次数, 第一次迭代,第二次...
m = beta1*m + (1-beta1)*dx
mt = m / (1-beta1**t)
v = beta2*v + (1-beta2)*(dx**2)
vt = v / (1-beta2**t)
x += - learning_rate * mt / (np.sqrt(vt) + eps)其意义在于: 因为初始m和v都是0, 为了让m和v快速加速到预定值, 所以最开始(1-beta**t) 很大.
有了伪代码, 实现作业可以说顺水推舟. 按照要求的字典形式改写:
rmsprop
cache = config['decay_rate'] * config['cache'] + (1-config['decay_rate']) * dw * dw
next_w = w - config['learning_rate'] * dw / (np.sqrt(cache) + config['epsilon'])
config['cache'] = cacheadam
# 迭代次数 + 1
t = config['t'] + 1 # 别忘了读取参数
beta1 = config['beta1']
beta2 = config['beta2']
m = config['m']
v = config['v']
# fisrt moment
m = beta1 * m + (1 - beta1) * dw
# second moment
v = beta2 * v + (1 - beta2) * dw * dw
mt = m / (1 - beta1 ** t)
vt = v / (1 - beta2 ** t)
next_w = w - config['learning_rate'] * mt / (np.sqrt(vt) + config['epsilon'])
# 更新参数
config['m'] = m
config['v'] = v
config['t'] = t按照作业默认的参数, 得到了如下图像:
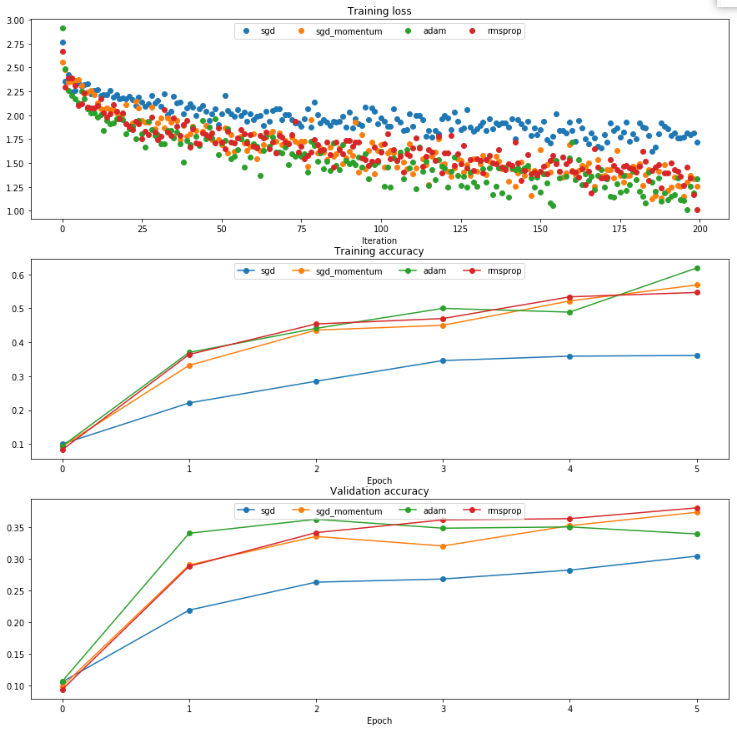
能够看出, 本例中梯度并不会产生收敛结果明显区别的问题, 所以最终的准确度不会有什么区别, 但是SGD之外三个算法都是收敛明显较快, 而值得注意, adam虽然训练集的曲线和剩下两个差不多, 但是验证集效果却非常好.
设计一个好的网络
下面是实操环节. 我们已经构造了任意的层数网络, 只需要调用solver即可. 梯度下降用adam就行, 而考虑到他说网络准确度55%就可以了, 可能是神经网络的瓶颈, 所以这里不采用过多的网络层数.我们直接用4层隐含层, 每层150, adam, 超参数lr=3e-4, weight_scale = 2.5e-2, 训练10个epoch之后, 已经可以得到这样的准确度, 算是很好了.
戏剧性的是, 我用两层隐含层, 验证集准确度大幅下降, 但是测试集居然准确率没差, 这表明多层下出现了明显过拟合. 看来咱还没到卷积网络,一味追求深度, 实在是不可取!
问题与回答

答案: 1,2 1是因为不断反向传播造成的, 而2是因为relu的神经元死亡. 3的话比2好很多.

答案: 我们仿佛提到了问题所述现象, 却没有真正深入探讨. 多层之下容易过拟合(泛化性能没那么好), 而且因为调节参数多, 也会对参数更为敏感, 也更容易陷入一些局部最小值. 总之就是, 情况变复杂了, 自然问题也会多.

答案: adagrad是因为cache的累加机制导致了dw/...的值迅速下降, 这更可能下降到局部最小值. 而adam因为其用指数平滑, 所以不会如此, 能够反应实时变化.
这个作业耗时是真的长, 差不多历时两天写完, 但是收获确实不少,感觉上路了