整体思路
第一步 抓取全部的列表页链接
第二步 抓取每个列表页的商品总数,页数
第三步 单个列表页 进行分业 抓取商品价格
第四步 单个列表页抓取完成后 输出商品数据并在本地文件记录本次抓取
最后一步 合并各个列页表抓取的商品数据
第一步
爬取的网站,获得分类信息
https://global.11st.co.kr/glb/
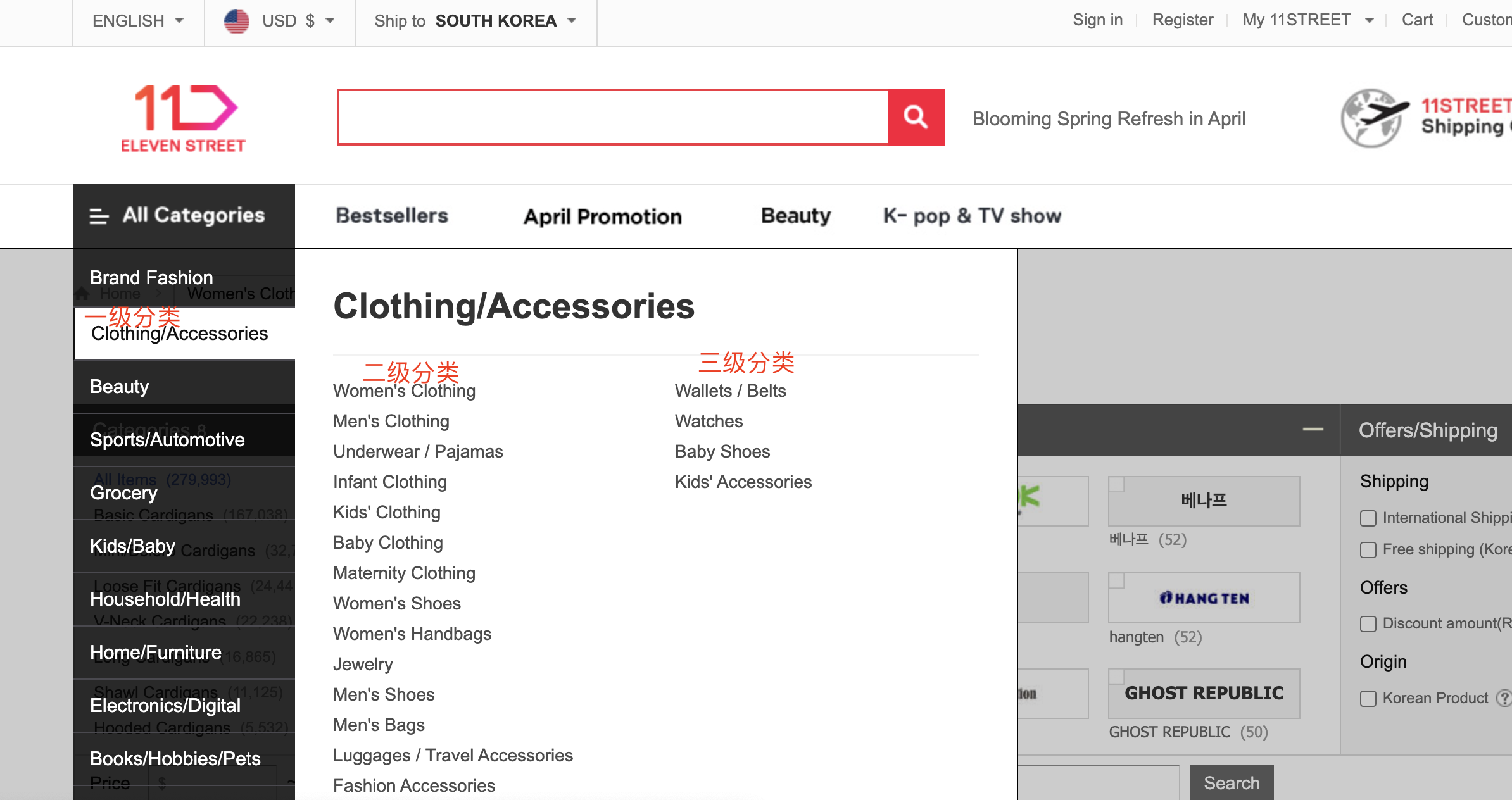
这里分类是动态加载的,需要用selenium + chromedriver
代码如下
import requests,random,os,math,time,re,pandas as pd,numpy as np
from bs4 import BeautifulSoup
from selenium import webdriver
#chomedriver 地址
CHROME_DRIVER_PATH = '/Users/xxxx/Downloads/chromedriver'
#爬取动态界面
def get_dynamic_html(site_url):
print('开始加载',site_url,'动态页面')
chrome_options = webdriver.ChromeOptions()
#ban sandbox
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
#use headless
#chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--ignore-ssl-errors')
driver = webdriver.Chrome(executable_path=CHROME_DRIVER_PATH,chrome_options=chrome_options)
#print('dynamic laod web is', site_url)
driver.set_page_load_timeout(100)
#driver.set_script_timeout(100)
try:
driver.get(site_url)
except Exception as e:
driver.execute_script('window.stop()') # 超出时间则不加载
print(e, 'dynamic web load timeout')
data = driver.page_source
soup = BeautifulSoup(data, 'html.parser')
try:
driver.quit()
except:
pass
return soup
#获得列表页链接
def get_page_url_list(cate_path):
cate_url_list = []
print('开始爬取')
page_url = 'https://global.11st.co.kr/glb/en/browsing/Category.tmall?method=getCategory2Depth&dispCtgrNo=1001819#'
soup = get_dynamic_html(page_url)
print(soup.prettify())
one_cate_ul_list = soup.select('#lnbMenu > ul > li')
for i in range(0, len(one_cate_ul_list)):
one_cate_ul = one_cate_ul_list[i]
one_cate_name = one_cate_ul.select('a')[0].text
one_cate_url = one_cate_ul.select('a')[0].attrs['href']
two_cate_ul_list = one_cate_ul.select('ul.list_category > li')
for two_cate_ul in two_cate_ul_list:
two_cate_name = two_cate_ul.select('a')[0].text
two_cate_url = two_cate_ul.select('a')[0].attrs['href']
three_cate_ul_list = two_cate_ul.select('li .list_sub_cate > li')
for three_cate_ul in three_cate_ul_list:
three_cate_name = three_cate_ul.select('a')[0].text
three_cate_url = three_cate_ul.select('a')[0].attrs['href']
cate_obj = {
'brand': 'global.11st.co',
'site': 'kr',
'one_cate_name': one_cate_name,
'one_cate_url': one_cate_url,
'two_cate_name': two_cate_name,
'two_cate_url': two_cate_url,
'three_cate_name': three_cate_name,
'three_cate_url': three_cate_url,
}
cate_url_list.append(cate_obj)
cate_url_df = pd.DataFrame(cate_url_list)
cate_url_df.to_excel(cate_path, index=False)
if __name__ == '__main__':
#列表页链接存放位置
cate_excel_path = '/Users/xxxx/Downloads/11st_kr_page_list.xlsx'
get_page_url_list(cate_excel_path)
第二步
如图每个列表页可以看到总商品数量,每页展示40件商品,可以计算总页数
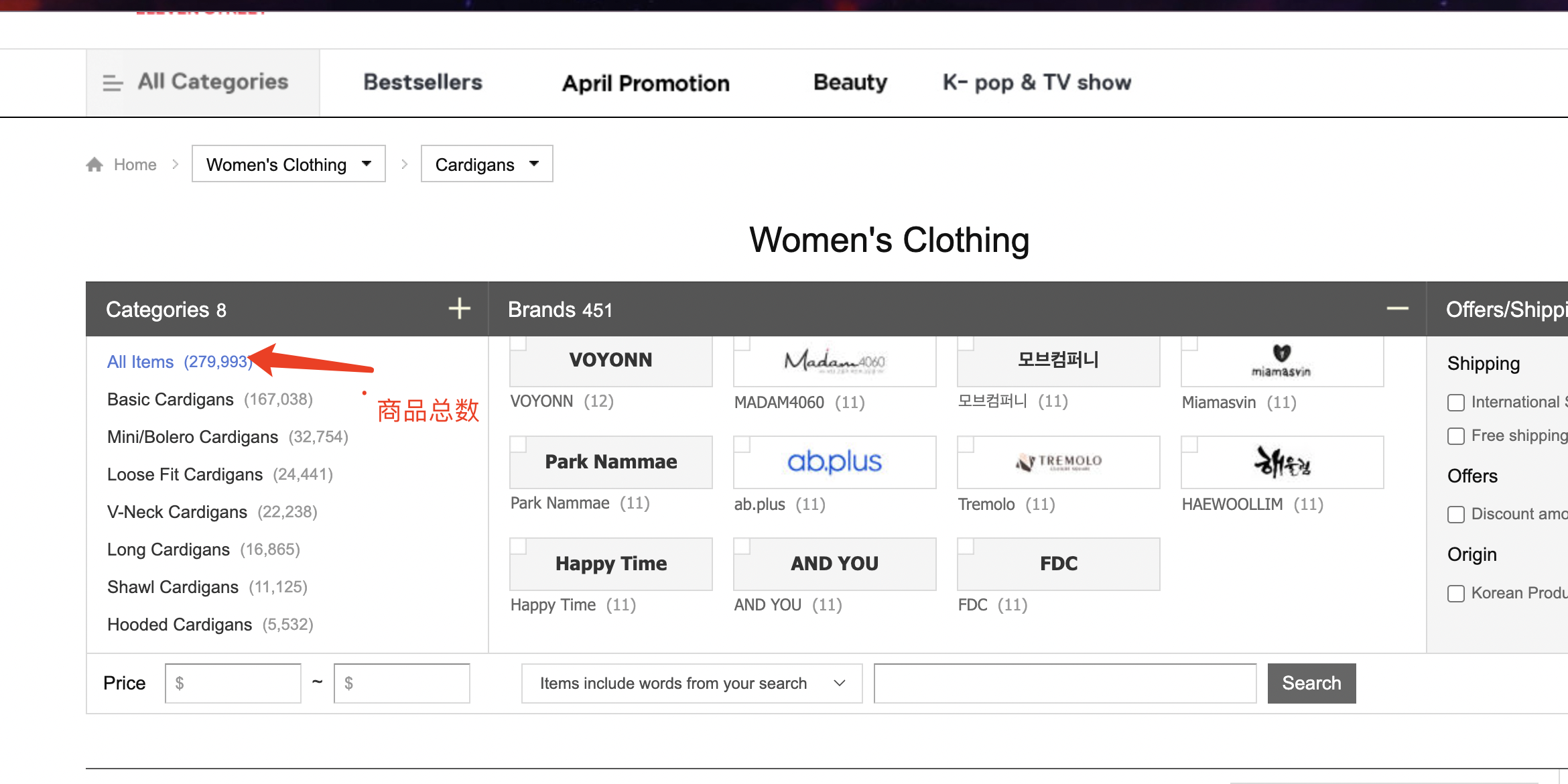
基于步骤一获得文件,去计算每个列表页的页数
#需要引入的包 都在步骤一
#获得总数量 和 总页数 def account_page_num(cate_path, reocrd_path): out_page_list = [] page_list_df = pd.read_excel(cate_path) for index, row in page_list_df.iterrows(): print(index, row) page_item = { 'brand': row['brand'], 'site': row['site'], 'one_cate_name': row['one_cate_name'], 'two_cate_name': row['two_cate_name'], 'two_cate_url': row['two_cate_url'], 'three_cate_name': row['three_cate_name'], 'three_cate_url': row['three_cate_url'] } page_item['total_item_num'] = 'not found tag' page_item['total_page_num'] = 0 page_item['per_page_num'] = 40 page_item['start_page_num'] = 0 soup = get_static_html(page_item['three_cate_url']) total_num_tag_list = soup.select('ul.categ > li.active') if len(total_num_tag_list) > 0: total_num_tag = total_num_tag_list[0] tag_text = total_num_tag.text num_pattern = re.compile('\(([0-9 ,]+)\)') num_arr = num_pattern.findall(tag_text) if len(num_arr) > 0: page_item['total_item_num'] = int(num_arr[0].replace(',', '')) page_item['total_page_num'] = math.ceil(page_item['total_item_num'] / page_item['per_page_num']) else: page_item['total_item_num'] = f'text error:{tag_text}' print(page_item) out_page_list.append(page_item) record_url_df = pd.DataFrame(out_page_list) record_url_df.to_excel(reocrd_path, index=False) if __name__ == '__main__': date_str = '2023-04-06' #爬虫记录 记录已经爬取的页数,以防中途爬取失败,不用从头开始爬,可接着爬 crawl_record_path = f'/Users/xxxx/Downloads/11st_kr_page_reocrd_{date_str}.xlsx' account_page_num(cate_excel_path, crawl_record_path)
第三步,第四步
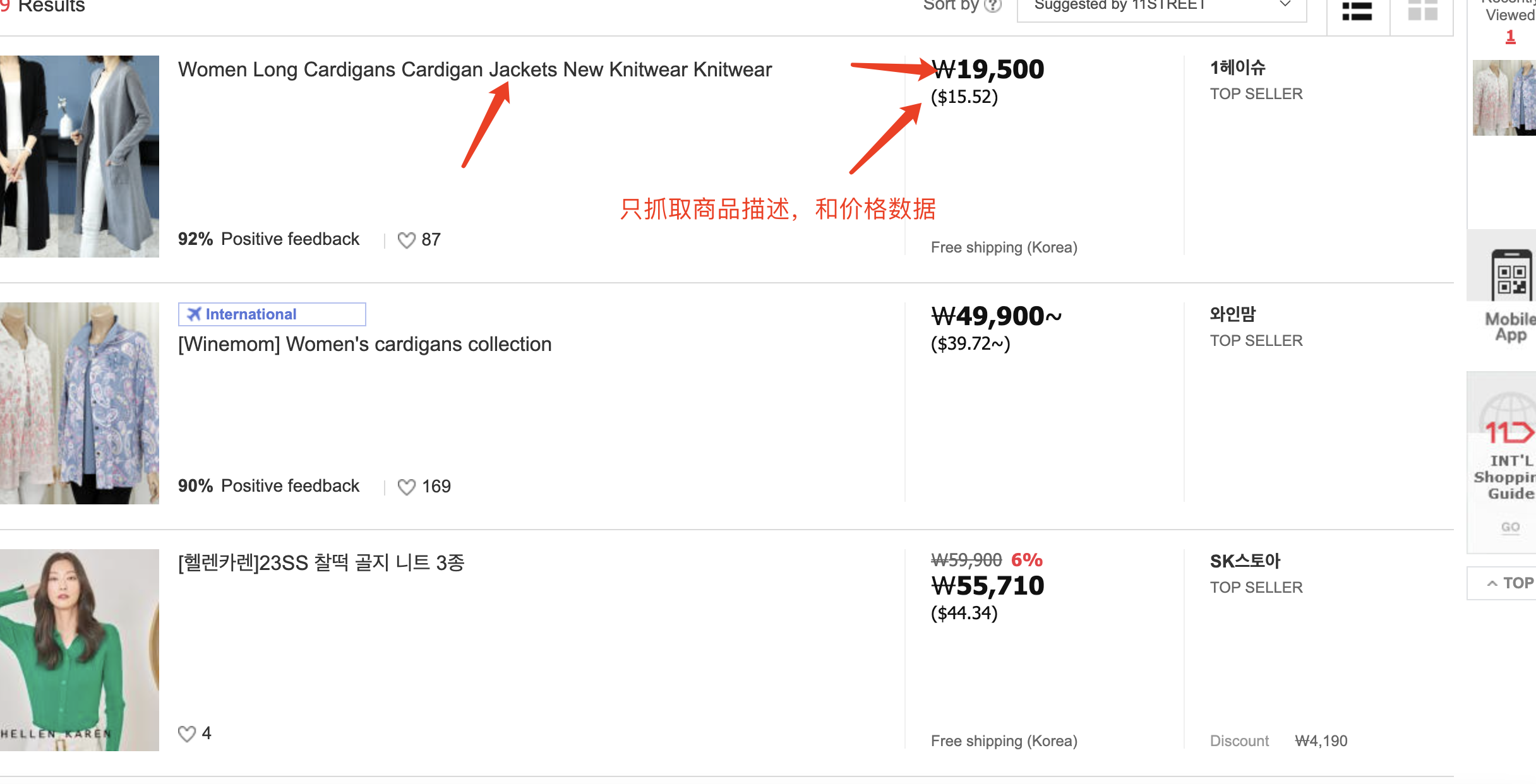
代码如下
#需要引入的包都在步骤1
#获得静态的界面
def get_static_html(site_url):
print('开始加载', site_url, '页面')
headers_list = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
]
headers = {
'user-agent': headers_list[random.randint(0,len(headers_list))-1],
'Connection': 'keep - alive'
}
try:
resp = requests.get(site_url, headers=headers)
except Exception as inst:
print(inst)
requests.packages.urllib3.disable_warnings()
resp = requests.get(site_url, headers=headers,verify=False)
soup = BeautifulSoup(resp.text, 'html.parser')
return soup
#dateframe格式 输出为无url格式的excel
def obj_list_to_df_wihout_url(obj_df, out_path):
conten_writer = pd.ExcelWriter(out_path, engine='xlsxwriter', options={'strings_to_urls': False})
obj_df.to_excel(conten_writer , index=False)
conten_writer.close()
#获取列表页的商品信息
def info_from_page_list(index, page_item):
#爬取最大列表数限制
max_limit = 250
#存放位置
three_cate_name = page_item['three_cate_name'].strip().replace(' ', '&').replace('/', '&')
now_out_path = f"{crawl_tmp_dir}/{index}_{three_cate_name}.xlsx"
total_page_num = page_item['total_page_num'] if page_item['total_page_num'] <= max_limit else max_limit
finsh_page_num = page_item['finsh_page_num']
print(finsh_page_num, total_page_num)
#如果从头开始
if finsh_page_num == 0 and not os.path.exists(now_out_path):
out_goods_list = []
#接着上次爬取
else:
already_obj_df = pd.read_excel(now_out_path)
out_goods_list = np.array(already_obj_df).to_list()
if finsh_page_num == total_page_num:
print(f"{index} {page_item['three_cate_name']} 抓取结束")
for i in range(finsh_page_num, total_page_num):
page_url = f"{page_item['three_cate_url']}#pageNum%%{i + 1}"
soup = get_static_html(page_url)
info_tag_list = soup.select('ul.tt_listbox > li')
for goods_tag in info_tag_list:
info_item = page_item.copy()
pattern_tag_3 = re.compile('products\/([0-9]+)')
href_tag = goods_tag.select('.photo_wrap > a')[0]
desc_tag = goods_tag.select('.list_info > .info_tit')[0]
#feedback_tag = goods_tag.select('.list_info .sfc')
#collect_tag = goods_tag.select('.list_info .def_likethis')
price_tag = goods_tag.select('.list_price .dlr')[0]
info_item['href'] = href_tag.attrs['href']
info_item['product_id'] = ''
info_item['desc'] = desc_tag.text
#info_item['feedback'] = feedback_tag.text
#info_item['collect'] = collect_tag.text
info_item['price_kr'] = int(price_tag.attrs['data-finalprice'])
info_item['price_us'] = round(info_item['price_kr'] * 0.0007959, 2)
if info_item['href'] != '':
id_arr = pattern_tag_3.findall(info_item['href'])
if len(id_arr) > 0:
info_item['product_id'] = id_arr[0]
out_goods_list.append(info_item)
#每50页保存一次
if i == total_page_num - 1 or i % 50 == 0:
print('开始保存')
#临时保存
out_goods_df = pd.DataFrame(out_goods_list)
obj_list_to_df_wihout_url(out_goods_df, now_out_path)
print('更新记录')
#更新记录
crawl_record_df = pd.read_excel(crawl_record_path)
crawl_record_df.loc[index, 'finsh_page_num'] = i + 1
print(crawl_record_df.loc[index, 'finsh_page_num'])
obj_list_to_df_wihout_url(crawl_record_df, crawl_record_path)
if __name__ == '__main__':
date_str = '2023-04-06'
#本次爬虫记录
crawl_record_path = f'/Users/xxx/Downloads/11st_kr_page_reocrd_{date_str}.xlsx'
#临时存放爬取的商品数据目录
crawl_tmp_dir = f'/Users/xxx/Downloads/11st_kr_page_reocrd_{date_str}'
if not os.path.exists(crawl_tmp_dir):
os.mkdir(crawl_tmp_dir)
crawl_record_df = pd.read_excel(crawl_record_path)
new_recrod_list = []
for index, row in crawl_record_df.iterrows():
info_from_page_list(index, row)
最后一步
合并临时存放商品数据的excel
crawl_tmp_dir