给出一个jax的jit的循环结构代码:
from jax import jit, random
import jax.numpy as jnp
from functools import partial
@partial(jit, static_argnums=(2,))
def f(x, y, z):
print("Running f():")
print(f" x = {x}")
print(f" y = {y}")
print(f" z = {z}")
for _ in range(z):
y = jnp.dot(x + 0.0001, y + 0.0001)
print(f" result = {y}")
return y
key = random.PRNGKey(0)
x = random.normal(key, (10000, 10000))
y = random.normal(key, (10000, ))
z = 10000
运行时间:
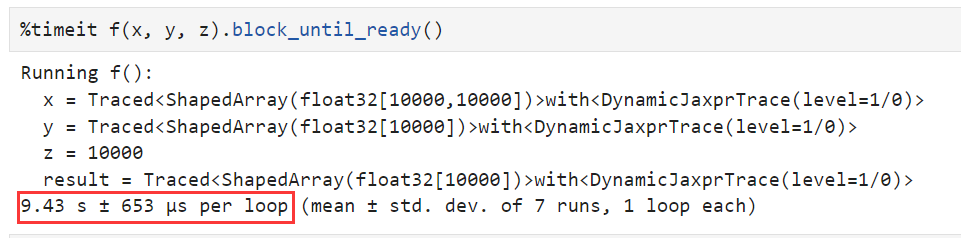
这里需要注意,上面的运算时间并没有包括jit的编译时间,只是编译后的jax的后端代码的运行时间。
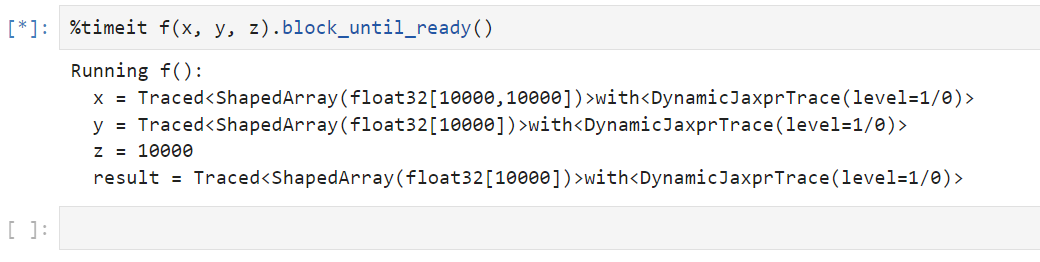
执行编译后发现很快的有打印:
CPU的使用率单核心满载,内存占用逐渐增加:
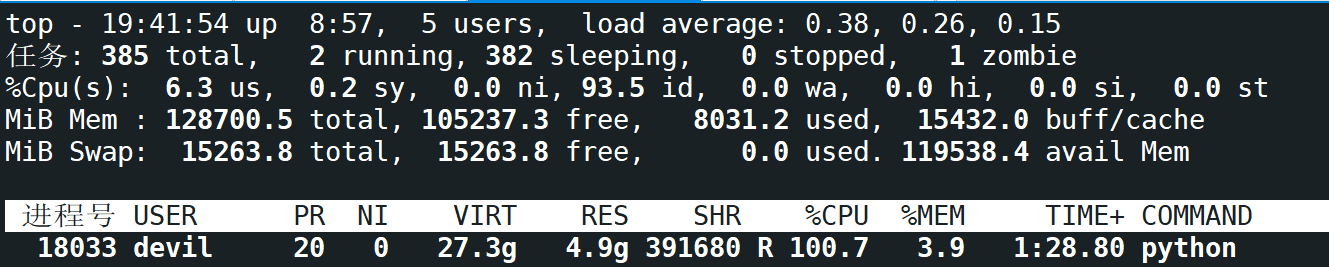
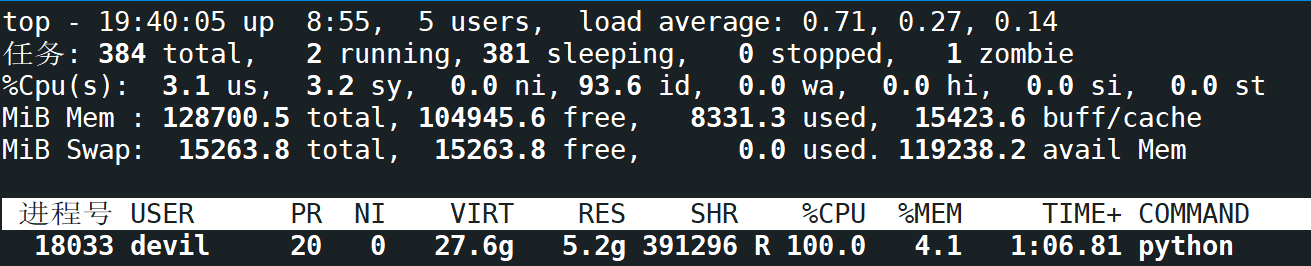
这里需要注意,在CPU单核心满载的同时GPU的负载为空:

一段时间后GPU才开始满载:

最后的运行结果:
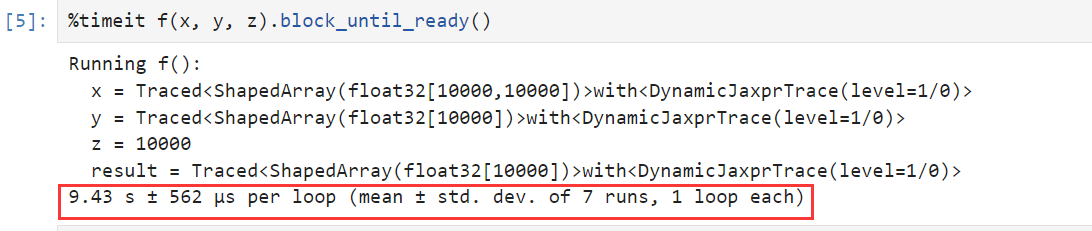
对此我们给出解释:
jax的jit编译会将循环结构进行展开编译,这个过程和C++中的inline是很像的,由于这里的循环次数为10000,因此这个训练结构展开编译需要耗费掉一定的时间,而且这个编译的时间要远大于真是代码的运行时间。
为此,我们给出非notebook的环境进行测试:
运行代码:
from jax import jit, random
import jax.numpy as jnp
from functools import partial
@partial(jit, static_argnums=(2,))
def f(x, y, z):
print("Running f():")
print(f" x = {x}")
print(f" y = {y}")
print(f" z = {z}")
for _ in range(z):
y = jnp.dot(x + 0.0001, y + 0.0001)
print(f" result = {y}")
return y
key = random.PRNGKey(0)
x = random.normal(key, (10000, 10000))
y = random.normal(key, (10000, ))
z = 10000
f(x, y, z).block_until_ready()
运行时间:
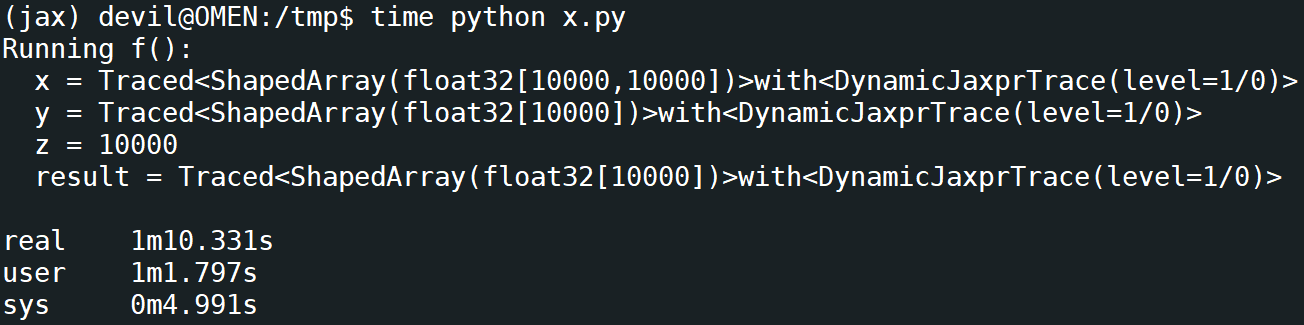
运行代码:
from jax import jit, random
import jax.numpy as jnp
from functools import partial
@partial(jit, static_argnums=(2,))
def f(x, y, z):
print("Running f():")
print(f" x = {x}")
print(f" y = {y}")
print(f" z = {z}")
for _ in range(z):
y = jnp.dot(x + 0.0001, y + 0.0001)
print(f" result = {y}")
return y
key = random.PRNGKey(0)
x = random.normal(key, (10000, 10000))
y = random.normal(key, (10000, ))
z = 10000
f(x, y, z).block_until_ready()
# y = random.normal(key, (10000, ))
f(x, y, z).block_until_ready()
运行时间:
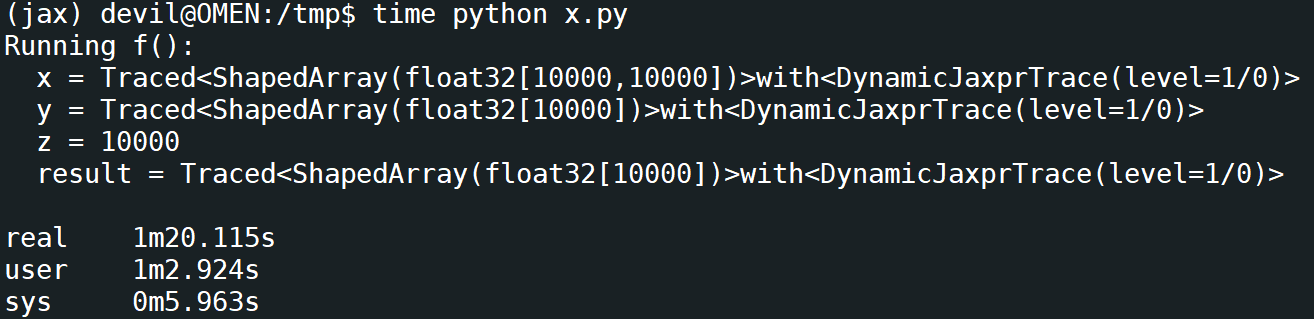
由此,我们可以估计出代码的真正运行时间为9秒左右,而jax的jit对10000次循环的编译时间为60秒左右。