1.数组介绍
1. 数组用于存储多个值,且提供索引标号便于取值
2. Bash支持普通的数值索引数组,还支持关联数组。
数组是最常见的数据结构,可以用来存放多个数据。
有两种类型的数组:数值索引类型数组和关联数组。
数值索引类型数组使用0、1、2、3…数值作为索引,通过索引可找到数组中对应位置的数据
关联数组使用名称(通常是字符串,但某些语言中支持其它类型)作为索引,是key/value模式的结构,key是索引,value是对应元素的值。
通过key索引可找到关联数组中对应的数据value
关联数组在其它语言中也称为map、hash结构、dict等。
打不死股,从严格意义上来说,关联数组不是数组,它不符合数组数据结构,只是因为访问方式类似于数值索引类型的数组,才在某些语言中称之为关联数组。
数值索引类型的数组中存放的每个元素在内存中连续的,只要知道第一个元素的地址,就能计算出第2个元素地址、第3个元素地址、第N个元素地址。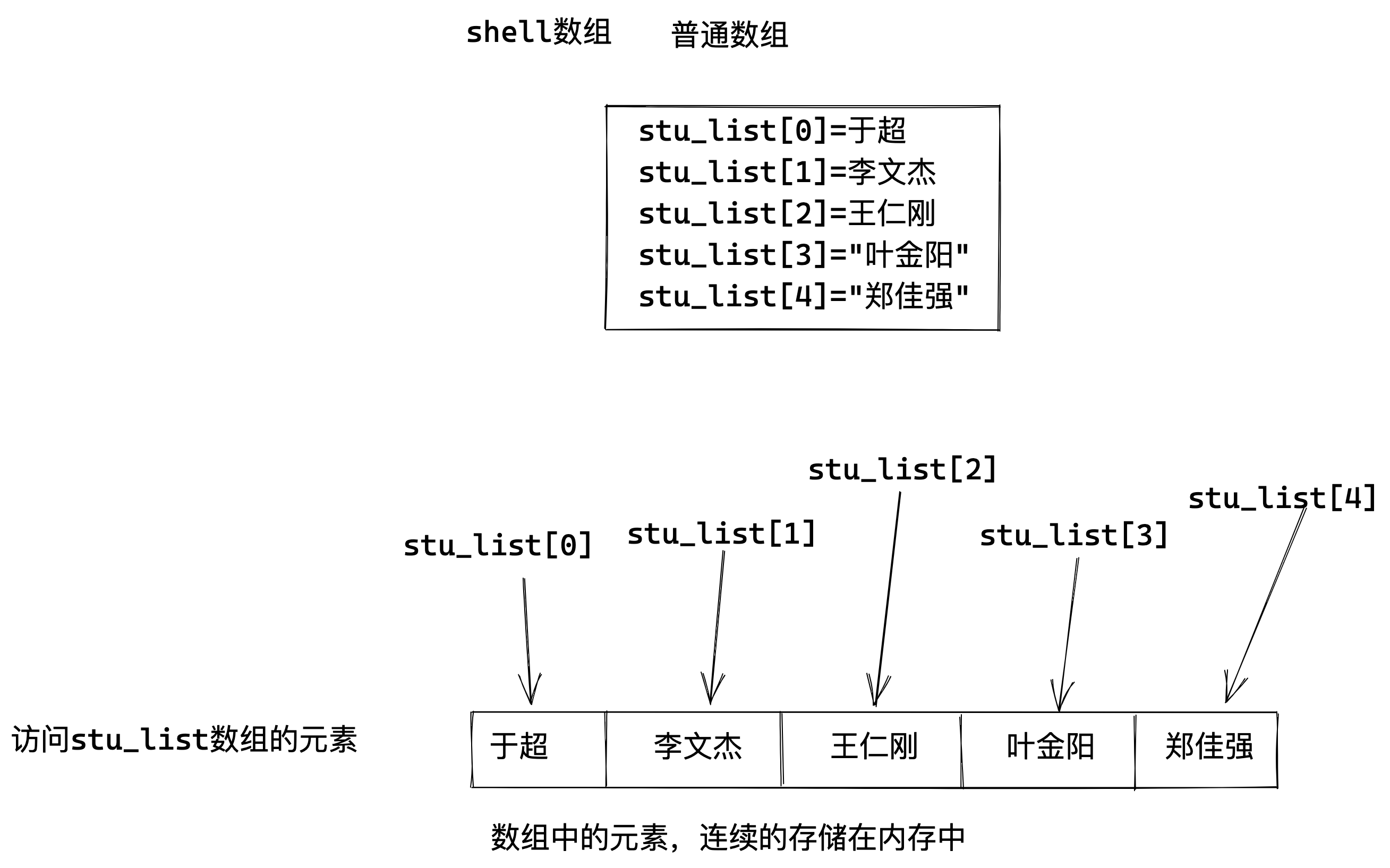
为了方便访问数组中的每一个元素,shell通过索引(下标)来一一对应每一个元素;
索引从0开始。2.数组分类
1. 普通数组 :
就是一个数组变量,有多个值,取值通过整数索引号取即可
2. 关联数组
自定义索引名,取值玩法是
数组变量[索引] 拿到值3.数组变量定义实践
3.1 语法
数组用小括号定义,元素以空格区分,数组元素的索引号从0 开始
stu_lists=(张三 李四 三胖 王二麻 )3.2 普通数组实践
普通数组,对比 python的 list数据类型理解
获取单个值
#!/bin/bash
# author: www.yuchaoit.cn
stu_lists=(张三 李四 三胖 王二麻 )
echo "提取数组 第1个元素 ${stu_lists[0]}"
echo "提取数组 第2个元素 ${stu_lists[1]}"
echo "提取数组 第3个元素 ${stu_lists[2]}"
echo "提取数组 第4个元素 ${stu_lists[3]}"
# 因此读取数组元素的语法是 ${array_name[index]}
# 如果直接打印数组变量,默认提取第一个元素
echo "$stu_lists"获取所有元素
以及定义数组的方式2
#!/bin/bash
# author: www.yuchaoit.cn
# 定义数组方式2,偷懒写法
stu_list[0]=罗兴林
stu_list[1]=李文杰
stu_list[2]=王仁刚
stu_list[3]="叶金阳"
stu_list[4]="郑佳强"
# 利用@ 或 * 可以提取所有元素
echo "数组的所有元素是:${stu_list[@]}"
echo "数组的所有元素是:${stu_list[*]}"获取数组元素个数(长度)
#!/bin/bash
# author: www.yuchaoit.cn
# 定义数组方式2,偷懒写法
stu_list[0]=罗兴林
stu_list[1]=李文杰
stu_list[2]=王仁刚
stu_list[3]="叶金阳"
stu_list[4]="郑佳强"
# 利用@ 或 * 可以提取所有元素
echo "数组的所有元素个数是:${#stu_list[@]}"
echo "数组的所有元素个数是:${#stu_list[*]}"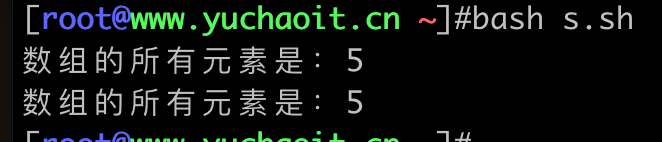
支持反向索引查找元素
[root@www.yuchaoit.cn ~]#stus=(于超 李文杰 郑佳强 张鑫)
[root@www.yuchaoit.cn ~]#
[root@www.yuchaoit.cn ~]#
[root@www.yuchaoit.cn ~]#echo ${stus[-1]}
张鑫
[root@www.yuchaoit.cn ~]#echo ${stus[-2]}
郑佳强
[root@www.yuchaoit.cn ~]#echo ${stus[-3]}
李文杰
[root@www.yuchaoit.cn ~]#echo ${stus[-4]}
于超取出所有索引
#!/bin/bash
# author: www.yuchaoit.cn
# 定义数组方式2,偷懒写法
stu_list[0]=罗兴林
stu_list[1]=李文杰
stu_list[2]=王仁刚
stu_list[3]="叶金阳"
stu_list[4]="郑佳强"
# 利用@ 或 * 可以提取所有元素
# 利用!固定语法,提取所有元素索引
echo "该数组的索引是:${!stu_list[@]}"
echo "该数组的索引是:${!stu_list[*]}"
# 语法上不支持提取单个元素的索引4.关联数组
关联数组使用名称(通常是字符串,但某些语言中支持其它类型)作为索引,是key/value模式的结构,key是索引,value是对应元素的值。
通过key索引可找到关联数组中对应的数据value
关联数组在其它语言中也称为map、hash结构、dict等。
打不死股,从严格意义上来说,关联数组不是数组,它不符合数组数据结构,只是因为访问方式类似于数值索引类型的数组,才在某些语言中称之为关联数组。
数值索引类型的数组中存放的每个元素在内存中连续的,只要知道第一个元素的地址,就能计算出第2个元素地址、第3个元素地址、第N个元素地址。
shell的关联数组,参考python的字典 dict数据类型。正统的数组,到底长啥样,请看python的。
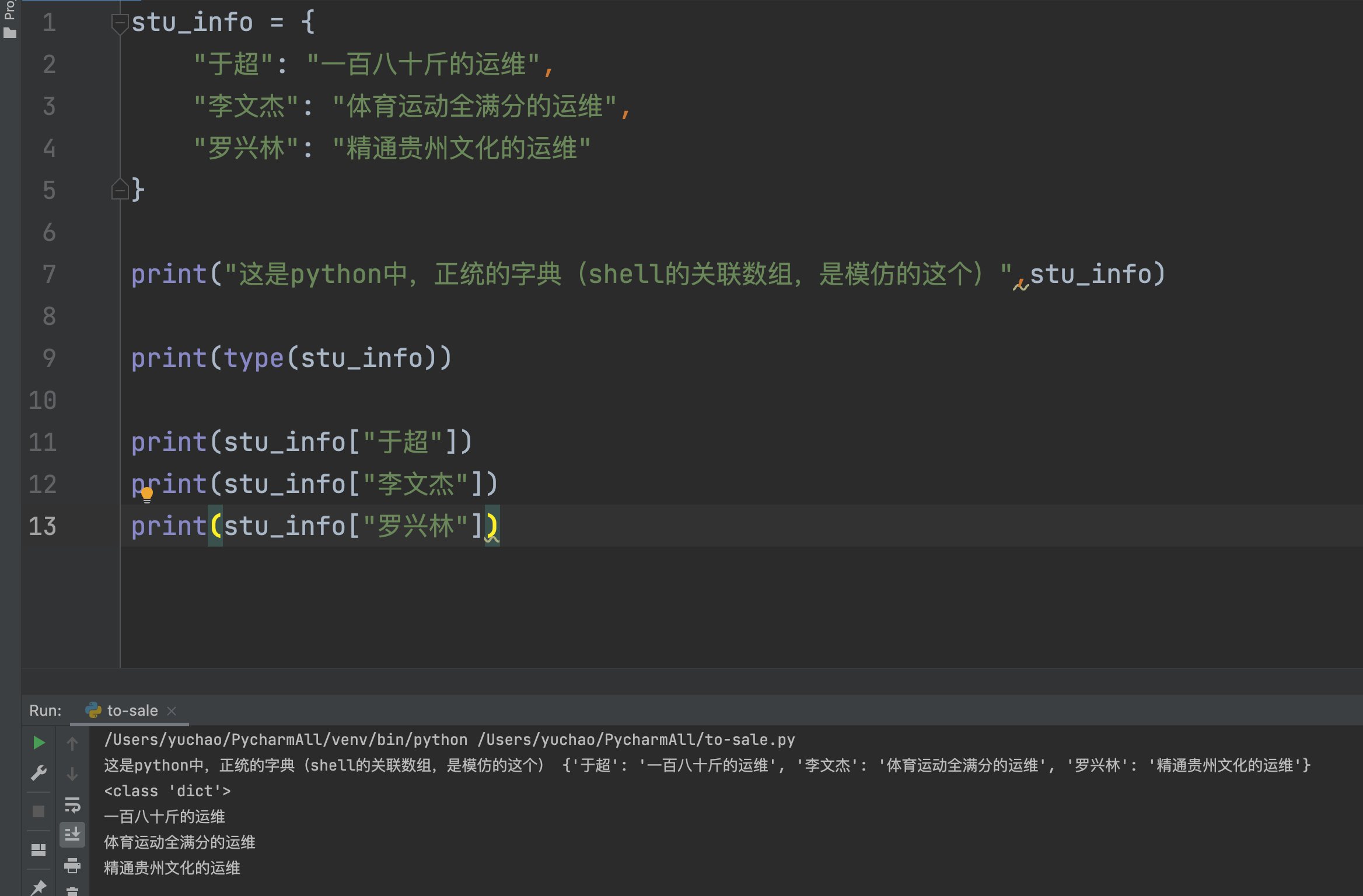
shell的关联数组
1. 必须先用declare -A命令定义,然后才能创建关联数组
#!/bin/bash
# author: www.yuchaoit.cn
declare -A stu_info
# key可以省略引号
# 定义关联数组
stu_info["于超"]="一百八十斤的运维"
stu_info[李文杰]="体育运动全满分的运维"
stu_info[罗兴林]="精通贵州文化的运维"
# 关联数组取值
echo "${stu_info[于超]}"
echo "${stu_info[李文杰]}"
echo "${stu_info[罗兴林]}"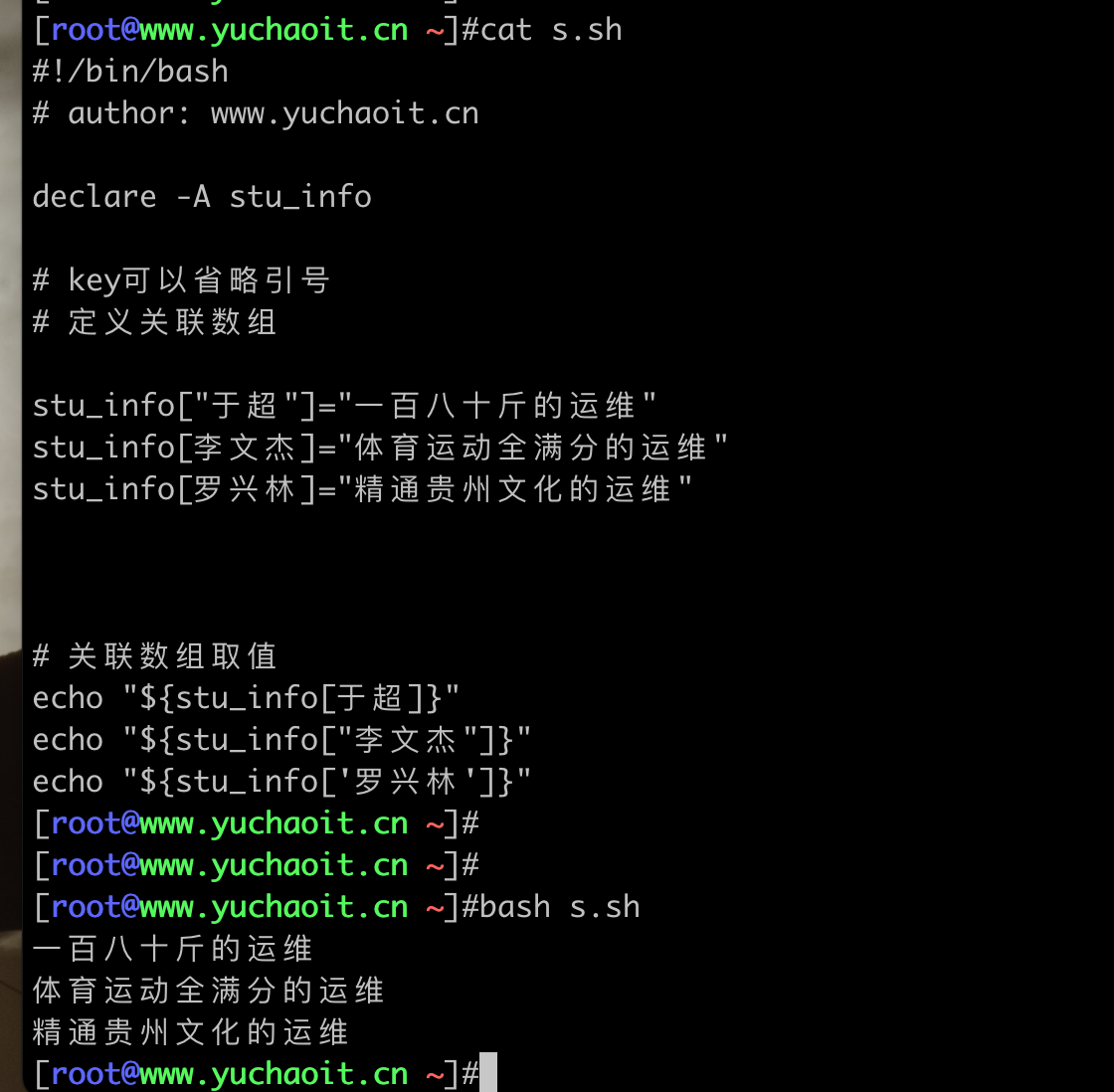
提取关联数组所有索引
1. 必须先用declare -A命令定义,然后才能创建关联数组
#!/bin/bash
# author: www.yuchaoit.cn
declare -A stu_info
# key可以省略引号
# 定义关联数组
stu_info["于超"]="一百八十斤的运维"
stu_info[李文杰]="体育运动全满分的运维"
stu_info[罗兴林]="精通贵州文化的运维"
# 关联数组取值
# echo "${stu_info[于超]}"
# echo "${stu_info[李文杰]}"
# echo "${stu_info[罗兴林]}"
# 提取所有索引(key)
echo "关联数组stu_info的所有key是:${!stu_info[@]}"
echo "关联数组stu_info的所有key是:${!stu_info[*]}"5.数组取值语法小结
#!/bin/bash
# author: www.yuchaoit.cn
echo ${!stu_info[*]} # 获取数组所有索引
echo ${!stu_info[@]} # 获取数组所有索引
echo ${stu_info[@]} # 获取数组所有元素
echo ${stu_info[*]} # 获取数组所有元素
echo ${#stu_info[*]} # 获取数组所有元素个数
echo ${#stu_info[@]} # 获取数组所有元素个数
echo ${stu_info[key]} # 根据key,提取value6.数组增删改查
#!/bin/bash
# author: www.yuchaoit.cn
# 增加数组元素,利用+=操作符可以添加
stus=(于超 罗兴林 张鑫 郑佳强)
echo "当前数组元素是: ${stus[@]}"
# 添加元素
stus+=(三胖 狗蛋)
echo "添加后的,数组元素是: ${stus[@]}"
# 修改第三个元素的值
stus[2]="黑旋风李逵"
echo "修改后的,数组元素是: ${stus[@]}"
# 删除数组元素
# 删除李逵和 罗兴林
unset stus[1]
unset stus[2]
echo "删除后的,当前数组元素是:${stus[@]}"7.遍历数组
# 基本语法
#!/bin/bash
# author: www.yuchaoit.cn
stus=(于超 罗兴林 张鑫 郑佳强)
# 语法1,直接提取所有元素
for res in ${stus[@]}
do
echo $res
done
echo "-------"
# 语法2,提取所有索引,然后再取值
for index in ${!stus[@]}
do
echo ${stus[${index}]}
done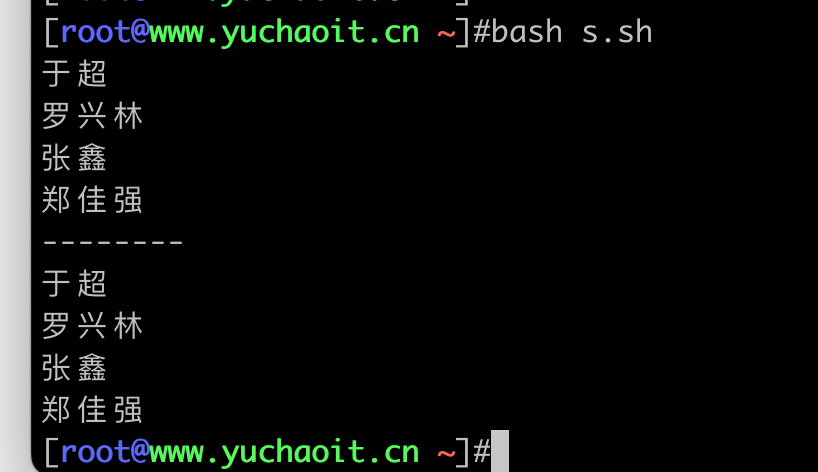
8.shell数组实践案例
统计/etc/passwd中的登录shell字段出现次数
#!/bin/bash
# author: www.yuchaoit.cn
#
declare -A shell_count
exec </etc/passwd
while read line
do
shell=$(echo $line |awk -F: '{print $NF}')
# 将每一个shell作为key,出现次数作为value
# 在循环体重,同一个shell的话,自增+1
let shell_count[${shell}]++
done
# 打印数组查看
echo "关联数组,shell_count数据是:${shell_count[@]}"
echo "该数组完整形式是:$(set|grep ^shell_count)"
echo '-----------------'
# 循环打印具体的key,value
# 提取所有key,然后根据key获取值
for item in ${!shell_count[@]}
do
echo -e "索引是:$item\n(该登录shell出现次数)是${shell_count[${item}]}"
done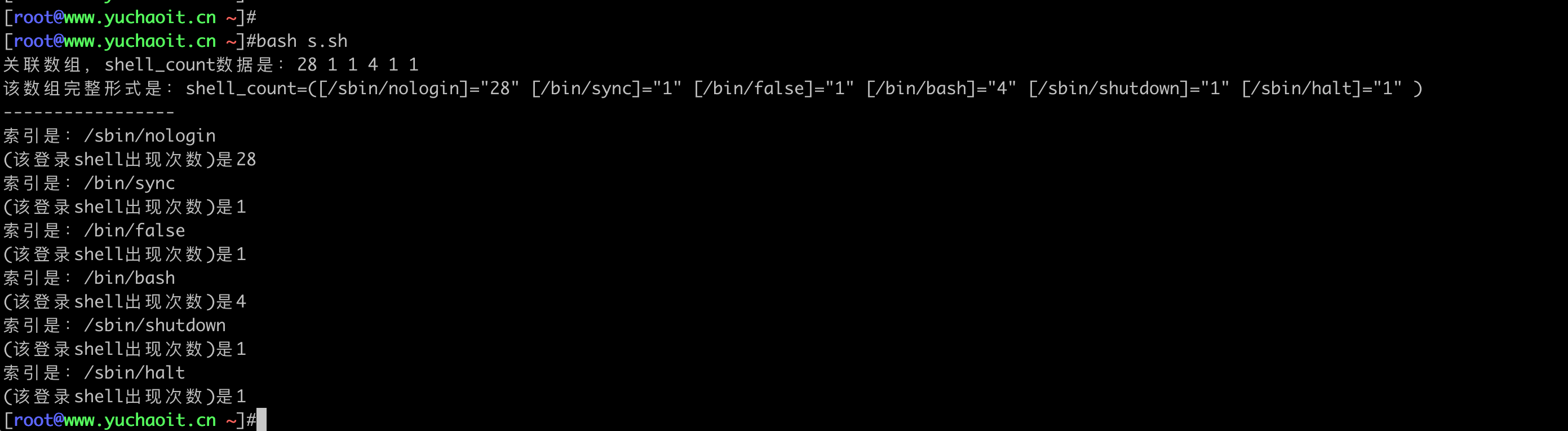
9.使用数组分析Nginx日志
统计Nginx的ip、以及出现次数,保存为关联数组数据。
#!/bin/bash
# author: www.yuchaoit.cn
declare -A ip_count
exec < /var/log/nginx/www.yuchaoit.cn.log
while read line
do
remote_ip=$(echo $line | awk '{print $1}')
# 一样的套路,直接累加赋值
let ip_count[$remote_ip]++
# 写法一个意思
# ip_count[$remote_ip]=$[ ip_count[$remote_ip] + 1]
done
for item in ${!ip_count[@]}
do
echo -e "该IP: {$item} 出现的次数是:${ip_count[${item}]}"
done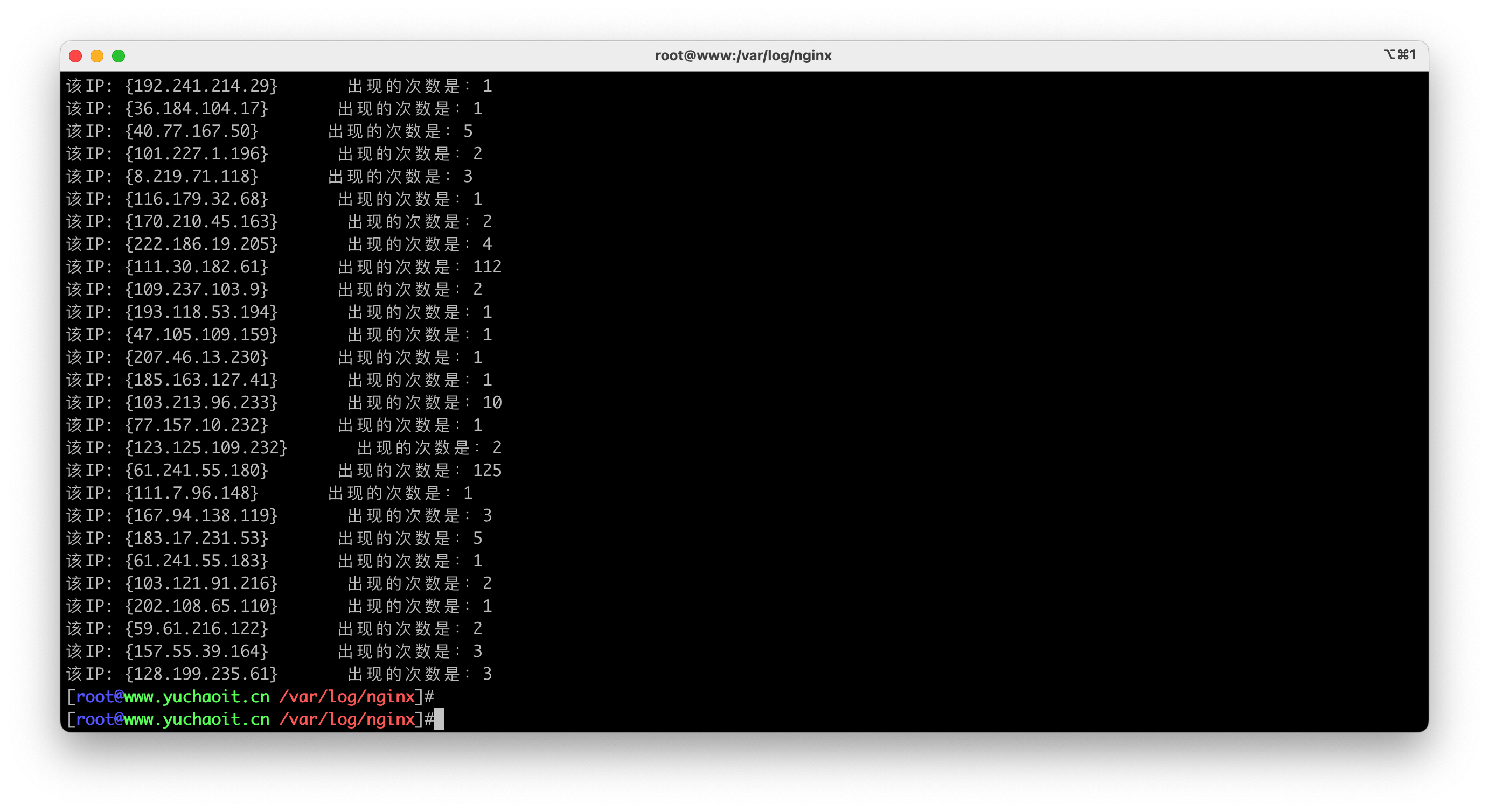
10.建议用awk进行统计处理
第九题的shell写法,其实非常耗时。
当我吧文件数据,增加到10万行后,脚本执行的时间,已经很恐怖了。
[root@www.yuchaoit.cn /var/log/nginx]#cat www.yuchaoit.cn.log |wc -l
100000
[root@www.yuchaoit.cn /var/log/nginx]#
[root@www.yuchaoit.cn /var/log/nginx]#time bash s.sh
部分信息
该IP: {59.61.216.122} 出现的次数是:2
该IP: {157.55.39.164} 出现的次数是:199
real 3m27.642s 好家伙,执行了三分钟,这也忒慢了
user 1m38.241s
sys 1m33.042s
[root@www.yuchaoit.cn /var/log/nginx]#改为awk关联数组写法
real 0m0.002s real 是命令从开始到结束的时间,
user 0m0.000s cpu执行进程耗时
sys 0m0.002s 系统内核执行的耗时
[root@www.yuchaoit.cn /var/log/nginx]#time awk '{ip_count[$1]++} END{for (item in ip_count) print "IP是:" item, "出现次数:" ip_count[item] }' www.yuchaoit.cn.log
所以在我们学完了基础语法后,你会发现,未来的路还很长,除了要完成功能,你还要不断学习,优化程序,考虑效率。
在有现成的工具,优秀的命令,软件,能解决你的问题时;
千万别去自己造轮子,费力不讨好,学习工具,解决问题是第一生产要素。