实验07 Pandas合并与级联
实验学时:2学时
实验类型:验证
实验要求:必修
一、实验目的
- 掌握pandas合并/拼接
- 掌握pandas级联
二、实验要求
利用pandas合并、拼接和级联等知识在PyCharm中编写程序,实现Python数据处理的相关操作。
三、实验内容
任务1.现有如下图的两个DataFrame 数据(如图1),采用Pandas中的merge()函数,将两组数据合并成第三组数据(如图2),再级联成第四组数据(如图3),用Python编写程序实现。
=左边的数据帧=
id Name subject_id
0 1 Alex sub1
1 2 Amy sub2
2 3 Allen sub4
3 4 Alice sub6
4 5 Ayoung sub5
=右边的数据帧=
id Name subject_id
0 1 Billy sub2
1 2 Brian sub4
2 3 Bran sub3
3 4 Bryce sub6
4 5 Betty sub5
图1
=合并的数据帧=
id_x Name_x subject_id id_y Name_y
0 2 Amy sub2 1 Billy
1 3 Allen sub4 2 Brian
2 4 Alice sub6 4 Bryce
3 5 Ayoung sub5 5 Betty
图2
=级联的数据帧=
id Name subject_id
0 1 Alex sub1
1 2 Amy sub2
2 3 Allen sub4
3 4 Alice sub6
4 5 Ayoung sub5
5 1 Billy sub2
6 2 Brian sub4
7 3 Bran sub3
8 4 Bryce sub6
9 5 Betty sub5
图3
任务2. 将数据文件:xmut0.xlsx中所有工作表“1班期末成绩表——6班期末成绩表”合并成一个DataFrame,并写入xmut1.xlsx文件中。用python编程产生如下数据(即数据的合并)。
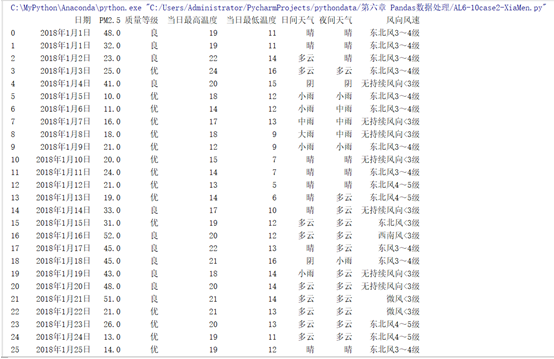
任务3. 将数据文件:Xiamen_2018.csv中数据清洗成如下图所示。用python编程实现。
test7.py
import pandas as pd
pd.set_option("display.unicode.ambiguous_as_wide", True)
pd.set_option("display.unicode.east_asian_width", True)
pd.set_option("display.width", None)
def task1():
# 左边的数据帧
left_df = pd.DataFrame({
'id': [1, 2, 3, 4, 5],
'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
'subject_id': ['sub1', 'sub2', 'sub4', 'sub6', 'sub5']
})
# 右边的数据帧
right_df = pd.DataFrame({
'id': [1, 2, 3, 4, 5],
'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
'subject_id': ['sub2', 'sub4', 'sub3', 'sub6', 'sub5']
})
# 合并两个数据帧
merged_df = pd.merge(left_df, right_df, how='inner', on='subject_id', suffixes=('_x', '_y'))
# 输出合并的数据帧
print("合并的数据帧:")
print(merged_df)
# 级联两个数据帧
concatenated_df = pd.concat([left_df, right_df])
# 输出级联的数据帧
print("\n级联的数据帧:")
print(concatenated_df)
def task2():
# 读取 Excel 文件中的所有工作表
file_path = 'xmut0.xlsx'
xls = pd.ExcelFile(file_path)
sheet_names = xls.sheet_names
# 初始化一个空的 DataFrame 用于存储合并后的数据
merged_df = pd.DataFrame()
# 遍历所有工作表并合并数据
for sheet_name in sheet_names:
df = pd.read_excel(file_path, sheet_name)
merged_df = pd.concat([merged_df, df], ignore_index=True)
# 将合并后的数据写入新的 Excel 文件
output_file = 'xmut1.xlsx'
merged_df.to_excel(output_file, index=False)
print(f"合并后的数据已写入 {output_file}")
def Data_split(df, columns, H_name, L_name):
temp = df[columns].str.split("/", expand=True) # 按宁符/分割列
df[H_name] = temp[0]
df[L_name] = temp[1]
df.drop(columns, axis=1, inplace=True)
return df
def sub(number):
count = ""
for i in number:
if i == "℃":
break
count += i
return int(count)
def task3():
df = pd.read_csv('Xiamen_2018.csv')
df.ffill(inplace=True)
df = Data_split(df, "气温", "当日最高温度", "当日最低温度")
df = Data_split(df, "天气状况", "日间天气", "夜间天气")
df = Data_split(df, "风力风向", "风向风速", "风向")
df.drop("风向", axis=1, inplace=True)
df["当日最高温度"] = df["当日最高温度"].map(sub)
df["当日最低温度"] = df["当日最低温度"].map(sub)
print(df)
df.to_csv('cleaned_xiamen_2018.csv', index=False)
if __name__ == '__main__':
task1()
task2()
task3()