I/O操作
所有对流的操作都称之为I/O操作
当流没有数据read时或者流已经满了无法在write时,会出现阻塞现象
阻塞场景:一段流中wirte端写入数据时,read端读取。wirte端无数据时read端会阻塞等待直到有数据,但是在多个wirte端同时写入时会互斥也是说同一时刻read端只能处理一个wirte端的数据,需要创建多个read端和流来处理。这种方式在没有IO复用的方案的单线程计算机时代就是灾难
解决阻塞死等待方案:
非阻塞,忙轮询:read端在处理完某一wirte端后,主动读取其他wirte端的数据流(并发效果),但对于其他wirte端来说效率还是低下
select:申请一段内存代收多个wirte段的数据流,当select有数据时read端只需要负责读取,但是读取select时只知道流的数量不知道具体某个wirte端的数据流,想要读取具体的流只能遍历所有流找到自己想要的流。
epoll:相对于select,epoll会对流进行标记,读取想要的流时只需要根据epoll返回的fd找到想要的流
分布式从ACID、CAP、BASE的理论推进
ACID理论:事务是一种将所有操作归纳成一个不可分割的执行单元,事务执行时其中任意一项操作失败整个事务都将回滚,需要保证事务的数据通常存储在数据库,ACID指数据库事务正确执行的四个特性的缩写:
原子性(Atomicity):保证事务执行时任意一项操作失败都将回滚
一致性(Consistency):保证事务执行时涉及的数据在事务执行完成后(不论失败或成功)的完整
隔离性(Isolation):并发事务同时访问同一数据时造成交叉执行导致的数据不一致,确保当前事务执行完成才会执行下一事务
持久性(Durability):事务处理结束后对数据的修改是永久的,即便系统故障也不会丢失
本地事务ACID实现上可用 “统一提交,失败回滚” 几字总结,严格保证了同一事务内数据的一致性,而分布式不能实现这种ACID,因为有CAP理论约束。
CAP理论:在一个分布式计算机系统中,一致性(Consistency)、可用性(Availability)、分区容错(partition-tolerance),这三种特性无法得到同时满足,最多满足两个(CA,CP,AP)。
从某一业务场景分析CAP的每个特点的含义:

该场景整体分为5个流程:
流程一、客户端发送请求(如:添加订单、修改订单、删除订单)
流程二、Web业务层处理业务,并修改存储成数据信息
流程三、存储层内部Master与Backup的数据同步
流程四、Web业务层从存储层取出数据
流程五、Web业务层返回数据给客户端
一致性是指更新数据后从任意节点读取的数据都是最新的状态,CAP的一致性还分为强一致性、弱一致性、最终一致性等级别。在写入主数据库后,在向从数据库同步期间要将从数据库锁定,同步完成后再释放,避免读到从数据库的旧数据。
分布式一致性的特点:1.由于存在数据同步过程,写操作的响应有延迟。
2.为了保证数据一致性同步过程中资源会暂时锁定,数据同步完成后再释放锁定的资源
3.如果请求的数据同步失败则会返回错误信息,一定不会返回旧数据
可用性是指服务一直可用,而且是正常响应时间。当主数据库正在写入数据时,其他从数据库在收到查询请求能够立刻响应,从数据库不允许出现响应超时或响应错误。为保证可用性应写入主数据库后立刻响应再异步请求同步数据,哪怕未同步完成查询到从数据库的旧数据也要保证从数据库的响应。
分布式可用性的特点:所有请求都有响应且不会出现响应超时或响应错误
分区容错性是指分布式系统中,部分节点出现消息丢失或故障,系统应继续运行。分布式系统的各个节点部署在不同子网,不可不避免的会出现由于网络问题而导致的节点之间通信失败,此时仍对外提供服务。尽量使用异步取代同步操作这样节点之间能有效的实现松耦合。添加从数据库节点这样其中一个从数据库挂掉其他从数据库节点提供服务。
分区容错性是分布式系统的基本能力。
CAP的 3选2 证明
一致性C的特性:数据同步时锁定资源保证数据的一致性,但会导致数据同步过程中资源无法访问直到同步结束
可用性A的特性:用户请求任意节点的服务都要立刻响应结果,因此数据必须异步更新但这会导致数据不一致
分区容错性P特性:分区后任意节点脱离系统(故障)都不会影响其他节点的正常运作
CA放弃P:一个分布式系统不可能不满足P,放弃P即不进行分区这样就不用考虑数据同步问题,那么这个系统就不是一个标准的分布式系统。对于一个分布式系统来说P是一个基本要求,CAP三者中只能在CA两者之间做权衡,并且要想尽办法提升P。
CP放弃A:一个分布式系统如果不强求可用性容许系统停机或者长时间无响应的话则可以放弃A。比如跨行转账,一次转账请求要等待双方系统都完成这个事务才算完成。
AP放弃C:追求分区容错性和可用性是很多分布式系统设计时的选择,实现AP前提是用户接受所查数据一定时间内不是最新的即可。通常实现AP都会保证最终一致性。比如淘宝订单退款,今日退款成功,明天账户到账。再比如12306购票,显示还有余票但是在付款时提示没有余票,都是在CA之间舍弃了C选择A。但这只是舍弃了强一致性,退而其次选择最终一致性。
BASE理论:Basically Available(基本可用),Soft state(软状态),Eventually consistent(最终一致性),BASE是CAP对一致性和可用性权衡的结果,是基于CAP演变而来的,其核心思想是即使无法做到强一致性,但每个应用都可以根据自身业务特点采用适当方法使系统达到最终一致性。
两个对冲的理念ACID和BASE:ACID是传统数据库常用的设计理念,追求强一致性。BASE支持大部分大型分布式系统,提出通过牺牲强一致性获得高可用性。
Basically Available(基本可用):实际上就是两个妥协,对响应时间上的妥协(搜索引擎响应时间是0.5秒,但由于出现故障增加到1-2秒) 和 对功能损失上的妥协(淘宝双十一高峰期部分消费者会被引导到一个降级页面让一些功能无法使用)。
Soft state(软状态):原子性(硬状态)要求所有节点数据都是一致的,软状态(弱状态)允许数据存在中间状态并认为该状态不影响系统的整体可用性即存在数据延迟。
Eventually consistent(最终一致性):软状态必须有时间限制,限期过后要保证所有节点的数据的一致性。这个时间期限取决于网络延时、系统负载、数据复制方案设计等等因素。
BASE总结:BASE理论是面向大型高可用可扩展的分布式系统,和所有传统事务ACID是相反的。牺牲强一致性来获得可用性并允许一段时间的数据不一致。
GMP设计思想及原理
在多进程/多线程的操作系统中,CPU调度算法(如CFS)会保证每一个 进程/线程 都被分配到时间片,但是 进程/线程 的创建、切换、销毁会占用很多资源,如果 进程/线程 过多CPU很多资源都会被这样浪费,而且多线程开发设计会变得更加复杂,要考虑同步竞争、锁、冲突等。大量的进程/线程会高内存占用,调度的高消耗CPU。
线程分为内核级线程和用户级线程,用户级线程由应用程序管理,当用户级线程被创建时线程库会将线程的执行映射到一个或多个内核级线程上。CPU对用户级线程无感只会执行被映射后的内核级线程,内核级线程由操作系统的调度算法和线程同步来管理。
一个用户态线程必须绑定一个内核态线程,CPU不知道用户态线程的存在,它只知道它运行的是一个内核态线程,再细分一下内核态线程依然叫线程(thread),用户态线程叫协程(co-routine)。一个协程可以绑定一个线程,那么多个协程绑定一个线程呢,有三种协程和线程的映射关系。
N:1关系:N个协程绑定一个线程,优点在于协程的切换可以在用户态完成,不会陷入到内核态,这种切换非常轻量快速,但缺点是一个进程的协程都绑定到一个线程上当某个协程阻塞该进程的其他协程都无法执行,根本没有并发的能力了。
1:1关系:协程的调度都由CPU完成,不存在N:1的缺点,但协程的创建、销毁、切换都非常浪费CPU。
M:N关系:M个协程绑定N个线程,克服了以上两种调度模型的缺点,但实现起来最为复杂。
Go语言的协程goroutine采用了M:N调度模型,2012年之前调度器性存在问题在使用4年后重新设计了调度器。在新调度器中除了协程G(goroutine)和线程M(machine),又引进了调度器P(processor)。
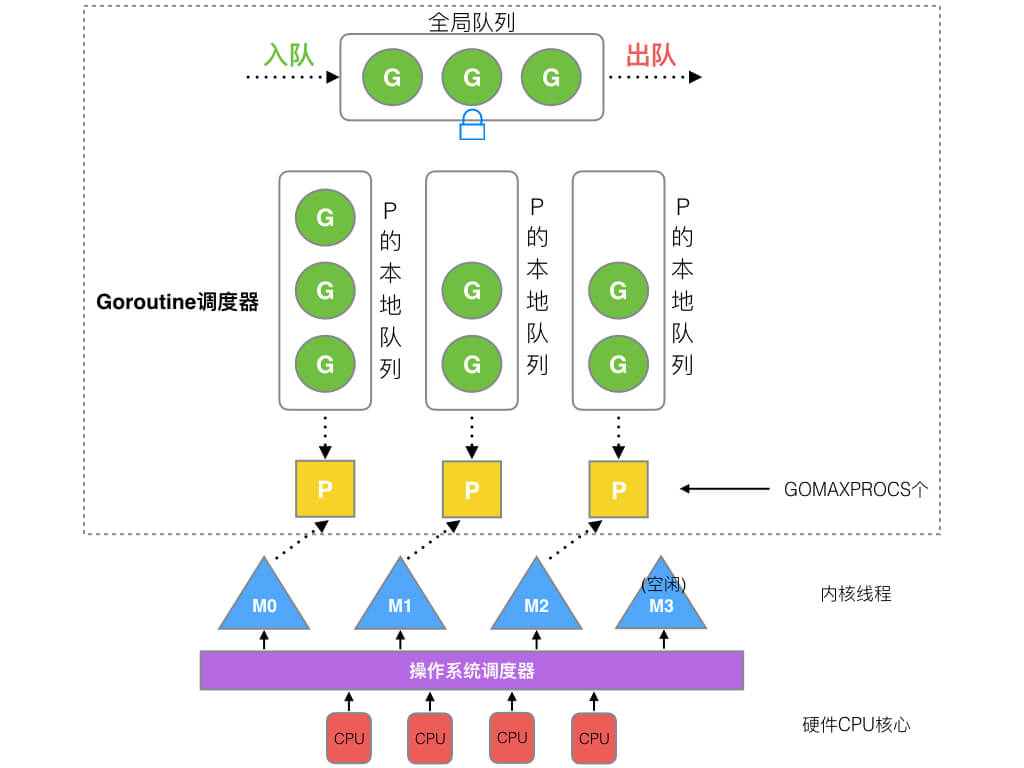
全局队列(global queue),存放待运行的G,容纳数量取决于可用内存大小,但goroutine太多会影响调度器性能。
P的本地队列,每个P都会维护一个类似全局队列的本地队列但最多容纳256个,新建G时优先加入本地队列,如果队列满了会拿一半G放入全局队列。
G:goroutine协程是进程维护的最小执行单位。
M:machine是用户态系统线程,M想要执行G必须通过调度器绑定P获取。
P:processor在程序启动时创建,最多有GOMAXPROC(可配置)个。
Goroutine调度器和OS调度器是通过M结合起来的,每个M都代表了1个用户态系统线程,OS调度器负责把用户态线程映射给内核态线程再让CPU执行。
M和P是多对多的关系,P的数量可以根据环境变量#GOMAXPROCS或者runtime.GOMAXPROCS()决定。在go中默认M的最大数量为1000个,但内核很难支持这么多所以可以忽略,还可以通过runtime/debug中的SetMaxThread()来设置M的最大数量。M和P是没有绝对关系的,一个M阻塞后P就会去创建或者切换到另一个M,所以即使只有一个P也会存在多个M。
P只是调度器里的一个逻辑概念,而不是独立存在的,P的工作都是由调度器完成。G的每次切换都会涉及唤醒调度器的操作,唤醒调度器分为显式和隐式,可以通过runtime.Gosched()主动让出时间片或time.Sleep()等 会使G进入阻塞状态的方法显式唤醒调度器。当满足一些特殊条件可以隐式唤醒调度器(比如:当前G的时间片用完会将其放回本来的队列或全局队列中,选择另外一个G执行,这个过程是处理器自动完成不需要主动的显式调用任何函数来唤醒调度器)。
GMP的本质其实就是G和M之间多了一个P,P是调度器的抽象逻辑。每个G都有独立的用户态栈其默认大小为2kb,栈不足时可以动态扩展到2gb,因为G所需内存较小所以创建和销毁的开销都比较小,这也是Go的核心之一。而M是用户态的系统线程可以根据P的调度轮流切换执行G,M同一时间只能绑定一个P但不局限于某一个P,M空闲时会被标记为休眠状态以便复用,如果M长时间处于空闲状态调度器会根据一定策略销毁一部分。
调度器的设计策略:复用线程避免频繁创建、销毁线程。
1.work stealing(工作窃取)机制,当前M没有可执行G时会尝试从其他P里窃取G,其他P也没有待执行G时再尝试从全局队列获取G(但会涉及到全局队列的资源互斥这需要锁),而不是销毁M,实在没有待执行的G时会进入休眠状态直到被重新唤醒或被回收释放。
2.hand off(移交)机制,当前M因为系统调用阻塞时会把当前P重新绑定给其他空闲的M(没有就新建M)。
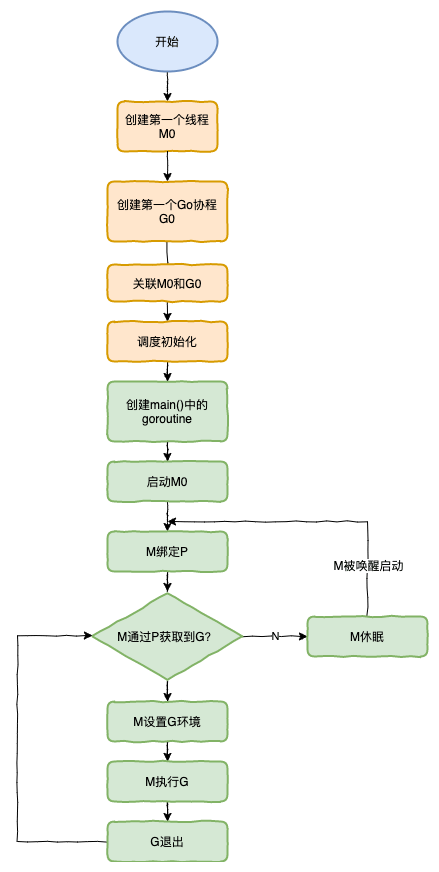
调度器的生命周期:在go中有一个特殊的M0和G0,M0是go程序启动main()之前创建的系统线程,不执行用户代码,它的主要任务是初始化环境并创建其他M和G0,每个与P绑定的M都会有G0,G0的数量等于P,M0再初始化完后会进入休眠状态等待唤醒,和其他M无异。G0的栈大小固定,调用栈不会被回收等,G0由系统管理应用程序无法直接控制,它还可以执行系统级任务比如垃圾回收调度器初始化等。当调度器要进行切换G或者移交P时都会调用G0进行操作。
垃圾回收(Garbage Collection)
V1.3之前的标记清除(mark and sweep)算法:第一步暂停程序业务逻辑即STW(stop the work),扫描对象且进行标记找出不可到达的对象。第二步清除未被标记的不可到达的对象。第三步继续运行程序



mark and sweep的缺点:STW,标记时需要扫描整个heap,清除对象时产生heap碎片。
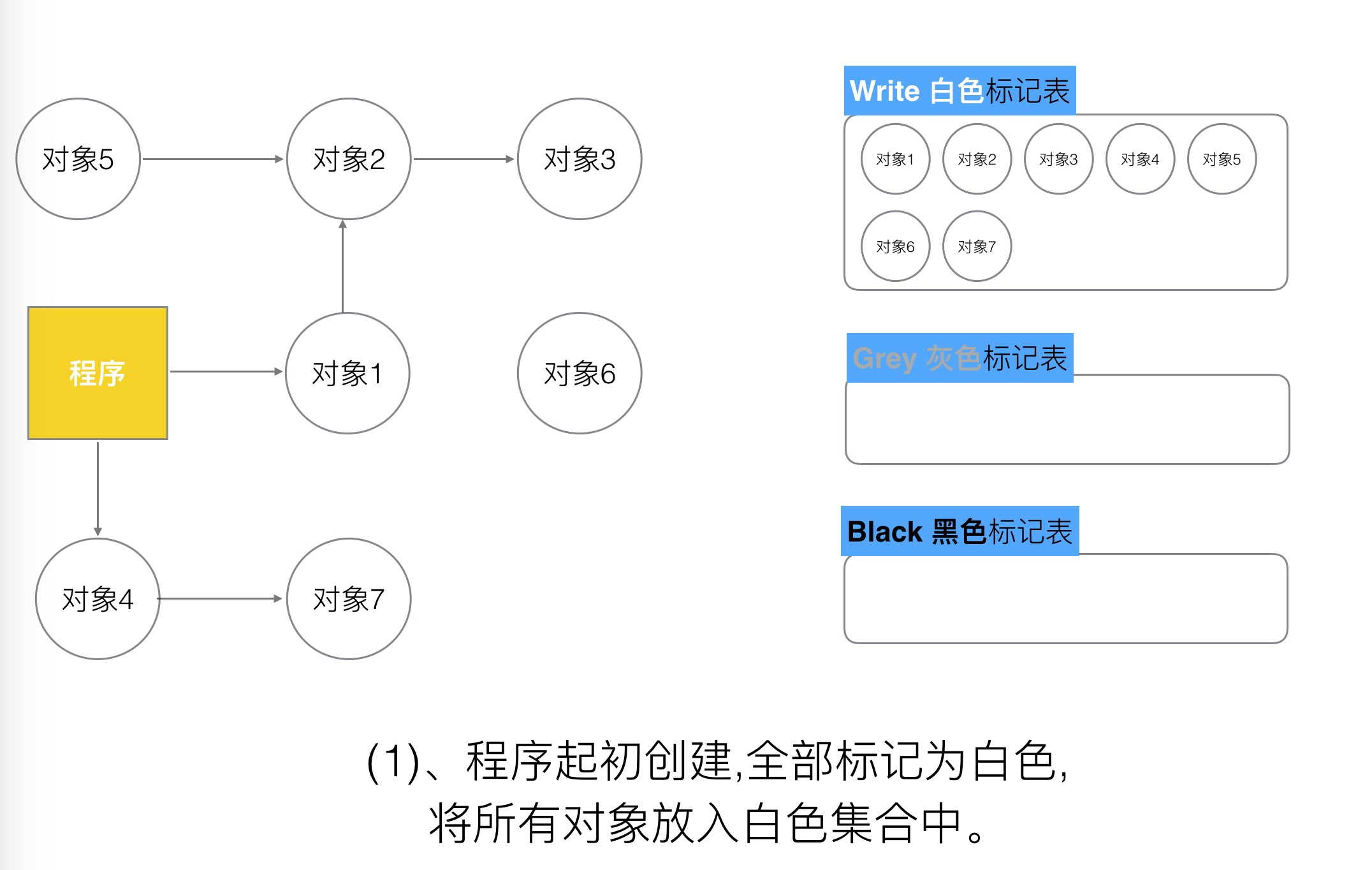
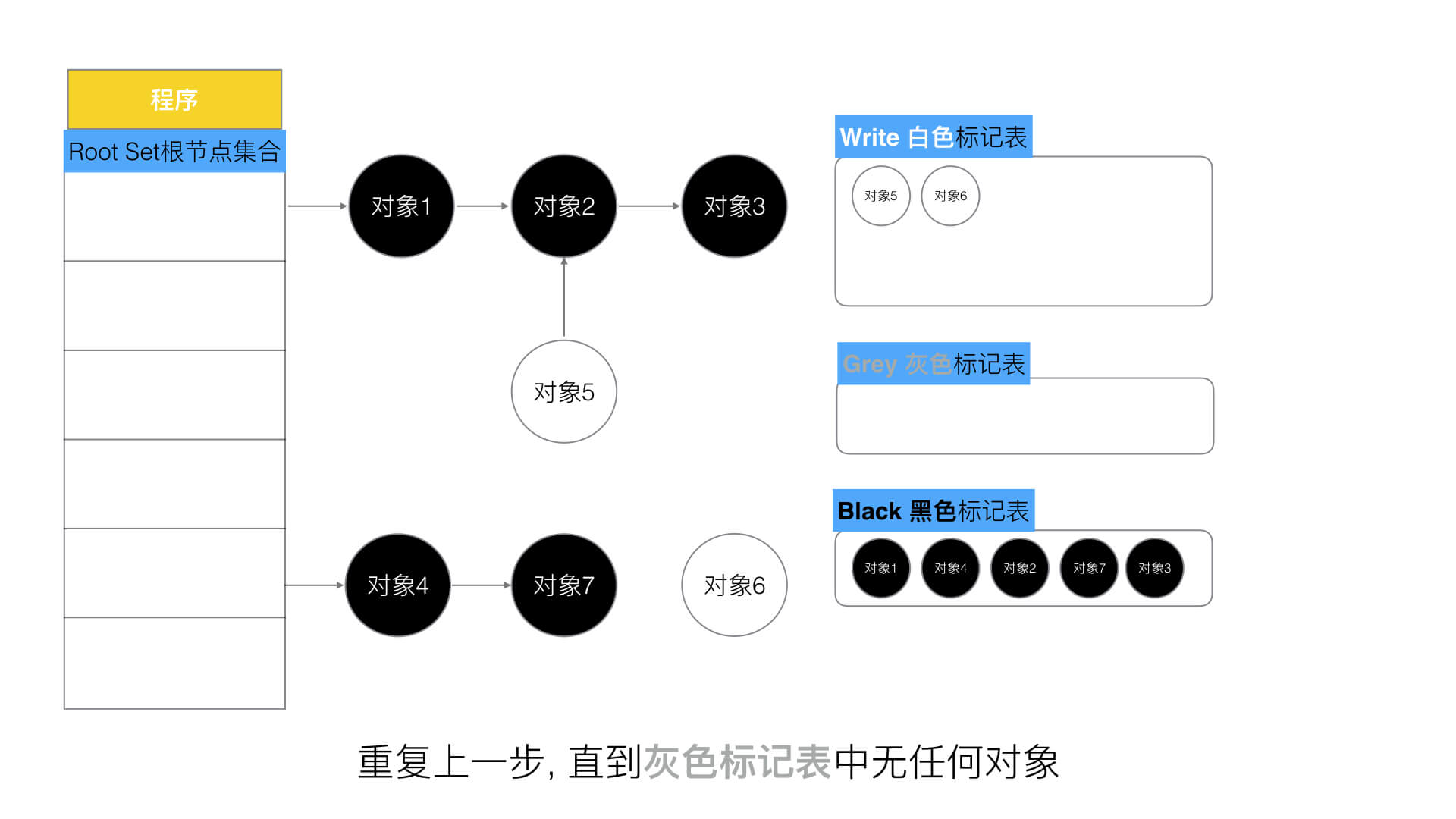
v1.5之后三色并发标记法:第一步将所有新建的对象默认为白色对象并加入白色表。
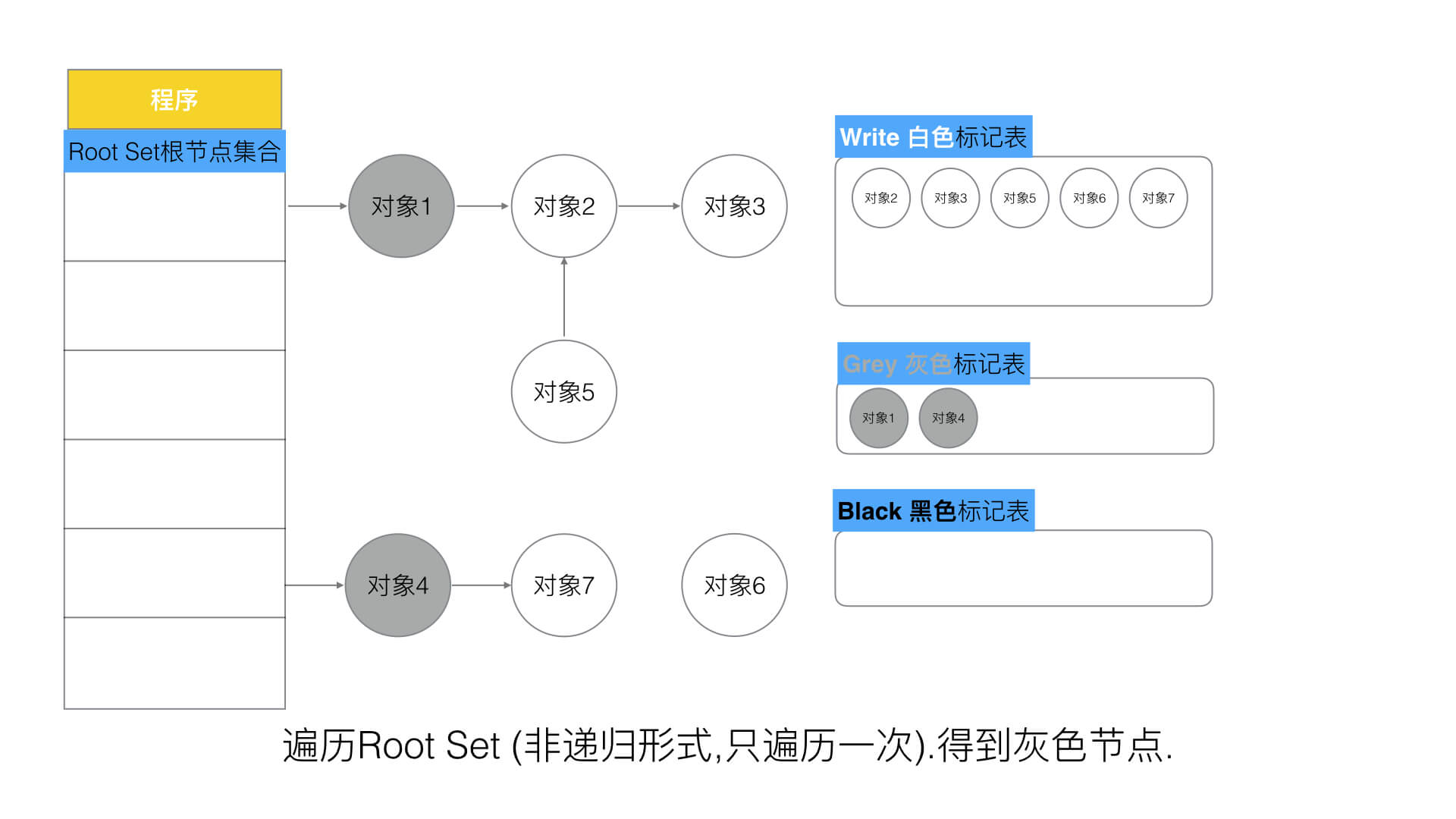
第二步每次GC回收都只会遍历一层而不是递归式的遍历,遍历所有根节点把第一层白色对象加入灰色对象表。
第三步遍历灰色对象表把它下一层的所有下游对象加入到灰色对象表中,当前灰色对象本身则加入到黑色对象表。
第四步重复第三步直到没有灰色对象为止。
第五步清除所有白色对象。



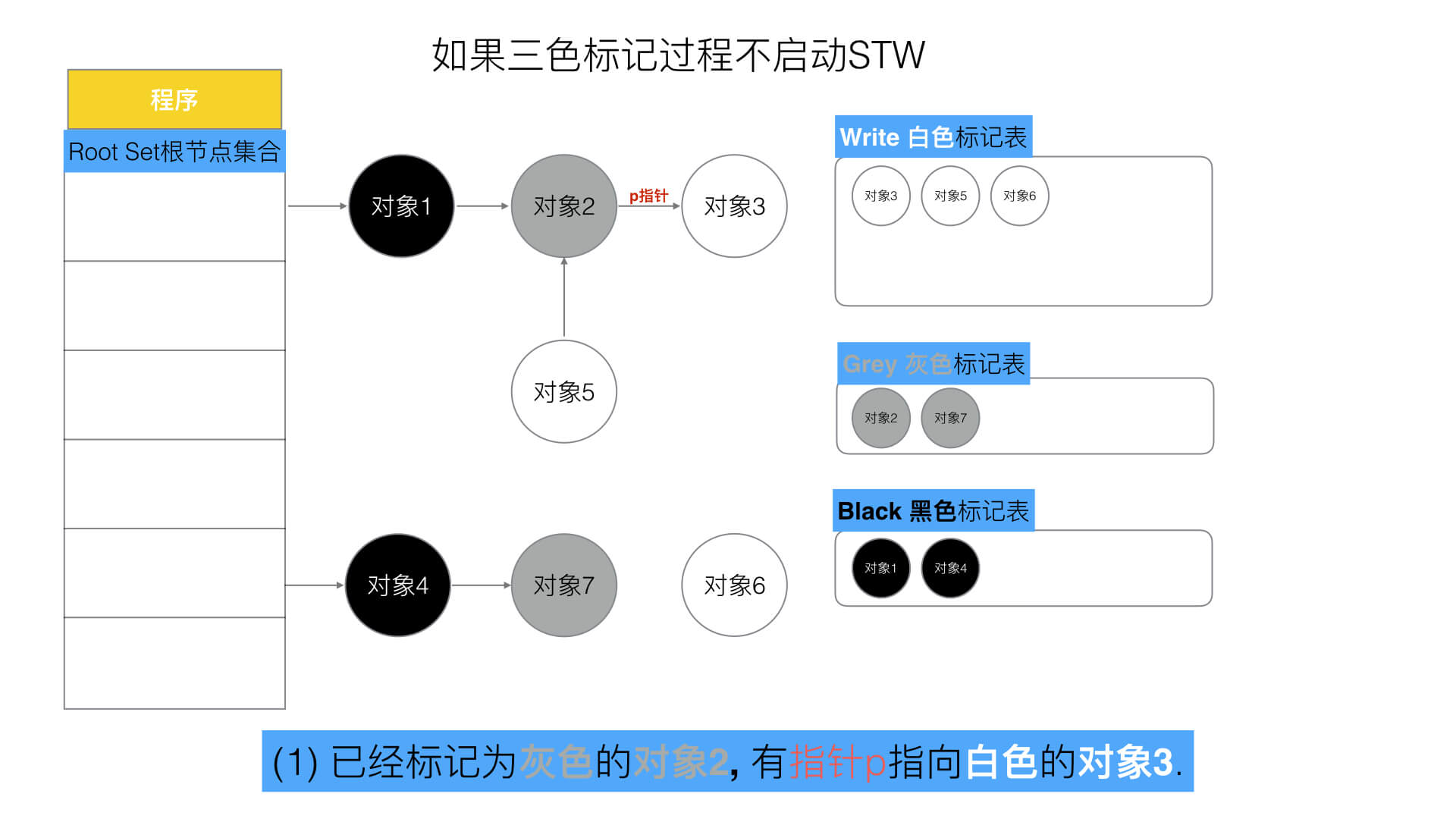
三色标记如果没有STW保护可能会出现在标记过程中,黑色对象引用了某个被灰色对象创建后又取消引用的白色对象或者黑色对象新建了一个对象默认白色的,这会导致对象丢失。但如果使STW过程中直接禁止其他用户程序对对象的引用这一干扰会导致性能有很大影响。所以go有一个屏障机制避免黑色对象引用到被灰色对象创建且取消引用的白色对象这两个条件。
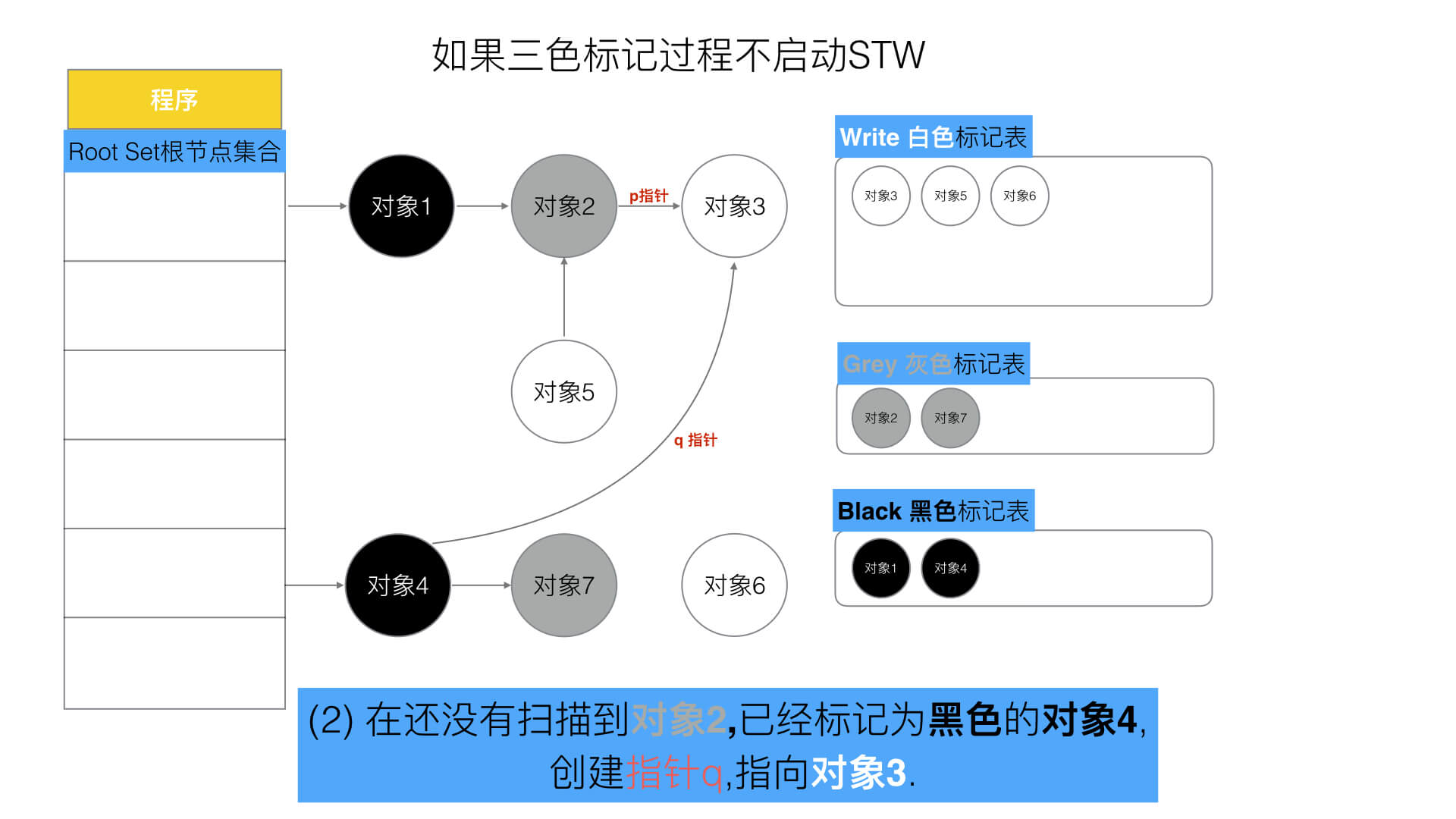


屏障机制:强、弱三色不变式
强三色:不存在黑色引用白色对象的指针

弱三色:所有被黑色对象引用的白色对象都必须在灰色对象的保护下

满足这两种情况可保对象不丢失,通过这两种机制golang团队可以初步得到两种保护对象的屏障方式
插入时的屏障:强三色不变式(不存在黑色对象引用白色对象的情况了, 因为白色会强制变成灰色)
具体操作:黑色A对象新建了一个B对象(默认白色)时,B必须标记为灰色对象
伪代码:
添加下游对象(当前下游对象slot,新下游对象ptr){
//1
标记灰色(新下游对象ptr)
//2
当前下游对象slot=新下游对象ptr
}
场景:A.添加下游对象(nil,B) //A之前没有下游对象,新添加一个下游对象B,B标记为灰色。
A.添加下游对象(C,B) //A将原本的下游C变成B且标记为灰,C没有了上游等待被回收。
这段伪代码就是插入屏障的逻辑,但内存槽有两种位置,栈和堆,栈空间特点是容量小但要求响应速度快,因为"插入屏障"频繁调用所以这个机制不会在栈空间的对象操作中使用,仅仅使用在堆空间的对象操作中。
删除时的屏障:弱三色不变式(保护灰色对象到白色对象的路径不会断)
具体操作:被删除的对象如果本身是灰色或者白色,那么被标记灰色
伪代码:
添加下游对象(当前下游对象slot,新下游对象ptr){
//1
if(当前下游对象slot是灰色 || 当前下游对象slot是白色){
标记灰色(当前下游对象slot)
}
//2
当前下游对象slot=新下游对象ptr
}
场景:A.添加下游对象(B,nil) //A的下游原本是B,把A下游指向空从而删除B,把B标记为灰色
A.添加下游对象(B,C) //A的下游原本是B,把A下游指向C,把B标记为灰色(如果B本身白色)
这段伪代码就是删除屏障的逻辑,这种方式回收精度低,下游对象即使被删除了依旧可以活过这一轮,需要在下一轮GC才会被清理掉。
插入/删除屏障的缺点:插入屏障只有在堆里面使用,结束时需要STW来重新扫描标记栈上的白色对象
删除屏障回收精度低,GC开始时STW扫描堆栈来记录初始快照,这会保留开始时刻的所有存活对象
v1.8的混合写屏障(hybrid write barrier)机制,避免了对栈的reScan的过程,极大的减少了STW时间。
变形的弱三色不变式,具体操作:
1.GC开始时扫描栈上可到达的对象并标记为黑色,之后不会在进行第二次重复扫描,无需STW
2.GC期间任何栈上创建的新对象均为黑色
3.被删除的对象标记为灰色
4.被添加的对象标记为灰色
伪代码:
添加下游对象(当前下游对象slot,新下游对象ptr){
//1
标记灰色(当前下游对象slot) //只要当前的下游对象被移走,该下游对象就标记为灰色
//2
标记灰色(新下游对象ptr)
//3
当前下游对象slot=新下游对象ptr
}
这段伪代码操作不会在栈上应用,因为要保障栈的效率