DataX3.0快速入门
一、DataX3.0概览
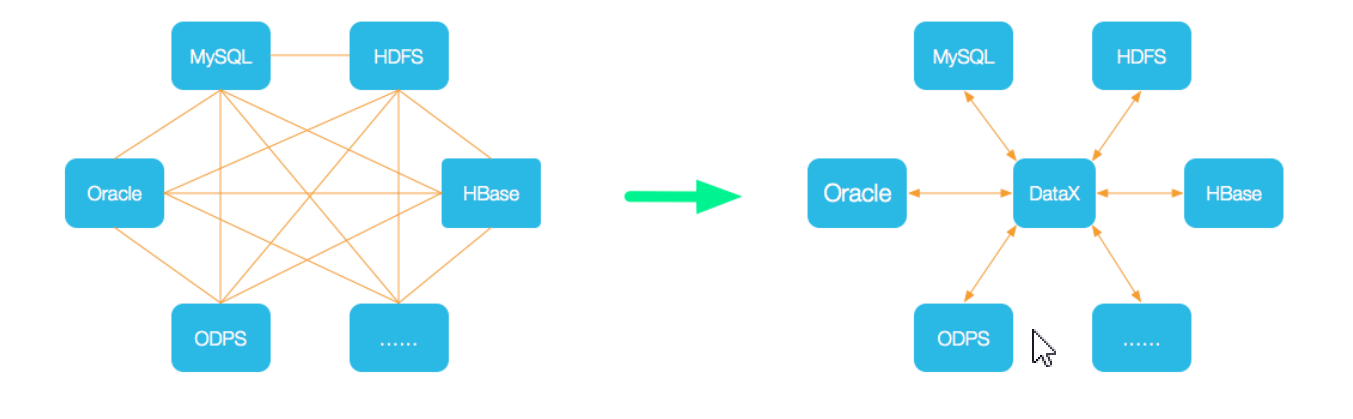
DataX是阿里云DataWorks数据集成的开源版本,在阿里巴巴集团内部被广泛使用的离线数据同步工具/平台。解决了数据库之中的数据同步、迁移问题,把网状结构转为星型结构,主要用于数据库之间传送业务数据。
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。
当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
Github主页地址:https://github.com/alibaba/DataX
Github下载地址:https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz
- 数据仓库的分层图:

二、插件体系
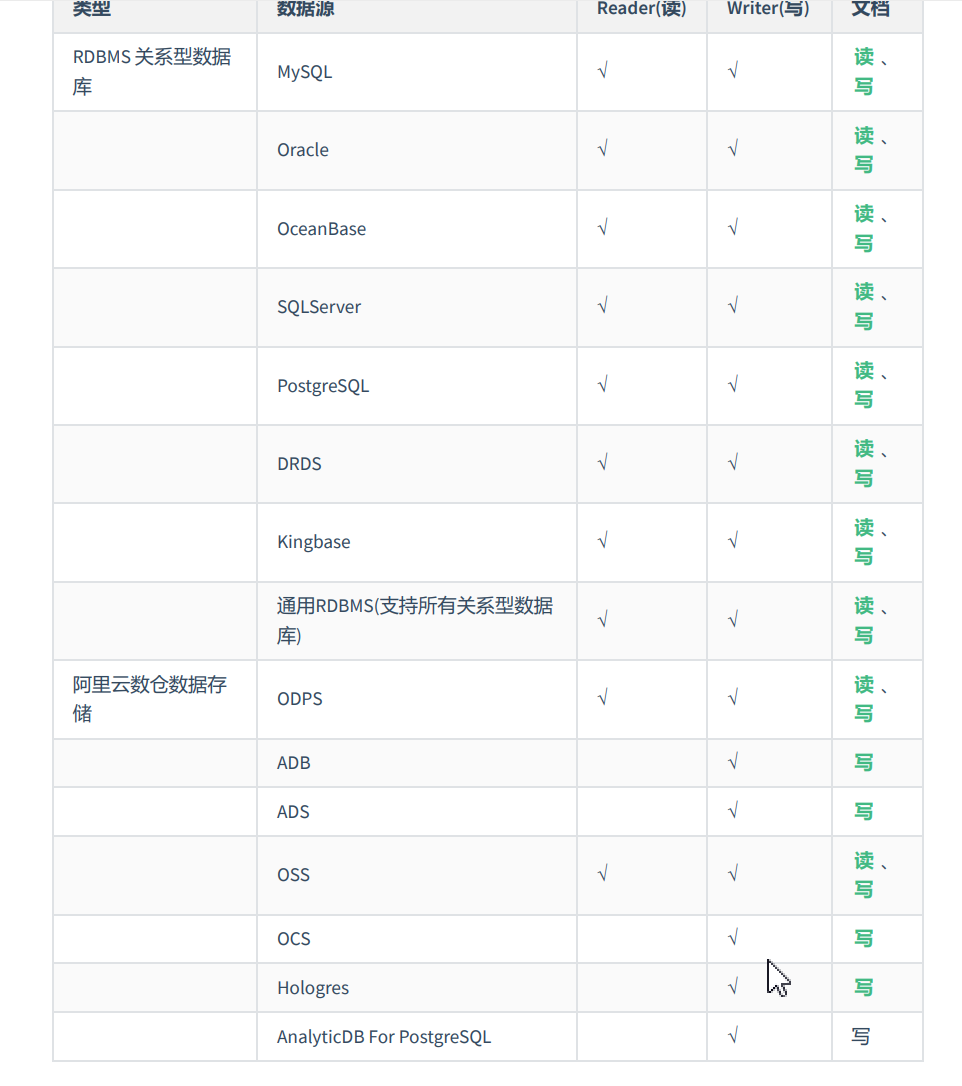
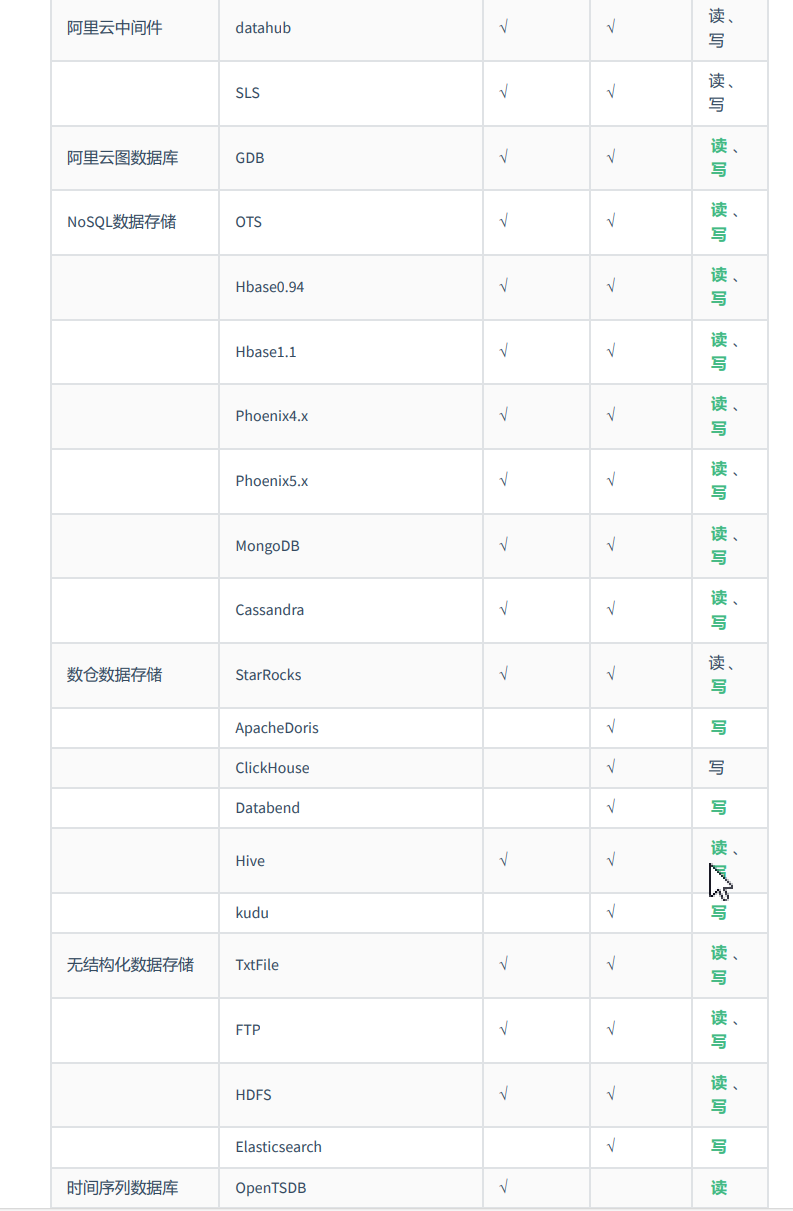
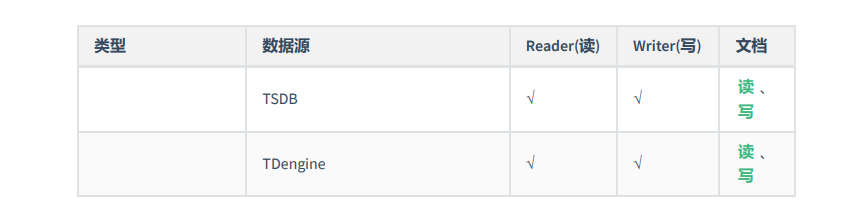
经过几年积累,DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。DataX目前支持数据如下:
DataX支持的hive数据类型如下:

提醒:目前不支持hive数据类型:decimal、binary、arrays、maps、structs、union类型;
三、DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework+plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。Reader是数据采集模块、Writer是数据写入模块,它们都将数据发送到FrameWork中,FrameWork作为两者的数据传输通道,并处理缓冲,流控、并发、数据转换等核心技术问题。
工作原理:DataX接收一个Job,启动一个进程完成数据同步,job启动后,会根据不同的源端切分策略,将job切分成多个小的Task子任务,每个Task都会负责一部分数据的同步工作,datax job会调用scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组成新的TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5,Task启动后,会固定启动Reader->Channel->Writer的线程来完成任务同步工作。DataX作业运行起来后,job监控多个Taskgroup模块任务完成,等待所有TaskGroup任务完成以后job成功退出,否则异常退出。
抽取策略:小表——全量抽取 大表——增量抽取
调优建议: 调优主要是调整channel,byte,record参数,不过具体性能还是取决于源端数据库的表 例如是否适合切分,是否有合适的切分字段,切分字段最好为数字
四、Datax软件安装
直接下载DataX工具包:DataX下载地址。
上传并解压tar压缩包
tar -zxvf datax.tar.gz -C /usr/local/
检测检查脚本
python /usr/local/datax/bin/datax.py /usr/local/datax/job/job.json
- 查看命令查看配置文件模板(以mysql===>hive为例)
python /usr/local/datax/bin/datax.py -r mysqlreader -w hdfswriter
--------------------------------------执行结果---------------------------------------------
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [],
"compress": "",
"defaultFS": "",
"fieldDelimiter": "",
"fileName": "",
"fileType": "",
"path": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
- json配置文件模板语法解释
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader", reader名字
"parameter": { 需要同步的列名集合,使用json数组描述自带信息,*代表所有列
"column": [], 具体的列和value
"connection": [ 连接信息
{
"jdbcUrl": [],对数据库的JDBC连接信息,使用JSON数组描述,支持多个连接地址
"table": [] 需要同步的表,支持多个
【"querySql":[]】 自定义SQL,配置它后,mysqlreader直接忽略table、column、where
}
],
"password": "", 数据库用户名对应的密码
"username": "", 数据库用户名
"where": "", 筛选条件
【"splitPK":"" 】 数据分片字段,一般是主键,仅支持整型
}
},
"writer": {
"name": "hdfswriter" writer名
"parameter": {
"column": [], 写入数据的字段,其中name指定字段名,type指定类型
"compress": "", hdfs文件压缩类型,默认不填写意味着没有压缩
"defaultFS": "hdfs://node1:8020", hdfs文件系统的namenode节点地址,格式: hdfs://ip:端口
"fieldDelimiter": "", 字段分隔符
"fileName": "", 写入的文件名
"fileType": "", 文件的类型,目前只支持用户配置位“text”或者“orc”
"path": "", 存储到Hadoop hdfs文件系统的路劲信息
"writeMode": "" hdfswriter写入前数据清理处理模式:1)append:写入前不做任何处理,hdfsWroter直接使用Filename写入,并保证文件名不冲突 2)nonConfict:如果目录下有fileName前缀的文件,直接报错 truncate,如果目录下有fileName前缀的文件,先删除后写入。
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
- 案例一,mysql2hdfs
配置文件编写
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"empno",
"ename",
"job",
"mgr",
"hiredate",
"sal",
"comm",
"deptno"
],
"splitPK":"empno",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://192.168.147.120:3306/scott?
characterEncoding=utf8"],
"table": ["emp"]
}
],
"password": "Root@123456.",
"username": "root",
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name":"empno",
"type":"INT"
},
{
"name":"ename",
"type":"STRING"
},
{
"name":"job",
"type":"STRING"
},
{
"name":"mgr",
"type":"INT"
},
{
"name":"hiredate",
"type":"DATE"
},
{
"name":"sal",
"type":"DOUBLE"
},
{
"name":"comm",
"type":"DOUBLE"
},
{
"name":"deptno",
"type":"INT"
},
],
"defaultFS": "hdfs://master:8020",
"fieldDelimiter": "\t",
"fileName": "tb_emp",
"fileType": "text",
"path": "/datax/warehouse",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
注意:json配置文件中的hdfs路径要与hive建表时的存放的路径一致。建表时不设置路径,默认存放在
/hive/warehouse/数据库名.db/表名下。hive表要提前创建好,并且每个字段和数据类型要与配置文件中一致!!
启动数据导入工作
# cd /usr/local/datax #切换到根目录下
# python bin/datax.py bin/job/mysql2hive.json #启动数据导入工作
- mysql数据导入到HBase中
自定义json配置文件
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"empno",
"ename",
"job",
"mgr",
"hiredate",
"sal",
"comm",
"deptno"
],
"splitPK":"empno",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://192.168.147.120:3306/scott?
characterEncoding=utf8"],
"table": ["emp"]
}
],
"password": "Root@123456.",
"username": "root",
}
},
"writer": {
"name": "hbase11xwriter",
"parameter": {
"column": [
{"index":1,
"name": "cf1:q1",
"type": "int"
},
{"index":1,
"name": "cf1:q2",
"type": "string"
},
{"index":1,
"name": "cf1:q3",
"type": "string"
},
{"index":1,
"name": "cf1:q4",
"type": "string"
},
{"index":1,
"name": "cf1:q5",
"type": "string"
},
{"index":1,
"name": "cf1:q6",
"type": "double"
},
{"index":1,
"name": "cf1:q7",
"type": "double"
},
{"index":1,
"name": "cf1:q8",
"type": "double"
},
],
"encoding": "utf-8",
"hbaseConfig": {
"hbase.zookeeper.quorum": "node1:2181,master:2181,node2:2181"
},
"mode": "normal",
-- rowKeyColumn指 rowkey列的类型和索引
"rowkeyColumn": [
{
"index":0,
"type": "string"
},
{
"index":-1,
"type": "string",
"value":"rowkeys"
},
]
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
五、DataX-web安装
- 环境要求
Language: Java 8(jdk版本建议1.8.201以上)
Python2.7(支持Python3需要修改替换datax/bin下面的三个python文件,替换文件在doc/dataxweb/datax-python3下)
Environment: MacOS, Windows,Linux
Database: Mysql8.0.16
- 上传压缩包并解压(下载地址:datax-web下载地址)
tar -zxvf datax-web-xxxx-bin.tar.gz -C /usr/local/datax-web/
- 把mysql-connection-8.0.16.jar放入datax-web根目录下的libs中。
- 执行安装脚本,同时填写sql连接信息
/usr/local/datax-web/install.sh --force
- 执行过程根据提示,填写mysql连接信息!
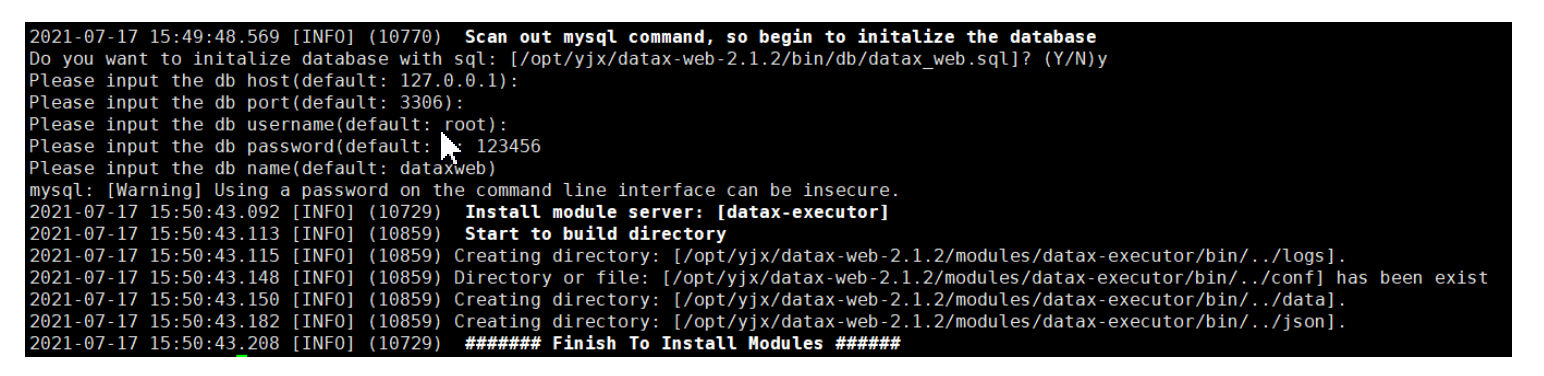
在Linux环境下使用JPS命令,查看是否出现DataXAdminApplication和DataXExecutorApplication 进程,如果存在这表示项目运行成功
部署完成后,在浏览器中输入 http://node01:9527/index.html 就可以访问对应的主界面.
输入用户名 admin 密码 123456 就可以直接访问系统.
- 提示:在导入数据前,要先在导入源创建表!
- 总结
大数据主要阶段:
- 数据采集
2.数据传输
3.数据存储
4.数据分析与计算
- 数据结果存储和展示
六、案例
1、处理业务数据(datax)
需求:把mysql数据库中的emp、dept、salgrade表导入hive中并分区,并对表进行分层分析!
- 导入依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<!-- Hadoop 版本控制 -->
<hadoop.version>3.1.2</hadoop.version>
<!-- Hive 版本控制 -->
<hive.version>3.1.2</hive.version>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.11.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flume/flume-ng-core -->
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.11.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.40</version>
</dependency>
</dependencies>
- 使用java代码生成数据,插入到数据库中
package com.yjxxt.mock;
import java.sql.*;
import java.time.LocalDate;
import java.util.Random;
//给emp表插入数据
public class Hello02InsertDataToEmpTable {
private static final String JDBC_DRIVER = "com.mysql.cj.jdbc.Driver";
private static final String DB_URL = "jdbc:mysql://192.168.147.120:3306/scott?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC";
private static final String USERNAME = "root";
private static final String PASSWORD = "Root@123456.";
private static final String INSERT_EMP_SQL = "INSERT INTO emp (empno, ename, job, mgr, hiredate, sal, comm, deptno) VALUES (?, ?, ?, ?, ?, ?, ?, ?)";
private static final String[] JOBS = {"CLERK", "SALESMAN", "MANAGER", "ANALYST", "PRESIDENT"};
public static void main(String[] args) throws SQLException {
Connection connection = null;
PreparedStatement statement = null;
Random random = new Random();
try {
// 连接数据库
Class.forName(JDBC_DRIVER);
connection = DriverManager.getConnection(DB_URL, USERNAME, PASSWORD);
// 插入数据
statement = connection.prepareStatement(INSERT_EMP_SQL);
for (int i = 1; i <= 1000; i++) {
statement.setInt(1, 10000 + i);
statement.setString(2, "EMP" + i);
statement.setString(3, JOBS[random.nextInt(JOBS.length)]);
statement.setInt(4, 7902);
statement.setDate(5, Date.valueOf(LocalDate.of(2010, 1, 1).plusDays(random.nextInt(4748))));
statement.setFloat(6, 1000 + random.nextInt(9000));
statement.setFloat(7, 100 + random.nextInt(900));
statement.setInt(8, 66 + random.nextInt(30));
statement.addBatch();
}
int[] ints = statement.executeBatch();
System.out.println("Data inserted successfully." + ints);
} catch (SQLException | ClassNotFoundException e) {
e.printStackTrace();
} finally {
// 关闭连接和声明
if (statement != null) {
statement.close();
}
if (connection != null) {
connection.close();
}
}
}
}
-----------------------------------------------------------------------------------------
package com.yjxxt.mock;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
//导入数据到dept表中!
public class Hello03InsertDeptData {
private static final String JDBC_DRIVER = "com.mysql.cj.jdbc.Driver";
private static final String DB_URL = "jdbc:mysql://192.168.147.120:3306/scott?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC";
private static final String USERNAME = "root";
private static final String PASSWORD = "Root@123456.";
private static final String INSERT_DEPT_SQL = "INSERT INTO dept (deptno, dname, loc) VALUES (?, ?, ?)";
private static final String[] LOCATIONS = {"NEW YORK", "DALLAS", "CHICAGO", "LOS ANGELES", "BOSTON", "LONDON"};
private static final int MIN_DEPTNO = 66;
private static final int MAX_DEPTNO = 99;
public static void main(String[] args) {
try {
Class.forName(JDBC_DRIVER);
Connection connection = DriverManager.getConnection(DB_URL, USERNAME, PASSWORD);
PreparedStatement statement = connection.prepareStatement(INSERT_DEPT_SQL);
Random random = new Random();
List<String> usedNames = new ArrayList<>();
for (int deptno = MIN_DEPTNO; deptno <= MAX_DEPTNO; deptno++) {
String dname = generateUniqueName(usedNames);
int locIndex = random.nextInt(LOCATIONS.length);
statement.setInt(1, deptno);
statement.setString(2, dname);
statement.setString(3, LOCATIONS[locIndex]);
statement.addBatch();
}
int[] result = statement.executeBatch();
System.out.println("Rows affected: " + result.length);
statement.close();
connection.close();
} catch (ClassNotFoundException | SQLException e) {
e.printStackTrace();
}
}
private static String generateUniqueName(List<String> usedNames) {
String name = "";
do {
name = generateName();
} while (usedNames.contains(name));
usedNames.add(name);
return name;
}
private static String generateName() {
String[] parts = {"SALES", "ACCOUNTING", "RESEARCH", "OPERATIONS", "MARKETING", "HR"};
Random random = new Random();
int part1 = random.nextInt(parts.length);
int part2 = random.nextInt(100);
return parts[part1] + "_" + part2;
}
}
- 在hive中创建
ods_dept、ods_emp、ods_salgrade表
create database datax;
use datax;
create table if not exists datax.ods_dept(
DEPTNO int,
DNAME varchar(255),
LOC varchar(255)
)
row format delimited fields terminated by ','
lines terminated by '\n';
create table if not exists datax.ods_emp(
EMPNO int,
ENAME varchar(255),
JOB varchar(255),
MGR int,
hiredate date,
sal double,
comm double,
DEPTNO int
)
row format delimited fields terminated by ','
lines terminated by '\n';
create table if not exists datax.ods_salgrade(
GRADE int,
losal int,
hisal int
)
row format delimited fields terminated by ','
lines terminated by '\n';
- 编写datax json配置文件
mysql2hive_emp.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"empno",
"ename",
"job",
"mgr",
"hiredate",
"sal",
"comm",
"deptno"
],
"splitPK":"empno",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://192.168.147.120:3306/scott?
characterEncoding=utf8"],
"table": ["emp"]
}
],
"password": "Root@123456.",
"username": "root",
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name":"empno",
"type":"INT"
},
{
"name":"ename",
"type":"STRING"
},
{
"name":"job",
"type":"STRING"
},
{
"name":"mgr",
"type":"INT"
},
{
"name":"hiredate",
"type":"DATE"
},
{
"name":"sal",
"type":"DOUBLE"
},
{
"name":"comm",
"type":"DOUBLE"
},
{
"name":"deptno",
"type":"INT"
}
],
"defaultFS": "hdfs://master:8020",
"fieldDelimiter": ",",
"fileName": "ods_emp",
"fileType": "text",
"path": "/hive/warehouse/datax.db/ods_emp",
"writeMode": "truncate"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
mysql2hive_dept.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"deptno",
"dname",
"loc"],
"splitPK":"deptno",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://192.168.147.120:3306/scott?
characterEncoding=utf8"],
"table": ["dept"]
}
],
"password": "Root@123456.",
"username": "root",
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name":"deptno",
"type":"INT"
},
{
"name":"dname",
"type":"STRING"
},
{
"name":"loc",
"type":"STRING"
}
],
"defaultFS": "hdfs://master:8020",
"fieldDelimiter": ",",
"fileName": "ods_dept",
"fileType": "text",
"path": "/hive/warehouse/datax.db/ods_dept",
"writeMode": "truncate"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
mysql2hive_salgrade.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"grade",
"losal",
"hisal"],
"splitPK":"grade",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://192.168.147.120:3306/scott?
characterEncoding=utf8"],
"table": ["dept"]
}
],
"password": "Root@123456.",
"username": "root",
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name":"grade",
"type":"INT"
},
{
"name":"losal",
"type":"INT"
},
{
"name":"hisal",
"type":"INT"
}
],
"defaultFS": "hdfs://master:8020",
"fieldDelimiter": ",",
"fileName": "ods_salgrade",
"fileType": "text",
"path": "/hive/warehouse/datax.db/ods_salgrade",
"writeMode": "truncate"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
datax 执行脚本
python /usr/local/datax/bin/datax.py /usr/local/datax/job/mysql2hive_emp.json
python /usr/local/datax/bin/datax.py /usr/local/datax/job/mysql2hive_dept.json
python /usr/local/datax/bin/datax.py /usr/local/datax/job/mysql2hive_salgrade.json
MySQL字段名和表名:严格区别字母大小写
- 业务数据处理
use datax;
-- ods层表创建
create table if not exists datax.ods_dept(
DEPTNO int,
DNAME varchar(255),
LOC varchar(255)
)
row format delimited fields terminated by ','
lines terminated by '\n';
drop table datax.ods_emp;
create table if not exists datax.ods_emp(
EMPNO int,
ENAME varchar(255),
JOB varchar(255),
MGR int,
hiredate date,
sal double,
comm double,
DEPTNO int
)
row format delimited fields terminated by ','
lines terminated by '\n';
create table if not exists datax.ods_salgrade(
GRADE int,
losal int,
hisal int
)
row format delimited fields terminated by ','
lines terminated by '\n';
select * from datax.ods_emp;
select * from datax.ods_salgrade;
select * from datax.ods_dept;
-- dwd层数据明细
drop table datax.dwd_emp;
create table if not exists datax.dwd_emp(
EMPNO int,
ENAME varchar(255),
JOB varchar(255),
MGR int,
hiredate date,
sal double,
comm double,
grade int,
DEPTNO int
)
partitioned by (ymd string)
row format delimited fields terminated by ','
lines terminated by '\n';
select * from dwd_emp;
insert into datax.dwd_emp partition (ymd='20231125')
select
e.empno,
e.ename,
e.job,
e.mgr,
e.hiredate,
e.sal,
e.comm,
s.GRADE,
e.deptno
from datax.ods_emp e
left join ods_salgrade s on e.sal between s.losal and s.hisal;
-- dim层纬度表层
create table if not exists dim_dept(
DEPTNO int,
DNAME varchar(255),
LOC varchar(255)
) row format delimited fields terminated by ','
lines terminated by '\n';
insert into table dim_dept
select *
from ods_dept;
select * from dim_dept;
-- dws数据服务层
create table if not exists dws_emp(
EMPNO int,
ENAME varchar(255),
JOB varchar(255),
MGR int,
hiredate date,
sal double,
comm double,
grade int,
DEPTNO int,
LOC string
)partitioned by (ymd string)
row format delimited fields terminated by ','
lines terminated by '\n';
insert into dws_emp partition (ymd='20231125')
select
e.empno, e.ename, e.job, e.mgr, e.hiredate, e.sal, e.comm, e.grade, e.deptno,
dd.LOC
from dwd_emp e
left join dim_dept dd on e.DEPTNO = dd.DEPTNO;
select *
from dws_emp;
2、处理日志行为数据(flume)
- java代码生成数据文本文件
package com.yjxxt.mock;
import com.yjxxt.util.EventGenerator;
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.io.IOException;
/**
* 生成随机数据的类 埋点数据生成 大数据
*/
public class Hello01MockMsg {
public static void main(String[] args) {
//开启一个线程专门用于发送消息
new Thread(() -> {
try {
//世界的尽头
while (true) {
//获取埋点数据
String event = EventGenerator.generateEvent() + "\r\n";
//向文件写入数据
FileUtils.write(new File("/home/datax/data.log"), event, "utf-8", true);
//休眠0.1秒
Thread.sleep(100);
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
打成jar包的步骤
把以上代码选择好主类打成jar包,上传到linux上跑!会在linux上生成一个日志文件。
java -jar yjxxt06dw_01mockdata-1.0-SNAPSHOT.jar
使用flume对日志行为数据进行采集,生成文本文件分区
- 导入依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<!-- Hadoop 版本控制 -->
<hadoop.version>3.1.2</hadoop.version>
<!-- Hive 版本控制 -->
<hive.version>3.1.2</hive.version>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.11.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flume/flume-ng-core -->
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.11.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.40</version>
</dependency>
</dependencies>
- 方式一:自定义flume拦截器代码(源数据格式输出)
package com.yjxxt.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//flume日志行为数据采集 把日期转为时间戳 放进event header中以 "timestamp"="121212"
public class DataxFilterInterceptor implements Interceptor {
// 声明一个存放事件的List
private List<Event> eventList;
@Override
public void initialize() {
//声明对象
eventList = new ArrayList<>();
}
@Override
public Event intercept(Event event) {
try {
//获取请求头信息
Map<String, String> headers = event.getHeaders();
//获取请求体信息
String body = new String(event.getBody());
//根据自己的需求处理数据
String regex = ".*date=(.+?),.*";
Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(body);
if (matcher.matches()) {
String dateString = matcher.group(1);
Date date = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒").parse(dateString);
//为Header设置ts
headers.put("timestamp", String.valueOf(date.getTime()));
}
} catch (ParseException e) {
e.printStackTrace();
}
//返回处理后的结果
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
//清空历史记录
eventList.clear();
//依次处理数据
for (Event event : list) {
eventList.add(intercept(event));
}
//返回结果
return eventList;
}
@Override
public void close() {
}
/**
* 通过该静态内部类来创建自定义对象供flume使用,实现Interceptor.Builder接口,并实现其抽象方法
*/
public static class Builder implements Interceptor.Builder {
/**
* 该方法主要用来返回创建的自定义类拦截器对象
*
* @return
*/
@Override
public Interceptor build() {
return new DataxFilterInterceptor();
}
/**
* 用来接收flume配置自定义拦截器参数
*
* @param context 通过该对象可以获取flume配置自定义拦截器的参数
*/
@Override
public void configure(Context context) {
}
}
}
- 方式二:自定义flume拦截器代码(把日志行为数据转化为json字符串写入HDFS中)。
package com.yjxxt.interceptor;
import com.alibaba.fastjson2.JSON;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.*;
/**
* 把日志行为数据转化为json字符串
*/
public class DataxFilterInterceptor implements Interceptor {
// 声明一个存放事件的List
private List<Event> eventList;
@Override
public void initialize() {
//声明对象
eventList = new ArrayList<>();
}
@Override
public Event intercept(Event event) {
try {
//获取请求头信息
Map<String, String> headers = event.getHeaders();
byte[] bytes = event.getBody();
//获取请求体信息
String body = new String(bytes, Charset.forName("UTF-8"));
Map<String,String> map=new HashMap<>();
String[] arr= body.split(",");
String[] strings = arr[0].replace("{", "").split("=");
map.put(strings[0],strings[1]);
for (int i=1;i<arr.length-1;i++){
map.put(arr[i].split("=")[0],arr[i].split("=")[1]);
}
String[] arrEnd = arr[arr.length - 1].replace("}", "").split("=");
map.put(arrEnd[0],arrEnd[1]);
Date date = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒").parse(map.get("date"));
//为Header设置ts
headers.put("timestamp", String.valueOf(date.getTime()));
String json = JSON.toJSONString(map);
event.setBody(json.getBytes(StandardCharsets.UTF_8));
} catch (ParseException e) {
e.printStackTrace();
}
//返回处理后的结果
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
//清空历史记录
eventList.clear();
//依次处理数据
for (Event event : list) {
eventList.add(intercept(event));
}
//返回结果
return eventList;
}
@Override
public void close() {
}
/**
* 通过该静态内部类来创建自定义对象供flume使用,实现Interceptor.Builder接口,并实现其抽象方法
*/
public static class Builder implements Interceptor.Builder {
/**
* 该方法主要用来返回创建的自定义类拦截器对象
*
* @return
*/
@Override
public Interceptor build() {
return new DataxFilterInterceptor();
}
/**
* 用来接收flume配置自定义拦截器参数
*
* @param context 通过该对象可以获取flume配置自定义拦截器的参数
*/
@Override
public void configure(Context context) {
}
}
}
- 把以上代码用maven打成jar包,上传到flume包下的lib目录中。
注意:如果使用方式二,打成jar包,要把fastjson2-2.0.40.jar与拦截器jar包一并上传到flume包下的lib目录中,否则会报错找不到fastjson类。
- 编写dataInterceptor.conf配置文件(数据上传到hdfs://hdfs-zwf/flume/datax/)
##定义a1的三个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
##定义Source的类型
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /home/flumePosition/datax_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /home/datax/data.log
a1.sources.r1.headers.f1.headerKey1 = f1
a1.sources.r1.fileHeader = true
## 定义拦截器
a1.sources.r1.interceptors=i6
a1.sources.r1.interceptors.i6.type=com.yjxxt.interceptor.DataxFilterInterceptor$Builder
##定义Channel的类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
##定义Sink的类型
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=hdfs://hdfs-zwf/flume/datax/%Y%m%d/%H%M%S
##hdfs有多少条消息时新建文件,0不基于消息个数
a1.sinks.k1.hdfs.rollCount=0
##hdfs创建多长时间新建文件,0不基于时间
a1.sinks.k1.hdfs.rollInterval=60
##hdfs多大时新建文件,0不基于文件大小
a1.sinks.k1.hdfs.rollSize=10240
##当目前被打开的临时文件在该参数指定的时间(秒)内,没有任何数据写入,则将该临时文件关闭并重
命名成目标文件
a1.sinks.k1.hdfs.idleTimeout=3
a1.sinks.k1.hdfs.fileType=DataStream
##使用事件的header中的timestamp属性对应的值作为分区的判定标准
a1.sinks.k1.hdfs.useLocalTimeStamp=false
##每五分钟生成一个目录:
##是否启用时间上的”舍弃”,这里的”舍弃”,类似于”四舍五入”,后面再介绍。如果启用,则会影响除了%t的其他所有时间表达式
a1.sinks.k1.hdfs.round=true
##时间上进行“舍弃”的值;
a1.sinks.k1.hdfs.roundValue=1
##时间上进行”舍弃”的单位,包含:second,minute,hour
a1.sinks.k1.hdfs.roundUnit=hour
##组装source channel sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 执行flume脚本命令
flume-ng agent -n a1 -c c -f /usr/local/flume/options/dataInterceptor.conf -Dflume.root.logger=INFO.console;
- 创建hive表接收未处理的日志数据(默认存在hdfs上的/hive/warehouse/datax.db/browntable目录)
create table if not exists datax.brownTable(
events string
)partitioned by (ymd string)
row format delimited lines terminated by '\n';
-- 导入数据
-- /*/* 把所有目录下的所有文件 把flume采集后上传到hdfs上的文本数据进行加载到表中!
load data inpath '/flume/datax/20231124/*/*' into table datax.brownTable partition (ymd='20231124');
- 执行后HDFS文件

- 编写UDTF自定义函数代码(处理方式一源数据的方式)
package com.yjxxt.hive;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructField;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class YjxxtLogLogSplitUDTF extends GenericUDTF {
/**
* 实例化 UDTF 对象,判断传入参数的长度以及数据类型
*
* @param argOIs
* @return
* @throws UDFArgumentException
*/
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
// 获取入参
List<? extends StructField> fieldRefs = argOIs.getAllStructFieldRefs();
// 参数校验,判断传入参数的长度以及数据类型
if (fieldRefs.size() != 1) {
throw new UDFArgumentLengthException("参数个数必须为 1");
}
if (!ObjectInspector.Category.PRIMITIVE.equals(fieldRefs.get(0).getFieldObjectInspector().getCategory())) {
throw new UDFArgumentTypeException(0, "参数类型必须为 String");
}
// 自定义函数输出的字段和类型
// 创建输出字段名称的集合
ArrayList<String> columnNames = new ArrayList<>();
// 创建字段数据类型的集合
ArrayList<ObjectInspector> columnType = new ArrayList<>();
columnNames.add("user_id");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("product_id");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("duration");
columnType.add(PrimitiveObjectInspectorFactory.javaIntObjectInspector);
columnNames.add("page");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("action");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("device_type");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("browser");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("language");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("referrer");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("location");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("ts");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(columnNames, columnType);
}
/**
* 处理数据
*
* @param args
* @throws HiveException
*/
@Override
public void process(Object[] args) throws HiveException {
try {
//存储要输出的列的值
Object[] outColumnValue = new Object[11];
//定义一个Map存储拆分后的数据
Map<String, String> map = new HashMap<>();
if (args[0] != null) {
//替换大括号,并分割属性
String[] attrs = args[0].toString().replaceAll("\\{|\\}", "").split(",");
//遍历
for (String attr : attrs) {
String[] kv = attr.split("=");
map.put(kv[0].trim(), kv[1].trim());
}
//开始拼接数据
outColumnValue[0] = map.get("user_id");
outColumnValue[1] = map.get("product_id");
outColumnValue[2] = Integer.parseInt(map.get("duration"));
outColumnValue[3] = map.get("page");
outColumnValue[4] = map.get("action");
outColumnValue[5] = map.get("device_type");
outColumnValue[6] = map.get("browser");
outColumnValue[7] = map.get("language");
outColumnValue[8] = map.get("referrer");
outColumnValue[9] = map.get("location");
outColumnValue[10] = String.valueOf(new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒").parse(map.get("date")).getTime());
//将值进行输出
forward(outColumnValue);
} else {
//传入的数据格式有误
System.out.println("YjxxtLogLogSplitUDTF.process【" + args + "】");
}
} catch (ParseException e) {
e.printStackTrace();
}
}
@Override
public void close() throws HiveException {
}
}
- 自定义UDTF函数(处理方式二json字符串)
package com.yjxxt.hive;
import com.alibaba.fastjson2.JSONObject;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructField;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* @Description :
* @School:优极限学堂
* @Official-Website: http://www.yjxxt.com
* @Teacher:李毅大帝
* @Mail:863159469@qq.com
*/
public class YjxxtLogLogSplitUDTF extends GenericUDTF {
/**
* 实例化 UDTF 对象,判断传入参数的长度以及数据类型
*
* @param argOIs
* @return
* @throws UDFArgumentException
*/
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
// 获取入参
List<? extends StructField> fieldRefs = argOIs.getAllStructFieldRefs();
// 参数校验,判断传入参数的长度以及数据类型
if (fieldRefs.size() != 1) {
throw new UDFArgumentLengthException("参数个数必须为 1");
}
if (!ObjectInspector.Category.PRIMITIVE.equals(fieldRefs.get(0).getFieldObjectInspector().getCategory())) {
throw new UDFArgumentTypeException(0, "参数类型必须为 String");
}
// 自定义函数输出的字段和类型
// 创建输出字段名称的集合
ArrayList<String> columnNames = new ArrayList<>();
// 创建字段数据类型的集合
ArrayList<ObjectInspector> columnType = new ArrayList<>();
columnNames.add("user_id");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("product_id");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("duration");
columnType.add(PrimitiveObjectInspectorFactory.javaIntObjectInspector);
columnNames.add("page");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("action");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("device_type");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("browser");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("language");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("referrer");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("location");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
columnNames.add("ts");
columnType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(columnNames, columnType);
}
/**
* 处理数据
*
* @param args
* @throws HiveException
*/
@Override
public void process(Object[] args) throws HiveException {
try {
//存储要输出的列的值
Object[] outColumnValue = new Object[11];
//定义一个Map存储拆分后的数据
if (args[0] != null) {
//args[0]数据一行一行读取!
Map<String,String> map = JSONObject.parseObject(args[0].toString(), Map.class);
//开始拼接数据
outColumnValue[0] = map.get("user_id");
outColumnValue[1] = map.get("product_id");
outColumnValue[2] = Integer.parseInt(map.get("duration"));
outColumnValue[3] = map.get("page");
outColumnValue[4] = map.get("action");
outColumnValue[5] = map.get("device_type");
outColumnValue[6] = map.get("browser");
outColumnValue[7] = map.get("language");
outColumnValue[8] = map.get("referrer");
outColumnValue[9] = map.get("location");
outColumnValue[10] = String.valueOf(new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒").parse(map.get("date")).getTime());
//将值进行输出
forward(outColumnValue);
} else {
//传入的数据格式有误
System.out.println("YjxxtLogLogSplitUDTF.process【" + args + "】");
}
} catch (ParseException e) {
e.printStackTrace();
}
}
@Override
public void close() throws HiveException {
}
}
- 把自定义函数打成jar包,上传到HDFS上。
- hive上注册自定义UDTF函数
-- 自定义函数
CREATE FUNCTION data_format AS 'com.yjxxt.hive.YjxxtLogLogSplitUDTF'
USING JAR 'hdfs:///yjxxt06dw_01mockdata-1.0-SNAPSHOT.jar';
- 使用函数把数据插入hive的brownTableDemo表中
create table if not exists datax.brownTableDemo(
user_id string,
product_id string,
duration int,
page string,
action string,
device_type string,
browser string,
language string,
referrer string,
location string,
ts bigint
)partitioned by (ymd string)
row format delimited fields terminated by ','
lines terminated by '\n';
-- 插入数据
insert into datax.brownTableDemo partition(ymd='20231124')
select data_format(events) from datax.brownTable where ymd='20231124';
-- 查询整理好的数据
select * from brownTableDemo;
如果Hdfs上的文件数据是json字符串,可以直接使用下面方式直接解析json字符串
-- 处理json字符串 可以直接使用json序列化器 不用自定义UDTF函数
create table if not exists datax.brownTableDemo(
user_id string,
product_id string,
duration int,
page string,
action string,
device_type string,
browser string,
language string,
referrer string,
location string,
ts bigint
)partitioned by (ymd string)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
lines terminated by '\n'
STORED AS TEXTFILE;
-- 直接把HDFS上转化为JSON字符串文本数据导入表中 会自动序列化!
-- /*/* 把所有目录下的所有文件 把flume采集后上传到hdfs上的文本数据进行加载到表中!
load data inpath '/flume/datax/20231124/*/*' into table datax.brownTableDemo partition (ymd='20231124');