2023数据采集与融合技术实践作业三
作业①:
-
要求:
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
-
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
-
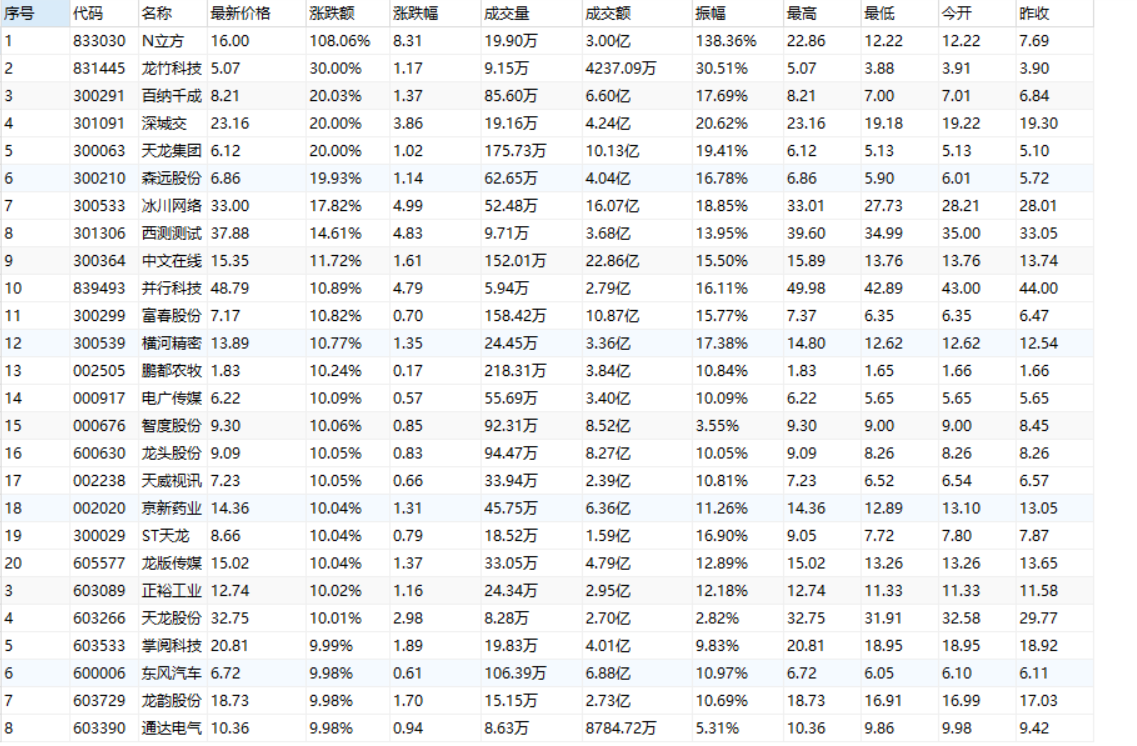
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 688093 | N世华 | 2 8.47 | 62.22% | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.2 | 17.55 |
| 2...... |
代码:
import pymysql
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import datetime
import time
import logging
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"}
imagePath = "download"
def __init__(self):
# 初始化日志记录器
logging.basicConfig(filename='spider.log', level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s')
self.logger = logging.getLogger(__name__)
def startUp(self, url, key):
# 初始化Chrome浏览器
chrome_options = Options()
chrome_options.add_argument('--headless') # 设置无头模式,不弹出浏览器窗口
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(options=chrome_options)
self.driver.get(url)
# 初始化变量
self.bankuai = ["nav_hs_a_board", "nav_sh_a_board", "nav_sz_a_board"]
self.bankuai_id = 0 # 当前板块
# 初始化数据库
try:
self.con = pymysql.connect(host='localhost', port=3307, user='root', password='123456',
db='Data acquisition')
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
# 如果有表就删除
self.cursor.execute("drop table if exists stocks")
# 建立新的表
sql = "create table stocks(序号 varchar(128),代码 varchar(128),名称 varchar(128),最新价格 varchar(128),涨跌额 varchar(128),涨跌幅 " \
"varchar(128),成交量 varchar(128),成交额 varchar(128),振幅 varchar(128)," \
"最高 varchar(128),最低 varchar(128),今开 varchar(128),昨收 varchar(128), unique(代码));"
self.cursor.execute(sql)
except Exception as err:
self.logger.error(f"Init error: {err}")
raise
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.quit()
self.logger.info('Quit driver and close database connection successfully.')
except Exception as err:
self.logger.error(f"Close error: {err}")
raise
def insertDB(self, data):
try:
sql = "insert into stocks(序号,代码,名称,最新价格,涨跌额,涨跌幅,成交量,成交额,振幅,最高,最低,今开,昨收)values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.executemany(sql, data)
self.con.commit()
except Exception as err:
self.logger.error(f"Insert error: {err}")
self.con.rollback()
def processSpider(self, max_page=10):
page = 1
processed_codes = set() # 已处理的股票代码集合
while True:
time.sleep(1)
self.logger.info(f"Processing page {page} of data...")
trs = self.driver.find_elements(By.XPATH, "//table[@class='table_wrapper-table']/tbody/tr")
if not trs:
self.logger.warning('No data found on current page.')
break
data = []
for tr in trs:
try:
daima = tr.find_elements(By.XPATH, "./td")[1].text
if daima in processed_codes:
continue # 跳过已处理的股票代码
number = tr.find_elements(By.XPATH, "./td")[0].text
name = tr.find_elements(By.XPATH, "./td")[2].text
new = tr.find_elements(By.XPATH, "./td")[4].text
zangfu = tr.find_elements(By.XPATH, "./td")[5].text
e = tr.find_elements(By.XPATH, "./td")[6].text
chengjiao = tr.find_elements(By.XPATH, "./td")[7].text
jiaoe = tr.find_elements(By.XPATH, "./td")[8].text
zhenfu = tr.find_elements(By.XPATH, "./td")[9].text
max = tr.find_elements(By.XPATH, "./td")[10].text
min = tr.find_elements(By.XPATH, "./td")[11].text
today = tr.find_elements(By.XPATH, "./td")[12].text
ye = tr.find_elements(By.XPATH, "./td")[13].text
data.append((number, daima, name, new, zangfu, e, chengjiao, jiaoe, zhenfu, max, min, today, ye))
processed_codes.add(daima)
except Exception as err:
self.logger.error(f"Data parsing error: {err}")
try:
if data:
self.insertDB(data)
self.logger.info('Data inserted successfully.')
else:
self.logger.warning('No new data to be inserted.')
except Exception as err:
self.logger.error(f"Insert error: {err}")
if page >= max_page:
break
try:
self.bankuai_id += 1
next = self.driver.find_element(By.XPATH, "//li[@id='" + self.bankuai[self.bankuai_id % 3] + "']/a")
self.driver.execute_script("arguments[0].click();", next)
self.logger.info('Switched to next page successfully.')
time.sleep(5)
except Exception as err:
self.logger.error(f"Switch page error: {err}, exit spider.")
break
page += 1
def executeSpider(self, url, key):
starttime = datetime.datetime.now()
self.logger.info("Spider starting......")
self.startUp(url, key)
self.logger.info("Spider processing......")
self.processSpider()
self.logger.info("Spider closing......")
self.closeUp()
self.logger.info("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
self.logger.info(f"Total {elapsed} seconds elapsed")
if __name__ == '__main__':
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
spider = MySpider()
spider.executeSpider(url, "key")
结果图片:
心得体会:
在实践过程中出现的问题以及解决方法:1.元素定位:Selenium 中使用 XPATH 进行元素定位,定位表格中的数据时,需要保证 XPATH 表达式的准确性,否则会导致数据提取错误。2.数据库交互:涉及数据库的操作,需要注意 SQL 语句的正确性和安全性,以及异常处理的完善性。3.日志记录:日志记录是很好的编程习惯,有助于排查问题,但需要注意日志级别的选择和日志信息的完整性。收获:通过这段代码,可以学习到如何使用 Selenium 进行网页数据的抓取和交互操作,了解了如何使用 pymysql 库来进行 Python 和 MySQL 数据库的交互,学会了如何进行日志记录,以便对程序的执行情况进行监控和排查问题。
作业②
-
要求:
- 熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
-
候选网站:中国mooc网:https://www.icourse163.org
-
输出信息:MYSQL数据库存储和输出格式
| Id | cCourse | cCollege | cTeacher | cTeam | cCount | cProcess | cBrief |
|---|---|---|---|---|---|---|---|
| 1 | Python数据分析与展示 | 北京理工大学 | 嵩天 | 嵩天 | 470 | 进行至第8周 | “我们正步入一个数据或许比软件更重要的新时代。——Tim O'Reilly” …… |
| 2..... |
代码:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import pymysql
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"}
def __init__(self):
self.driver = None
self.page = 0
self.no = 0
self.con = None
self.cursor = None
def init(self):
print("初始化爬虫中...")
chrome_options = Options()
self.driver = webdriver.Chrome(options=chrome_options)
self.page = 0
self.no = 0
try:
self.con = pymysql.connect(host='localhost', port=3307, user='root', password='123456',
db='Data acquisition')
self.cursor = self.con.cursor()
try:
self.cursor.execute("drop table if exists mooc")
except:
pass
try:
# 建立数据表
sql = """create table mooc(Id varchar(8),cCource varchar(64),cCollege varchar(64),cTeacher varchar(64),
cTeam varchar(64),cCount varchar(64),cBrief varchar(256))ENGINE=InnoDB DEFAULT CHARSET=utf8"""
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
print("初始化完成,准备进行登录")
def login(self, account, password, loginurl):
print("登录中")
# 获取登录页面
self.driver.get(loginurl)
# 点击手机号登录按钮切换至手机号登录
self.driver.find_element(By.XPATH, "//ul[@class='ux-tabs-underline_hd']//li").click()
# 由于登录框是一个弹出窗口,需要切换frame,否则会找不到元素
self.driver.switch_to.frame(
self.driver.find_element(By.XPATH, "//div[@class='ux-login-set-container']/iframe"))
# 定位到输入账号的位置,输入账号
self.driver.find_element(By.XPATH, "//input[@class='dlemail j-nameforslide']").send_keys(account)
# 定位到输入密码的位置,输入密码
self.driver.find_element(By.XPATH, "//input[@class='j-inputtext dlemail']").send_keys(password)
# 点击登录按钮
self.driver.find_element(By.XPATH, "//a[@class='u-loginbtn btncolor tabfocus ']").click()
print("登录成功")
def choose(self, key, url):
# 获取网页
print("正在搜索关键词{}......".format(key))
self.driver.get(url)
time.sleep(1)
# 定位到搜索框,将关键词输入到搜索框
keyInput = self.driver.find_element(By.XPATH, ".//div[@class='u-baseinputui']/input[@type='text']")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
time.sleep(2)
print("搜索完成,准备开始爬取")
def download(self):
try:
# 统计爬取的当前页
self.page += 1
print("爬取第{}页".format(self.page))
# 爬取的各个课程数据列表
datalist = self.driver.find_elements(By.XPATH, "//div[@class='cnt f-pr']")
time.sleep(2)
for data in datalist:
# 有些课程格式不符合规范,如没有开课学校的,使用except略过,否则会因为格式问题报错,影响爬取
try:
# 待爬取的各项数据
cCource = data.find_element(By.XPATH, "./div[@class='t1 f-f0 f-cb first-row']").text
cCollege = data.find_element(By.XPATH, ".//a[@class='t21 f-fc9']").text
cTeacher = data.find_element(By.XPATH, ".//a[@class='f-fc9']").text
cTeam = data.find_element(By.XPATH, ".//a[@class='f-fc9']").text
cCount = data.find_element(By.XPATH, ".//span[@class='hot']").text
cBrief = data.find_element(By.XPATH, ".//span[@class='p5 brief f-ib f-f0 f-cb']").text
# 统计爬取的课程个数,用做序号数据项
self.no += 1
# 将爬取的数据插入到mysql数据库中
self.cursor.execute("insert into mooc values(%s,%s,%s,%s,%s,%s,%s)",
(self.no, cCource, cCollege, cTeacher, cTeam, cCount, cBrief))
# 提交到命令行执行
self.con.commit()
# 简单记录爬取过程
print(cCource)
except:
pass
try:
# 查找是否可以翻页,如果找到不可翻页标记则说明到了最后一页,程序结束,否则进入except
self.driver.find_element(By.XPATH,
"//li[@class='ux-pager_btn ux-pager_btn__next']/a[@class='th-bk-disable-gh']")
print("爬取结束")
except:
# 点击翻页,然后递归调用download
nextpage = self.driver.find_element(By.XPATH,
"//li[@class='ux-pager_btn ux-pager_btn__next']/a[@class='th-bk-main-gh']")
nextpage.click()
time.sleep(3)
self.download()
except Exception as err:
print(err)
def process(self, url, loginurl):
self.init()
print("请输入账号:")
account = input()
print("请输入密码:")
password = input()
self.login(account, password, loginurl)
print("请输入要爬取的关键词:")
key = input()
self.choose(key, url)
self.download()
if __name__ == '__main__':
url = "https://www.icourse163.org"
loginurl = "https://www.icourse163.org/member/login.htm#/webLoginIndex"
spider = MySpider()
spider.process(url, loginurl)
结果图片:
心得体会:
在实践时,出现了以下几个问题:页面元素定位问题:在使用 find_element 定位页面元素时,可能会因为 XPath 表达式不准确而定位失败;异常处理不完善:当前代码使用了一个简单的 try-except 块来捕获异常,但没有对具体的异常情况进行区分处理;数据库连接安全性:代码中数据库连接的用户名和密码是硬编码在代码中的,这样存在安全风险。建议使用配置文件等方式来管理敏感信息,增加安全性。最后的收获:熟悉了 Selenium 的基本用法,包括模拟浏览器行为、页面元素定位和交互操作;对于网页数据的抓取、解析和存储有了一定的了解;了解了如何使用 Python 连接和操作 MySQL 数据库。
作业③:
-
要求:
- 掌握大数据相关服务,熟悉Xshell的使用
- 完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
- 环境搭建:
- 任务一:开通MapReduce服务
-
实时分析开发实战:
- 任务一:Python脚本生成测试数据
- 任务二:配置Kafka
- 任务三: 安装Flume客户端
- 任务四:配置Flume采集数据
-
输出:实验关键步骤或结果截图。
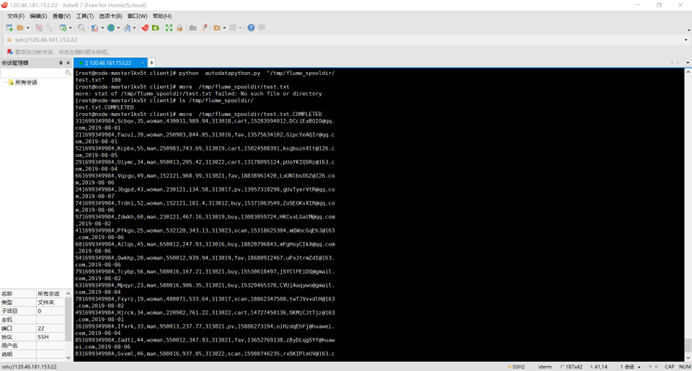
任务一:Python脚本生成测试数据
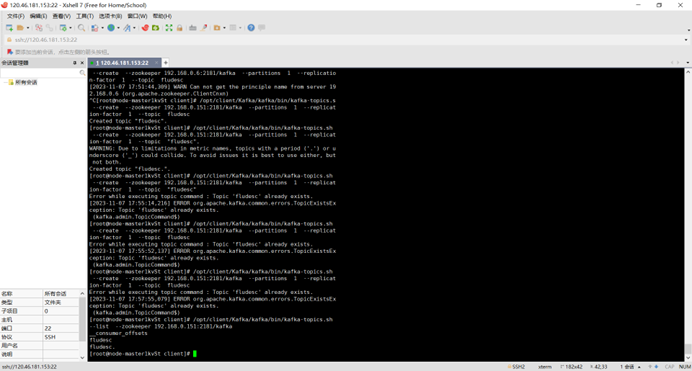
任务二:配置Kafka
任务三: 安装Flume客户端
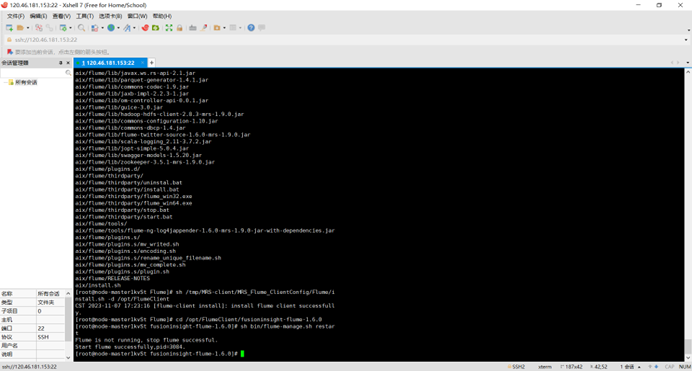
任务四:配置Flume采集数据
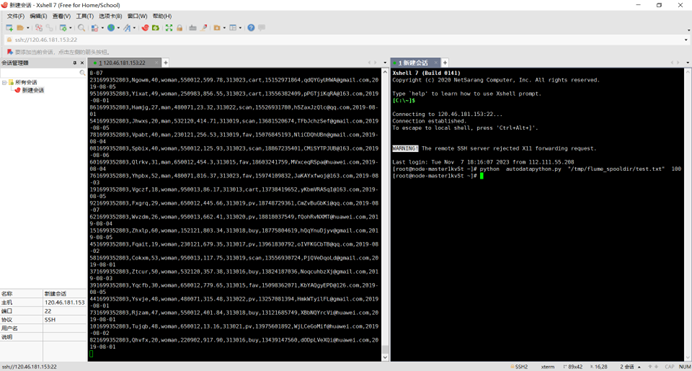
心得体会:
在完成作业的过程中,我深入了解了大数据相关服务以及实时分析处理的实际操作,掌握了Xshell工具的使用技巧。针对文档中的任务,我逐一进行了操作。通过完成这些任务,我不仅掌握了大数据相关服务和工具的使用,还对实时数据处理的流程和方法有了更深入的了解,提升了我的实际操作能力和对大数据处理的整体认识。希望这次实践能够为我今后在大数据领域的学习和工作打下坚实的基础。