下面我们就从第一个模块,数据采集模块开始。
注意:在实际工作中,数据采集模块不是只针对某一个项目而言的,而是一个公共的采集平台,所有项目依赖的数据全部是来源于数据采集模块,所以在设计采集模块的时候要考虑通用性。
数据采集架构详细分析
在具体开始之前,我们还要再分析一些内容
我们前面在分析整体架构的时候说过,filebeat采集的数据到达kafka以后会通过flume再做一下分发,为什么要有这个分发过程?这个分发过程实现了什么功能呢?
我们来看一下这张图
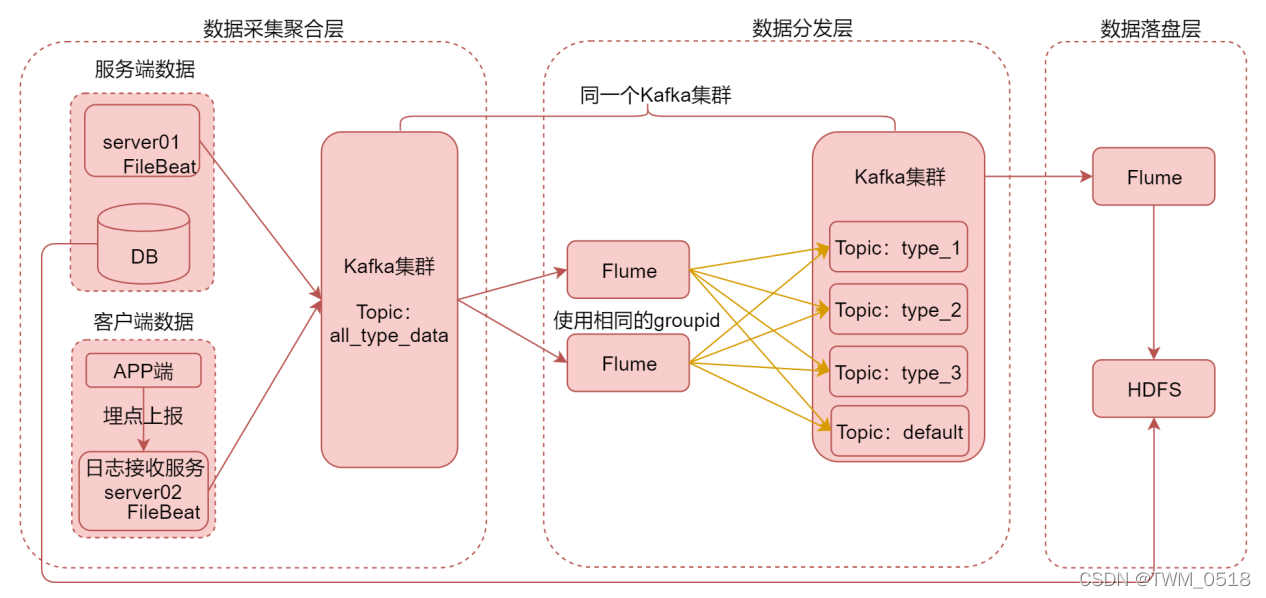
这个图里面是针对数据采集模块做了详细分析,把数据采集模块划分了三层,数据采集聚合层、数据分发层、数据落盘层。
在数据采集聚合层,我们为了保证采集程序的通用性,不至于每次新增一个业务指标的数据,就去重新增加一个采集进程或者修改采集程序的配置文件
所以我们定义了一个规则,所有的日志数据全部保存在服务器的一个特定的目录下面,我会让filebeat监控这个目录下面的所有文件,如果后期有新增业务日志,那么就会在这个目录下新增一种日志文件,filebeat就可以自动识别,
但是这个时候会有一个问题,filebeat的输出只有一个,多种类型的日志数据会被filebeat采集到同一个topic中,如果各种类型的日志数据全部混到一块,会导致后期处理数据的时候比较麻烦,本来我只想计算一种数据,但是这个时候就需要读取这个大的topic,这里面的数据量很大,计算的时候就会影响计算效率了,也间接的浪费了计算资源。
所以针对这个问题,我们又定义了一个规则,所有的日志数据全部使用json格式,并且在json中增加一个type字段,标识数据的类型,这样每一条数据都有自己的类型标识,然后汇聚到kafka中的一个大的topic中,
为了后面使用方便,我们就需要把这个大topic中的数据,根据业务类型进行拆分,把不同类型的数据分发到不同的topic中。
看这个图中的数据分发层
在这里面我们使用flume对kafka中这个大topic中的数据进行分发,利用flume中的拦截器,解析数据中的type字段的值,把type字段值作为输出的topic名称,这样就可以把相同类型的数据分发到同一个topic中(当然了,这些topic需要提前创建)。
如果想要提高数据分发能力,还可以启动多个flume进程,只需要保证多个flume中指定相同的group id就可以了,这样就可以并行执行数据分发操作。
把数据分发到对应的topic中以后,后面实时计算程序就可以直接消费这个topic进行计算了,不需要读取那个大的topic了,可以提高计算性能,并且还可以把需要备份的topic数据使用flume进行落盘,保存到hdfs上。
所以这个就是数据采集架构的详细设计。
数据来源分析
下面我们来分析一下针对这个项目我们需要采集哪些业务类型的数据,以及这些数据来源于什么地方。
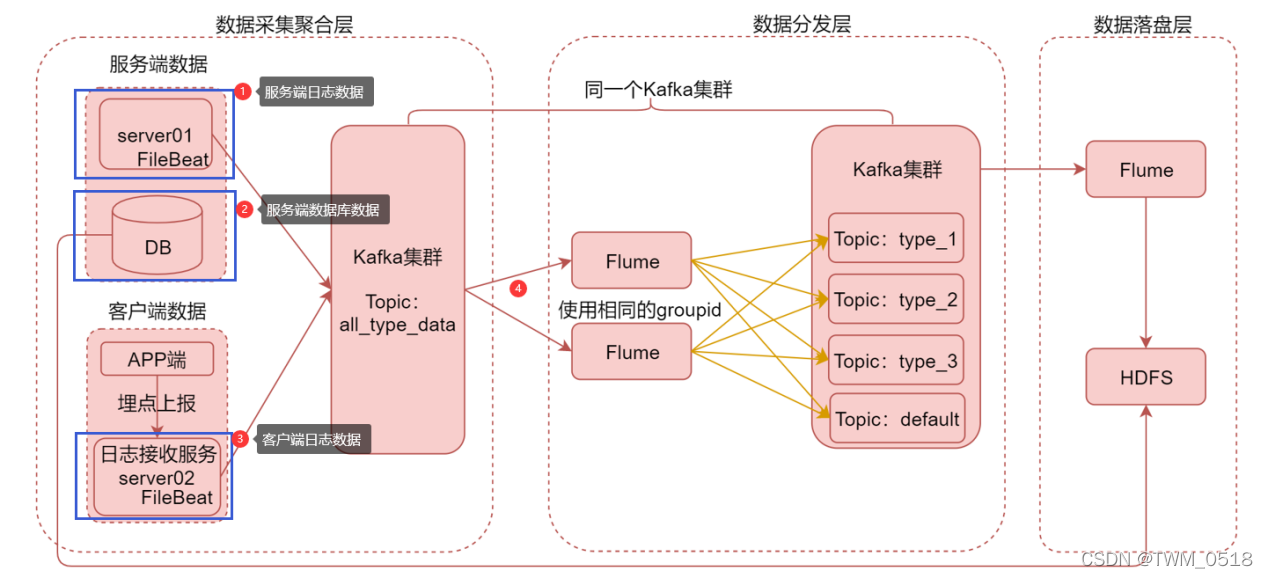
服务端日志数据
首先是服务端日志数据:
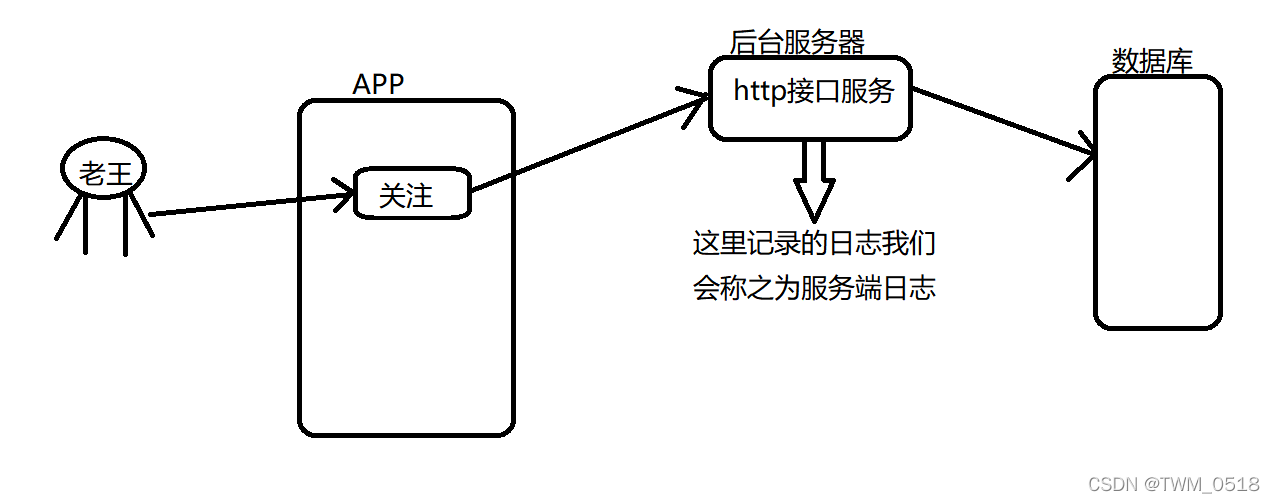
什么是服务端日志呢?可以这样理解,就是我们在app中点击一些按钮的时候,例如:我们要关注一个主播,这个时候,当我们点击这个关注按钮之后,app会去请求对应的接口,接口中的代码逻辑就是将我们关注的数据保存到数据库里面,同时,这个接口也会记录一份日志,因为这个接口是为app提供后台服务的,所以它记录的日志我们称之为服务端日志。
简单画个图是这样的:
在我们这个项目里面,针对服务端日志,主要包括实时粉丝关注数据、视频数据
- 实时粉丝关注数据,因为用户在点击关注以及取消关注的时候都需要调用服务端接口,所以这个数据会在服务端通过日志记录,
- 还有就是视频数据,这里的视频其实就是直播,当主播关闭直播的时候会调用服务端接口,上报本次直播的相关指标数据
其实服务端记录的还有很多类型的数据,不过目前我们暂时只需要这两种数据
服务端数据库数据
接下来看一下服务端数据库中的数据
注意:服务端数据库中的数据就是这个图中数据库中的数据
在这个项目中,我们主要获取:历史粉丝关注数据、主播等级数据
这里面我们需要历史粉丝关注数据,因为我们在做这个项目的时候,我们的直播平台已经运营了两年,所以需要把历史粉丝关注数据初始化到图数据库中,这些历史数据服务端存储在数据库中,所以我们需要从这里取
还有就是主播的等级信息,其实这个数据在服务端日志中也有,但是我们考虑到服务端数据库中的数据是最准确的,【特别是针对用户相关的数据,最好是以服务端数据库中的为准】,所以我们就从服务端数据库中每天凌晨定时把昨天等级发生了变化的主播等级数据导入到hdfs,方便后面离线计算使用
客户端日志数据
刚才我们分析了服务端日志,那什么是客户端日志呢?
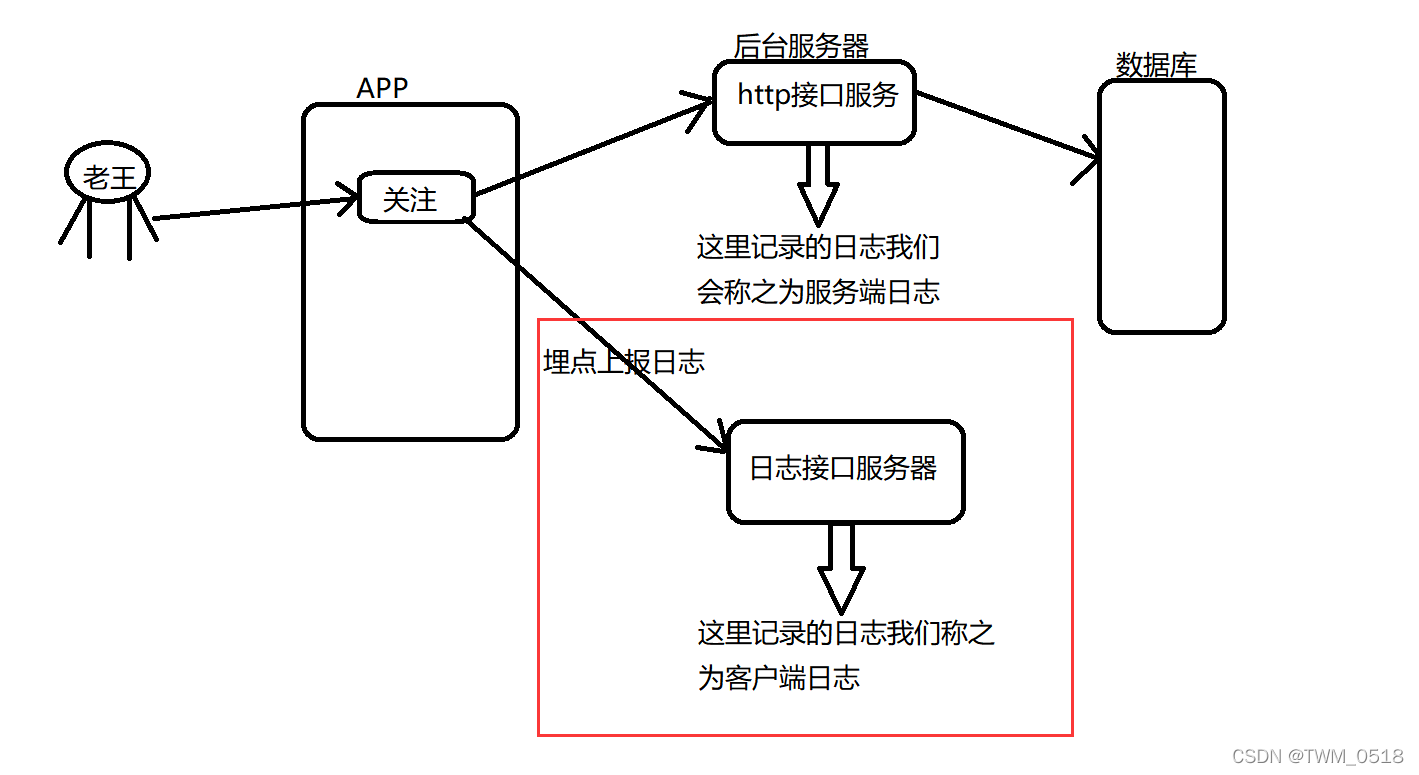
其实就是用户在app客户端操作的时候,直接通过埋点上报的日志数据,这种数据称之为客户端日志数据
简单画个图看一下
总结
那服务端日志和客户端日志有什么区别吗?
为什么有的地方使用客户端日志,有的地方使用服务端日志。
针对我们这个APP里面的关注功能,服务端记录的日志会更加准确,因为服务端接口里面会涉及到对数据库的操作,里面会有事务,只有这条数据真正保存成功的时候才会记录日志,如果保存失败了,是不会记录日志的。
但是客户端日志,只要用户在app中点击了一次关注功能,就会上报一次日志,最终日志接口服务器就会接收到并记录下来,可能会由于网络等原因导致最终关注失败,但是这条日志数据已经被记录下来了,所以相对来说,服务端数据的准确性是比客户端的准确性高的,如果说一份数据在服务端日志和客户端日志中都有的话,我们肯定要优先选择服务端中的日志数据。
一般我们在客户端通过埋点上报的数据都是一些用户行为数据,这些数据就算有一些误差也没多大影响,所以客户端日志中大部分都是一些用户行为数据。
在我们这个项目中,针对客户端日志,我们主要获取用户活跃数据,活跃表示只要用户每天打开app就认为用户活跃了,用户的这些行为数据会在客户端通过埋点上报过来。
这些就是我们这个项目中需要的基础数据。
这三份数据对应到图里面就是这三块。
模拟产生数据
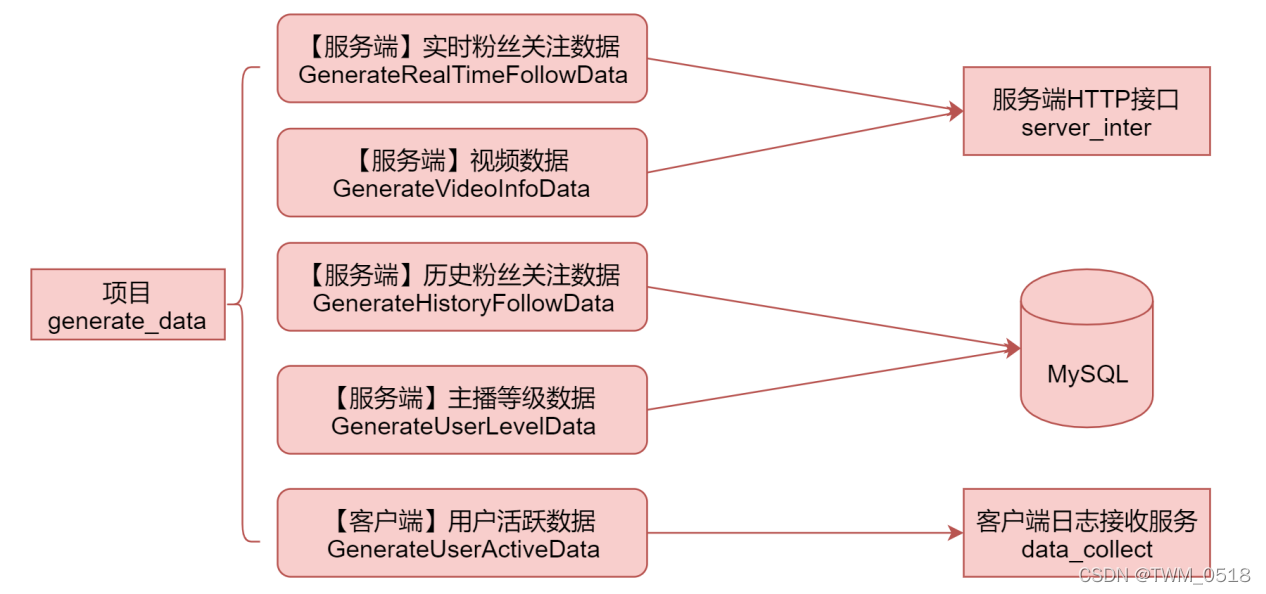
我们通过执行generate_data项目中的这5个入口类,可以模拟产生这5种数据
在这里注意一下,因为不能直接使用企业中的真实数据,所以在这里我会根据企业中真实数据的格式去模拟生成,最终的效果是没有区别的。
生成服务端数据和客户端数据代码如下:
【服务端日志】实时粉丝关注数据: GenerateRealTimeFollowData
【服务端日志】视频数据:GenerateVideoInfoData
【服务端数据库】历史粉丝关注数据:GenerateHistoryFollowData
【服务端数据库】主播等级数据:GenerateUserLevelData
【客户端日志】用户活跃数据:GenerateUserActiveData
在执行这些代码的时候还是需要使用之前在微信公众号中获取的校验码
这些代码在执行的时候会调用服务端接口和客户端日志接收服务,以及还会向MySQL中写入数据
所以需要把这两个服务部署起来,以及在MySQL中初始化数据库和对应的表。
data_collect项目编译打包
对data_collect项目编译打包
部署data_collect
将生成的jar包上传到bigdata01机器的/data/soft/video_recommend/data_collect目录下,如果目录不存在则创建
server_inter项目编译打包
对server_inter项目编译打包
部署server_inter
将生成的jar包上传到bigdata01机器的/data/soft/video_recommend/server_inter目录下,如果目录不存在则创建
初始化数据库脚本
脚本内容如下:
create database if not exists video;
use video;
drop table if exists follower_00;
create table follower_00
(
fuid varchar(10) not null,
uid varchar(10) not null,
timestamp timestamp(0) not null
);
drop table if exists follower_01;
create table follower_01
(
fuid varchar(10) not null,
uid varchar(10) not null,
timestamp timestamp(0) not null
);
drop table if exists follower_02;
create table follower_02
(
fuid varchar(10) not null,
uid varchar(10) not null,
timestamp timestamp(0) not null
);
drop table if exists follower_03;
create table follower_03
(
fuid varchar(10) not null,
uid varchar(10) not null,
timestamp timestamp(0) not null
);
drop table if exists follower_04;
create table follower_04
(
fuid varchar(10) not null,
uid varchar(10) not null,
timestamp timestamp(0) not null
);
drop table if exists follower_05;
create table follower_05
(
fuid varchar(10) not null,
uid varchar(10) not null,
timestamp timestamp(0) not null
);
drop table if exists follower_06;
create table follower_06
(
fuid varchar(10) not null,
uid varchar(10) not null,
timestamp timestamp(0) not null
);
drop table if exists follower_07;
create table follower_07
(
fuid varchar(10) not null,
uid varchar(10) not null,
timestamp timestamp(0) not null
);
drop table if exists follower_08;
create table follower_08
(
fuid varchar(10) not null,
uid varchar(10) not null,
timestamp timestamp(0) not null
);
drop table if exists follower_09;
create table follower_09
(
fuid varchar(10) not null,
uid varchar(10) not null,
timestamp timestamp(0) not null
);
drop table if exists cl_level_user;
create table cl_level_user
(
id int(10) not null,
uid varchar(10) not null,
anchor_exp int(10) not null,
anchor_level int(10) not null,
create_time datetime(0) not null,
update_time datetime(0) not null,
exp int(10) not null,
level int(10) not null
);
模拟产生数据
接下来执行代码,开始模拟产生数据