KMP算法
KMP算法的作用
- 在一个字符串里面查找子串,比如字符串"aabbaabbaaf"中,查找"aabbaaf"
KMP名字由来
- 三个老头,一个姓K,一个姓M,一个姓P
算法思想
这个算法很复杂,需要循序渐进解释。从人类的正常思考方式讲起。
暴力算法
如果让你从中寻找aabbaaf子串,你会怎么找呢?不难想到,通过一次次对比进行判断
第一次对比:
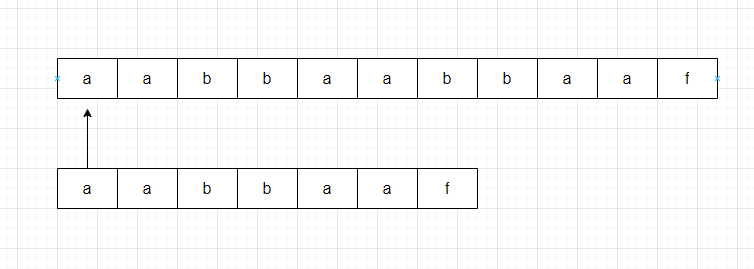
第二次对比:
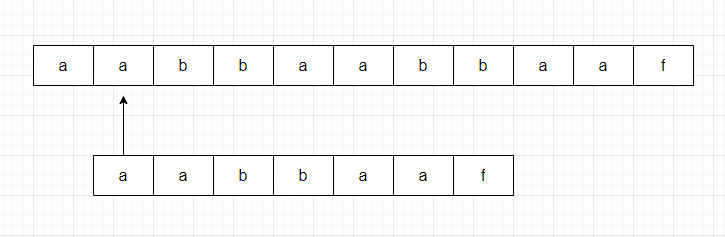
....
....
....
第n次对比:
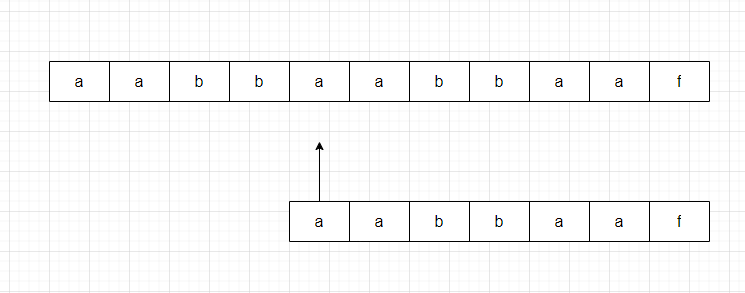
通过循环遍历的方式,对比以每个字母为起始位置,是否能够满足每个字母都和子串相等。
可以,但没必要。
现在我们来思考一下,有没有机会优化它的时间复杂度?
有,为什么?
很简单,你笨心眼寻思,还是刚刚的字符串举例。
第一次对比:
可以看到
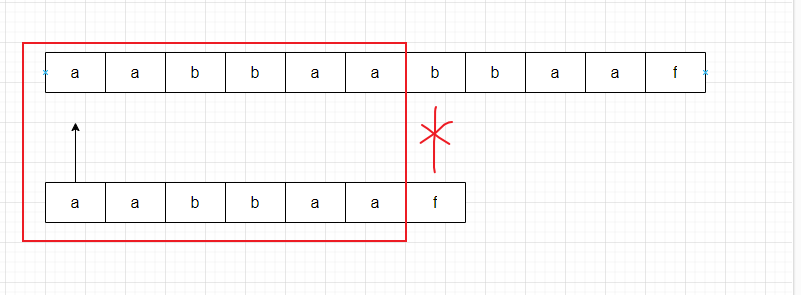
前面字母完全一致,只有最后一个字母不同对吧?
那么我们还有必要进行如下的第二次对比吗?
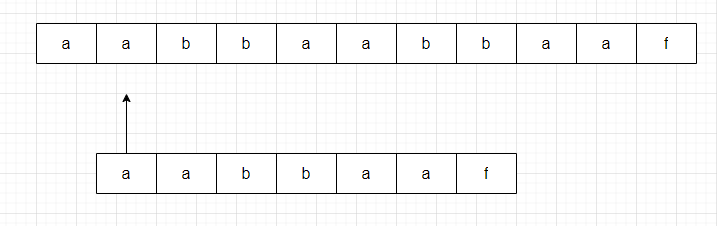
没有必要!为什么?
以人类的思维逻辑来看,我们已经知道自己是"aabbaaf", 又知道第一次对比时候前面6个字符是"aabbaa",那由此可以推断,我们第二次对比一定行不通,因为通过之前的信息,可以确定,第二个字符是a,第三个字符是b,和我们字符串本身"aabbaaf"不一样,因此第二次对比是完全的浪费时间行为。
但是重点来了!我们很难把这个逻辑通过代码告诉计算机的!神奇不神奇!
很简单的道理计算机听不懂,为什么?因为计算机没有记忆,计算机不知道自己是"aabbaaf",他只知道自己的前6个字符和字符串的前6个字符是相同的,第7个是不同的,后面的不知道了。
所以计算机,只会对比,不会记忆!因此我们需要通过一些数字,或者是什么矩阵或者是什么东西,传达一些信息给计算机,来达到让计算机完成这个逻辑的目的。
很复杂,不然不会三个老头一起想,才想出来。
KMP算法
先把此视频完整、不快进地看完。
https://www.youtube.com/watch?v=V5-7GzOfADQ&t=849s
示例:请你在字符串"ababcabcabababd"中找到"ababd".
对于这种复杂的东西,最好的方式是,我先演示给你看。0
第一步(重点):忘记一切你之前看过的KMP的相关文章、视频、博客、教材。我一定让你理解。
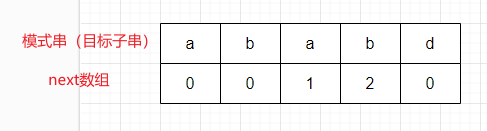
第二步:拿到目标子串,也叫模式串,本实例即"ababd", 并按照以下方法,创建一个数组, 一般称之为next数组。
方法:
- 开头是0
- 从后面找到与开头相同的子串,并按顺序标记1,2,3....
- 其他都是0
如果不同数组如何创建,请务必看完上面的视频!
第三步:配合next数组,进行比较。
方法如下:
- 为了某些便利,将next数组向后移动一位,设一个标志 j 为从索引0开始,一个标志i指向文本串。
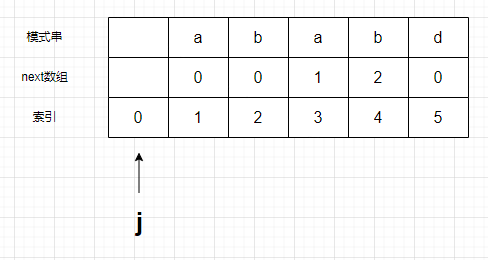
第一步:比较 模式串中第j+1个字母和文本串第i个字母。

结果是匹配,那么i++,j++,继续匹配。
比较j+1 和 i
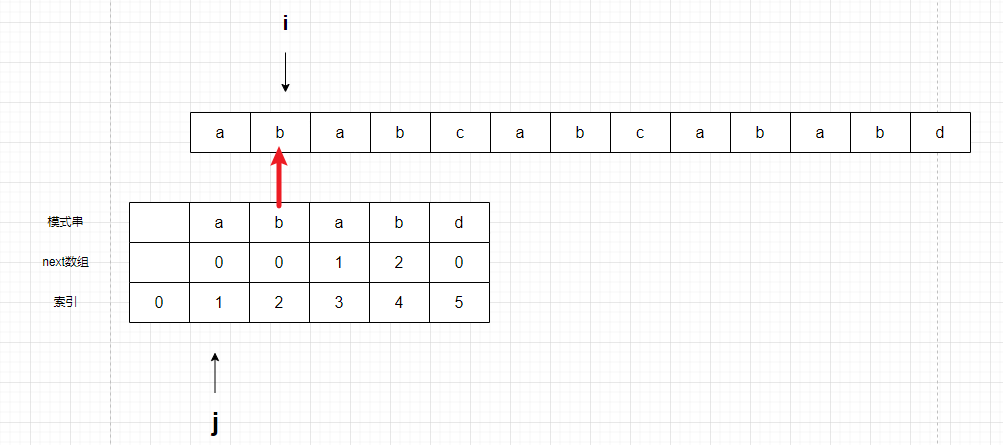
匹配,j++,i++,继续匹配
比较j+1 和 i
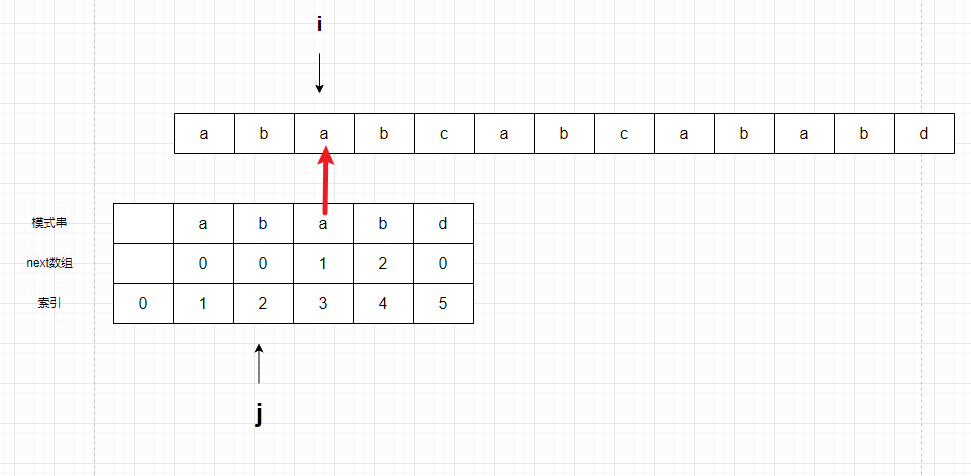
匹配,j++,i++,继续匹配
比较j+1 和 i
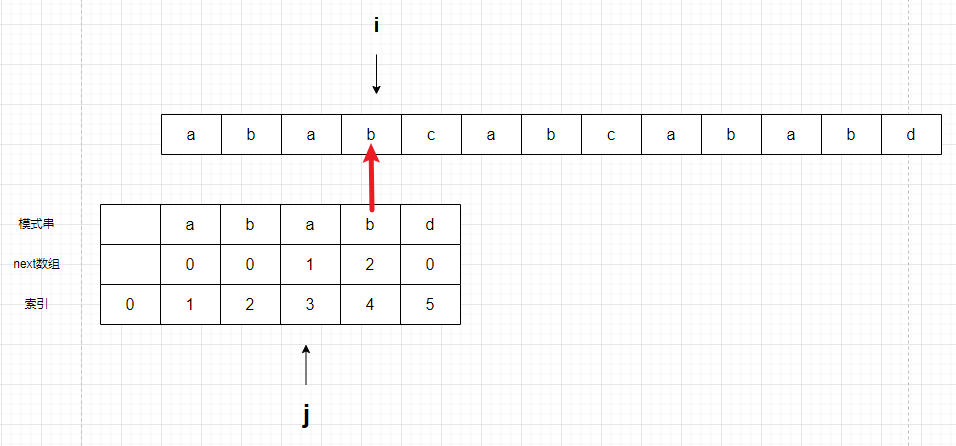
匹配,j++,i++,继续匹配
比较j+1 和 i
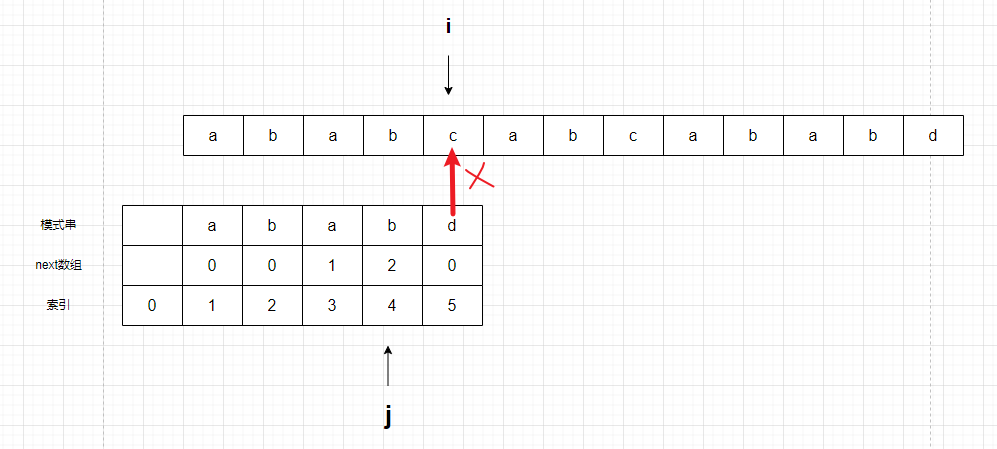
不匹配!此时 j 回退到索引 2 的位置,因为 j 对应的next数组的值是2.
继续比较j+1 和 i
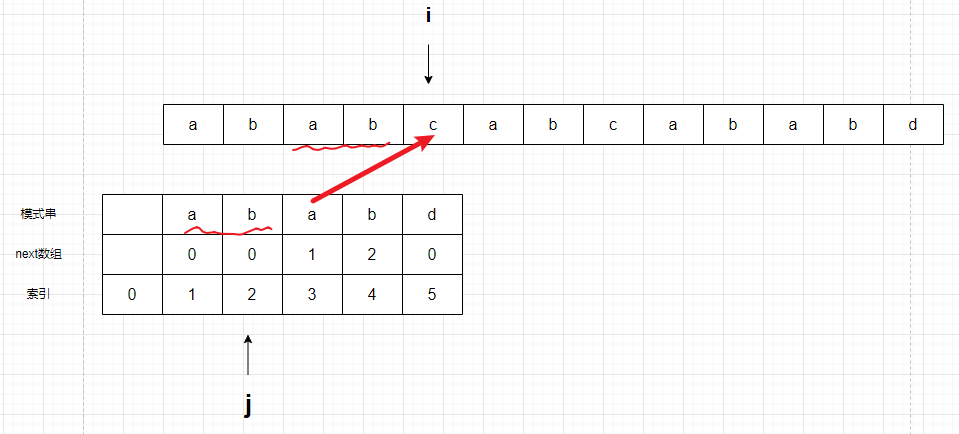
大家有没有发现一个问题,计算机巧妙的找到了它该去的位置。没有对比前面已经正确的ab,直接从第三个字母进行对比。也就是说,通过next数组的配合,完成了与人类记忆类似的功能,通过数组传递的信息,使计算机精准的找到了应该继续匹配位置。
那么这是什么道理呢?
听我说两件事情:
- 第一:next数组的值,代表这个字母是重复开头部分的第几个字母,比如b对应的next数组,值为2,代表它是重复开头部分的第二个字母,也就是说,开头部分一定是a,b。当然,计算机不知道是什么, 只知道模式串string[3],string[4]在重复string[1],string[2]。
也就是说
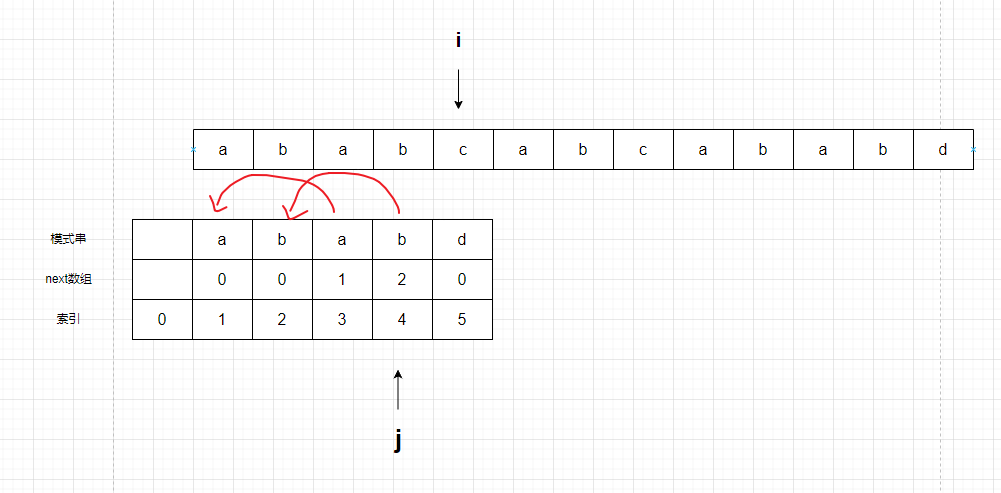
这两个字符,与开头两个字符相等
- 第二:j 既然已经走到了b,说明b已经b以前的所有字符,都与文本串匹配到了,也就是说
前面四个字符都可以匹配上,都相等。
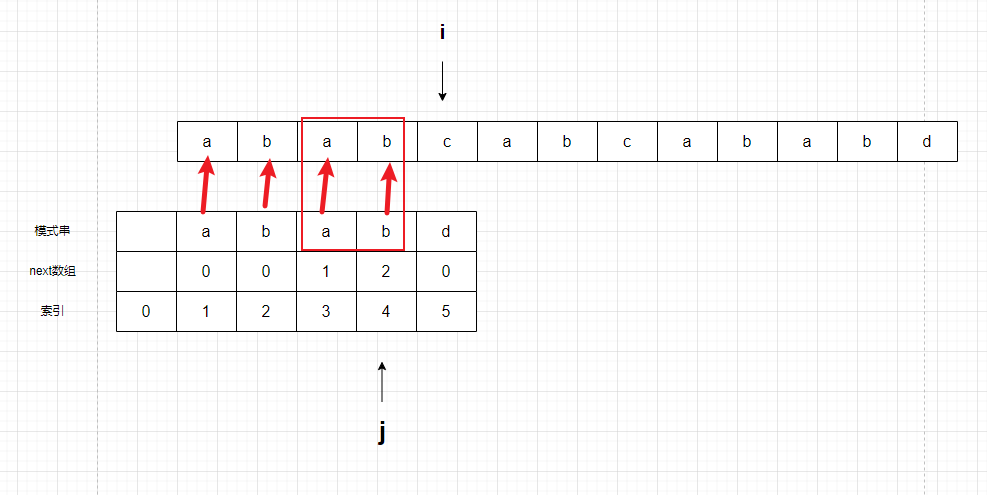
大家注意我画框的部分,根据这两个事情,(注意计算机不知道是ab,只知道相等,我是为了方便理解)
- ab和开头的ab相等
- ab和文本串的ab相等
可以推出,文本串的ab和开头的ab相等!
是一个相等的传递性。
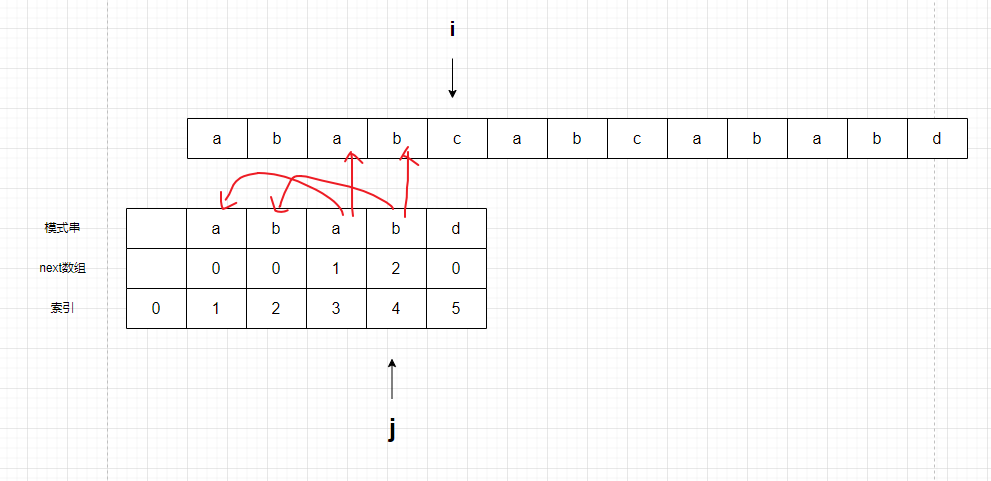
由此可以确定,开头的ab和文本串ab相等,直接对比下一个字符
不相等,根据j的next数组值,回退到索引0
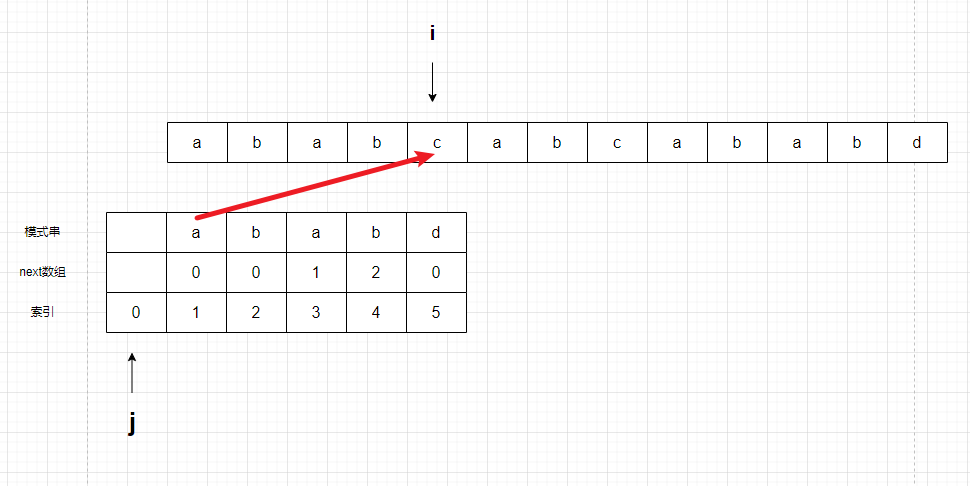
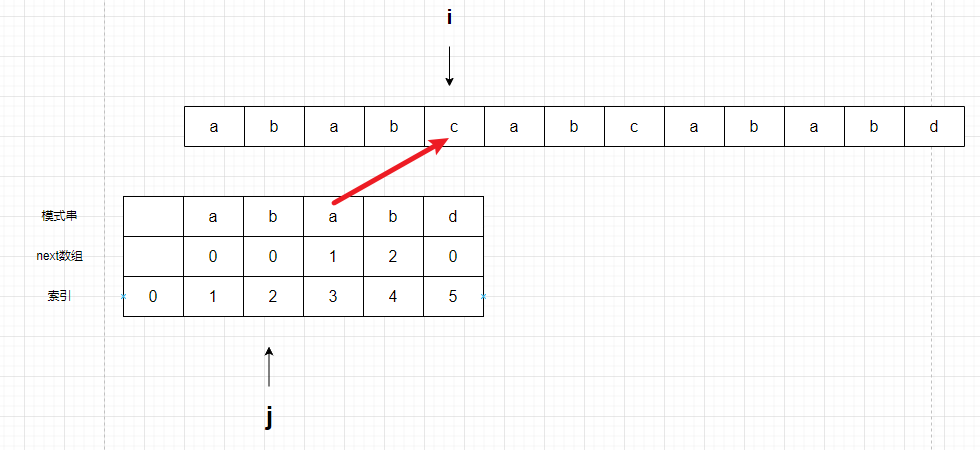
再次不相等,但是j已经到0了,无法再次移动,说白了,就是无法再通过next数组投机取巧了,只能继续向后寻找了。
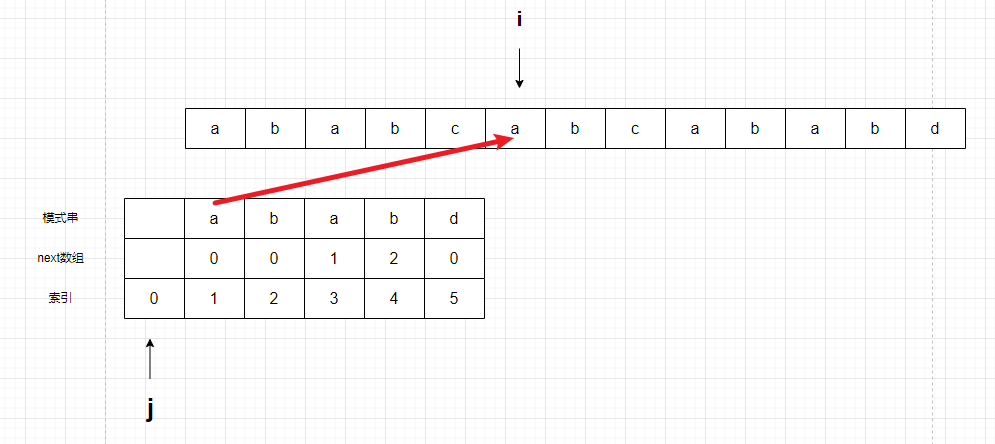
匹配,j++,i++。
继续刚才的方法吧!
通过此方法,可以发现,i永远都不会回退,只需遍历一遍文本串即可。时间复杂度为O(m+n)。
代码实现:
真正学会,必须根据思路手撕代码。通过大概半小时的学习,就可以了解大概思路,但是离手撕代码还差得远
想一想思路,首先根据模式串,创建next数组是必要的。那么如何把刚刚的创建next数组思路,用代码写出来,是有一定难度的。
思路:类似双指针,一个i一个j,然后对比从各个位置开始,与开头部分重合情况。
第一步:
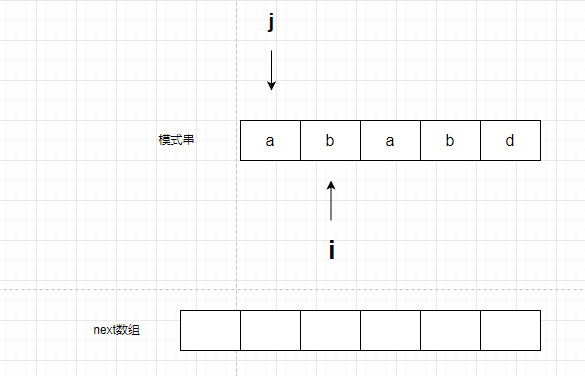
next数组第一个值是空着的,是什么无所谓,只是为了进行查找时方便,如果不设置一个空格也是可以的。这里先实现有空格的,因为可以对接之前的思路。
把j指向第一个,它负责开头部分。把i指向第二个,为什么?因为要查看每个位置与开头部分的重合情况,但是没必要指向第一个,因为第一个是肯定重合,并且根据数组规则,next数组第一个字母对应的值固定为0.
因此,第一个空格不用填,第二个为0(根据规则).
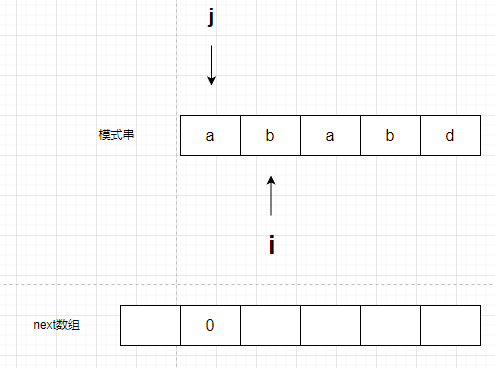
此时,对比s[j]和s[i],有两种情况,相等和不等。
如果相等,就代表从b开始,有1一个字母与开头部分重合。而这个“1个”字母,个数是由j来统计的,因此如果相等j++,然后把next数组的值设置为j。
如果不等,就代表从b开始,有0个字母与开头重合,而这个“0个”,依然是由j来统计的。
进行比较,结果是不等,赋值为0。
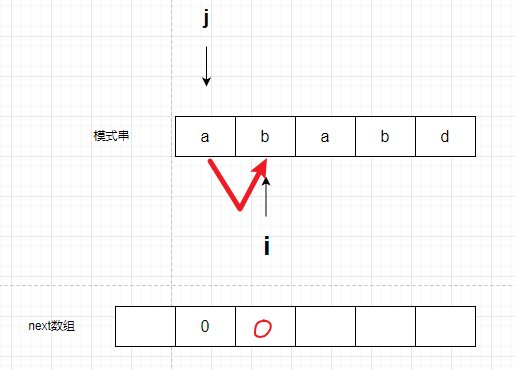
然后i向后移动,比较下一个字母a开始的重合情况
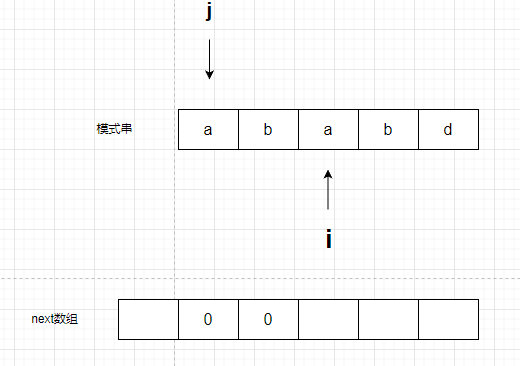
比较s[i]和s[j],相等
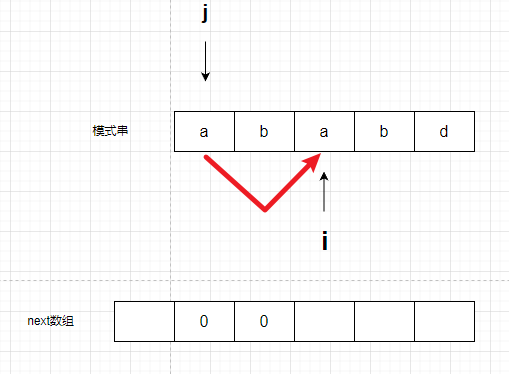
那么用来计数有多少字母重合的 j 就+1,然后next数组,赋值为j,
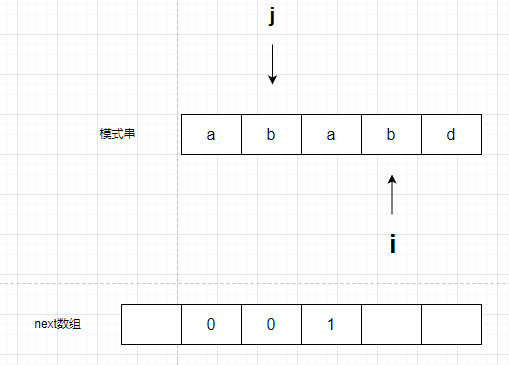
此时j值为1,指向b,next数组a所对应的值为1,代表从a开始,这个是与开头部分重合的第一个字母。
要注意,kmp算法的难点就在于此,以前的算法,这种指针指向的方式比如 j 可能仅仅代表这个第几个字母的单纯索引含义,但是kmp算法中,j第一负责了计数,记录有多少个和开头重合,第二负责指针,指向下一个字母,用来继续比较。这两个东西实际是一码事,但是其中的联系没有其他算法那么明显。
然后继续比较s[i]和s[j],相等,j++,(两个含义:第一计数加1,第二指针右移一位),next[i + 1]赋值为j,因为next数组前面多一个嘛,所以是i + 1。最后一次循环结束,i++
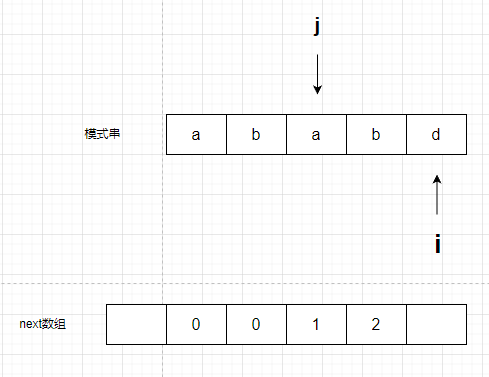
继续对比s[i], s[j]。不等,注意此时 j 进行回退。回退为next[j],也就是0.
然后继续对比s[i]和s[j]
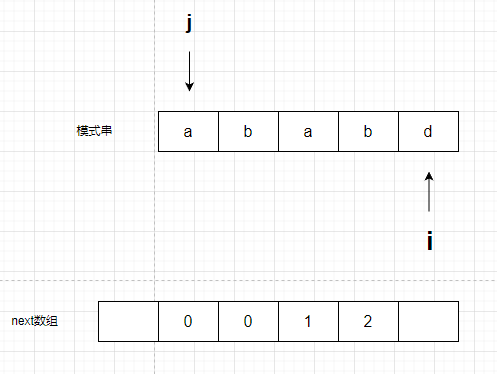
注意,kmp算法有两种回退,不要混淆,原理一样,但是初学者会蒙。
第一种,就是我讲思路的时候,查找字符串的时候进行的回退,第二种就是这个,创建next数组时候的回退。
道理是一样的,第一种是从一个文本串里找模式串,第二种是从模式串里找模式串的开头部分。
此时j 回退到next[j]也就是0,对比s[i]和s[j].
不相等,于是赋值为0,创建next完成
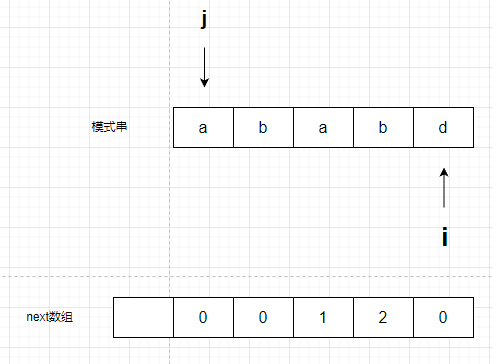
注意:next数组最后一位没有什么用,可以是任何值,因为查找时候都要看前一位的值,因此最后这个数用不到的。
代码
void getNext(const string& s, int* next)
{
//j 从0开始,代表从模式串第1个字母进行比较,同时代表计数重复的部分目前是0个字母
int j = 0;
//根据规则,next数组第一位可以是任意值(留空),第二位对应字符串第一个字母,固定为0
next[1] = 0;
//i代表从每个位置作为起点的时候,与开头部分的重合情况
for (int i = 1; i < s.size(); i++)
{
//如果不相等,并且j不是指向开头部分,也就是说前面有重复,此时优先进行回退再对比,回退一次,看看是否相等,不相等继续回退,直到回退到开头(回退到开头就意味着无法投机取巧了)。
while (j > 0 && s[j] != s[i])
{
//j = next[j],看的是前一位,但是因为next数组前面空一位,所以直接next[j]即可。
//这里比较难想,j代表从i开始有j个重复的,next[j]代表与开头重复的字符串里,有没有重复的,套娃。
j = next[j];
}
if s[i] == s[j]
{
//相等情况,j计数+1,指向右移一位
j++;
//赋值给next数组,代表这个字母是重复开头的第j个,因为无论如何最后都会赋值,因此直接抽出来放在if外边。
//next[i + 1] = j;
}
next[i + 1] = j;
}
}
然后是通过next数组查找字符串的逻辑
道理差不多但是有细微差别。
int strStr(string haystack, string needle) {
//j从0开始,它是代表计数,文本串和模式串有多个字母重复,同时j + 1也是指向要对比的字母的指针。
int j = 0;
//创建next数组,比模式串大1,因为next我们前面留了个空格。
int next[needle.size() + 1];
//创建next数组。
getNext(needle, next);
for (int i = 0; i < haystack.size(); i++)
{
//如果不相等,回退到next[j]
while (j > 0 && haystack[i] != needle[j])
{
j = next[j];
}
//相等,j++
if (haystack[i] == needle[j])
{
j++;
}
//如果全部相等
if (j == needle.size())
{
return i - j + 1;
}
}
return -1;
}
//未完待续