一、背景与挖掘目标
居民在使用家用热水器的过程中,会因为地区气候、不同区域和用户年龄性别差异等原因形成不同的使用习惯。家电企业若能深入了解其产品在不同用户群中的使用习惯,开发符合客户需求和使用习惯的功能,就能开拓新市场。
本案例将依据BP神经网络算法构建洗浴事件识别模型,进而对不同地区的用户的洗浴事件进行识别,然后根据识别结果比较不同客户群的客户使用习惯,以加深对客户需求的理解等。从而厂商便可以对不同的客户群提供最适合的个性化产品,改进新产品的智能化研发并制定相应的营销策略。
国内某热水器生产厂商新研发的一种高端智能热水器,在状态发生改变或者有水流状态时,会采集各监控指标数据。本案例基于热水器采集的时间序列数据,根据水流量和停顿时间间隔,将顺序排列的离散的用水时间节点划分为不同大小的时间区间,每个区间都是一个可理解的一次完整的用水事件,并以热水器一次完整用水事件作为一个基本事件,将时间序列数据划分为独立的用水事件,并识别出其中属于洗浴的事件。基于以上工作,该厂商可从热水器智能操作和节能运行等方面对产品进行优化。
在热水器用户行为分析过程中,用水事件识别是最为关键的环节。根据该热水器生产厂商提供的数据,热水器用户用水事件划分与识别案例的整体目标如下:
1)根据热水器采集到的数据,划分一次完整用水事件。 2)在划分好的一次完整用水事件中,识别出洗浴事件。
二、分析方法与过程
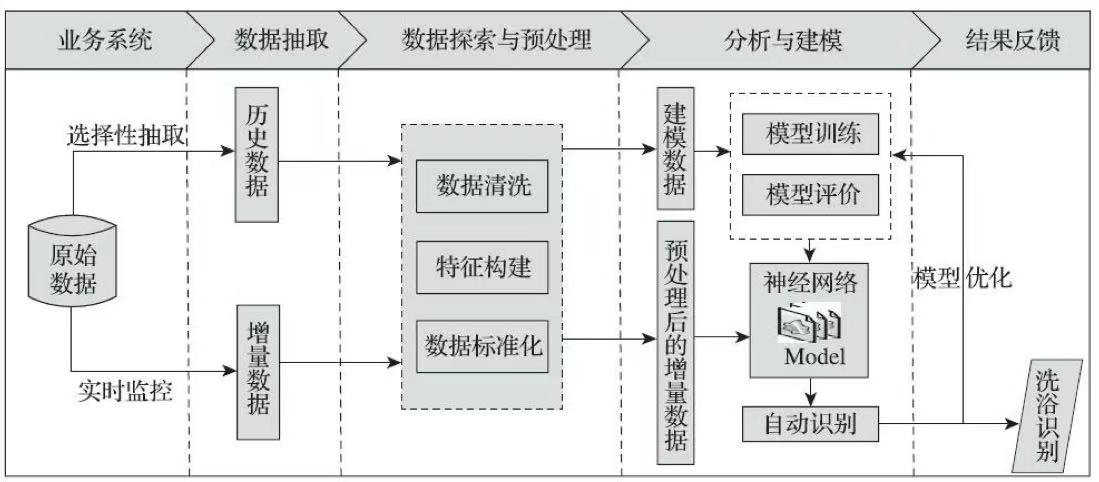
热水器用户用水事件划分与识别案例主要包括以下5个步骤:
1)对热水器用户的历史用水数据进行选择性抽取,构建专家样本。
2)对步骤1形成的数据集,进行数据探索分析与预处理,包括探索水流量的分布情况,删除冗余属性,识别用水数据的缺失值,并对缺失值进行处理,然后根据建模的需要进行属性构造等。最后根据以上处理,对热水器用户用水样本数据建立用水事件时间间隔识别模型和划分 一次完整的用水事件模型,接着在一次完整用水事件划分结果的基础上,剔除短暂用水事件、缩小识别范围等。
3)在步骤2得到的建模样本数据基础上,建立洗浴事件识别模型,对洗浴事件识别模型进行模型分析评价。
4)应用步骤3形成的模型结果,并对洗浴事件划分进行优化。
5)调用洗浴事件识别模型,对实时监控的热水器流水数据进行洗浴事件自动识别。
(一)数据探索分析
本案例对原始数据采用无放回随机抽样法,抽取200家热水器用户自2014年1月1日至2014年12月31日的用水记录作为原始建模数据。由于热水器用户不仅使用热水器来洗浴,还有洗手、洗脸、刷牙、洗菜、做饭等用水行为,所以热水器采集到的数据来自各种不同的用水事件。
热水器采集的用水数据包含12个属性:热水器编码、发生时间、开关机状态、加热中、保温中、有无水流、实际温度、热水量、水流量、节能模式、加热剩余时间和当前设置温度等。

探索分析热水器的水流量状况,其中“有无水流”和“水流量”属性最能直观体现热水器的水流量情况,对这两个属性进行探索分析。
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 4 inputfile = 'E:/大三下/数据分析/数据/第十章/original_data.xls' # 输入的数据文件 5 data = pd.read_excel(inputfile) # 读取数据 6 7 # 查看有无水流的分布 8 # 数据提取 9 lv_non = pd.value_counts(data['有无水流'])['无'] 10 lv_move = pd.value_counts(data['有无水流'])['有'] 11 # 绘制条形图 12 13 fig = plt.figure(figsize = (6 ,5)) # 设置画布大小 14 plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示 15 plt.rcParams['axes.unicode_minus'] = False 16 plt.bar(x=range(2), height=[lv_non,lv_move], width=0.4, alpha=0.8, 17 color='skyblue') 18 plt.xticks([index for index in range(2)], ['无','有']) 19 plt.xlabel('水流状态') 20 plt.ylabel('记录数') 21 plt.title('2019114243032 不同水流状态记录数') 22 plt.show() 23 plt.close() 24 25 # 查看水流量分布 26 water = data['水流量'] 27 # 绘制水流量分布箱型图 28 fig = plt.figure(figsize = (5 ,8)) 29 plt.boxplot(water, 30 patch_artist=True, 31 labels = ['水流量'], # 设置x轴标题 32 boxprops = {'facecolor':'lightblue'}) # 设置填充颜色 33 plt.title('2019114243032 水流量分布箱线图') 34 # 显示y坐标轴的底线 35 plt.grid(axis='y') 36 plt.show()
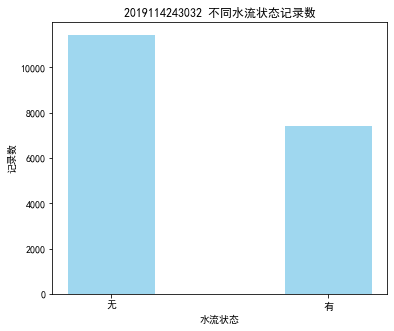
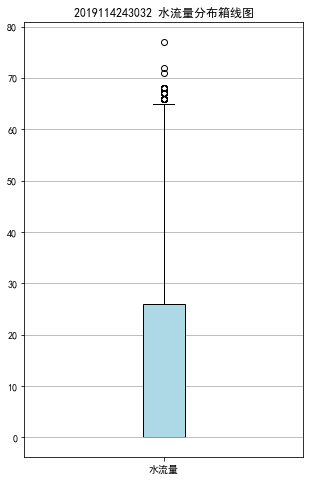
通过不同水流状态的记录条形图可知无水流状态的记录明显比有水流状态的记录要多。通过水流量分布箱型图可知箱体贴近0,说明无水流量的记录较多,水流量的分布与水流状态的分布一致。
“用水停顿时间间隔”定义为一条水流量不为0的流水记录同下一条水流量不为0的流水记录之间的时间间隔。根据现场实验统计,两次用水过程的用水停顿间隔时长一般不大于4分钟。为了探究热水器用户真实用水停顿时间间隔的分布情况,统计用水停顿的时间间隔并做出频率分布表。通过频率分布表分析用户用水停顿时间间隔的规律性,具体的数据如下表所示。
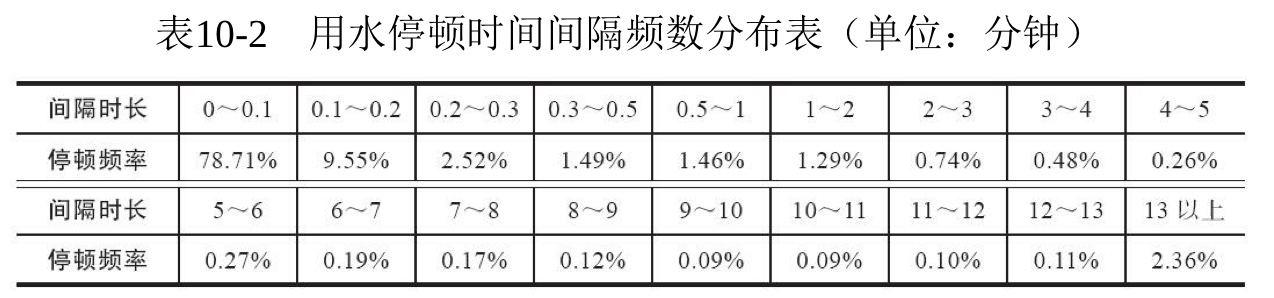
通过分析表10-2可知,停顿时间间隔为0~0.3分钟的频率很高,根据日常用水经验可以判断其为一次用水时间中的停顿;停顿时间间隔为 6~13分钟的频率较低,分析其为两次用水事件之间的停顿。根据现场实验统计用水停顿的时间间隔可知,两次用水事件的停顿时间间隔分布在3~7分钟。
(二)数据预处理
1、属性规约
由于热水器采集的用水数据属性较多,本案例做以下处理。
因为分析的主要对象为热水器用户,分析的主要目标为热水器用户洗浴行为的一般规律,所以“热水器编号”属性可以去除;因为在热水器采集的数据中,“有无水流”属性可以通过“水流量”属性反映出来,“节能模式”属性取值相同均为“关”,对分析无作用,所以可以去除。
以下代码为删除冗余属性“热水器编号”、“有无水流”、“节能模式”。
1 import pandas as pd 2 import numpy as np 3 data = pd.read_excel('E:/大三下/数据分析/数据/第十章/original_data.xls') 4 print('初始状态的数据形状为:', data.shape) 5 # 删除热水器编号、有无水流、节能模式属性 6 data.drop(labels=["热水器编号","有无水流","节能模式"],axis=1,inplace=True) 7 print('删除冗余属性后的数据形状为:', data.shape) 8 data.to_csv('E:/大三下/数据分析/数据/第十章/water_heart.csv',index=False)

2、划分用水事件
热水器用户的用水数据存储在数据库中,记录了各种各样的用水事件,包括洗浴、洗手、刷牙、洗脸、洗衣、洗菜等,而且一次用水事件由数条甚至数千条的状态记录组成。所以本案例首先需要在大量的状态记录中划分出哪些连续的数据是一次完整的用水事件。在用水状态记录中,水流量不为0,表明热水器用户正在使用热水;而水流量为0时,则表明热水器用户用热水时发生停顿或者用热水结束。对于任何一个用水记录,如果它的向前时差超过阈值T,则将它记为事件的开始编号;如果它的向后时差超过阈值T,则将其记为事件的结束编号。
一次完整用水事件的划分步骤如下: 1)读取数据记录,识别所有水流量不为0的状态记录,将它们的发生时间记为序列t1。2)对序列t1构建其向前时差列和向后时差列,并分别与阈值进行比较。向前时差超过阈值T,则将它记为新的用水事件的开始编号;如果向后时差超过阈值T,则将其记为用水事件的结束编号。
循环执行步骤2,直到向前时差列和向后时差列与均值比较完毕, 则结束事件划分。
用水事件划分主要分为两个步骤,即确定单次用水时长间隔,计算两条相邻记录的时间,实现代码如下。
1 import pandas as pd 2 import numpy as np 3 # 读取数据 4 data = pd.read_csv('E:/大三下/数据分析/数据/第十章/water_heart.csv') 5 # 划分用水事件 6 threshold = pd.Timedelta('4 min') # 阈值为4分钟 7 data['发生时间'] = pd.to_datetime(data['发生时间'], format = '%Y%m%d%H%M%S') # 转换时间格式 8 data = data[data['水流量'] > 0] # 只要流量大于0的记录 9 sjKs = data['发生时间'].diff() > threshold # 相邻时间向前差分,比较是否大于阈值 10 sjKs.iloc[0] = True # 令第一个时间为第一个用水事件的开始事件 11 sjJs = sjKs.iloc[1:] # 向后差分的结果 12 sjJs = pd.concat([sjJs,pd.Series(True)]) # 令最后一个时间作为最后一个用水事件的结束时间 13 # 创建数据框,并定义用水事件序列 14 sj = pd.DataFrame(np.arange(1,sum(sjKs)+1),columns = ["事件序号"]) 15 sj["事件起始编号"] = data.index[sjKs == 1]+1 # 定义用水事件的起始编号 16 sj["事件终止编号"] = data.index[sjJs == 1]+1 # 定义用水事件的终止编号 17 print('当阈值为4分钟的时候事件数目为:',sj.shape[0]) 18 sj.to_csv('E:/大三下/数据分析/数据/第十章/sj.csv',index = False)

3、确定单次用水事件时长阈值
对某热水器用户的数据,根据不同的阈值划分用水事件,得到相应的事件个数。先统计出各个阈值下的用水事件的个数,再通过阈值寻优的方式找出最优的阈值,具体实现方式如代码所示。
1 # 确定单次用水事件时长阈值 2 n = 4 # 使用以后四个点的平均斜率 3 threshold = pd.Timedelta(minutes=5) # 专家阈值 4 data['发生时间'] = pd.to_datetime(data['发生时间'], format='%Y%m%d%H%M%S') 5 data = data[data['水流量'] > 0] # 只要流量大于0的记录 6 # 自定义函数:输入划分时间的时间阈值,得到划分的事件数 7 def event_num(ts): 8 d = data['发生时间'].diff() > ts # 相邻时间作差分,比较是否大于阈值 9 return d.sum() + 1 # 这样直接返回事件数 10 dt = [pd.Timedelta(minutes=i) for i in np.arange(1, 9, 0.25)] 11 h = pd.DataFrame(dt, columns=['阈值']) # 转换数据框,定义阈值列 12 h['事件数'] = h['阈值'].apply(event_num) # 计算每个阈值对应的事件数 13 h['斜率'] = h['事件数'].diff()/0.25 # 计算每两个相邻点对应的斜率 14 h['斜率指标']= h['斜率'].abs().rolling(4).mean() # 往前取n个斜率绝对值平均作为斜率指标 15 ts = h['阈值'][h['斜率指标'].idxmin() - n] 16 # 用idxmin返回最小值的Index,由于rolling_mean()计算的是前n个斜率的绝对值平均 17 # 所以结果要进行平移(-n) 18 if ts > threshold: 19 ts = pd.Timedelta(minutes=4) 20 print('计算出的单次用水时长的阈值为:',ts)

4、属性构造
(1)构建用水时长与用水频率属性
1 data = pd.read_csv('E:/大三下/数据分析/数据/第十章/water_heart.csv') # 读取热水器使用数据记录 2 sj = pd.read_csv('E:/大三下/数据分析/数据/第十章/sj.csv') # 读取用水事件记录 3 # 转换时间格式 4 data["发生时间"] = pd.to_datetime(data["发生时间"],format="%Y%m%d%H%M%S") 5 6 # 构造特征:总用水时长 7 timeDel = pd.Timedelta("0.5 sec") 8 sj["事件开始时间"] = data.iloc[sj["事件起始编号"]-1,0].values- timeDel 9 sj["事件结束时间"] = data.iloc[sj["事件终止编号"]-1,0].values + timeDel 10 sj['洗浴时间点'] = [i.hour for i in sj["事件开始时间"]] 11 sj["总用水时长"] = np.int64(sj["事件结束时间"] - sj["事件开始时间"])/1000000000 + 1 12 13 # 构造用水停顿事件 14 # 构造特征“停顿开始时间”、“停顿结束时间” 15 # 停顿开始时间指从有水流到无水流,停顿结束时间指从无水流到有水流 16 for i in range(len(data)-1): 17 if (data.loc[i,"水流量"] != 0) & (data.loc[i + 1,"水流量"] == 0) : 18 data.loc[i + 1,"停顿开始时间"] = data.loc[i +1, "发生时间"] - timeDel 19 if (data.loc[i,"水流量"] == 0) & (data.loc[i + 1,"水流量"] != 0) : 20 data.loc[i,"停顿结束时间"] = data.loc[i , "发生时间"] + timeDel 21 22 # 提取停顿开始时间与结束时间所对应行号,放在数据框Stop中 23 indStopStart = data.index[data["停顿开始时间"].notnull()]+1 24 indStopEnd = data.index[data["停顿结束时间"].notnull()]+1 25 Stop = pd.DataFrame(data={"停顿开始编号":indStopStart[:-1], 26 "停顿结束编号":indStopEnd[1:]}) 27 # 计算停顿时长,并放在数据框stop中,停顿时长=停顿结束时间-停顿结束时间 28 Stop["停顿时长"] = np.int64(data.loc[indStopEnd[1:]-1,"停顿结束时间"].values- 29 data.loc[indStopStart[:-1]-1,"停顿开始时间"].values)/1000000000 30 # 将每次停顿与事件匹配,停顿的开始时间要大于事件的开始时间, 31 # 且停顿的结束时间要小于事件的结束时间 32 for i in range(len(sj)): 33 Stop.loc[(Stop["停顿开始编号"] > sj.loc[i,"事件起始编号"]) & 34 (Stop["停顿结束编号"] < sj.loc[i,"事件终止编号"]),"停顿归属事件"]=i+1 35 36 # 删除停顿次数为0的事件 37 Stop = Stop[Stop["停顿归属事件"].notnull()] 38 39 # 构造特征 用水事件停顿总时长、停顿次数、停顿平均时长、 40 # 用水时长,用水/总时长 41 stopAgg = Stop.groupby("停顿归属事件").agg({"停顿时长":sum,"停顿开始编号":len}) 42 sj.loc[stopAgg.index - 1,"总停顿时长"] = stopAgg.loc[:,"停顿时长"].values 43 sj.loc[stopAgg.index-1,"停顿次数"] = stopAgg.loc[:,"停顿开始编号"].values 44 sj.fillna(0,inplace=True) # 对缺失值用0插补 45 stopNo0 = sj["停顿次数"] != 0 # 判断用水事件是否存在停顿 46 sj.loc[stopNo0,"平均停顿时长"] = sj.loc[stopNo0,"总停顿时长"]/sj.loc[stopNo0,"停顿次数"] 47 sj.fillna(0,inplace=True) # 对缺失值用0插补 48 sj["用水时长"] = sj["总用水时长"] - sj["总停顿时长"] # 定义特征用水时长 49 sj["用水/总时长"] = sj["用水时长"] / sj["总用水时长"] # 定义特征 用水/总时长 50 print('用水事件用水时长与频率特征构造完成后数据的特征为:\n',sj.columns) 51 print('用水事件用水时长与频率特征构造完成后数据的前5行5列特征为:\n', 52 sj.iloc[:5,:5])

(2)构建用水量与用水波动属性
除了用水时长、停顿和频率外,用水量也是识别该事件是否为洗浴事件的重要属性。同时用水波动也是区分不同用水事件的关键。
1 # ´代码10-6 2 3 data["水流量"] = data["水流量"] / 60 # 原单位L/min,现转换为L/sec 4 sj["总用水量"] = 0 # 给总用水量赋一个初始值0 5 for i in range(len(sj)): 6 Start = sj.loc[i,"事件起始编号"]-1 7 End = sj.loc[i,"事件终止编号"]-1 8 if Start != End: 9 for j in range(Start,End): 10 if data.loc[j,"水流量"] != 0: 11 sj.loc[i,"总用水量"] = (data.loc[j + 1,"发生时间"] - 12 data.loc[j,"发生时间"]).seconds* \ 13 data.loc[j,"水流量"] + sj.loc[i,"总用水量"] 14 sj.loc[i,"总用水量"] = sj.loc[i,"总用水量"] + data.loc[End,"水流量"] * 2 15 else: 16 sj.loc[i,"总用水量"] = data.loc[Start,"水流量"] * 2 17 18 sj["平均水流量"] = sj["总用水量"] / sj["用水时长"] # 定义特征 平均水流量 19 # 构造特征:水流量波动 20 # 水流量波动=∑(((单次水流的值-平均水流量)^2)*持续时间)/用水时长 21 sj["水流量波动"] = 0 # 给水流量波动赋一个初始值0 22 for i in range(len(sj)): 23 Start = sj.loc[i,"事件起始编号"] - 1 24 End = sj.loc[i,"事件终止编号"] - 1 25 for j in range(Start,End + 1): 26 if data.loc[j,"水流量"] != 0: 27 slbd = (data.loc[j,"水流量"] - sj.loc[i,"平均水流量"])**2 28 slsj = (data.loc[j + 1,"发生时间"] - data.loc[j,"发生时间"]).seconds 29 sj.loc[i,"水流量波动"] = slbd * slsj + sj.loc[i,"水流量波动"] 30 sj.loc[i,"水流量波动"] = sj.loc[i,"水流量波动"] / sj.loc[i,"用水时长"] 31 32 # 构造特征:停顿时长波动 33 # 停顿时长波动=∑(((单次停顿时长-平均停顿时长)^2)*持续时间)/总停顿时长 34 sj["停顿时长波动"] = 0 # 给停顿时长波动赋一个初始值0 35 for i in range(len(sj)): 36 if sj.loc[i,"停顿次数"] > 1: # 当停顿次数为0或1时,停顿时长波动值为0,故排除 37 for j in Stop.loc[Stop["停顿归属事件"] == (i+1),"停顿时长"].values: 38 sj.loc[i,"停顿时长波动"] = ((j - sj.loc[i,"平均停顿时长"])**2) * j + \ 39 sj.loc[i,"停顿时长波动"] 40 sj.loc[i,"停顿时长波动"] = sj.loc[i,"停顿时长波动"] / sj.loc[i,"总停顿时长"] 41 42 print('用水量和波动特征构造完成后数据的特征为:\n',sj.columns) 43 print('用水量和波动特征构造完成后数据的前5行5列特征为:\n',sj.iloc[:5,:5])
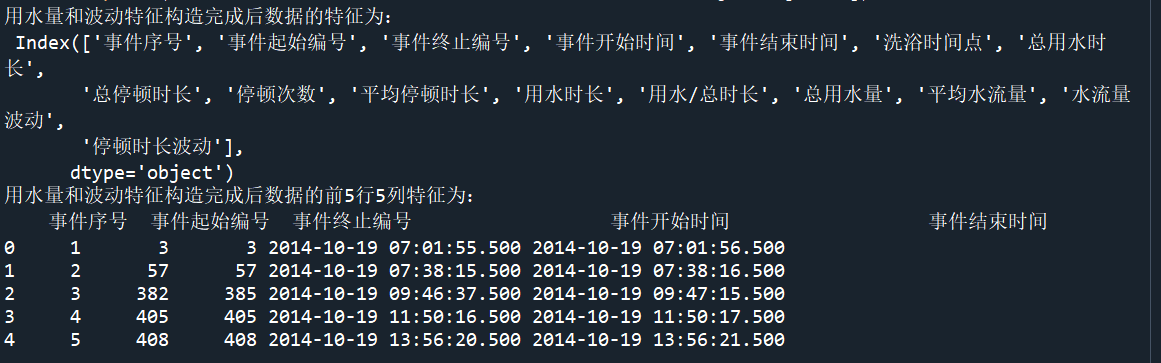
5、筛选候选洗浴事件
洗浴事件的识别是建立在一次用水事件识别的基础上的,也就是从已经划分好的一次用水事件中识别出哪些一次用水事件是洗浴事件。
可以使用3个比较宽松的条件筛选掉那些非常短暂的用水事件,确定不可能为洗浴事件的数据就删除,剩余的事件称为“候选洗浴事件”。 这3个条件是“或”的关系,也就是说,只要一次完整的用水事件满足任意一个条件,就被判定为短暂用水事件,即会被筛选掉。3个筛选条件如下:
1)一次用水事件中总用水量小于5升。 2)用水时长小于100秒。3)总用水时长小于120秒。
基于构建的用水时长、用水量属性,筛选候选洗浴事件,如以下代码所示。
1 # 代码10-7 2 3 sj_bool = (sj['用水时长'] >100) & (sj['总用水时长'] > 120) & (sj['总用水量'] > 5) 4 sj_final = sj.loc[sj_bool,:] 5 sj_final.to_excel('E:/大三下/数据分析/数据/第十章/sj_final.xlsx',index=False) 6 print('筛选出候选洗浴事件前的数据形状为:',sj.shape) 7 print('筛选出候选洗浴事件后的数据形状为:',sj_final.shape)

筛选前,用水事件数目总共为172个,经过筛选,余下75个用水事件。结合日志,最终用于建模的属性的总数为11个,其基本情况如下表所示。
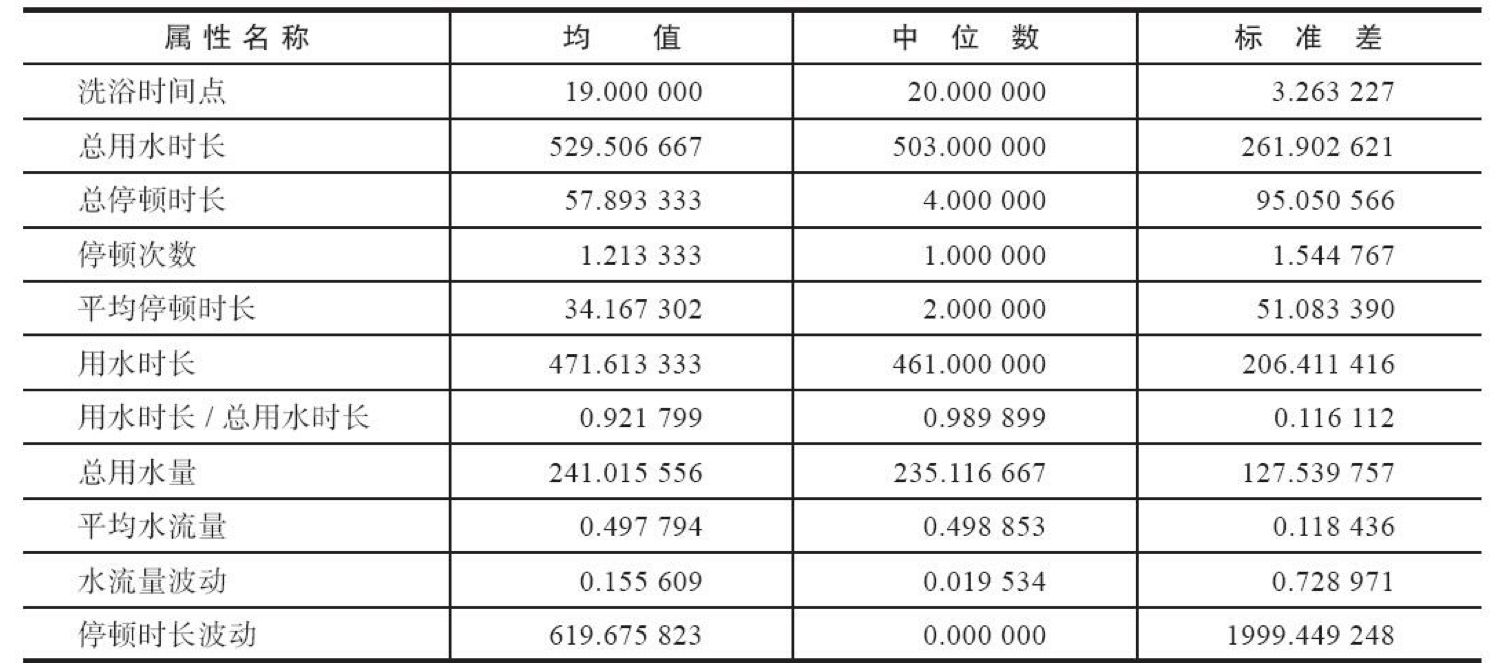
(三)模型构建
根据建模样本数据建立BP神经网络模型识别洗浴事件。由于洗浴事件与普通用水事件在特征上存在不同,而且这些不同的特征要被体现出来。于是,根据热水器用户提供的用水日志,将其中洗浴事件的数据状态记录作为训练样本训练BP神经网络。然后根据训练好的BP神经网络来检验新采集的数据,具体过程如下图所示。

在训练BP神经网络的时候,选取了“候选洗浴事件”的11个属性作为BP神经网络的输入,分别为:洗浴时间点、总用水时长、总停顿时长、平均停顿时长、停顿次数、用水时长、用水时长/总用水时长、总用水量、平均水流量、水流量波动和停顿时长波动。训练BP神经网络时给定的输出为1与0,其中1代表该次事件为洗浴事件,0表示该次事件不是洗浴事件。是否为洗浴事件的标签的依据是热水器的用水记录日志。
构建BP神经网络模型需要注意数据本身属性之间存在的量级差异,因此需要进行标准化,消除量级差异。另外,为了便于后续应用模型,可以用joblib.dump函数保存模型。
1 import pandas as pd 2 from sklearn.preprocessing import StandardScaler 3 from sklearn.neural_network import MLPClassifier 4 #from sklearn.externals import joblib 5 import joblib 6 7 # 读取数据 8 Xtrain = pd.read_excel('E:/大三下/数据分析/数据/第十章/sj_final.xlsx') 9 ytrain = pd.read_excel('E:/大三下/数据分析/数据/第十章/water_heater_log.xlsx') 10 test = pd.read_excel('E:/大三下/数据分析/数据/第十章/test_data.xlsx') 11 # 训练集测试集区分。 12 x_train, x_test, y_train, y_test = Xtrain.iloc[:,5:],test.iloc[:,4:-1],\ 13 ytrain.iloc[:,-1],test.iloc[:,-1] 14 # 标准化 15 stdScaler = StandardScaler().fit(x_train) 16 x_stdtrain = stdScaler.transform(x_train) 17 x_stdtest = stdScaler.transform(x_test) 18 # 建立模型 19 bpnn = MLPClassifier(hidden_layer_sizes = (17,10), max_iter = 200, solver = 'lbfgs',random_state=50) 20 bpnn.fit(x_stdtrain, y_train) 21 # 保存模型 22 joblib.dump(bpnn,'E:/大三下/数据分析/程序/第十章/water_heater_nnet.m') 23 print('构建的模型为:\n',bpnn)

在训练BP神经网络时,对神经网络的参数进行了寻优,发现含有两个隐层的神经网络训练效果较好,其中两个隐层的隐节点数分别为17 和10时训练的效果较好。
根据样本,得到训练好的神经网络后,就可以用来识别对应的热水器用户的洗浴事件,其中待检测的样本的11个属性作为输入,输出层输出一个在[-1,1]范围内的值,如果该值小于0,则该事件不是洗浴事件,如果该值大于0,则该事件是洗浴事件。某热水器用户记录了两周的热水器用水日志,将前一周的数据作为训练数据,将后一周的数据作为测试数据,代入上述模型进行测试。
(四)模型检验
结合模型评价的相关知识,使用精确率(precision)、召回率 (recall)和F1值来衡量模型评价的效果较为客观、准确。同时结合ROC曲线,可以更加直观地评价模型的效果。
1 # 模型评价 2 from sklearn.metrics import classification_report 3 from sklearn.metrics import roc_curve 4 import joblib 5 import matplotlib.pyplot as plt 6 7 bpnn = joblib.load('E:/大三下/数据分析/程序/第十章/water_heater_nnet.m') # 加载模型 8 y_pred = bpnn.predict(x_stdtest) # 返回预测结果 9 print('神经网络预测结果评价报告:\n',classification_report(y_test,y_pred)) 10 # 绘制roc曲线图 11 plt.rcParams['font.sans-serif'] = 'SimHei' # 显示中文 12 plt.rcParams['axes.unicode_minus'] = False # 显示负号 13 fpr, tpr, thresholds = roc_curve(y_pred,y_test) # 求出TPR和FPR 14 plt.figure(figsize=(6,4)) # 创建画布 15 plt.plot(fpr,tpr) # 绘制曲线 16 plt.title('2019114243032 用户用水事件识别ROC曲线') # 标题 17 plt.xlabel('FPR') # x轴标签 18 plt.ylabel('TPR') # y轴标签 19 plt.savefig('E:/大三下/数据分析/数据/第十章/用户用水事件识别ROC曲线.png') # 保存图片 20 plt.show() # 显示图形
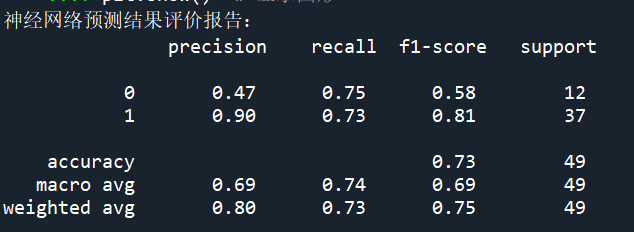
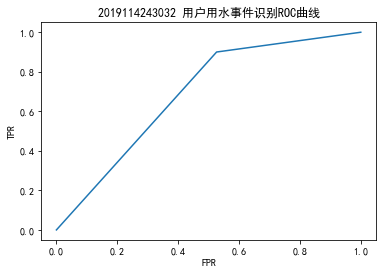
根据模型评估报告可以看出,在洗浴事件的识别上精确率 (precision)非常高,达到了90%,同时召回率(recall)也达到了70%以上。综合上述结果,可以确定此次创建的模型是有效且效果良好的,能够用于实际的洗浴事件的识别中。