作业①
爬取股票信息
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import sqlite3
import datetime
itemscount=0
pagescount=0
class MySpider:
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.31"
}
def startUp(self, url):
# Initializing Chrome browser
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
# Initializing variables
self.threads = []
self.No = 0
self.imgNo = 0
# Initializing database
try:
self.con = sqlite3.connect("stock1.db")
self.cursor = self.con.cursor()
try:
# 如果有表就删除
self.cursor.execute("drop table stock1")
except:
pass
try:
# 建立新的表
sql = "create table stock1 (mNo varchar(32) primary key, mcode varchar(256),mname varchar(256)," \
"t1 varchar(256),t2 varchar(256),t3 varchar(256),t4 varchar(256),t5 varchar(256),t6 varchar(256)," \
"t7 varchar(256),t8 varchar(256),t9 varchar(256),t10 varchar(256))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
self.driver.get(url)
# keyInput = self.driver.find_element_by_id("key_S")
# keyInput.send_keys(key)
# keyInput.send_keys(Keys.ENTER)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err)
def insertDB(self, mNo, mcode, mname, t1,t2,t3,t4,t5,t6,t7,t8,t9,t10):
try:
sql = "insert into stock1 (mNo, mcode, mname, t1,t2,t3,t4,t5,t6,t7,t8,t9,t10) values (?,?,?,?,?,?,?,?,?,?,?,?,?)"
self.cursor.execute(sql, (mNo, mcode, mname, t1,t2,t3,t4,t5,t6,t7,t8,t9,t10))
except Exception as err:
print(err)
def showDB(self):
try:
con = sqlite3.connect("stock1.db")
cursor =con.cursor()
print("%-8s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%s"
%("No", "mcode", "mname", "t1","t2","t3","t4","t5","t6","t7","t8","t9","t10"))
cursor.execute("select mNo, mcode, mname, t1,t2,t3,t4,t5,t6,t7,t8,t9,t10 from stock1 order by mNo")
rows = cursor.fetchall()
for row in rows:
print("%-8s %-16s %-16s %-16s %-16s %-16s %-16s %-16s %-16s %-16s %-16s %-16s %s"
% (row[0], row[1], row[2], row[3],row[4], row[5], row[6], row[7],row[8], row[9], row[10],
row[11],row[12]))
con.close()
except Exception as err:
print(err)
def processSpider(self):
try:
lis =self.driver.find_elements_by_xpath("//div[@id='table_wrapper']//div[@class='listview full']//tbody//tr")
for li in lis:
print(self.driver.current_url)
try:
mcode = li.find_element_by_xpath('./td[position()=2]').text
except:
mcode = ""
try:
mname = li.find_element_by_xpath('.//td[@class="mywidth"]').text
except:
mname = ""
try:
# 价格
t1 = li.find_element_by_xpath('.//td[@class="mywidth2"]').text
# 涨跌幅
t2 = li.find_element_by_xpath('.//td[@class="mywidth"]').text
# 涨跌额
t3 = li.find_element_by_xpath('./td[position()=6]').text
# 成交量
t4 = li.find_element_by_xpath('./td[position()=8]').text
# 成交额
t5 = li.find_element_by_xpath('./td[position()=9]').text
# 振幅
t6 = li.find_element_by_xpath('./td[position()=10]').text
# 最高
t7 = li.find_element_by_xpath('./td[position()=11]').text
# 最低
t8 = li.find_element_by_xpath('./td[position()=12]').text
# 今开
t9 = li.find_element_by_xpath('./td[position()=13]').text
# 昨收
t10 = li.find_element_by_xpath('./td[position()=14]').text
except:
t1 = ""
t2 = ""
self.No = self.No + 1
no = str(self.No)
while len(no) < 6:
no = "0" + no
print(no, mcode, mname, t1, t2, t3, t4, t5, t6, t7, t8, t9, t10)
self.insertDB(no, mcode, mname, t1, t2, t3, t4, t5, t6, t7, t8, t9, t10)
except Exception as err:
print(err)
def executeSpider(self, url):
global itemscount
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url)
print("Spider processing......")
self.processSpider()
print("一共爬取了"+str(itemscount)+"条股票信息")
print("Spider closing......")
self.closeUp()
for t in self.threads:
t.join()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
# url = "http://quote.eastmoney.com/center/gridlist.html#sh_a_board"
# url = "http://quote.eastmoney.com/center/gridlist.html#sz_a_board"
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
spider.executeSpider(url)
continue
elif s == "2":
spider.showDB()
continue
elif s == "3":
break
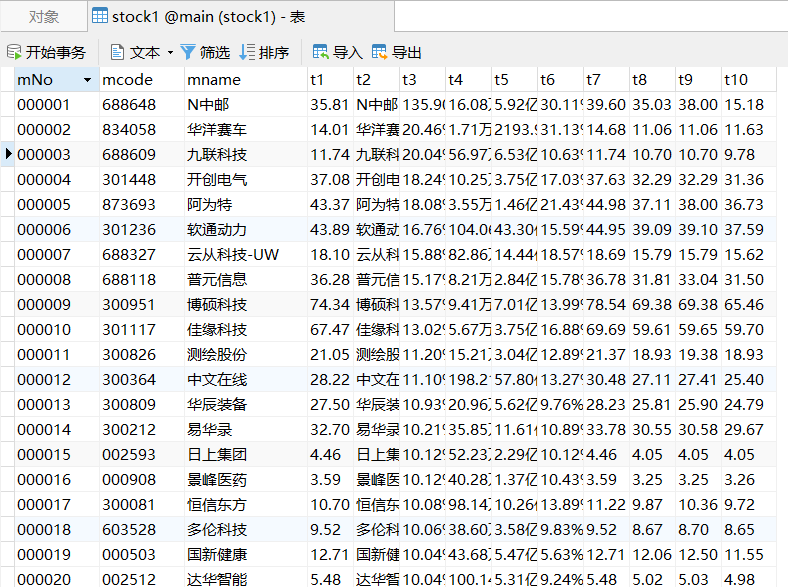
运行结果:
心得体会
该题采用Selenium 框架+ MySQL数据库存储技术路线爬取股票网信息
作业②
爬取中国大学MOOC网信息
import time
import pandas as pd
from selenium import webdriver
from scrapy.selector import Selector
from sqlalchemy import create_engine
from selenium.webdriver.common.by import By
url = 'https://www.icourse163.org/'
browser = webdriver.Chrome()
browser.get(url)
time.sleep(2)
# 找到登录按钮并点击
login=browser.find_element(By.XPATH,'//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div')
login.click()
time.sleep(3)
browser.switch_to.default_content()
browser.switch_to.frame(browser.find_elements(By.TAG_NAME,'iframe')[0])
# 输入账号密码信息
telephone=browser.find_element(By.XPATH,'/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input')
telephone.clear()
telephone.send_keys("15260726980")
time.sleep(3)
password=browser.find_element(By.XPATH,'/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]')
password.clear()
password.send_keys("R2023zwl111")
deng=browser.find_element(By.XPATH,'//*[@id="submitBtn"]')
deng.click()
time.sleep(5)
browser.switch_to.default_content()
select_course=browser.find_element(By.XPATH,'/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[1]/div/div/div/div/div/div/input')
select_course.send_keys("python")
dianji=browser.find_element(By.XPATH,'//html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[2]/span')
dianji.click()
time.sleep(3)
content = browser.page_source
print(content)
# 退出
browser.quit()
selector = Selector(text=content)
rows = selector.xpath("//div[@class='m-course-list']/div/div")
data = []
# 爬取网站信息
for row in rows:
lis = []
# 课程名称
course1= row.xpath(".//span[@class=' u-course-name f-thide']//text()").extract()
course="".join(course1)
# 学校
college=row.xpath(".//a[@class='t21 f-fc9']/text()").extract_first()
# 主讲教师
teacher=row.xpath(".//a[@class='f-fc9']//text()").extract_first()
# 团队成员
team1 = row.xpath(".//a[@class='f-fc9']//text()").extract()
team=",".join(team1)
# 参加人数
count = row.xpath(".//span[@class='hot']/text()").extract_first()
# 课程进度
process = row.xpath(".//span[@class='txt']/text()").extract_first()
# 课程简介
brief1=row.xpath(".//span[@class='p5 brief f-ib f-f0 f-cb']//text()").extract()
brief=",".join(brief1)
lis.append(course)
lis.append(college)
lis.append(teacher)
lis.append(team)
lis.append(count)
lis.append(process)
lis.append(brief)
data.append(lis)
df = pd.DataFrame(data=data, columns=['course','college','teacher','team','count','process','brief'])
print(df)
engine = create_engine("mysql+mysqlconnector://root:102102109@127.0.0.1:3306/MyDB")
df.to_sql("mooc", engine, if_exists="replace", index=False)
运行结果:

心得体会
在模拟登录的过程中,元素会有一个id属性,这个是表示用户的身份,这边不能将其作为我们找元素的依据,需要绕开这个id。而在爬取的过程中出现了登录所需要点击的界面通过xpath查取不到,经过对源码的分析后,发现要通过switch_to.frame进入frame框架页面才能爬取到该内容。
作业③
华为云
要求:
- 掌握大数据相关服务,熟悉 Xshell 的使用
- 完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
(1)环境搭建: - 任务一:开通 MapReduce 服务
打开华为云官网,进行登录后在首页的“产品”>“EI企业智能”>“大数据计算”中找到MapReduce服务(MRS),并进行集群的申请和配置,具体操作同文档。
(2)实时分析开发实战:
- 任务一:Python 脚本生成测试数据
用xftp7将本地的autodatapython.py文件上传至服务器/opt/client/目录:

使用mkdir命令在/tmp下创建目录flume_spooldir:

执行Python命令,测试生成100条数据并查看:

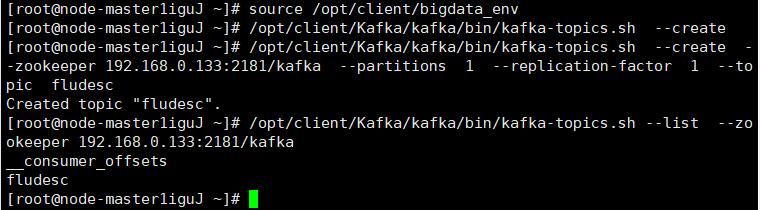
- 任务二:配置 Kafka
设置环境变量,在kafka中创建topic并查看:
- 任务三: 安装 Flume 客户端
解压下载的flume客户端文件步并校验文件包,接着解压“MRS_Flume_ClientConfig.tar”文件:

安装Flume环境变量,查看安装输出信息,如有Components client installation is complete输出则表示客户端运行环境安装成功:


解压Flume客户端:

安装Flume客户端并重启:

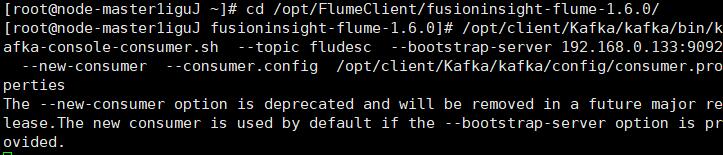
- 任务四:配置 Flume 采集数据
修改配置文件并创建消费者消费kafka中的数据:
执行Python脚本命令,再生成一份数据,接着查看Kafka中是否有数据产生:


心得体会
通过该实验,我掌握了使用Flume进行实时流前端数据采集的方法,为之后数据处理和数据的可视化打下了一定基础,同时我也掌握了在实时场景下,大数据的数据采集能力。