main.go
Kubegres 使用 Kubebuilder V3 创建, 所以直接进行到 main.go.
func main() { ... if err = (&controllers.KubegresReconciler{ Client: mgr.GetClient(), Logger: ctrl.Log.WithName("controllers").WithName(ctx2.KindKubegres), Scheme: mgr.GetScheme(), Recorder: mgr.GetEventRecorderFor("Kubegres-controller"), }).SetupWithManager(mgr); err != nil { setupLog.Error(err, "unable to create controller", "controller", ctx2.KindKubegres) os.Exit(1) } ... }
KubegresReconciler 增加了 Logger 和 Recorder, Logger 用于日志记录, Recorder 用于记录 events.
转进到 api/v1/kubegres_types.go, 查看 Kubegres 的定义.
KubegresSpec
如何去描述一个 PostgreSql 集群期望的状态?
第一, 针对于数据库本身的部署, 应该分配多大的存储空间? pgdata 挂载在哪里? Volume 使用哪个 PVC? 在本例中, KubegresDatabase 直接存储了 StorageClass, 二把 PVC 进行了单独的列项.
第二, 调度策略, 与 Workload Resource 调度相关的, 就两个, 一个是 node/pod affinity, 一个是忍受什么样的污点, toleration.
第三, 故障转移, 就是当 Primary 节点发生故障, 是否允许将 Replica 推举为 Primary.
第四, 备份, 多久备份一次, 这要用到 CronJob 定时任务, 然后备份到哪个文件夹, 然后备份的 PVC 也要准备.
第五, 除去一下子就能想到的, 存活探针和 Ready 探针, Postgres 的 Docker Image 从哪里下载, 预定义的 ConfigMap, 对外提供服务的端口, 还有一些环境变量.
// ----------------------- SPEC ------------------------------------------- // 用于描述 Postgres 实例 type KubegresDatabase struct { // 集群中每个 Postgres Pod 数据库所占据的存储空间大小, "Mi" 和 "Gi" 属于 Kubernetes 惯用法, 注意 "Mi" 是 1024*1024 Size string `json:"size,omitempty"` // Postgres 容器中 pgdata 的挂载点. 也就是 PVC postgres-db-xx 的挂载位置 VolumeMount string `json:"volumeMount,omitempty"` // 在 Dynamic Provisioning 中, StorageClass 用作创建 PV 的模板, 提供 provisioner 和 parameters. // 在 Static Provisioning 中, StorageClass 用作 PV 和 PVC 的绑定决策. // 如果未设置, 则使用默认的 StorageClass, 如果没有开启 DefaultStorageClass 的 Admission Plugin, 则就是 "" StorageClassName *string `json:"storageClassName,omitempty"` } // 用于描述 Postgres 备份 type KubegresBackUp struct { // 通过标准的 cron 格式来指定多久进行一次备份 Schedule string `json:"schedule,omitempty"` // 在 docker 镜像中备份的存储位置, 一个用于备份的 Volume 会挂载到这个文件夹. VolumeMount string `json:"volumeMount,omitempty"` // PVC 定义备份的数据存储到哪个 Volume. PvcName string `json:"pvcName,omitempty"` } // 用于描述 Postgres 故障转移 type KubegresFailover struct { // 关闭 PostgresSql 集群的自动故障转移功能. // 如果为 true 则当一个 Primary 或 Replica PostgresSql 实例不在线 Kubegres 不会尝试故障转移和修复集群. // 在手动管理一个 node (重启, patching等) 的维护期间使用. IsDisabled bool `json:"isDisabled,omitempty"` // 允许手动将一个 Replica PostgresSql 推举为一个 Primary Pod. // 需要一个被期望推举为 Primary 的 Replica Pod 的 name 字段 // 无论 failover.isDisabled true or false, 总是可以手动推举一个 Pod PromotePod string `json:"promotePod,omitempty"` } // 用于描述 Postgres 调度 type KubegresScheduler struct { // 自定义 Pod/Node affinity 策略 Affinity *v1.Affinity `json:"affinity,omitempty"` // 自定义 tolerations 策略 (污点是否要 tolerated) Tolerations []v1.Toleration `json:"tolerations,omitempty"` } // PVC 模板 type VolumeClaimTemplate struct { Name string `json:"name,omitempty"` Spec v1.PersistentVolumeClaimSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"` } // 用于描述 Volume type Volume struct { // 允许 Postgres container(s) 挂载一个或多个 Volumes 的不同挂载点. VolumeMounts []v1.VolumeMount `json:"volumeMounts,omitempty"` // 允许声明可以被挂载到 Postgres container(s) 的一个或多个 Volumes. Volumes []v1.Volume `json:"volumes,omitempty"` // 允许使用 StorageClass 的 provisioner 自动为 Postgres container(s) 提供一个或多个 Volumes. VolumeClaimTemplates []VolumeClaimTemplate `json:"volumeClaimTemplates,omitempty"` } // 探针 type Probe struct { // 存活探针, 否则重启容器 LivenessProbe *v1.Probe `json:"livenessProbe,omitempty"` // 是否准备好接入流量 ReadinessProbe *v1.Probe `json:"readinessProbe,omitempty"` } // KubegresSpec 定义 Kubegres 的期望状态 type KubegresSpec struct { // 集群中的节点数量 Replicas *int32 `json:"replicas,omitempty"` // 指定 Postgres Docker image, 建议使用 Docker 官方维护的版本, 12.4 及以上. Image string `json:"image,omitempty"` // Postgres docker container 公开的端口. Port int32 `json:"port,omitempty"` // 允许从私有 repo 中提取自定义 Postgres images. ImagePullSecrets []v1.LocalObjectReference `json:"imagePullSecrets,omitempty"` // 允许设置 ConfigMap, 其中包含 Kubegres 所需的配置文件及内容. CustomConfig string `json:"customConfig,omitempty"` Database KubegresDatabase `json:"database,omitempty"` Failover KubegresFailover `json:"failover,omitempty"` Backup KubegresBackUp `json:"backup,omitempty"` // 环境变量 Env []v1.EnvVar `json:"env,omitempty"` Scheduler KubegresScheduler `json:"scheduler,omitempty"` // 定义 requests 和 limits Resources v1.ResourceRequirements `json:"resources,omitempty"` Volume Volume `json:"volume,omitempty"` SecurityContext *v1.PodSecurityContext `json:"securityContext,omitempty"` Probe Probe `json:"probe,omitempty"` }
KubegresStatus
首先要区分一个概念, Status 和 State 有什么区别? 中文语境里两个都是状态, 但是细分呢, 尤其是后面会有一堆 state 的代码, 需要进行一个概念上的区分.

State 是事物自身的状态, 而 Status 表达是形态转换之中观察到, 所谓有显著特征的离散中间值.
数据库作为典型的有状态应用, 一方面该不该使用 Docker 部署数据库的争论尚在, 另一方面云原生数据库又已经成了新的数据库开发的标准, 总之呢, 这里使用 StatefulSet 部署数据库应用, 通过 Headless Service 来保证 Primary Postgres 和 Replica Postgres 之间的数据同步, 以及数据的备份.
数据库的很多操作是阻塞的, 这里成了 Status 的一部分, 包括对 StatefulSet 的操作和 StatefulSet Spec 的 Update. 同时还会记录最近一次创建的 StatefulSet 的索引, 和执行副本的数量.
// ----------------------- STATUS ----------------------------------------- // 用于描述 Kubegres StatefulSet 操作 type KubegresStatefulSetOperation struct { InstanceIndex int32 `json:"instanceIndex,omitempty"` Name string `json:"name,omitempty"` } // 用于描述 Kubegres StatefulSet Update 操作 type KubegresStatefulSetSpecUpdateOperation struct { SpecDifferences string `json:"specDifferences,omitempty"` } // 用于描述 Kubegress Blocking Operation, 阻塞操作 type KubegresBlockingOperation struct { OperationId string `json:"operationId,omitempty"` StepId string `json:"stepId,omitempty"` TimeOutEpocInSeconds int64 `json:"timeOutEpocInSeconds,omitempty"` HasTimedOut bool `json:"hasTimedOut,omitempty"` // Custom operation fields StatefulSetOperation KubegresStatefulSetOperation `json:"statefulSetOperation,omitempty"` StatefulSetSpecUpdateOperation KubegresStatefulSetSpecUpdateOperation `json:"statefulSetSpecUpdateOperation,omitempty"` } // KubegressStatus 定义 Kubegres 观察到的状态 type KubegresStatus struct { LastCreatedInstanceIndex int32 `json:"lastCreatedInstanceIndex,omitempty"` BlockingOperation KubegresBlockingOperation `json:"blockingOperation,omitempty"` PreviousBlockingOperation KubegresBlockingOperation `json:"previousBlockingOperation,omitempty"` EnforcedReplicas int32 `json:"enforcedReplicas,omitempty"` }
Kubegres 和 KubegresList
略.
Controller
简单过了一下 Kubegres 会关注哪些点, 正式开始 Controller 的逻辑部分, 先看一下 controllers 文件夹.
├── ctx
│ ├── log
│ ├── resources
│ └── status
├── kubegres_controller.go
├── operation
│ └── log
├── spec
│ ├── checker
│ ├── defaultspec
│ ├── enforcer
│ │ ├── comparator
│ │ ├── resources_count_spec
│ │ └── statefulset_spec
│ └── template
│ └── yaml
└── states
├── log
└── statefulset
文件夹分为五个部分, 最熟悉 kubegres_controller.go 作为主调用者, ctx 提供 Kubegres Context, 方便进行各种操作, spec 中是调谐的主要实现, 要注意的是 states 不是 Status, states 获取的当前状态是 spec 进行调谐的依据, Status 只是一种获取到的中间状态, 最后是阻塞操作.
kubegres_controller.go
import ( ... ctx2 "reactive-tech.io/kubegres/controllers/ctx" "reactive-tech.io/kubegres/controllers/ctx/resources" ... ) // KubegresReconciler reconciles a Kubegres object type KubegresReconciler struct { client.Client Logger logr.Logger Scheme *runtime.Scheme // EventRecorder knows how to record events on behalf of an EventSource. Recorder record.EventRecorder }
可以看出主要的逻辑都在 ctx2 里面实现, Reconciler 内增加了 Logger 和 EventRecorder.
//+kubebuilder:rbac:groups=kubegres.reactive-tech.io,resources=kubegres,verbs=get;list;watch;create;update;patch;delete //+kubebuilder:rbac:groups=kubegres.reactive-tech.io,resources=kubegres/status,verbs=get;update;patch //+kubebuilder:rbac:groups=kubegres.reactive-tech.io,resources=kubegres/finalizers,verbs=update // +kubebuilder:rbac:groups="",resources=events,verbs=get;list;watch;create;update;patch;delete // +kubebuilder:rbac:groups="",resources=pods,verbs=get;list;watch;create;update;patch;delete // +kubebuilder:rbac:groups="",resources=configmaps,verbs=get;list;watch;create;update;patch;delete // +kubebuilder:rbac:groups="",resources=services,verbs=get;list;watch;create;update;patch;delete // +kubebuilder:rbac:groups="",resources=persistentvolumeclaims,verbs=get;list;watch;create;update;patch;delete // +kubebuilder:rbac:groups="apps",resources=statefulsets,verbs=get;list;watch;create;update;patch;delete // +kubebuilder:rbac:groups="batch",resources=cronjobs,verbs=get;list;watch;create;update;patch;delete // +kubebuilder:rbac:groups="storage.k8s.io",resources=storageclasses,verbs=get;list;watch
除了 kubegres 自身的权限, 对 events, pods, configmaps, services, pvc, statefulsets, cronjobs, storageclasses 都要了权限, groups="" 说明是 cluster 范围的权限, 这么大的资源创建的时候就必须要增加索引, 否则节点增加后, 过滤的时候会严重降低效率.
// Reconcile 是 Kubernetes 调谐主循环的一部分, 致力于将集群的当前状态推向期望状态. func (r *KubegresReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { ... // 拿到已经部署的 Kubegres Resource kubegres, err := r.getDeployedKubegresResource(ctx, req) if err != nil { r.Logger.Info("Kubegres resource does not exist") return ctrl.Result{}, nil } // 创建 ResourceContext, 更新 State resourcesContext, err := resources.CreateResourcesContext(kubegres, ctx, r.Logger, r.Client, r.Recorder) if err != nil { return ctrl.Result{}, err } // 阻塞操作超时前剩余时间 nbreSecondsLeftBeforeTimeOut := resourcesContext.BlockingOperation.LoadActiveOperation() resourcesContext.BlockingOperationLogger.Log() resourcesContext.ResourcesStatesLogger.Log() // 这里需要 Requeue, 在 nbreSecondsLeftBeforeTimeOut 重新调用 Reconciler if nbreSecondsLeftBeforeTimeOut > 0 { resultWithRequeue := ctrl.Result{ Requeue: true, RequeueAfter: time.Duration(nbreSecondsLeftBeforeTimeOut) * time.Second, } return r.returnn(resultWithRequeue, nil, resourcesContext) } // 检查 Spec 设置 specCheckResult, err := resourcesContext.SpecChecker.CheckSpec() if err != nil { return r.returnn(ctrl.Result{}, err, resourcesContext) // 发生了致命错误 } else if specCheckResult.HasSpecFatalError { return r.returnn(ctrl.Result{}, nil, resourcesContext) } // Reconcile 调用结束, 是否终止要看是否有其他错误 return r.returnn(ctrl.Result{}, r.enforceSpec(resourcesContext), resourcesContext) }
获取已部署的 Kubegres, 创建 Kubegres Context, 加载当前活跃的阻塞操作, 如果还未到超时时间则等到超时时间再次调用 Reconcile, 然后检查 Spec 设置, 最后根据当前 State 与 Spec 的差别, 并执行调谐, 这就是 Reconcile() 的逻辑.
func (r *KubegresReconciler) returnn(result ctrl.Result, err error, resourcesContext *resources.ResourcesContext) (ctrl.Result, error) { errStatusUpt := resourcesContext.KubegresContext.Status.UpdateStatusIfChanged() if errStatusUpt != nil && err == nil { return result, errStatusUpt } return result, err }
returnn() 内部还会调用 Update, 这里要强调, Update 前必须 Get 以获取最新的 Resource, 否则 Update 会失败会重新出发 Requeue, Patch 就不会有这个问题.
func (r *KubegresReconciler) getDeployedKubegresResource(ctx context.Context, req ctrl.Request) (*kubegresv1.Kubegres, error) { // 这里睡眠 1 秒确保 Kubernetes 完成了更新 // 这样可以确保 Get 拿到的是最新的 Kubegres resource time.Sleep(1 * time.Second) kubegres := &kubegresv1.Kubegres{} err := r.Client.Get(ctx, req.NamespacedName, kubegres) if err == nil { return kubegres, nil } r.Logger.Info("Kubegres resource does not exist") return &kubegresv1.Kubegres{}, err }
这里在 Get 前额外睡了一秒, 以保证可以拿到最新的 Kubegres, Kubernetes 可能会有延迟, 不过这种操作第一次见到.
func (r *KubegresReconciler) enforceSpec(resourcesContext *resources.ResourcesContext) error { err := r.enforceResourcesCountSpec(resourcesContext) if err != nil { return err } return r.enforceAllStatefulSetsSpec(resourcesContext) } func (r *KubegresReconciler) enforceResourcesCountSpec(resourcesContext *resources.ResourcesContext) error { return resourcesContext.ResourcesCountSpecEnforcer.EnforceSpec() } func (r *KubegresReconciler) enforceAllStatefulSetsSpec(resourcesContext *resources.ResourcesContext) error { return resourcesContext.AllStatefulSetsSpecEnforcer.EnforceSpec() }
执行 Spec 相关操作, 分了两部分, 一部分是各种 Resource 的计数, 另一部分就是所有的 StatefulSets.
func (r *KubegresReconciler) SetupWithManager(mgr ctrl.Manager) error { ctx := context.Background() // 这里是创建 OwnerKey 的索引 err := ctx2.CreateOwnerKeyIndexation(mgr, ctx) if err != nil { return err } return ctrl.NewControllerManagedBy(mgr). // For(&kubegresv1.Kubegres{}) specifies the Kubegres type as the primary resource to watch. For each Kubegres type Add/Update/Delete event the // reconcile loop will be sent a reconcile Request (a namespace/name key) for that Kubegres object. For(&kubegresv1.Kubegres{}). // Owns(&appsv1.StatefulSet{}) specifies the StatefulSet type as the secondary resource to watch. For each StatefulSet type Add/Update/Delete event, // the event handler will map each event to a reconcile Request for the owner of the StatefulSet. Which in this case is the StatefulSet object for which the StatefulSet was created. Owns(&apps.StatefulSet{}). Owns(&core.Service{}). Complete(r) }
如上面所说, CreateOwnerKeyIndexIndexation() 用于对属于 Kubegres 的资源创建索引, 查看其实现:
func CreateOwnerKeyIndexation(mgr ctrl.Manager, ctx context.Context) error { ... if err := mgr.GetFieldIndexer().IndexField(ctx, &apps.StatefulSet{}, DeploymentOwnerKey, func(rawObj client.Object) []string { depl := rawObj.(*apps.StatefulSet) owner := metav1.GetControllerOf(depl) ... return []string{owner.Name} }); err != nil { return err } ... if err := mgr.GetFieldIndexer().IndexField(ctx, &core.Service{}, DeploymentOwnerKey, func(rawObj client.Object) []string { ... if err := mgr.GetFieldIndexer().IndexField(ctx, &core.ConfigMap{}, DeploymentOwnerKey, func(rawObj client.Object) []string { ... if err := mgr.GetFieldIndexer().IndexField(ctx, &core.Pod{}, DeploymentOwnerKey, func(rawObj client.Object) []string { }
也就是说, 对于所有归属于 Kubegres 的 StatefulSet, Service, ConfigMap, Pod 都会创建一个 ".metadata.controller" = []string{owner.Name} 的索引, 在 LIST 的时候会用到.
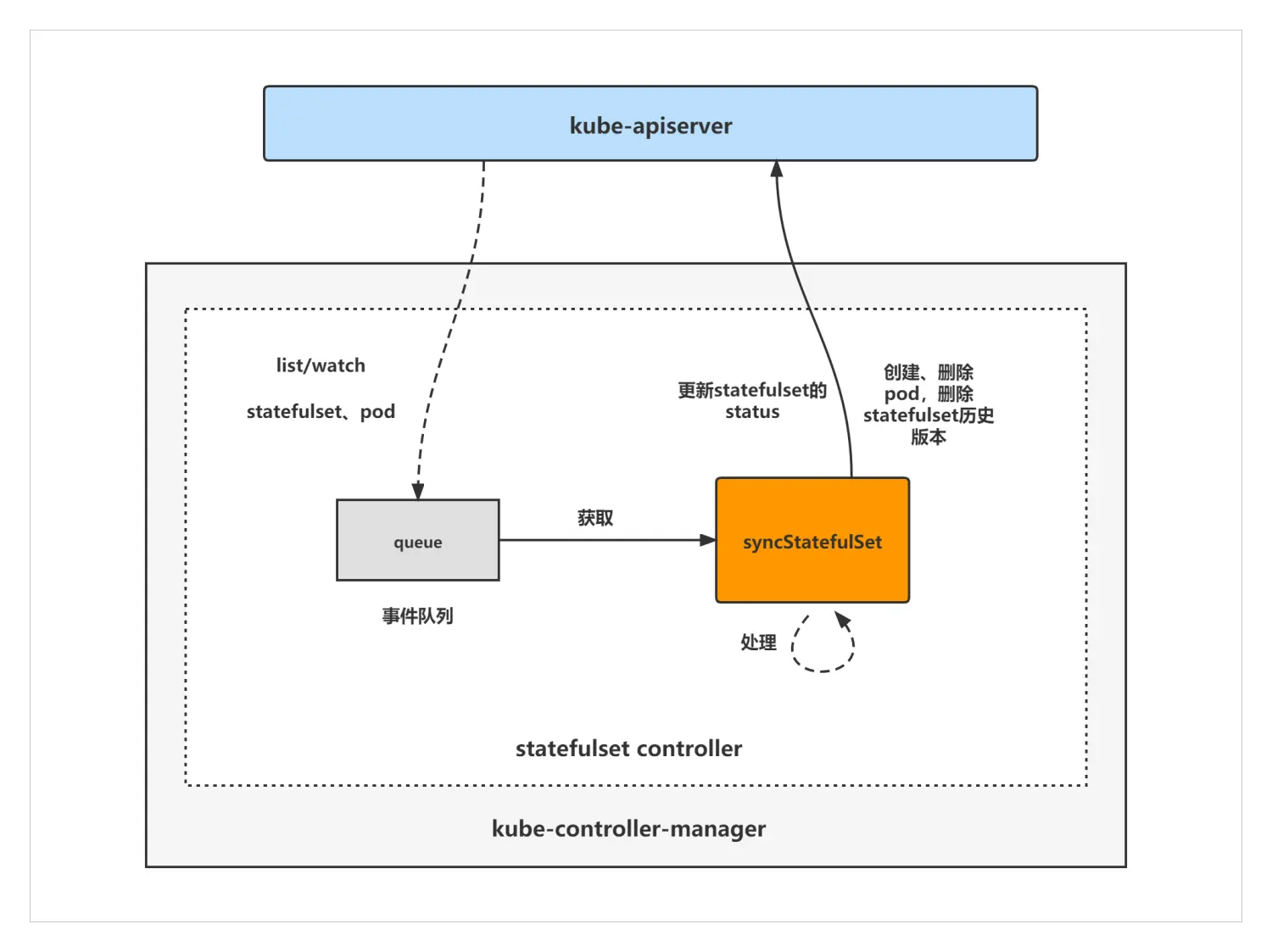
GetControllerOf 也很有意思, 要注意的是, 属主不一定有 Controller, 所以要进行判断. 举个例子, 假设 Pod 的属主是 StatefulSet, 而 StatefulSet 是有 Controller的, 且属于 kube-controller-manager 中众多控制器的一个, 这里再贴一张图. StatefulSet Controller 通过对 StatefulSet, Pod 等资源的 Watch, 当资源发生变化时就会触发 Controller 对相应的 StatefulSet 资源进行调谐, 涉及 pod 创建, 删除, 更新, 扩容缩容, StatefulSet 的滚动更新, status 更新, 旧版本 StatefulSet 清理等.
func GetControllerOf(controllee Object) *OwnerReference { ref := GetControllerOfNoCopy(controllee) if ref == nil { return nil } cp := *ref return &cp } // GetControllerOf returns a pointer to the controllerRef if controllee has a controller func GetControllerOfNoCopy(controllee Object) *OwnerReference { refs := controllee.GetOwnerReferences() for i := range refs { if refs[i].Controller != nil && *refs[i].Controller { return &refs[i] } } return nil }
最后再解释一下 ctrl.NewControllerManagedBy().For() 和 ctrl.NewControllerManagedBy().Owns().
For() 中的对象就是 Controller 所对应的 Kubegres, 而 Kubegres 通过创建 StatefulSet 实现部署, 与此同时, Service 因为涉及到读写分离, 也会对集群造成影响, 所以 Owns 的对象有两个.
至此, kubegres_controller.go 的分析结束, 进入到 resources.CreateResourceContext().
CreateResourceContext
func CreateResourcesContext(kubegres *postgresV1.Kubegres, ctx context.Context, logger logr.Logger, client client.Client, recorder record.EventRecorder) (rc *ResourcesContext, err error) { setReplicaFieldToZeroIfNil(kubegres) rc = &ResourcesContext{} rc.LogWrapper = log.LogWrapper{Kubegres: kubegres, Logger: logger, Recorder: recorder} // 此时我们刚拿到 Kubegres, 当前的 Status 是上一次更新的. rc.LogWrapper.Info("KUBEGRES", "name", kubegres.Name, "Status", kubegres.Status) //rc.LogWrapper.WithName(kubegres.Name) rc.KubegresStatusWrapper = &status.KubegresStatusWrapper{ Kubegres: kubegres, Ctx: ctx, Log: rc.LogWrapper, Client: client, } rc.KubegresContext = ctx2.KubegresContext{ Kubegres: kubegres, Status: rc.KubegresStatusWrapper, Ctx: ctx, Log: rc.LogWrapper, Client: client, }
ResourcesContext 包装了 Kubegres 的所有 Resource, 这里进行各项的填充.
rc.DefaultStorageClass = defaultspec.CreateDefaultStorageClass(rc.KubegresContext) if err = defaultspec.SetDefaultForUndefinedSpecValues(rc.KubegresContext, rc.DefaultStorageClass); err != nil { return nil, err }
创建默认的 Storageclass, 并用 KubegresContext 和 Storageclass 来为其他未指定值的 Spec Values 设定默认值.
func SetDefaultForUndefinedSpecValues(kubegresContext ctx.KubegresContext, defaultStorageClass DefaultStorageClass) error { defaultSpec := UndefinedSpecValuesChecker{ kubegresContext: kubegresContext, defaultStorageClass: defaultStorageClass, } return defaultSpec.apply() } func (r *UndefinedSpecValuesChecker) apply() error { wasSpecChanged := false kubegresSpec := &r.kubegresContext.Kubegres.Spec const emptyStr = "" if kubegresSpec.Port <= 0 { ... if kubegresSpec.Database.VolumeMount == emptyStr { ... if kubegresSpec.CustomConfig == emptyStr { ... if r.isStorageClassNameUndefinedInSpec() { wasSpecChanged = true defaultStorageClassName, err := r.defaultStorageClass.GetDefaultStorageClassName() if err != nil { return err } kubegresSpec.Database.StorageClassName = &defaultStorageClassName r.createLog("spec.Database.StorageClassName", defaultStorageClassName) } if kubegresSpec.Scheduler.Affinity == nil { kubegresSpec.Scheduler.Affinity = r.createDefaultAffinity() wasSpecChanged = true r.createLog("spec.Affinity", kubegresSpec.Scheduler.Affinity.String()) } if wasSpecChanged { return r.updateSpec() } return nil }
GetDefaultStorageclassName() 记录了选择默认 StorageClass 的过程.
func (r *DefaultStorageClass) GetDefaultStorageClassName() (string, error) { // 先拿到本集群的 StorageclassList list := &storage.StorageClassList{} err := r.kubegresContext.Client.List(r.kubegresContext.Ctx, list) // Annotation 中 "storageclass.kubernetes.io/is-default-class" = "true" 的就是本集群默认的 Storageclass for _, storageClass := range list.Items { if storageClass.Annotations["storageclass.kubernetes.io/is-default-class"] == "true" { return storageClass.Name, nil } }
createDefaultAffinity() 则提供了默认的带权重的 pod Affinity 规则, 规则表明, Pod 不希望跟任何携带了 app=Kubegres 的 Label 的 Pod 存在于同一个节点上, 即实现 Postgres 实例分散部署. 注意最后返回的是 PodAntiAffinity.
Weight 的取值范围是 1 - 100, 当调度器能够找到满足 Pod 的其他调度请求的节点时, 调度器会遍历节点满足的所有偏好性规则, 并将对应表达式的 weight 值相加. 最终的相加值会添加到该节点的其他优先级函数的评分之上. 在调度器为 Pod 做出调度决定时, 总分最高的节点的优先级也最高.
这里 Weight 直接拉满到 100, 意思是尽可能去满足 Postgres 实例部署到不同的节点上.
func (r *UndefinedSpecValuesChecker) createDefaultAffinity() *core.Affinity { resourceName := r.kubegresContext.Kubegres.Name // 带权重的 PodAffinityTerm weightedPodAffinityTerm := core.WeightedPodAffinityTerm{ Weight: 100, PodAffinityTerm: core.PodAffinityTerm{ LabelSelector: &metav1.LabelSelector{ MatchExpressions: []metav1.LabelSelectorRequirement{ { Key: "app", Operator: metav1.LabelSelectorOpIn, Values: []string{resourceName}, }, }, }, TopologyKey: "kubernetes.io/hostname", }, } return &core.Affinity{ PodAntiAffinity: &core.PodAntiAffinity{ PreferredDuringSchedulingIgnoredDuringExecution: []core.WeightedPodAffinityTerm{weightedPodAffinityTerm}, }, } }
这里补充一点, Affinity 相关操作由 PodAffinityPredicate 进行, 它是有作用域的, 就是仅对携带了 Key 是 "Kubernetes.io/hostname" label 的节点有效, 注意这是个 labelSelector.
调度有两个阶段, Predicate 和 Priority, 看命名, Affinity 的相关过滤是强条件, 必须要满足, 一个猜测.
最后进行判断, 如果在这一步 Spec 发生了修改, 则进行 Update, 可以认为这里的操作是对 Spec 进行默认值的填充. 有那么点 Mutating Webhook 的 Defaulter 操作的意思了.
if wasSpecChanged { return r.updateSpec() } return nil
至此, 对于 Spec 默认值的填充完成, 创建 ResourceContext 的剩余逻辑下一篇继续.