1.集成学习的概念
集成学习是一种机器学习范式,在这种范式中,多个学习者被训练和组合起来一起解决同一个问题。通过使用多个学习者,就可以把整个模型的泛化能力提高很多倍
所以说,集成学习的泛化能力比单个学习者强得多得多,所以叫:“集思广益”。
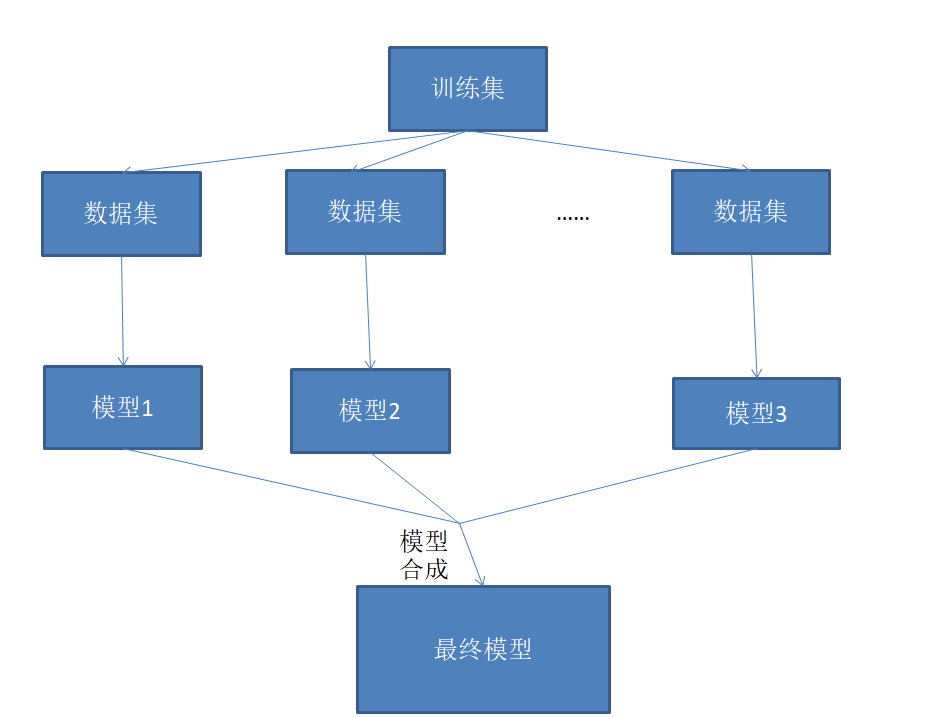
2.集成学习的具体流程
- 一个问题出来,数据集丢给若干模型进行训练,训练出若干模型
- 所有模型汇总合成得到最好的一个模型
- 这个模型就是集成学习训练所得结果
3.集成学习分类
| 分类 | Bagging | Boosting |
|---|---|---|
| 方法 | 独立构建若干基本学习器 | 按顺序方式构建基本学习器 |
| 如何汇总模型 | 平均学习器的预测 | 一次预测一次拾取,每一次减少综合学习偏差 |
| 效果 | 方差减少了,平均下来效果通常比任何单基学习者更好 | 综合学习器具有很强拟合数据能力 |
| 典型算法 | 随机森林 | GBDT,Adaboost |
4.典型算法——随机森林
随机森林=Bagging+CART决策树
核心就是:构建多个决策树,平均他们的预测
如下图:
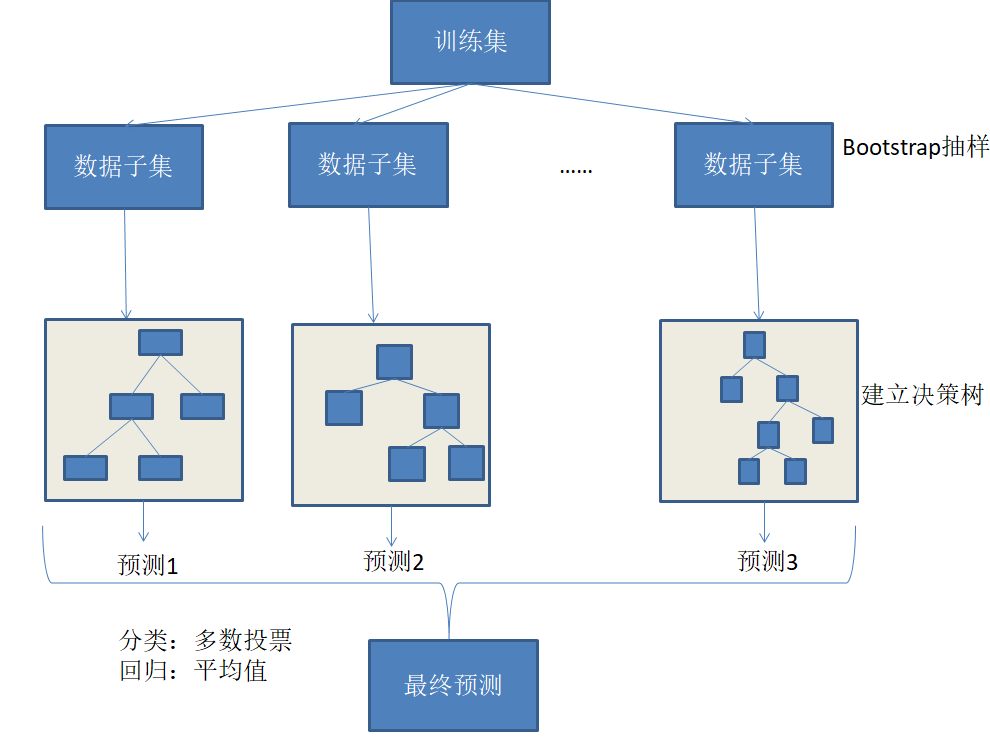
对每一个决策树都进行每一次所用来构建决策数的对应的数据子集进行预测,最终所有的预测结果进行相应的问题来做相应的操作:
- 分类问题就对所有预测进行投票表决,票数最多的预测作为最终预测,即最终归为的那一类
- 回归问题即取所有预测平均值作为最终结果
5.典型算法——GBDT
GBDT属于Boosting算法的一种
综合模型的结果就是所有学习器结果相加等于预测值,本质:下一个基础学习器去拟合误差函数对预测值的残差(此残差即预测值与真实值间的误差)
GBDT训练模型时,要求模型预测样本损失尽量小最好
看个例子:
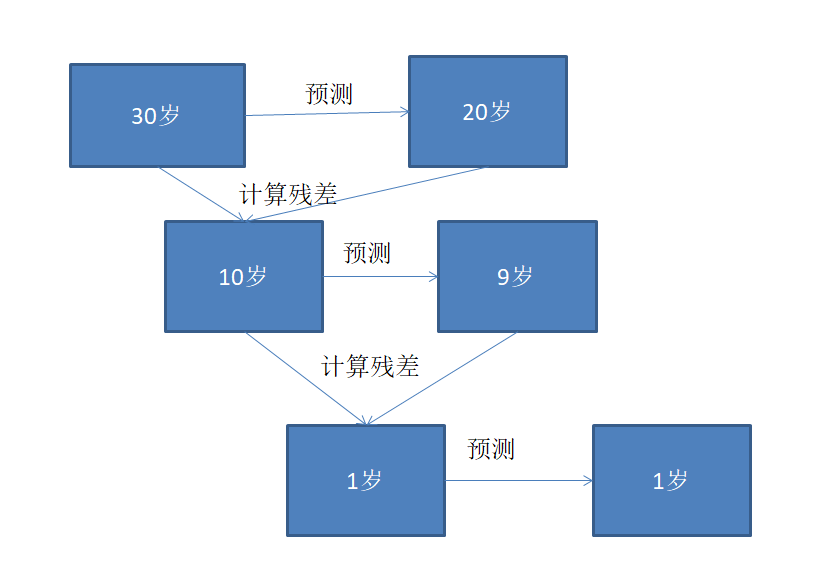
如上图:
- 要预测一个30岁的人,我们第一次预测20岁,显然差的很多,然后进行残差计算为10,对残差拟合-->预测出来为9岁;
- 以此类推,残差=1岁,再对1岁预测-->1岁,无法继续往下了(预测正确);
- 对右边三个预测结果加起来:20+9+1=30岁,这就跟我们放入的数据一样;
总的来说:对右边直到第一次预测成功(与上一次残差相等时)的数据从下往上求和所有预测结果,其和就是我们的真实数据。
5.最后,总结
- 集成学习就是让一个训练集划分若干数据子集训练出多个模型,给多个模型进行预测,对预测结果取平均或最大最小等一系列操作,得到一个最终的预测值,简单地说即“集思广益”;
- 集成学习分类:Bagging,Boosting
- 随机森林:Bagging+决策树,核心思想:构建多个决策树,若是分类问题就进行预测结果的投票取最高票数的预测值,即所归之类,若是回归问题就进行所有预测结果取平均值;
- GBDT,核心思想:对残差拟合,直到残差预测正确,从下往上求和所有的预测值,所有预测值之和就是真实数据的值。