本实验基于MRS环境,主要介绍如何利用Spark RDD的常用算子进行简单统计分析,以及如何利用SparkSQL进行结构化批处理。
购买弹性公网IP
购买MRS集群
选择“自定义购买”
区域:华北—北京四
计费模式:按需计费
集群名称:mrs-bigdata
版本类型:普通版
集群版本:MRS 3.1.0 WXL
集群类型:自定义
勾选组件:Hadoop/Spark2x/HBase/Hive
可用区:任意均可
虚拟私有云:vpc-bigdata
子网:subnet-bigdata
安全组:sg-bigdata
弹性公网IP:选择下拉框中已购买的ip
常用模板:默认选项
开启“拓扑调整”,勾选如下图位置所示的“DN, NM, RS”。此操作表示在Master3节点分别部署DataNode, NodeManager, RegionServer以解决如上警告。
安装jdk环境
wget https://sandbox-expriment-files.obs.cn-north-1.myhuaweicloud.com/hccdp/HCCDP/jdk-8u341-linux-x64.tar.gz下载完成后,运行下列命令进行解压:
tar -zxvf jdk-8u341-linux-x64.tar.gz
下载解压Maven环境
wget https://sandbox-expriment-files.obs.cn-north-1.myhuaweicloud.com/hccdp/HCCDP/apache-maven-3.6.0.tar.gz利用如下命令进行解压:
tar -zxvf apache-maven-3.6.0.tar.gz
安装Scala环境
Spark编程推荐使用Scala,语法简洁,且更符合Spark Core运行逻辑。在xfce命令行运行下列代码下载Scala压缩文件,直接下载到/home/user目录下即可,方便查找。
wget https://sandbox-expriment-files.obs.cn-north-1.myhuaweicloud.com/hccdp/HCCDP/scala-2.11.8.tgz
下载完成后,运行下列命令进行解压:
tar -zxf scala-2.11.8.tgz
解压成功后,修改配置文件。使用如下命令进入配置文件编辑界面
vim ~/.bashrc
export JAVA_HOME=/home/user/jdk1.8.0_341
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export SCALA_HOME=/home/user/scala-2.11.8
export PATH=${JAVA_HOME}/bin:${SCALA_HOME}/bin:$PATH
激活修改后的环境:
source ~/.bashrc利用如下命令查看是否安装成功:
java -version
scala -version
安装IDEA
打开xfce命令行,利用下列命令下载IDEA:
wget https://sandbox-expriment-files.obs.cn-north-1.myhuaweicloud.com/hccdp/ideaIC.tar.gz
下载完成后,利用如下命令进行解压:
tar -zxvf ideaIC.tar.gz
解压完成后,利用下列命令安装idea:
/home/user/idea-IC/bin/idea.sh
修改Maven配置
等待安装完毕,出现IDEA界面,在界面左侧找到Customize标签,点击该标签。

在Customize窗口下找到All settings,点击弹出配置窗口。
在新窗口左侧找到“Build, Execution, Deployment”,展开该标签,选择“Build Tools”-“Maven”标签进入如下界面。

直接编辑“Maven home path”,修改为如下路径:
/home/user/apache-maven-3.6.0
修改“User settings file”为相关配置路径(记得点选右侧的Override):
/home/user/apache-maven-3.6.0/conf/setting.xml
确认无误后点击OK即可。
安装Scala插件
在IDEA初始界面找到Plugins标签,单击打开
选择Marketplace,在搜索框中输入scala,完成scala插件安装。
安装scala插件后,点击绿色的Restart IDE重启IntelliJ IDEA。
点击New Project,如果在Language标签下显示Scala,表示已成功安装。
Spark是个轻量级的组件,底层用Scala实现,充分利用Scala语言的简洁和丰富表达力。同时巧妙利用了Hadoop的基础设施。Spark计算过程的中间数据放在内存中,对于迭代运算、批处理计算的效率更高,延迟更低性能上提升高于Mapreduce100倍(全内存计算)。Spark对小数据集可达到亚秒级的延迟。允许扩展新的数据算子、新的数据源。
Spark核心概念是RDD,RDD是Spark对基础数据的抽象。本任务通过介绍Spark RDD的相关Scala API编程,针对部分客户收入和支出情况数据进行统计分析,以便掌握Spark Core的运行原理与核心机制。
新建Scala Maven工程
点击”New Project” 按钮,新建一个项目。此时记得勾选Maven Archetype。

按如下配置项目信息:
① Name:SparkRDD
② Location:~/IdeaProjects
③ JDK:下拉,找到最下方的 ~/jdk1.8.0_341
④ Catalog:Internal
⑤ Archetype:org.scala-tools.archetypes:scala-archetype-simple (可以手动输入scala单词,方便筛选)
⑥ Version:1.2
⑦ Advanced Settings:
⑧ GroupId:com.huawei
⑨ ArtifactId:SparkRDD
⑩ Version:1.0-SNAPSHOT
确认无误后点击Create。
此时系统会自动从华为云中央仓库拉取所需的依赖。此步骤所耗时间较长,预计需耐心等待约5分钟。
项目架构安装完毕后,会看到下方出现以下信息。此时可以进行下一步操作。

配置POM文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.com.hw</groupId>
<artifactId>SPARKRDD</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11.8</scala.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.1</version>
</dependency>
<dependency>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.11</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
复制粘贴后会自动下载依赖,此时会占用大量内存。下载依赖需要一定时间,预计约需10分钟左右。
如果POM文件中有标红报错的行,请展开右侧Maven标签,在该标签中有“刷新”按钮,点击即可继续下载:

等到POM文件中所有标红的错误均已消失,此时表示依赖已安装完毕。
(注:如果此时发生闪退,请再次于xfce命令行执行下列命令:
/home/user/idea-IC-221.5921.22/bin/idea.sh如果闪退后重新进入IDEA界面,出现SparkRDD工程不存在的情况,可以点击左上角的File,然后点击Open,选到~/IdeaProjects目录下的SparkRDD文件夹,然后Trust 该工程,点击This Window,即可继续下载依赖了。)
编写RDD业务代码
依赖安装完毕后,左侧能看到src文件夹,一直展开该文件夹下所有子目录,可以看到如下结构:

接下来需要在com.huawei文件夹下新建一个名为RDD的Scala Object. 右键点击com.huawei,选择New>Scala Class.
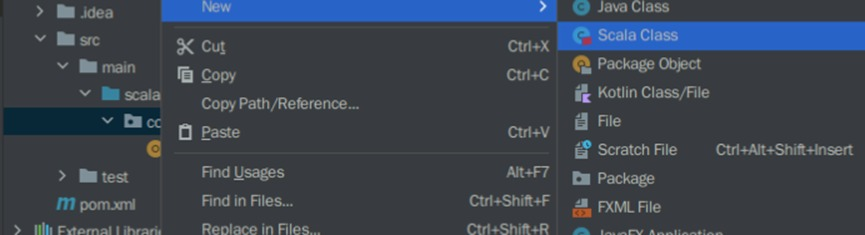
在新界面中选择下方黄色的Object选项,并填入名称为RDD。回车即可创建成功。
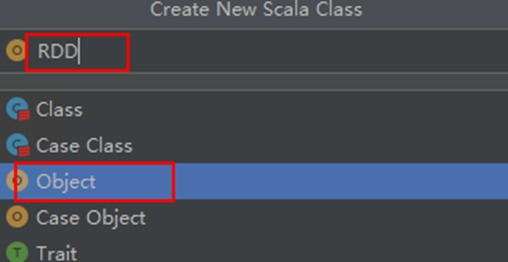
打开新建的RDD文件,编辑代码如下
package com.huawei
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object RDD {
def main (args: Array[String]) {
// 设置Spark application的名称
val conf = new SparkConf().setAppName("CollectOutInfo")
// 初始化Spark,设置日志级别为警告
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
// 读取指定的目录或文件,由参数指定
val text = sc.textFile(args(0))
// val text = rdd1
// 过滤出支出的项目
val data = text.filter(_.contains("out"))
// 统计每个人的支出总和
val result:RDD[(String,Int)] = data.map(line =>{
val t= line.split(',')
(t(0),t(2).toInt)
}).reduceByKey(_ + _)
println("支出的结果统计为:")
result.collect().map(x => x._1 + ',' + x._2).foreach(println)
sc.stop()
}
}
然后将系统自带的名为App的Scala Object删除。
右键点击App,选择Delete
同样的方法,将test文件夹整个删除。
Maven打包并上传
打开编译器右上角的maven 标签,在Lifecycle下面找到package,双击package,此时编译器下面会开始进行build。
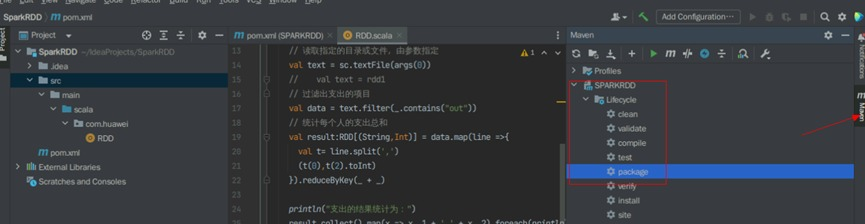
打包时同样会下载补充依赖文件,预计需等待约2分钟。
package结束后会出现BUILD SUCCESS,此时我们就可以在相应的目录下查看jar包。
打开桌面上的xfce终端,利用以下命令进入安装目录:
cd ~/IdeaProjects/SparkRDD/target/scp ~/IdeaProjects/SparkRDD/target/SPARKRDD-1.0-SNAPSHOT.jar root@xxx.xxx.xxx.xxx:/root运行并验证
使用ssh命令远程登录到MRS集群中。
将该jar包上传到HDFS上,路径为/tmp/
hdfs dfs -put SPARKRDD-1.0-SNAPSHOT.jar /tmp/
利用Vim编辑器,在本地编辑一个文件。输入以下命令:
vim data.txt
按ecs退出编辑模式,然后输入“ :wq ”(不包含引号,但需包含冒号),回车即可退出vim编辑器环境,回到Linux环境。
使用如下命令创建HDFS路径,并上传文件到对应路径中
hdfs dfs -mkdir /tmp/test/
hdfs dfs -put data.txt /tmp/test/
hdfs dfs -ls /tmp/test/
使用yarn-client模式提交任务,将结果直接打印在控制台:
spark-submit --class com.huawei.RDD --master yarn-client SPARKRDD-1.0-SNAPSHOT.jar /tmp/test/data.txtSpark SQL是Spark中用于结构化数据处理的模块。在Spark应用中,可以无缝的使用SQL语句亦或是DataFrame API对结构化数据进行查询。
DataFrame提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame提供了数据的结构信息,即schema。Spark SQL将SQL语言解析成RDD,再由Spark Core执行。在spark2.0版本之前,Spark SQL中SQLContext是创建DataFrame和执行SQL的入口,可以利用hiveContext通过hive sql语句操作hive表数据,兼容hive操作,并且hiveContext继承自SQLContext。
本任务通过介绍Spark SQL的相关编程,帮助大家掌握如何利用DataFrame的Java 及Scala API完成相关业务的开发与应用。
新建Scala Maven工程
点击”New Project” 按钮,新建一个项目。记得勾选Maven Archetype。
按如下配置项目信息:
① Name:SparkSQL
② Location:~/IdeaProjects
③ JDK:1.8
④ Catalog:Internel
⑤ Archetype:org.scala-tools.archetypes:scala-archetype-simple
⑥ Version:1.2
⑦ Advanced Settings:
⑧ GroupId:com.huawei
⑨ ArtifactId:SparkSQL
⑩ Version:1.0-SNAPSHOT
确认无误后点击Create。
如果弹出以下窗口,选择This Window,可以节约内存空间:
配置POM文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.com.hw</groupId>
<artifactId>SparkSQL</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11.8</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.1</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
生成随机数据
在com.huawei文件夹下新建一个名为SamplePeopleInfo的Java类。

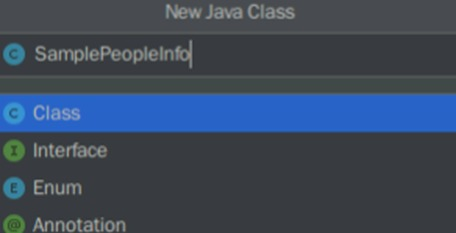
package com.huawei;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Random;
/**
* args[0] : 文件路径
* args[1] : 生成数据量条数
*/
class dataProducer {
public static void main(String[] args) {
String filePath = "/home/user/SparkSQLData.txt";
int peopleNum = 1000; //测试数据量1000条
File file = new File(filePath);
FileWriter fw = null;
BufferedWriter writer = null;
Random rand = new Random();
int age = 0;
int se = 0;
String sex = null;
try {
fw = new FileWriter(file);
writer = new BufferedWriter(fw);
for(int i = 1;i<= peopleNum ;i++){
//通过随机数生成年龄、性别数据
age = rand.nextInt(100)+120;
se = rand.nextInt(2);
if(se!=0){
sex = "F";
}else {
sex = "M";
}
writer.write(i+","+sex+","+age);
writer.newLine(); //换行
writer.flush();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
writer.close();
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
编辑好后,按照之前类似的方法,删除App对象和test文件夹:
在代码编辑窗口点击鼠标右键,选择Run 'dataProducer.main()'
看到有如下信息输出:
此时打开xcfe窗口,使用如下命令,即可看到SparkSQLData.txt文件。
编写SparkSQL业务代码
在com.huawei文件夹下新建一个名为DataStatistics的Scala Object。

package com.huawei
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
/**
* args(0) : HDFS数据文件地址
*/
object DataStatistics {
private val schemaString = "id,gender,height"
def main(args: Array[String]): Unit = {
if (args.length < 1) {
//未输入数据源路径参数,则报错退出
println("Usage:dataStatistics filePath")
System.exit(1)
}
//配置工程
val conf = new SparkConf().setAppName("dataStatistics")
val sc = new SparkContext(conf)
//屏蔽警告等级以下的信息
sc.setLogLevel("WARN")
//读取数据源路径
val peopleDateRdd = sc.textFile(args(0).trim);
val sqlCtx = new SQLContext(sc)
val schemaArr = schemaString.split(",")
//设置数据源的schema信息
val schema = StructType(schemaArr.map(fieldName => StructField(fieldName,StringType,true)))
//读取数据并转化为特定DataFrame格式
val rowRdd : RDD[Row] = peopleDateRdd
.map(_.split(","))
.map(eachRow => Row(eachRow(0),eachRow(1),eachRow(2)))
val peopleDF = sqlCtx.createDataFrame(rowRdd,schema)
//将数据源缓存在内存中,会根据数据量节省很多时间
peopleDF.persist(StorageLevel.MEMORY_ONLY_SER)
peopleDF.createOrReplaceTempView("people")
//获取男性身高超过180cm的数据
val higherMale180 = sqlCtx.sql("select * from people where height > 180 and gender = 'M'")
println("Men whose height are more than 180: " + higherMale180.count())
//获取男性身高超过210cm的数据,只显示前10条
println("Men whose height is more than 210")
peopleDF.filter(peopleDF("gender").equalTo("M")).filter(peopleDF("height") > 210).show(10)
//将身高由高到低排序,获取前10人的数据
println("Sorted the people by height in descend order,Show top 10 people")
peopleDF.sort(peopleDF("height").desc).take(10).foreach { println }
//获取男性平均身高
println("The Average height for Men")
peopleDF.filter(peopleDF("gender").equalTo("M")).agg(Map("height" -> "avg")).show()
//获取女性最高身高
println("The Max height for Women:")
peopleDF.filter(peopleDF("gender").equalTo("F")).agg("height" -> "max").show()
println("All the statistics actions are finished on structured People data.")
}
}
Maven打包并上传
打开编译器右上角的maven project,在Lifecycle下面找到package,双击package,此时编译器下面会开始进行build。
package结束后会出现BUILD SUCCESS,此时我们就可以在相应的目录下查看jar包。
打开桌面上的xfce终端,利用以下命令进入安装目录:
cd ~/IdeaProjects/SparkSQL/target/
利用scp命令将SPARKRDD-1.0-SNAPSHOT.jar和SparkSQLData.txt两份文件上传到MRS集群中(需分两步操作,不能一次复制两条):
scp ~/IdeaProjects/SparkSQL/target/SparkSQL-1.0-SNAPSHOT.jar root@xxx.xxx.xxx.xxx:/root
scp ~/SparkSQLData.txt root@xxx.xxx.xxx.xxx:/root
运行并验证
使用ssh命令远程登录到MRS集群中。同样在xfce终端中,输入以下命令:
ssh root@xxx.xxx.xxx.xxx
将jar包和数据文件上传到HDFS的/tmp/路径中:
hdfs dfs -put SparkSQL-1.0-SNAPSHOT.jar /tmp/
hdfs dfs -put SparkSQLData.txt /tmp/
使用yarn-client模式提交任务,将结果直接打印在控制台:
spark-submit --class com.huawei.DataStatistics --master yarn-client SparkSQL-1.0-SNAPSHOT.jar /tmp/SparkSQLData.txt