问题处理思路:
在讲解具体的问题前,我先来说一下使用正则处理问题的基本思路。有一些方法比较固定,比如将问题分解成多个小问题,每个小问题见招拆招:某个位置上可能有多个字符的话,就用字符组。某个位置上有多个字符串的话,就用多选结构。出现的次数不确定的话,就用量词。对出现的位置有要求的话,就用锚点锁定位置。
在正则中比较难的是某些字符不能出现,这个情况又可以进一步分成组中不能出现,和要查找的内容前后不能出现。后一种用环视来解决就可以了。我们主要说一下第一种。
如果是要查找的内容中不能出现某些字符,这种情况比较简单,可以通过使用中括号来排除字符组,比如非元音字母可以使用[^aeiou]来表示。
如果说内容中不能出现某个子串,比如要求密码是6位,且不能有连续两个数字出现。假设密码允许的范围是\w,你应该可以想到使用\w{6}来表示6位密码,但如果里面不能有连续两个数字的话,该如何限制呢?这个可以用环视来解决,就是每个字符的后面都不能是两个数字(要注意开头也不能是\d\d)。
常见问题及解决方案
1.匹配数字
-
- 数字的匹配比较简单,通过我们学习的字符组,量词等就可以轻松解决。
- 如果是连续的多个数字,可以使用\d+或[0-9]+
- 如果n位数据,可以使用\d
- 如果是至少n位数据,可以使用\d
- 如果是m-n数字,可以使用\d
2.匹配正数、负数和小数
如果希望正则能匹配到比如3,3.14,-3.3,+2.7等数字,需要注意的是,开头的正负符号可能有,也可能没有,所以可以使用[-+]?来表示,小数点和后面的内容也不一定会有,所以可以使用(?:.\d+)来表示,因此匹配正数、负数和小数的正则可以写成[-+]?\d+(?:.\d+)?
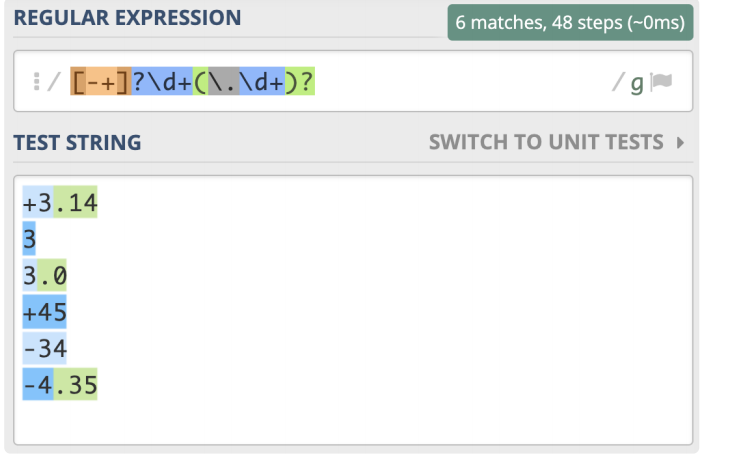
非负整数,包含0和正整数,可以表示成[1-9]\d*|0
非正整数,包含0和负整数,可以表示成-[1-9]\d*|0
3.浮点数
这个问题你可能觉得比较简单,其中表示正负的符号和小数点可能有,也可能没有,直接用[-+]?\d+(?:.\d+)?来表示
如果我们考虑.5和+.5这样的写法,但一版不会有-.5这样的写法。正则又如何写呢?
我们可以把问题拆解,浮点数分为符号位、整数部分、小数点和小数部分,这些部分都有可能不存在,如果我们每个部分都加个问号,这样整个表达式可以匹配上空。
根据上面的提示,负号的时候整数部分不能没有,而正数的时候,整数部分可以没有,所以正则你可以将正负两种情况拆开,使用多选结果写成 -?\d+(?:.\d+)?|+?(?:\d+
(?:.\d+)?|.\d+)
这个可以拆成两个问题:
负数浮点数表示:-\d+(?:.\d+)?
正数浮点数表示:+?(?:\d+(?:.\d+)?|.\d+)。
4.十六进制数
十六进制的数字除了有 0-9 之外,还会有 a-f(或 A-F) 代表 10 到 15 这 6 个数字,所以正则可以写成 [0-9A-Fa-f]+。
5.手机号码
手机号应该是比较常见的,手机号码比较复杂,如果要兼容所有的号段并不容易。目前来看,前四位是有一些限制,甚至1740和1741限制了前5位号段。
我们可以简单地使用字符组和多选分支,来准确地匹配手机号段。如果只限制前 2 位,可 以表示成 1[3-9]\d{9},如果想再精确些,限制到前三位,比如使用1(?:3\d|4[5-
9]|5[0-35-9]|6[2567]|7[0-8]|8\d|9[1389])\d{8}来表示。如果想精确到 4 位,甚至 5 位,可以根据公开的号段信息自己来写一下,但要注意的是,越是精确,只要 有新的号段,你就得改这个正则,维护起来会比较麻烦。另外,在实际运用的时候,你可能还要考虑一下有一些号码了 +86 或 0086 之类的前缀的情况。
手机号段的正则写起来其实写起来并不难,但麻烦的是后期的维护成本比较高,我之前就 遇到过这种情况,买了一个 188 的移动号码,有不少系统在这个号段开放了挺长时间之 后,还认为这个号段不合法。
6.身份证号码
我国的身份证号码是分两代的,第一代是 15 位,第二代是 18 位。如果是 18 位,最后一 位可以是 X(或 x),两代开头都不能是 0,根据规则,你应该能很容易写出相应的正则, 第一代可以用 [1-9]\d{14} 来表示,第二代比第一代多 3 位数据,可以使用量词 0 到 1 次,即写成 [1-9]\d{14}(\d\d[0-9Xx])?。
7.邮政编码
邮编一般为6位数字,首位不是0,比较简单,可以写成[1-9]\d{5},之前我们也提到过,6位数字在其它情况下出现可能性也非常大,比如手机号的一部分,身份证号的一部分,所以如果是数据提取,一般需要添加断言,即写成 (?<!\d)[1-9]\d{5}(?!\d)。
8.腾讯QQ号码
目前QQ号不能以0开头,最长的有10位,,最短的从 10000(5 位)开始。从规则上我
们可以得知,首位是 1-9,后面跟着是 4 到 9 位的数字,即可以使用 [1-9][0-9]{4,9} 来 表示。
9.中文字符
中文属于多字节 Unicode 字符,之前我们讲过比如通过 Unicode 属性,但有一些语言是不支持这种属性的,可以通过另外一个办法,就是码值的范围,中文的范围是 4E00 - 9FFF之间,这样可以覆盖日常使用大多数情况。
不同的语言是表示方式有一些差异,比如在 Python,Java,JavaScript 中,Unicode 可以写成 \u码值 来表示,即匹配中文的正则可以写成 [\u4E00-\u9FFF],如果在 PHP 中使用,Unicode 就需要写成 \u{码值} 的样式。下面是在 Python3 语言中测试的示例,你可以参考一下。
10.IPV4
IPv4 地址通常表示成 27.86.1.226 的样式,4 个数字用点隔开,每一位范围是 0-255,比如从日志中提取出 IP,如果不要求那么精确,一般使用 \d{1,3}(.\d{1,3}){3}就够了,需要注意点号需要转义。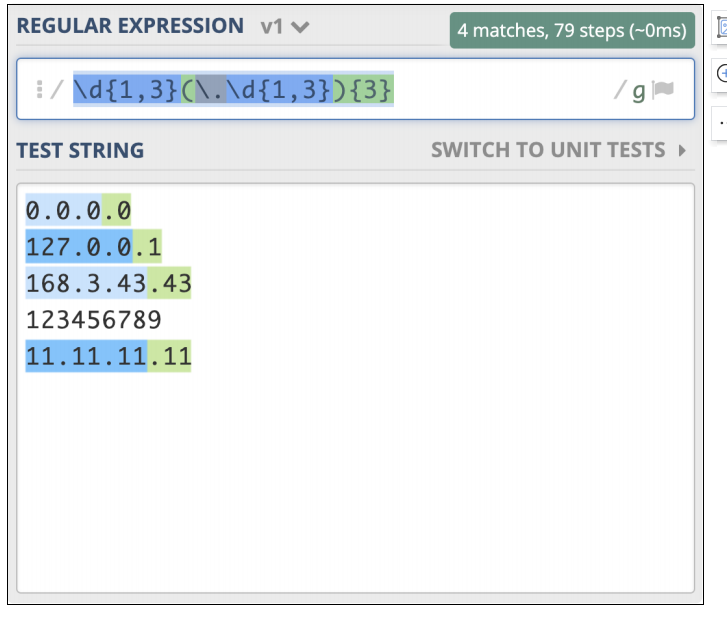
如果我们想要更精确地匹配,可以针对一到三位数分别考虑,一位数可以表示成0{0,2}\d,两位数可以表示成0?[1-9]\d,三位数可以表示成1\d\d|[0-4]\d|25[0-5],使用多选分支结构把他们写到一起,就是0{0,2}\d|0?[1-9]\d|1\d\d|2[0-4]\d|25[0-5]这样
这是表示出了 IPv4 地址中的一位(正则假设是 X),我们可以把 IPv4 表示成 X.X.X.X,可 以使用量词,写成 (?:X.){3}X 或 X(?:.X){3},由于 X 本身比较复杂,里面有多选分支结构, 所以需要把它加上括号,所以 IPv4 的正则应该可以写成
(?:0{0,2}\d|0?[1-9]\d|1\d\d|2[0-4]\d|25[0-5])(?:.0{0,2}\d|0?[1- 9]\d|1\d\d|2[0-4]\d|25[0-5]){3}。
你以为这么写就对了么,如果你测试一下就发现,匹配行为很奇怪。
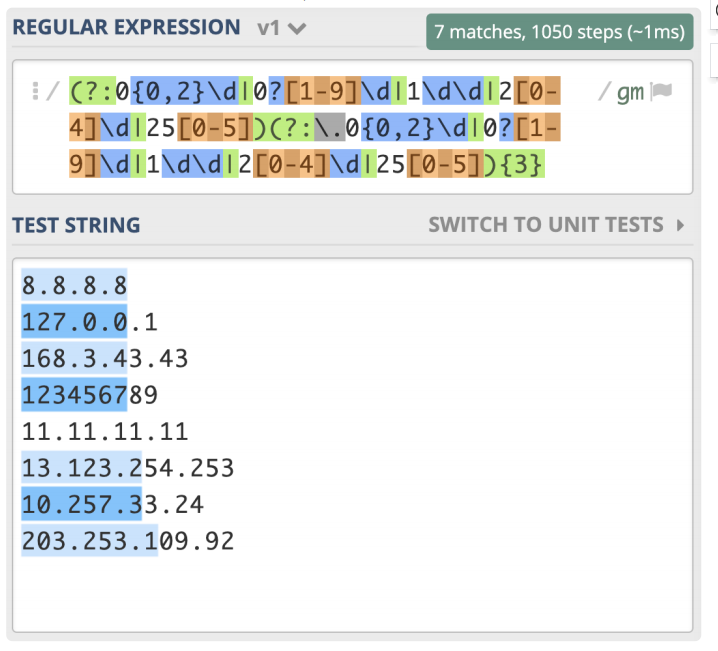
看到这个结果,你可能觉得太难了,不要担心,更不要放弃。其实我一开始也觉得这么写就可以了,我也需要测试,如果不符合预期,那就找到原因不断完善。
我们根据输出结果的表现,分析一下原因。原因主要有两点,都和多选分支结构有关系。 我们想的是所有的一到三位数字前面都有一个点,重复三次,但点号和 0{0,2}\d 写到一 起,意思是一位数字前面有点,两位和三位数前面没有点,所以需要使用括号把点挪出 去,最终写成(?:0{0,2}\d|0?[1-9]\d|1\d\d|2[0-4]\d|25[0-5])(?:.(?:0{0,2}\d|0?[1-9]\d|1\d\d|2[0-4]\d|25[0-5])){3}。
但是经过测试,还是会有问题,最后一个数字只匹配上了一位。
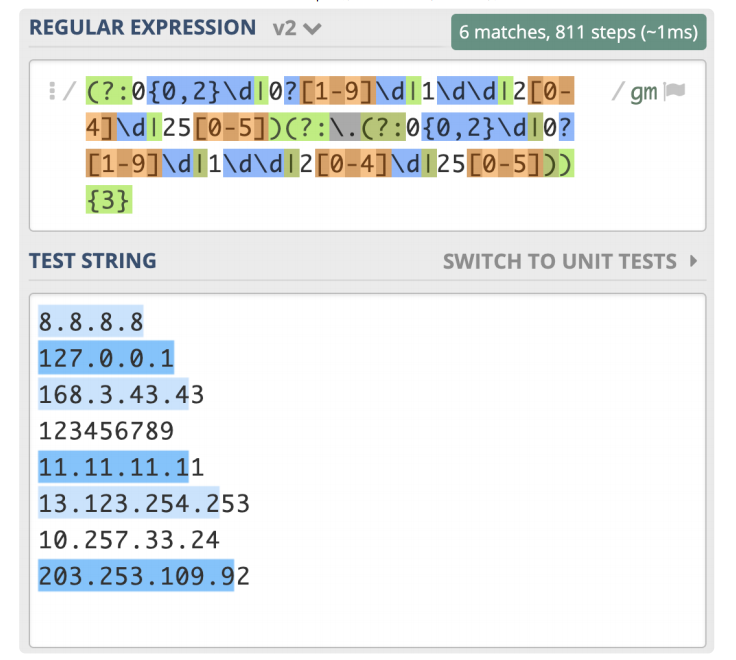
上一讲正则匹配原理中,我们讲解了 NFA 引擎在匹配多分支选择结构的时候,优先匹配最左边的,所以找到了一位数符合要求时,它就”急于“报告,并没有找出最长且符合要求的结果,这就要求我们在写多分支选择结构的时候,要把长的分支放左边,这样就可以解 决问题了,即正则写成(?:1\d\d|2[0-4]\d|25[0-5]|0?[1-9]\d|0{0,2}\d)
(?:.(?:1\d\d|2[0-4]\d|25[0-5]|0?[1-9]\d|0{0,2}\d)){3}。
11.日期和时间
假设日期格式是 yyyy-mm-dd,如果不那么严格,我们可以直接使用 \d{4}-\d{2}-\d{2}。 如果再精确一些,比如月份是 1-12,当为一位的时候,前面可能不带 0,可以写成 01 或 1,月份使用正则,可以表示成 1[0-2]|0?[1-9],日可能是 1-31,可以表示成 [12]\d|3[01]|0?[1-9],这里需要注意的是 0?[1-9] 应该放在多选分支的最后面,因为放最前面,匹配上一位数字的时候就停止了(示例),正确的正则(示例)应该是\d{4}-(?:1[0-2]|0?[1-9])-(?:[12]\d|3[01]|0?[1-9])。
时间格式比如是 23:34,如果是 24 小时制,小时是 0-23,分钟是 0-59,所以可以写成 (?:2[0-3]|1\d|0?\d)??:[1-5]\d|0?\d)。12 小时制的也是类似的,你可以自己想一想怎么写。
另外,日期中月份还有大小月的问题,比如 2 月闰年可以是 29 日,使用正则没法验证日期是不是正确的。我们也不应该使用正则来完成所有事情,而是只使用正则来限制具体的格式,比如四位数字,两位数字之类的,提取到之后,使用日期时间相关的函数进行转换,如果失败就证明不是合法的日期时间。
12.邮箱
邮箱的组成是比较复杂的,格式是 用户名 @主机名,用户名部分通常可以有英文字母,数字,下划线,点等组成,但其中点不能在开头,也不能重复出现。根据 RFC5322 没有办法写出一个完美的正则,你可以参考一下这个网站。不过我们可以实现一些简体的版本,比如:[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+.[a-zA-Z0-9-.]+
13.网页标签
配对出现的标签,比如title,一版网页标签不区分大小写,我们可以使用(?i)
我们通过一些常见的问题,逐步进行分析,讲解了正则表达式书写时的思路和一些常见的错误。这些正则如果用于校验,还需要添加断言,比如\A和\z(或\Z),或 ^ 和 $。
如果用于数据提取,还应当在首尾添加相应的断言