Abstarct
存在的问题:在Text-to-SQL问题中,之前的基准(Spider和WikiSQL)聚焦于数据库中较少的行,学术研究和现实应用的距离较大。
BIRD主要重视dirty content,external knowledge和SQL的效率三方面。
对比了human和ChatGPT生成语句的精度,发现chatgpt和人类仍存在很大的差距。
1.Introduction
Text-to-SQL: NL用于SQL询问
LLM 可以用于数据库的接口吗?No,下面这个图很好的解释了原因
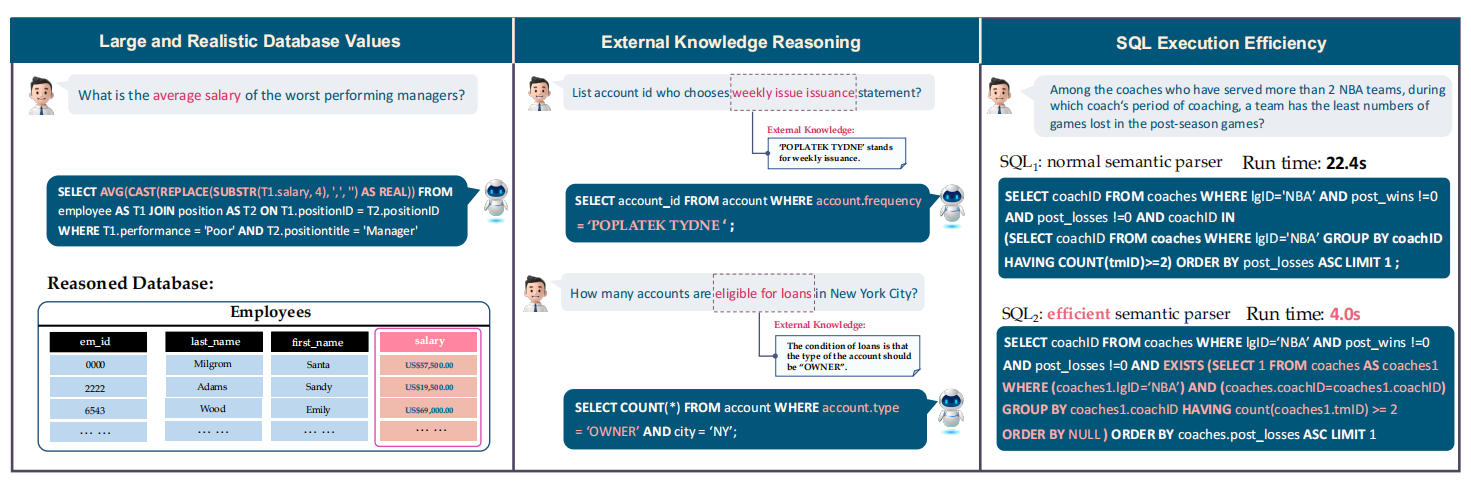
- 现实生活中数据库容量大以及噪声文本
- 需要赋予额外知识和推断能力
- 效率低下需要优化
怎么做?

提出BIRD(A Big Bench for Large-Scale DataBase)去代表真实世界的情况。采用95个关系型数据库,80个用于训练,15个用于评价。
- 列提出列名、列的类型、额外的知识等方面帮助annotators更好理解数据库中的内容。
- 训练native speaker提问,数据工程师和学生解答
- 提出VES评估生成SQL语句的效率,同时兼顾执行的准确度。
采用了两种方法去评价:fine-tuning with T5和ICL方法(基于LLM)
2 Task Formulation & Annotations2
\(Y = f(Q,D,k|\theta)\)
Q代表问题,Y代表答案,k代表额外的知识提升大模型的理解程度
\(f(.|\theta)\)代表模型(基于\(\theta\)参数)
额外的知识可具有结构,如json/csv files
也可以无结构,如evidence texts
也可以是空的。
3 Dataset Construction
3.1 Dataset Source
69个training,11个development,15个testing
同时划分为37个领域,涵盖健康关照、运动、政治
3.2 Question Annotation
Entrance
- ER图和数据库文件去帮助annotators理解数据库
- 每位annotators提供3个数据库(不同领域),每个生成10个问题
- 专家评价,保留有价值的annotators
Database Description File
- Full schema names:表和列的名字难以理解
- Value description:主要针对问题和数据库中的value难以匹配的问题。
比如“POJISTNE”代表insurance payment
External Knowledge
主要针对四个方面
- 数值推理知识:比如加、减、乘、取最小值等操作
- 领域知识:比如银行的交易需要金融领域的知识,计算投资收入等
- 同义词知识:不同的词可能有相同的含义,保证问题可以正确的转化为SQL语句。
- 具体值的说明:比如"pos = C"会和center等价
3.3 SQL Annotation
Entrance
选拔经过训练的数据工程师和学生。
被询问10个问题,只有能够回答9个或10个才能进入后续环节
Double-Blind Annotation
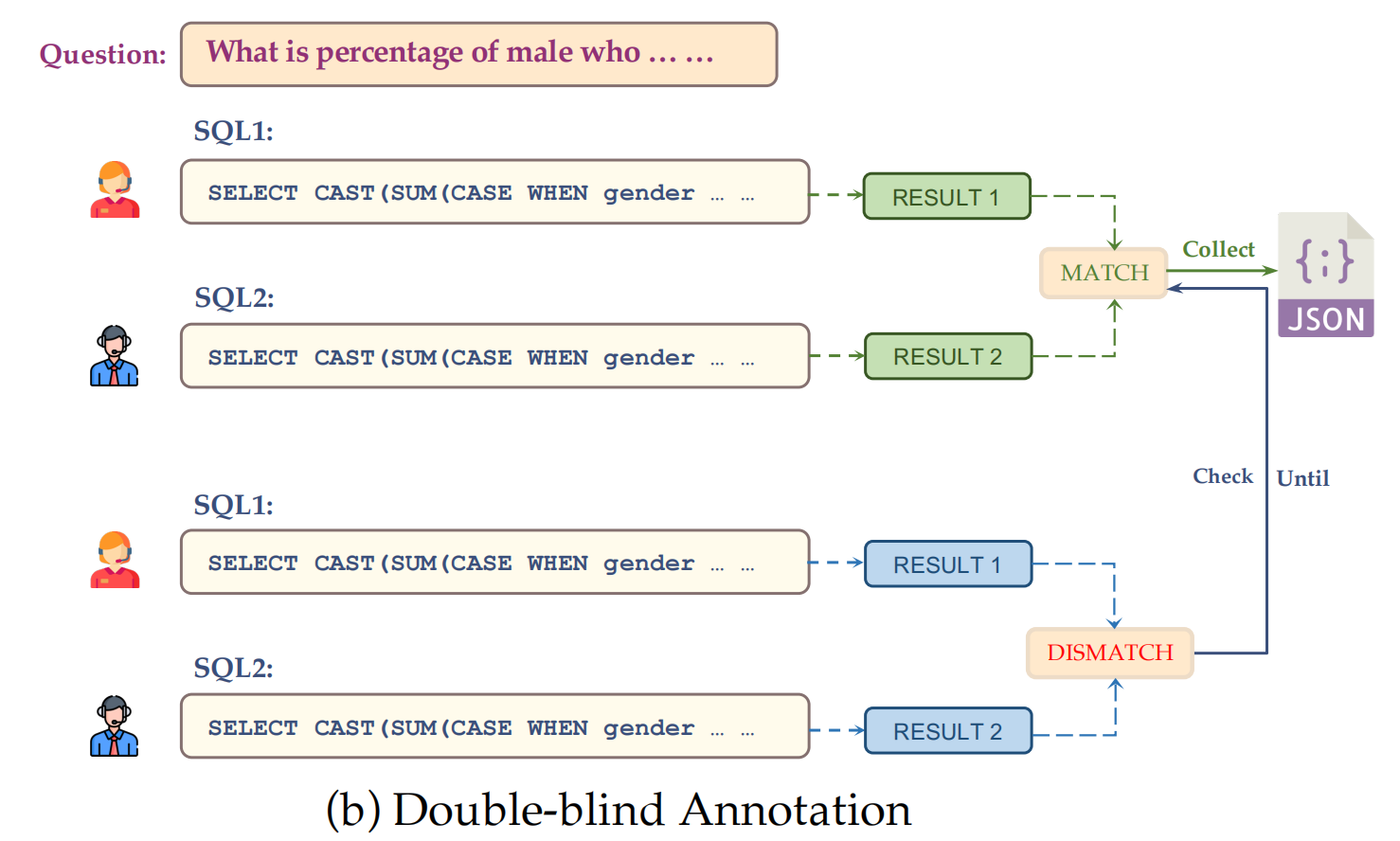
表现最好的SQL语句进入语料库,并且额外的知识语句也会记录下来
Examination
主要检查两方面。
- 生成的SQL语句是可执行的,可以返回数据库中有效的结果
- 生成的SQL语句是可以由问题和额外的已给定知识生成