今天继续rddd练习:
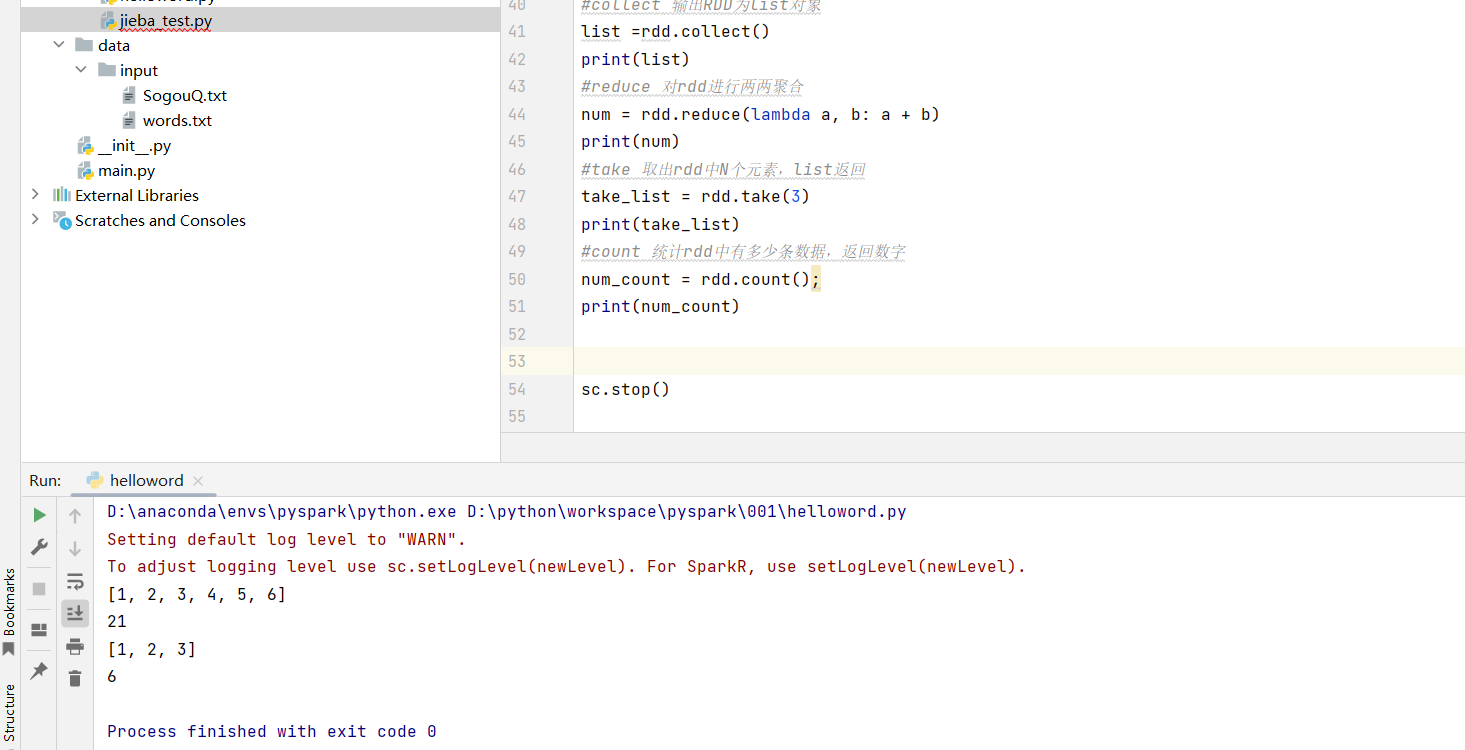
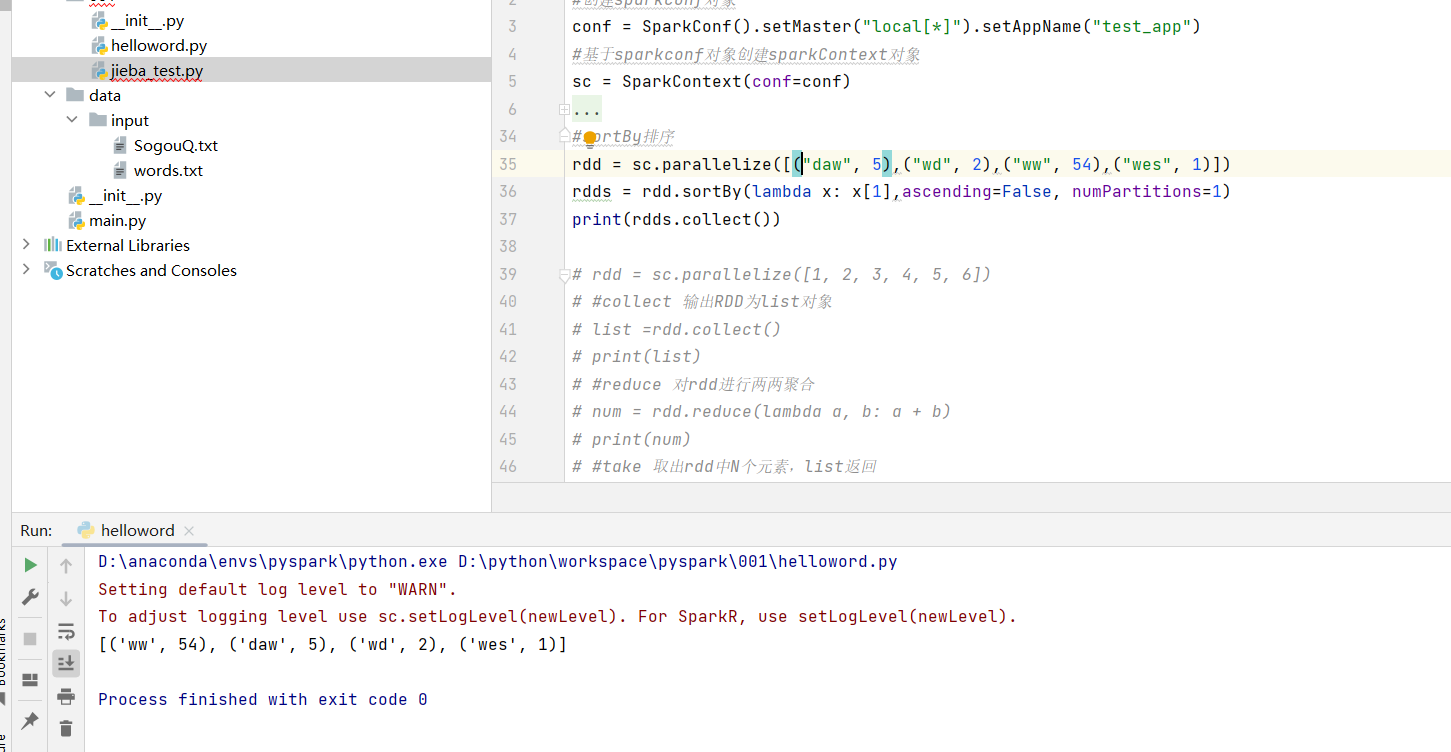
from pyspark import SparkConf,SparkContext #创建sparkconf对象 conf = SparkConf().setMaster("local[*]").setAppName("test_app") #基于sparkconf对象创建sparkContext对象 sc = SparkContext(conf=conf) ##########基本结构 #map计算 # rdd = sc.parallelize([1,2,3,4,5]) # def func(date): # return date*10 # rdds=rdd.map(func) #flatMap解除嵌套 # rdd = sc.parallelize(["dwad wad wdas","dwadw dfgawdfw dwad","dwadwad"]) # rdds=rdd.flatMap(lambda x : x.split(" ")) #reduceByKey分组两两计算 # rdd=sc.parallelize([('男',99),('女',99),('女',99),('男',99),('男',99),('男',99)]) # rdds = rdd.reduceByKey(lambda a, b: a+b) # print(rdds.collect()) #filter过滤数据 # rdd=sc.parallelize([1,2,3,4,5]) # rdds = rdd.filter(lambda num: num % 2 == 0) # print(rdds.collect()) #distinct去重 # rdd=sc.parallelize([1, 2, 3, 4, 5, 1]) # rdds = rdd.distinct() # print(rdds.collect()) #停止spark #sortBy排序 # rdd = sc.parallelize([("daw", 5),("wd", 2),("ww", 54),("wes", 1)]) # rdds = rdd.sortBy(lambda x: x[1],ascending=False, numPartitions=1) # print(rdds.collect()) rdd = sc.parallelize([1, 2, 3, 4, 5, 6]) #collect 输出RDD为list对象 list =rdd.collect() print(list) #reduce 对rdd进行两两聚合 num = rdd.reduce(lambda a, b: a + b) print(num) #take 取出rdd中N个元素,list返回 take_list = rdd.take(3) print(take_list) #count 统计rdd中有多少条数据,返回数字 num_count = rdd.count(); print(num_count) sc.stop()
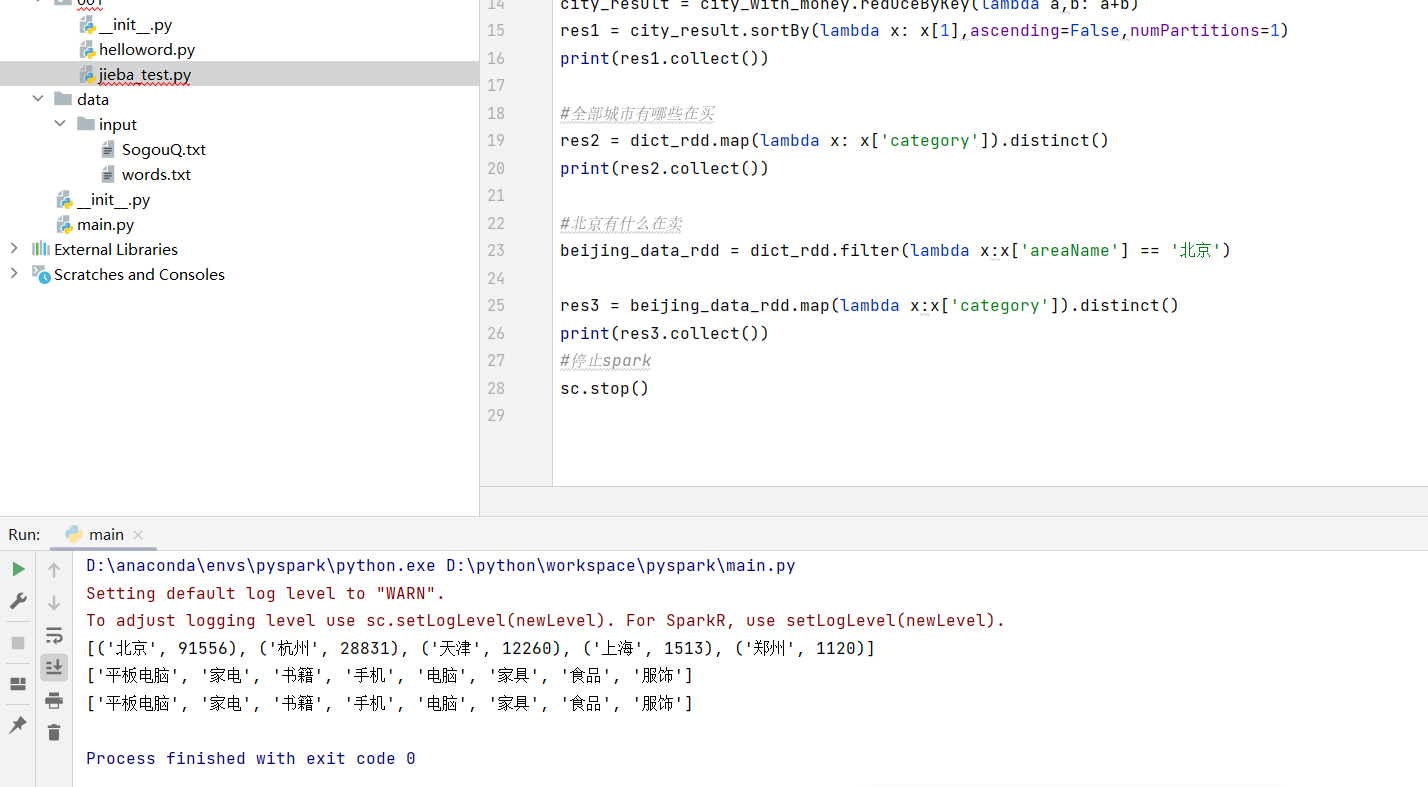
from pyspark import SparkConf,SparkContext import json #创建sparkconf对象 conf = SparkConf().setMaster("local[*]").setAppName("test_app") #基于sparkconf对象创建sparkContext对象 sc = SparkContext(conf=conf) file_rdd = sc.textFile("D:/order.txt") json_str_rdd = file_rdd.flatMap(lambda x: x.split("|")) #转化为map dict_rdd = json_str_rdd.map(lambda x: json.loads(x)) #城市销售额排名 #print(dict_rdd.collect()) city_with_money = dict_rdd.map(lambda x: (x['areaName'], int(x['money']))) city_result = city_with_money.reduceByKey(lambda a,b: a+b) res1 = city_result.sortBy(lambda x: x[1],ascending=False,numPartitions=1) print(res1.collect()) #全部城市有哪些在买 res2 = dict_rdd.map(lambda x: x['category']).distinct() print(res2.collect()) #北京有什么在卖 beijing_data_rdd = dict_rdd.filter(lambda x:x['areaName'] == '北京') res3 = beijing_data_rdd.map(lambda x:x['category']).distinct() print(res3.collect()) #停止spark sc.stop()