首先 来一下 官网文档地址:
一、数据库
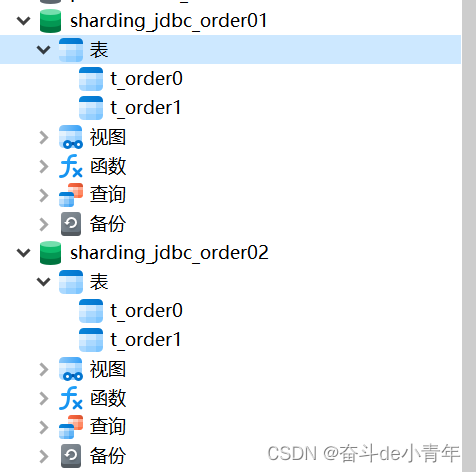
分为2个库,每个库有2张表
![]()
二、配置
官方有很多配置方式(
规则配置:数据分片遇到的坑
以下是官方给出的参数配置解释:
rules:
- !SHARDING
tables: # 数据分片规则配置
<logic-table-name> (+): # 逻辑表名称
actualDataNodes (?): # 由数据源名 + 表名组成(参考 Inline 语法规则)
databaseStrategy (?): # 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
standard: # 用于单分片键的标准分片场景
shardingColumn: # 分片列名称
shardingAlgorithmName: # 分片算法名称
complex: # 用于多分片键的复合分片场景
shardingColumns: # 分片列名称,多个列以逗号分隔
shardingAlgorithmName: # 分片算法名称
hint: # Hint 分片策略
shardingAlgorithmName: # 分片算法名称
none: # 不分片
tableStrategy: # 分表策略,同分库策略
keyGenerateStrategy: # 分布式序列策略
column: # 自增列名称,缺省表示不使用自增主键生成器
keyGeneratorName: # 分布式序列算法名称
auditStrategy: # 分片审计策略
auditorNames: # 分片审计算法名称
- <auditor-name>
- <auditor-name>
allowHintDisable: true # 是否禁用分片审计hint
autoTables: # 自动分片表规则配置
t_order_auto: # 逻辑表名称
actualDataSources (?): # 数据源名称
shardingStrategy: # 切分策略
standard: # 用于单分片键的标准分片场景
shardingColumn: # 分片列名称
shardingAlgorithmName: # 自动分片算法名称
bindingTables (+): # 绑定表规则列表
- <logic_table_name_1, logic_table_name_2, ...>
- <logic_table_name_1, logic_table_name_2, ...>
broadcastTables (+): # 广播表规则列表
- <table-name>
- <table-name>
defaultDatabaseStrategy: # 默认数据库分片策略
defaultTableStrategy: # 默认表分片策略
defaultKeyGenerateStrategy: # 默认的分布式序列策略
defaultShardingColumn: # 默认分片列名称
# 分片算法配置
shardingAlgorithms:
<sharding-algorithm-name> (+): # 分片算法名称
type: # 分片算法类型
props: # 分片算法属性配置
# ...
# 分布式序列算法配置
keyGenerators:
<key-generate-algorithm-name> (+): # 分布式序列算法名称
type: # 分布式序列算法类型
props: # 分布式序列算法属性配置
# ...
# 分片审计算法配置
auditors:
<sharding-audit-algorithm-name> (+): # 分片审计算法名称
type: # 分片审计算法类型
props: # 分片审计算法属性配置
# ...
以下是官方给出的配置示例:
dataSources:
ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3306/demo_ds_0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password:
ds_1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3306/demo_ds_1?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password:
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t-order-inline
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
auditStrategy:
auditorNames:
- sharding_key_required_auditor
allowHintDisable: true
t_order_item:
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order-item-inline
keyGenerateStrategy:
column: order_item_id
keyGeneratorName: snowflake
t_account:
actualDataNodes: ds_${0..1}.t_account_${0..1}
tableStrategy:
standard:
shardingAlgorithmName: t-account-inline
keyGenerateStrategy:
column: account_id
keyGeneratorName: snowflake
defaultShardingColumn: account_id
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_address
defaultDatabaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database-inline
defaultTableStrategy:
none:
shardingAlgorithms:
database-inline:
type: INLINE
props:
algorithm-expression: ds_${user_id % 2}
t-order-inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 2}
t_order-item-inline:
type: INLINE
props:
algorithm-expression: t_order_item_${order_id % 2}
t-account-inline:
type: INLINE
props:
algorithm-expression: t_account_${account_id % 2}
keyGenerators:
snowflake:
type: SNOWFLAKE
auditors:
sharding_key_required_auditor:
type: DML_SHARDING_CONDITIONS
props:
sql-show: false第一个坑:按官方给出的配置一直报错:找不到逻辑表名
org.springframework.jdbc.BadSqlGrammarException:
### Error updating database. Cause: java.sql.SQLSyntaxErrorException: Table 'sharding_jdbc_order01.t_order' doesn't exist
### The error may exist in com/sharding/jdbc/test/mapper/OrderMapper.java (best guess)
### The error may involve com.sharding.jdbc.test.mapper.OrderMapper.insert-Inline
### The error occurred while setting parameters
### SQL: INSERT INTO t_order ( id, order_no, user_id, amount ) VALUES ( ?, ?, ?, ? )
### Cause: java.sql.SQLSyntaxErrorException: Table 'sharding_jdbc_order01.t_order' doesn't exist
; bad SQL grammar []; nested exception is java.sql.SQLSyntaxErrorException: Table 'sharding_jdbc_order01.t_order' doesn't exist解决办法:在rules下边加上sharding
rules:
#需要加上sharding
sharding:
tables:第二个坑:分片算法名称必须是中划线,如果是下划线就会报下边的错
Caused by: org.apache.shardingsphere.spi.exception.ServiceProviderNotFoundException: No implementation class load from SPI `org.apache.shardingsphere.sharding.spi.ShardingAlgorithm` with type `null`.
at org.apache.shardingsphere.spi.typed.TypedSPIRegistry.getRegisteredService(TypedSPIRegistry.java:76)
at org.apache.shardingsphere.spring.boot.registry.AbstractAlgorithmProvidedBeanRegistry.lambda$registerBean$2(AbstractAlgorithmProvidedBeanRegistry.java:78)
at java.util.LinkedHashMap.forEach(LinkedHashMap.java:684)
at org.apache.shardingsphere.spring.boot.registry.AbstractAlgorithmProvidedBeanRegistry.registerBean(AbstractAlgorithmProvidedBeanRegistry.java:77)
at org.apache.shardingsphere.sharding.spring.boot.algorithm.ShardingAlgorithmProvidedBeanRegistry.postProcessBeanDefinitionRegistry(ShardingAlgorithmProvidedBeanRegistry.java:38)分片算法名称正确写法:
rules:
sharding:
tables: # 数据分片规则配置
t_order: # 逻辑表名称
actualDataNodes: server-order0$->{0..1}.t_order$->{0..1} # 由数据源名 + 表名组成(参考 Inline 语法规则)
databaseStrategy: # 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
standard: # 用于单分片键的标准分片场景
shardingColumn: user_id # 分片列名称(数据库列字段,用户名称)
shardingAlgorithmName: t-order-inline # 分片算法名称(必须以中划线命名)
#分片算法配置
shardingAlgorithms:
#行表达式分片算法
t-order-inline: # 分片算法名称(必须以中划线命名)
# type 和 props,请参考分片内置算法:https://shardingsphere.apache.org/document/current/cn/user-manual/common-config/builtin-algorithm/sharding/
type: INLINE # 分片算法类型
props: # 分片算法属性配置
#t_order0$->{user_id % 2} 表示 t_order 表根据 user_id 取模(取余) 2,而分成 2 张表,表名称为 t_order01 到 t_order02
algorithm-expression: server-order0$->{user_id % 2}分片算法名称错误写法:
rules:
sharding:
tables: # 数据分片规则配置
t_order: # 逻辑表名称
actualDataNodes: server-order0$->{0..1}.t_order$->{0..1} # 由数据源名 + 表名组成(参考 Inline 语法规则)
databaseStrategy: # 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
standard: # 用于单分片键的标准分片场景
shardingColumn: user_id # 分片列名称(数据库列字段)
shardingAlgorithmName: t_order_inline # 分片算法名称(不能用下划线命名)
#分片算法配置
shardingAlgorithms:
#行表达式分片算法
t_order_inline: # 分片算法名称(不能用下划线命名)
# type 和 props,请参考分片内置算法:https://shardingsphere.apache.org/document/current/cn/user-manual/common-config/builtin-algorithm/sharding/
type: INLINE # 分片算法类型
props: # 分片算法属性配置
#t_order0$->{user_id % 2} 表示 t_order 表根据 user_id 取模(取余) 2,而分成 2 张表,表名称为 t_order01 到 t_order02
algorithm-expression: server-order0$->{user_id % 2}暂时就遇到这两个,先记录一下,后续如果在遇到会继续写。