7.13-Prometheus Operator优化配置
1、数据持久化
1.1 prometheus数据持久化
默认Prometheus和Grafana不做数据持久化,那么服务重启以后配置的Dashboard、账号密码、监控数据等信息将会丢失,所以做数据持久化也是很有必要的。
原始的数据是以 emptyDir 形式存放在pod里面,生命周期与pod相同,出现问题时,容器重启,监控相关的数据就全部消失了。
vim manifests/prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.29.1
prometheus: k8s
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- apiVersion: v2
name: alertmanager-main
namespace: monitoring
port: web
enableFeatures: []
externalLabels: {}
image: quay.io/prometheus/prometheus:v2.29.1
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.29.1
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
probeNamespaceSelector: {}
probeSelector: {}
replicas: 2
resources:
requests:
memory: 400Mi
ruleNamespaceSelector: {}
ruleSelector: {}
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: 2.29.1
# 新增持久化存储,yaml 末尾添加
retention: 7d #加这个参数,表示prometheus数据保留的天数,默认会是1天
storage:
volumeClaimTemplate:
spec:
storageClassName: nfs-storageclass
resources:
requests:
storage: 50Gi1.2 grafana 数据持久化
先手动创建grafana的持久化PVC:grafana-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-pvc
namespace: monitoring
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi
storageClassName: nfs-storageclassvim manifests/grafana-deployment.yaml
volumes:
# - emptyDir: {} # 注释此两行,新增下三行
# name: grafana-storage
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana-pvc
- name: grafana-datasources
secret:
secretName: grafana-datasources为了固定grafana的登录密码,添加环境变量:
readinessProbe:
httpGet:
path: /api/health
port: http
env: #添加环境变量
- name: GF_SECURITY_ADMIN_USER #添加环境变量
value: admin #添加环境变量
- name: GF_SECURITY_ADMIN_PASSWORD #添加环境变量
value: admin #添加环境变量
resources:
limits:
cpu: 200m
memory: 200Mi2、优化配置
插件:kubernetes plugin for Grafana | Grafana Labs
kubectl exec -it $(kubectl get pod -n monitoring -l app.kubernetes.io/name=grafana \
-o jsonpath='{.items[*].metadata.name}') -n monitoring -- sh
/usr/share/grafana $ grafana-cli plugins install grafana-piechart-panel
/usr/share/grafana $ grafana-cli plugins install camptocamp-prometheus-alertmanager-datasource
/usr/share/grafana $ grafana-cli plugins install grafana-kubernetes-app
cd ./kube-prometheus/manifests
sed -i 's/UTC/UTC+8/g' grafana-dashboardDefinitions.yaml
kubectl apply -f grafana-dashboardDefinitions.yaml 3、如何修改alert rule?
3.1 通过rule规则修改
kubectl edit cm prometheus-k8s-rulefiles-0 -n monitoring 3.2 修改配置文件方式
cd ./kube-prometheus/manifests
vim kubernetes-prometheusRule.yaml
#应用
kubectl apply kubernetes-prometheusRule.yaml4、AlterManager报警配置
cat << EOF > alertmanager-prometheusAlert.yaml
apiVersion: v1
kind: Secret
metadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.24.0
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
global:
resolve_timeout: 5m
route:
group_by: ['env','instance','type','group','job','alertname','cluster']
group_wait: 10s
group_interval: 2m
repeat_interval: 10m
receiver: 'webhook'
receivers:
- name: 'webhook'
webhook_configs:
- url: 'http://prometheus-alert-center.monitor.svc:8080/prometheusalert?type=wx&tpl=prometheus-wx&wxurqq.com/cgi-bin/webhook/send?key=71c0a6f0-43a0-4ecf-dddd-52aff88f3b68&at=ZhangDaDan,ZHDYA'
send_resolved: true
type: Opaque
EOFkubectl apply -f alertmanager-prometheusAlert.yaml
7.14-1-Prometheus Operator自定义监控对象(上)
自定义监控对象-Ingress-Nginx
1、自定义资源
Prometheus-operator通过定期循环watch apiserver,获取到CRD资源(比如servicemonitor)的创建或者更新,将配置更新及时应用到运行中的prometheus pod中转换成标准prometheus配置文件供Prometheus server 使用
各CRD一级operator之间的关系:
使用CRD做prometheus配置,“匹配”是一个很重要的细节,详细匹配关系如图,任何地方匹配失败会导致转化成的匹配prometheus文件无法识别到targets。
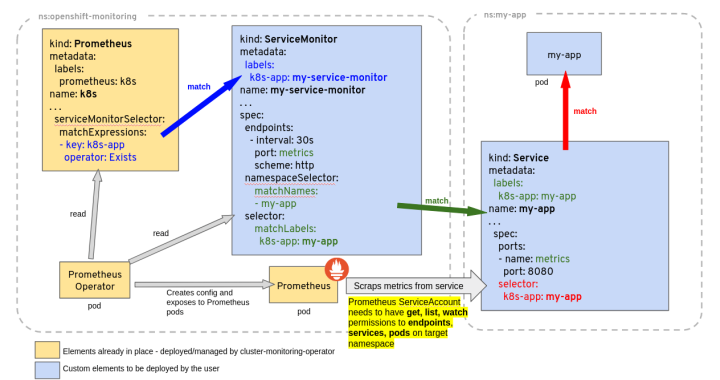
Prometheus Operater 定义如下四类自定义资源:
- Prometheus
- ServiceMonitor
- Alertmanager
- PrometheusRule
1.1 Prometheus
Prometheus 自定义资源(CRD)声明在kubernetes集群中运行的Prometheus的期望设置。包含了副本数量,持久化存储,以及Prometheus实例发送警告到Alertmanager 等配置选项。
每一个Prometheus 资源,Operator都会在相同的namespace 下部署成一个正确配置的StatefulSet,Prometheus的Pod会挂载一个名为Secret,里面包含了Prometheus 配置。Operator根据包含的ServiceMonitor生成配置,并且更新含有配置的Secret。无论是对ServiceMonitors或者Prometheus的修改,都会持续不断地被按照前面的步骤更新。
示例配置:
kind: Prometheus
metadata: # 略
spec:
alerting:
alertmanagers:
- name: prometheus-prometheus-oper-alertmanager # 定义该 Prometheus 对接的 Alertmanager 集群的名字, 在 default 这个 namespace 中
namespace: default
pathPrefix: /
port: web
baseImage: quay.io/prometheus/prometheus
replicas: 2 # 定义该 Proemtheus “集群”有两个副本
ruleSelector: # 定义这个 Prometheus 需要使用带有 prometheus=k8s 且 role=alert-rules 标签的 PrometheusRule
matchLabels:
prometheus: k8s
role: alert-rules
serviceMonitorNamespaceSelector: {} # 定义这些 Prometheus 在哪些 namespace 里寻找 ServiceMonitor
serviceMonitorSelector: # 定义这个 Prometheus 需要使用带有 k8s-app=node-exporter 标签的 ServiceMonitor,不声明则会全部选中
matchLabels:
k8s-app: node-exporter
version: v2.10.01.2 ServiceMonitor
官网配置:https://github.com/coreos/prometheus-operator/blob/master/Documentation/api.md#servicemonitor
ServiceMonitor自定义资源(CRD)能够声明如何监控一组动态服务的定义。它使用标签选择定义一组需要被监控的服务。这样允许组织引入如何暴露metrics的规定,只要符合这些规定新服务就好被发现列入监控,而不是需要重新配置系统。
使用Prometheus Operator监控Kubernetes集群中的应用,Endpoints对象必须存在。Endpoints对象本周是一个Ip地址列表。通常,Endpoints对象由Service构建。Service对象通过对象选择器发现Pod并将他们添加到Endpoints对象中。
Prometheus Operator 引入ServiceMonitor对象,它发现Endpoints对象并配置Prometheus去监控这些Pods。
ServiceMonitorSpec的endpoints部分用于配置需要手机metrics的Endpoints的端口和其他参数。
注意:endpoints(小写)是 ServiceMonitor CRD 中的一个字段,而 Endpoints(大写)是 Kubernetes 资源类型。ServiceMonitor和发下的目标可能来着任何namespace
- 使用PrometheusSpec 下ServiceMonitorNamespaceSelector,通过各自Prometheus server 限制 ServiceMonitors左右namespace
- 使用ServiceMonitorSpec下的namespaceSelector允许发现Endpoints对象的命名空间。要发现所有命名空间下的目标,namespaceSelector必须为空。
spec:
namespaceSelector:
any: true示例配置如下:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: node-exporter # 这个 ServiceMonitor 对象带有 k8s-app=node-exporter 标签,因此会被 Prometheus 选中
name: ingress-nginx
namespace: monitoring
spec:
endpoints:
- interval: 15s # 定义这些 Endpoints 需要每 15 秒抓取一次
port: prometheus # 这边一定要用svc中 port的name。
namespaceSelector:
matchNames:
- ingress-nginx # 选定抓取的指定namespace
selector:
matchLabels: # 匹配的抓取标签
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.7.01.3 Alertmanager
Alertmanager 配置:https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/api.md#alertmanager
Alertmanager 自定义资源(CRD)声明在kubernetes集群中运行的Alertmanager的期望设置。它也提供了配置副本集合持久化存储的选项。
每个Alertmanager资源,Operator都会在相同的namespace下部署成一个正确配置的StatefulSet。Alertmanager pods配置挂载一个Secret,使用alertmanager.yaml key作为配置文件
当有两个或更多配置的副本时,Operator可以高可用性模式运行Alertmanager 实例。
示例如下:
kind: Alertmanager # 一个 Alertmanager 对象
metadata:
name: prometheus-prometheus-oper-alertmanager
spec:
baseImage: quay.io/prometheus/alertmanager
replicas: 3 # 定义该 Alertmanager 集群的节点数为 3
version: v0.17.01.4 PrometheusRule
PrometheusRule 配置:https://github.com/coreos/prometheus-operator/blob/master/Documentation/api.md#prometheusrule
PrometheusRule CRD 声明一个或多个Prometheus实例需要的Prometheus rule。Alerts和recording rules 可以保存为yaml,可以被动态加载而不用重启服务。
示例配置:
kind: PrometheusRule
metadata:
labels: # 定义该 PrometheusRule 的 label, 显然它会被 Prometheus 选中
prometheus: k8s
role: alert-rules
name: prometheus-k8s-rules
spec:
groups:
- name: k8s.rules
rules: # 定义了一组规则,其中只有一条报警规则,用来报警 kubelet 是不是挂了
- alert: KubeletDown
annotations:
message: Kubelet has disappeared from Prometheus target discovery.
expr: |
absent(up{job="kubelet"} == 1)
for: 15m
labels:
severity: critical1.5 配置间的匹配总结
ServiceMonitor 注意事项:
- ServiceMonitor 的 label 需要跟prometheus中定义的serviceMonitorSelector一致。
- ServiceMonitor 的 endpoints 中 port 时对应k8s service资源中的 portname , 不是 port number。
- ServiceMonitor 的 selector.matchLabels 需要匹配 k8s service 中的 label。
- ServiceMonitor 资源创建在 prometheus 的 namespace 下,使用 namespaceSelector 匹配要监控的 k8s svc 的 ns。
- servicemonitor 若匹配多个 svc ,会发生数据重复。
7.14-2-Prometheus Operator自定义监控对象(下)
2、Ingress nginx(Helm)
2.1 暴露ingress的监控端口
通过helm部署维护的ingress-nginx
cat values.yaml
metrics:
port: 10254
portName: metrics
# if this port is changed, change healthz-port: in extraArgs: accordingly
enabled: true
service:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "10254"
···
prometheusRule:
enabled: true
additionalLabels: {}
namespace: "monitoring"默认情况下 nginx-ingress的监控指标端口为10254,监控路径为其下的/metrics。调整配置ingress-nginx的配置文件,打开service及pod的10254 端口
更新values
helm upgrade ingress-nginx ./ingress-nginx -f ./ingress-nginx/values.yaml -n ingress-nginx查看验证指标数据:
kubectl get ep -ningress-nginx
kubectl get ep -ningress-nginx
2.2 手动添加 serviceMonitor
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: ingress-nginx
namespace: monitoring
spec:
endpoints:
- interval: 15s
port: metrics
namespaceSelector:
matchNames:
- ingress-nginx
selector:
matchLabels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.7.0
---
# 在对应的ns中创建角色
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: prometheus-k8s
namespace: ingress-nginx
rules:
- apiGroups:
- ""
resources:
- services
- endpoints
- pods
verbs:
- get
- list
- watch
---
# 绑定角色 prometheus-k8s 角色到 Role
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: prometheus-k8s
namespace: ingress-nginx
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: prometheus-k8s
subjects:
- kind: ServiceAccount
name: prometheus-k8s # Prometheus 容器使用的 serviceAccount,kube-prometheus默认使用prometheus-k8s这个用户
namespace: monitoring验证:
kg servicemonitor -nmonitoring2.3 添加报警规则
prometheusRule:
enabled: true
additionalLabels: {}
namespace: "monitoring"
rules:
- alert: NginxFailedtoLoadConfiguration
expr: nginx_ingress_controller_config_last_reload_successful == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Nginx Ingress Controller配置文件加载失败"
description: "Nginx Ingress Controller的配置文件加载失败,请检查配置文件是否正确。"
- alert: NginxHighHttp4xxErrorRate
expr: rate(nginx_ingress_controller_requests{status=~"^404"}[5m]) * 100 > 1
for: 1m
labels:
severity: warining
annotations:
description: Nginx high HTTP 4xx error rate ( namespaces {{ $labels.exported_namespace }} host {{ $labels.host }} )
summary: "Too many HTTP requests with status 404 (> 1%)"
- alert: NginxHighHttp5xxErrorRate
expr: rate(nginx_ingress_controller_requests{status=~"^5.."}[5m]) * 100 > 1
for: 1m
labels:
severity: warining
annotations:
description: Nginx high HTTP 5xx error rate ( namespaces {{ $labels.exported_namespace }} host {{ $labels.host }} )
summary: "Too many HTTP requests with status 5xx (> 1%)"
- alert: NginxLatencyHigh
expr: histogram_quantile(0.99, sum(rate(nginx_ingress_controller_request_duration_seconds_bucket[2m])) by (host, node)) > 3
for: 2m
labels:
severity: warining
annotations:
description: Nginx latency high ( namespaces {{ $labels.exported_namespace }} host {{ $labels.host }} )
summary: "Nginx p99 latency is higher than 3 seconds"
- alert: NginxHighRequestRate
expr: rate(nginx_ingress_controller_nginx_process_requests_total[5m]) * 100 > 1000
for: 1m
labels:
severity: warning
annotations:
description: Nginx ingress controller high request rate ( instance {{ $labels.instance }} namespaces {{ $labels.namespaces }} pod {{$labels.pod}})
summary: "Nginx ingress controller high request rate (> 1000 requests per second)"
- alert: SSLCertificateExpiration15day
expr: nginx_ingress_controller_ssl_expire_time_seconds < 1296000
for: 30m
labels:
severity: warning
annotations:
summary: SSL/TLS certificate for {{ $labels.host $labels.secret_name }} is about to expire
description: The SSL/TLS certificate for {{ $labels.host $labels.secret_name }} will expire in less than 15 days.
- alert: SSLCertificateExpiration7day
expr: nginx_ingress_controller_ssl_expire_time_seconds < 604800
for: 30m
labels:
severity: critical
annotations:
summary: SSL/TLS certificate for {{ $labels.host $labels.secret_name }} is about to expire
description: The SSL/TLS certificate for {{ $labels.host $labels.secret_name }} will expire in less than 7 days.通过 webUI 去验证prometheus 的rules/target 是否ok;
三、 抓取自定义资源-- 常规部署的Ingress-nginx
3.1 修改Ingress Service
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "10254"
..
spec:
ports:
- name: prometheus
port: 10254
targetPort: 10254
..
修改完成最终效果:
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/port: "10254"
prometheus.io/scrape: "true"
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.3.1
name: ingress-nginx-controller
namespace: ingress-nginx
spec:
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- appProtocol: http
name: http
port: 80
protocol: TCP
targetPort: http
- appProtocol: https
name: https
port: 443
protocol: TCP
targetPort: https
- name: prometheus
port: 10254
targetPort: 10254
selector:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
type: ClusterIP3.2 修改Ingress deployment
apiVersion: v1
kind: Deployment
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "10254"
..
spec:
ports:
- name: prometheus
containerPort: 10254
..
## 重新apply一下yaml文件让修改的配置生效
$ kubectl apply -f ingress-deploy.yml 重新部署yaml
kubectl apply -f ingress-deploy.yml 3.3 测试验证:
kubectl get po,svc -n ingress-nginx
curl 127.0.0.1:10254/metrics # 在Ingress的节点上运行一下看看是否可以获取到资源3.4 新增Ingress ServiceMonitor
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: ingress-nginx
namespace: monitoring
spec:
endpoints:
- interval: 15s
port: prometheus
namespaceSelector:
matchNames:
- ingress-nginx
selector:
matchLabels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.7.0
---
# 在对应的ns中创建角色
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: prometheus-k8s
namespace: ingress-nginx
rules:
- apiGroups:
- ""
resources:
- services
- endpoints
- pods
verbs:
- get
- list
- watch
---
# 绑定角色 prometheus-k8s 角色到 Role
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: prometheus-k8s
namespace: ingress-nginx
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: prometheus-k8s
subjects:
- kind: ServiceAccount
name: prometheus-k8s # Prometheus 容器使用的 serviceAccount,kube-prometheus默认使用prometheus-k8s这个用户
namespace: monitoring3.5 添加报警规则
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: nginx-ingress-rules
namespace: monitoring
spec:
groups:
- name: nginx-ingress-rules
rules:
- alert: NginxFailedtoLoadConfiguration
expr: nginx_ingress_controller_config_last_reload_successful == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Nginx Ingress Controller配置文件加载失败"
description: "Nginx Ingress Controller的配置文件加载失败,请检查配置文件是否正确。"
- alert: NginxHighHttp4xxErrorRate
expr: rate(nginx_ingress_controller_requests{status=~"^404"}[5m]) * 100 > 1
for: 1m
labels:
severity: warining
annotations:
description: Nginx high HTTP 4xx error rate ( namespaces {{ $labels.exported_namespace }} host {{ $labels.host }} )
summary: "Too many HTTP requests with status 404 (> 1%)"
- alert: NginxHighHttp5xxErrorRate
expr: rate(nginx_ingress_controller_requests{status=~"^5.."}[5m]) * 100 > 1
for: 1m
labels:
severity: warining
annotations:
description: Nginx high HTTP 5xx error rate ( namespaces {{ $labels.exported_namespace }} host {{ $labels.host }} )
summary: "Too many HTTP requests with status 5xx (> 1%)"
- alert: NginxLatencyHigh
expr: histogram_quantile(0.99, sum(rate(nginx_ingress_controller_request_duration_seconds_bucket[2m])) by (host, node)) > 3
for: 2m
labels:
severity: warining
annotations:
description: Nginx latency high ( namespaces {{ $labels.exported_namespace }} host {{ $labels.host }} )
summary: "Nginx p99 latency is higher than 3 seconds"
- alert: NginxHighRequestRate
expr: rate(nginx_ingress_controller_nginx_process_requests_total[5m]) * 100 > 1000
for: 1m
labels:
severity: warning
annotations:
description: Nginx ingress controller high request rate ( instance {{ $labels.instance }} namespaces {{ $labels.namespaces }} pod {{$labels.pod}})
summary: "Nginx ingress controller high request rate (> 1000 requests per second)"
- alert: SSLCertificateExpiration15day
expr: nginx_ingress_controller_ssl_expire_time_seconds < 1296000
for: 30m
labels:
severity: warning
annotations:
summary: SSL/TLS certificate for {{ $labels.host $labels.secret_name }} is about to expire
description: The SSL/TLS certificate for {{ $labels.host $labels.secret_name }} will expire in less than 15 days.
- alert: SSLCertificateExpiration7day
expr: nginx_ingress_controller_ssl_expire_time_seconds < 604800
for: 30m
labels:
severity: critical
annotations:
summary: SSL/TLS certificate for {{ $labels.host $labels.secret_name }} is about to expire
description: The SSL/TLS certificate for {{ $labels.host $labels.secret_name }} will expire in less than 7 days.4、导入Grafana 模版
Ingress-nginx 模板ID:9614、14314
5、总结
- Kube-prometheus 是一个用于在Kubernetes上运行Prometheus的开源项目
- 它利用Kubernetes 的自定义资源定义(Custom Resource Definitions,CDR)机制来定义和管理Prometheus实例
- 在Prometheus Operator中,Prometheus 实例、ServiceMonitor、Alertmanager、PrometheusRule等都是自定义资源
- 通过Prometheus Operator来自动化管理和更新Prometheus实例的配置
- 通过Kubernetes 的CRD来管理Prometheus 实例,而无需手动管理和维护Prometheus的配置文件。
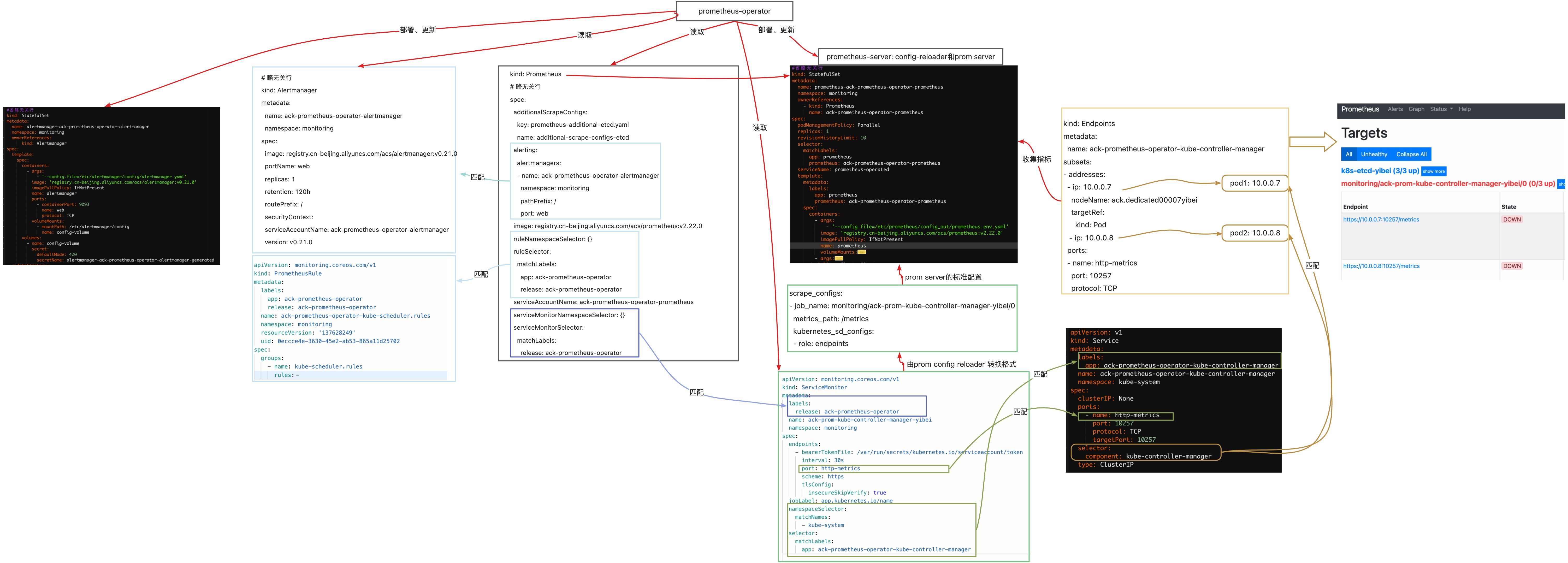
、
- Prometheus Operator 对象 7.13 7.14prometheus operator对象7.13 prometheus-operator prometheus容器operator体系 prometheus-operator servicemonitor prometheus prometheus大盘operator企业 prometheus exporter operator windows kube-prometheus prometheus operator简介 prometheus-operator集群prometheus operator prometheus-operator prometheus operator规则 customresourcedefinition operator对象 资源