Python 实现雪花算法
雪花算法:雪花算法是一种分布式全局唯一ID,一般不需要过多的深入了解,一般个人项目用不到分布式之类的大型架构,另一方面,则是因为,就算用到市面上很多 ID 生成器帮我们完成了这项工作。
介绍:Twitter 于 2010 年开源了内部团队在用的一款全局唯一 ID 生成算法 Snowflake,翻译过来叫做雪花算法。Snowflake 不借助数据库,可直接由编程语言生成,它通过巧妙的位设计使得 ID 能够满足递增属性,且生成的 ID 并不是依次连续的。
1.原理及介绍
Snowflake 是 Twitter 提出的一个算法,其目的是生成一个64位的整数;
64位的分布图如下图所示:
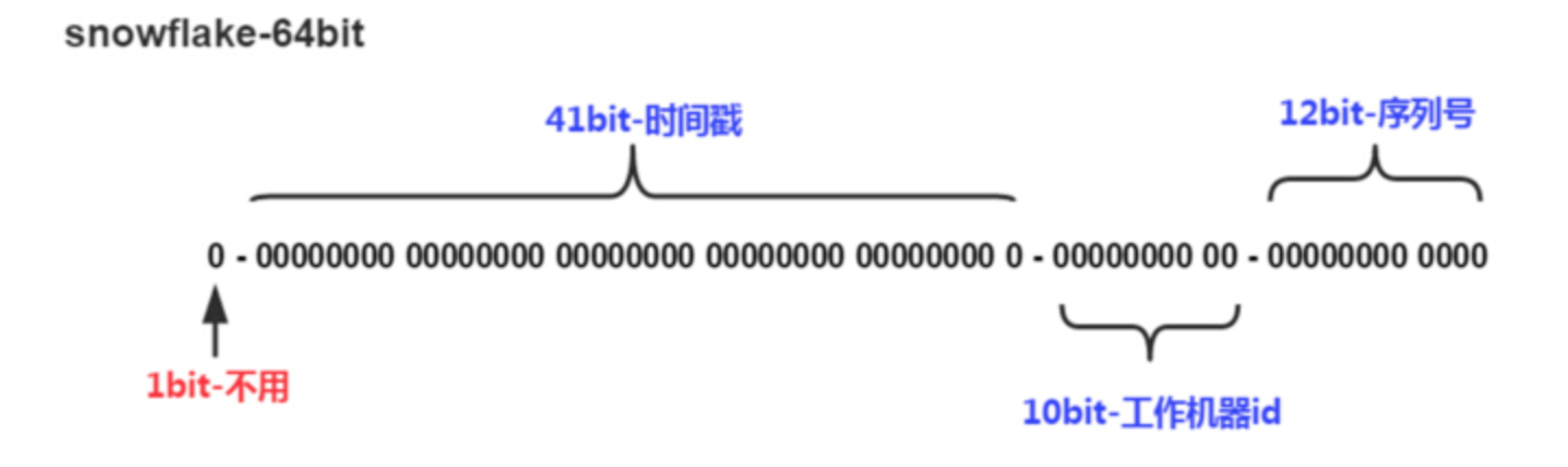
雪花算法
1 bit:一般是符号位,不做处理。
41bit : 用来记录时间戳,这里可以记录69年,如果设置好起始时间,比如今年是 2022 ,那么可以用到 2091 年,到时候怎么办,这个系统要是能够使用 69 年,估计系统早已经优化过很多次了。
10bit : 用来记录机器ID,总共可以记录1024台机器,一般用前5位代表数据中心,后面5位是某个数据中心的机器ID。(注:位数可以根据情况进行设定。)
12bit:循环用来对同一个毫秒内产生的不同的 ID,12位可以最多记录4095(212-1)次,多余的需要在下一毫秒进行处理。
上面是一个将64bit划分标准,当然也不一定这么做,可以根据不同的业务的具体场景进行行划分,例如:
服务目前QPS10万,预计几年之内会发展到百万。
当前机器三地部署,上海,北京,深圳都有。
当前机器10台左右,预计未来会增加至百台。
这个时候我们根据上面的场景可以再次合理的划分62 bit,QPS 几年之内会发展到百万,那么每毫秒就是千级的请求,目前 10 台机器那么每台机器承担百级的请求,为了保证扩展,后面的循环位可以限制到 1024,也就是2^10,那么循环位10位就足够了
机器三地部署我们可以用3bit总共8来表示机房位置,当前的机器10台,为了保证扩展到百台那么可以用7bit 128来表示,时间位依然是41bit,那么还剩下64-10-3-7-41-1 = 2bit,还剩下2bit可以用来进行扩展。

时钟回拨:因为机器的原因会发生时间回拨,雪花算法是强依赖时间的,如果发生时间回拨,有可能会发生重复ID,在我们上面的nextId中我们用当前时间和上一次时间进行判断,如果当前时间小于上一次的时间,那么肯定是发生了回拨,算法会直接抛出异常。
2.第三方包的使用
pip install pysnowflake下载包
snowflake_start_server --worker=1 启动服务
编写程序
from snowflake import client
client.get_guid()
