alias: Fan2023
tags: RetNet
rating: ⭐
share: false
ptype: article
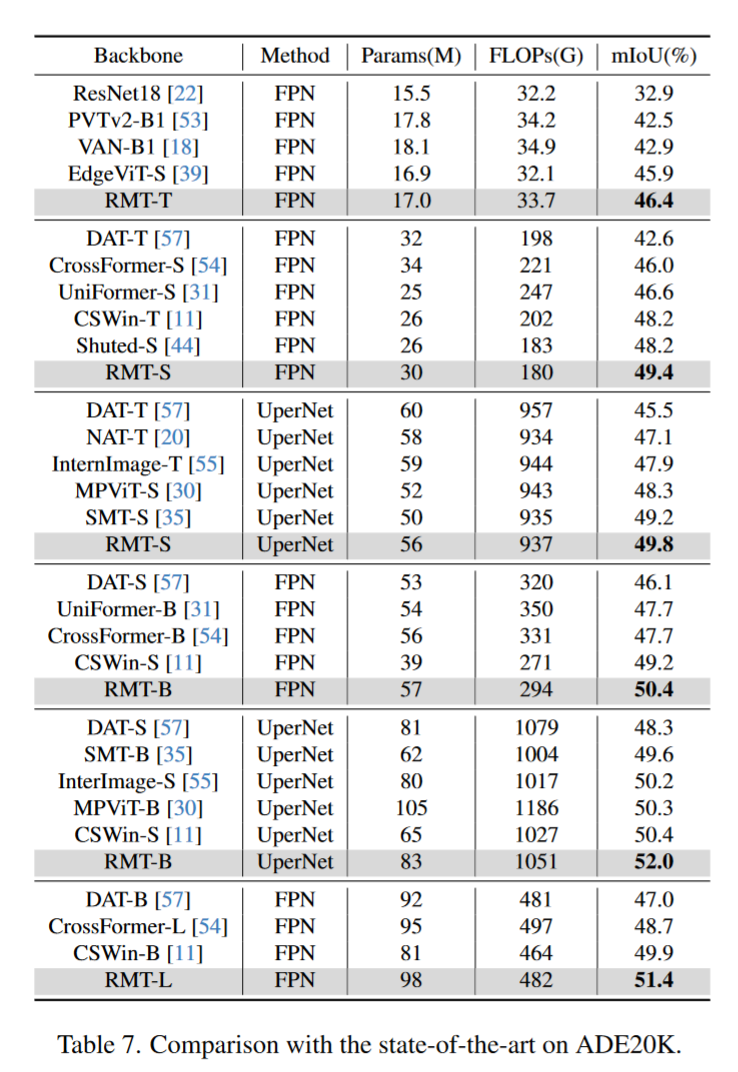
RMT: Retentive Networks Meet Vision Transformers
初读印象
comment:: (RMT)Retentive Network(RetNet)因其显式衰减机制而在自然语言处理中受到关注,但它不适合基于图像的任务。本文提出了保留性自我注意力 (reSA),这是一种专为视觉模型设计的双向二维显性衰减形式注意力。
Why
NLP中RetNet提高了推理速度。在 RetNet 中,显式衰减机制是专为语言数据设计的,表现为单向、一维的建模衰减过程,为模型提供了基于距离变化的先验知识。除此之外,RetNet 还采用了线性注意,用门激活取代了自注意中的softmax。这两个因素使 RetNet 具有很高的灵活性和良好的性能,使其能够通过三种操作形式适应并行训练和递归推理(自回归推理)的要求。
以上特点不能直接用于视觉模型,图像中的标记需要双向、二维建模。此外,虽然语言模型是并行训练的,但它们必须以顺序的方式用于自回归推理。这与视觉主干不同,后者在训练和推理过程中都使用相同的并行形式。
What
RetNet
RetNet以循环的方式考虑序列建模问题:
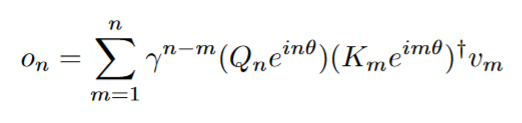 在为了并行训练,以上公式改为:
在为了并行训练,以上公式改为: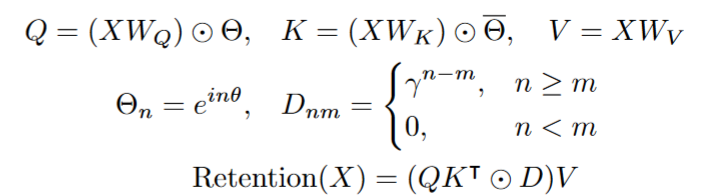
]
- 变量$θ_n$定义为$e^{inΩ}$,其中 i 是虚数单位,n 是参数,Ω 是一个常数。
- $D\in\mathbb{R}^{|x|\times|x|}$包含因果掩蔽和指数衰减:
- 如果 n 大于或等于 m,则 $d_{nm}$ 等于 $γ^ (n-m)$,其中 γ是衰减因子;否则, $d_{nm}$ 等于 0。
ReSA
去除因果
语言任务有因果性质,所以RetNet的保留是单项的,每个标记只能关注前面的标记,不能关注后面的标记。而图像任务没有标记关系。
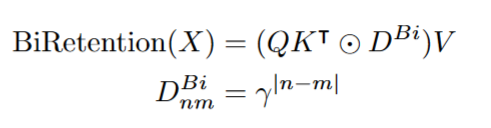 ####2D特化
####2D特化
使用曼哈顿距离作为2D的距离
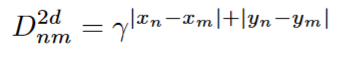
$(x_n, y_m)$是第n个点的坐标。
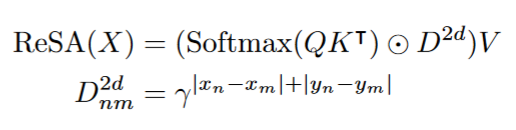 ####分解式ReSA
####分解式ReSA
前几个阶段中,视觉token太多了,复杂度比较高,因此提出分解ReSA为图像的两个轴。

最后加入局部信息
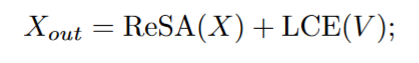
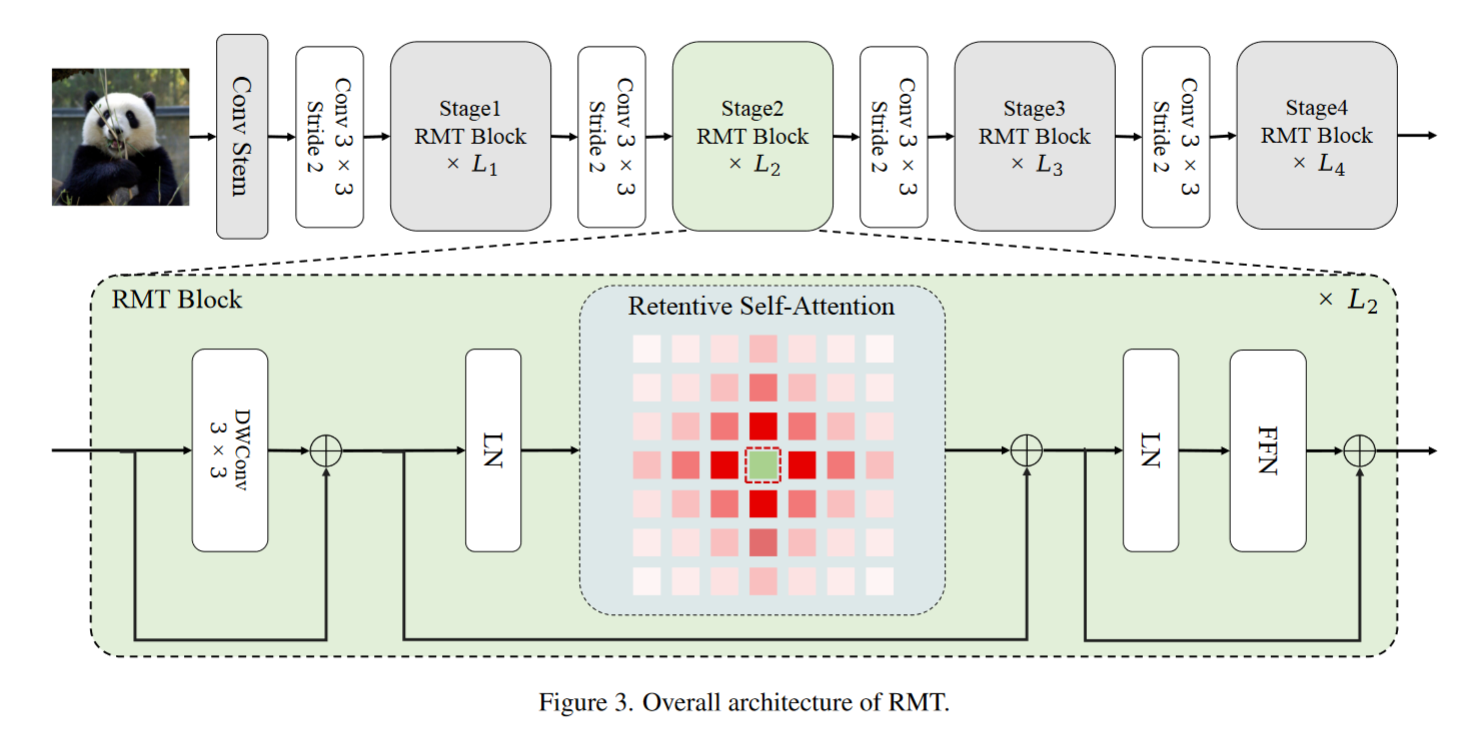
How