AI时代新的产品设计范式是什么
发布时间 2023-06-25 14:09:14作者: BOTAI
如果 99% 的软件会消失,要不要提前认命做个 API?
GUI 转化成 LUI,人人都想得到影响是易用性增加,比如不会 Excel 的人也可以通过下命令读表格作图。
不一定人人想得到的,是“意愿解读“(比如画个按钮让人按)和”功能实现“(比如画个图表)之间的解耦,让能力更容易被充分表达。比如 Excel 里 10000 个细微功能,但前端只有 100 个按钮位置(再多人类就学不会了),这样 99% 的功能不会被用到、不会被感知到——比如你只能问我和徐文浩 3 个固定的大模型技术问题,而且只允许我们回答 6 句话,会很难分辨谁技术比较强——能力被表达约束。但如果你可以抓着我俩敞开聊,10 分钟你就可以知道他懂我不懂。
如果“意愿解读”能力有限 & 要求专业,类似我们和每个人都只能问 3 道题,我们就会需要和很多人(软件)合作。但如果 LUI 提供了无限的、通用的”意愿解读“能力,我们还需要那么多人(软件)么?
但再进一步呢?GUI 其实是让用户走我们设计的迷宫,路径有限,知道用户会一步一步怎么走,所以我们很容易设计流程,后台开发也有可能会把很多小模块耦合在一起。但如果默认是 LUI 设计,允许用户东一榔头西一榔头提出需求,我们后台就会默认把能力颗粒度变细,然后一个一个解耦单独放出来(毕竟用户可能单拎这个功能用)。而如果颗粒化的能力,能够被单独调用,这不就是 API 么……
如果能力被细颗粒化 API 化,那么理论上就可以被内部外部广泛调用。同时,如果用户侧流量入口变成 AI Copilot 助理,有能力调用 API,理论上任何需求都可以通过调用成熟外部 API 组装出一个刚刚好的方案。这时,很多的软件和 SaaS 会消失,同时浮现一堆的 API 被 Copilot 调用(可能还会分钱)。类似一个城市,可能原本需要很多的便利店和超市,顾客想买什么东西可以去店里挑。但如果来了个大电商,直接细颗粒度提供便利店里也有的“商品”,而且可以做到 1 分钟送货上门,这样商品销售额可能会上升,但便利店可能要倒掉一片。
所以,其实现在存在一个思考路径,就是直接把自己当做商品,而不要去想门店的事儿。直接思考,自己对于世界来说,可以提供一个怎样的 API,创造怎样独一无二价值(独特的思考,独特的 action,独特的资源和能力),然后尽量让自己被更多次组装和调用。真的能做成入口平台的机会过于稀缺,做成被调用的能力集也不差——比如四通一达,肯定自己都有平台梦想,但现在基本上已经变成了被调用的 API,也不是不能接受。
我之前很喜欢 Web3 的一个概念是“可组合性”(Composability),很可能会在 AI 笼罩下的互联网世界先实现,这事儿挺妙。这时思考更多的不是人机交互界面,而是机机交互,我这个 agent 如何被主 agent 发现,如何被合理调度,如何获取商业价值……以及,为了交付好的结果,我应该如何主动去搜寻、评估和整合其他 agent。
类比来想,其实古典时代的软件更像是手工作坊,每一行代码、每一个零件都是手敲出来。而新时代的软件会更像是工厂,供应链协同几百个其他工厂,从别的工厂进货、自己加工、然后出货,而出的货可能又送往另一个工厂。大规模 agent 协作,相互调用标准化的能力,协同创造。
这样本质的变化过程中,机会在哪里呢?如果注定 99% 的软件会消失,要不要提前认命做个 API?
未来每一天,都会有 10 亿个新软件生成
Geoffrey Litt 的文章给了我很多启发。
之前,我考虑 AI 对产品设计的影响,主要是在考虑如何融合 GUI 和 LUI,比如把高频场景用 GUI、低频长尾场景用 LUI,以及用 GUI 做更多直觉引导约束之类。
但 Geoffery 给了一个不同的思考框架,有没有可能未来除了传统 GUI 和 LUI 之外,还有大量实时生成的 GUI 呢?
我们考虑 GUI 的时候,脑子里隐喻其实更像是操作一台机器,什么交互和功能都是固定的很不灵活,但约束和指引清晰。比如你用画笔(或者 ControlNet)表达构图,肯定比言更容易;比如我们开车的时候操作方向盘,就更容易和车子融入一体产生心流,要都用嘴皮子开车会累死。
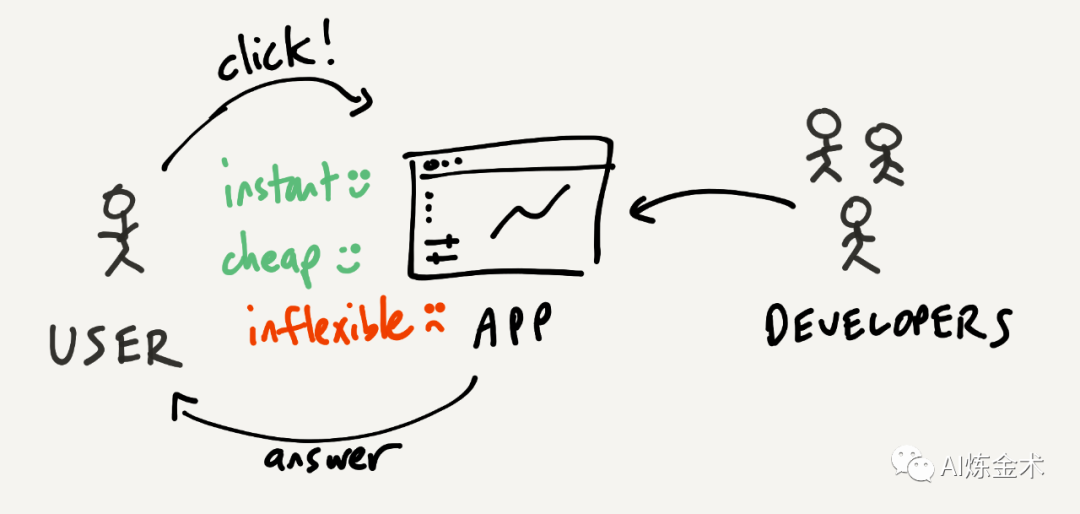
而我们考虑 LUI 的时候,脑子里隐喻其实更像是和一个顾问或者助理在沟通,约束和指引模糊,但非常灵活。比如你去店里买东西和店员聊天,不仅可以自由询问“有没有小一号”的这种 GUI 也很容易表达的问题,也可以聊“有没有类似这个款式,但是是白色的”。不一定有效率,但边界非常宽,门槛非常低。
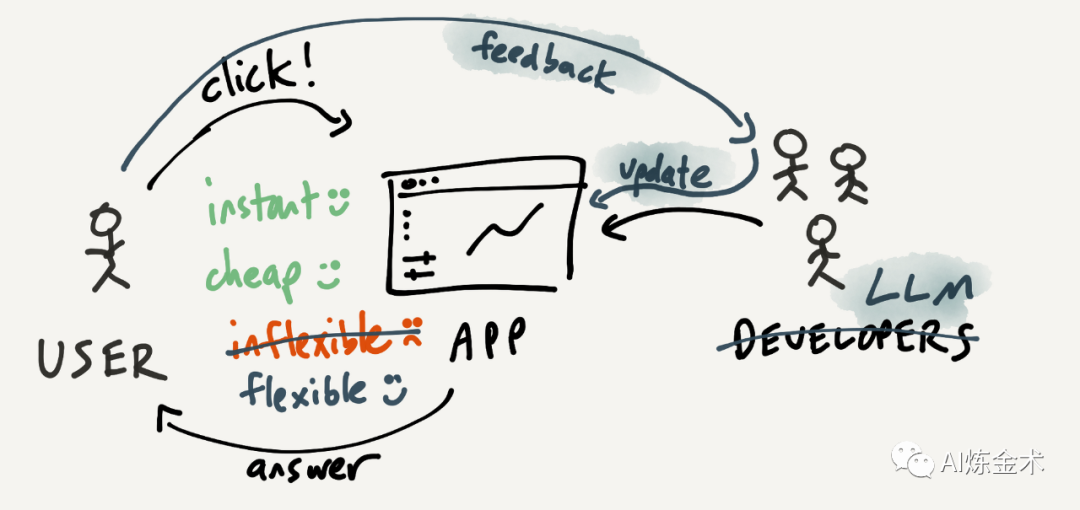
有没有可能结合两者,我们用 LUI 沟通的不是顾问,而是一个机器猫,每次不是直接帮我们解决问题,而是提供针对我这次任务的定制化道具(GUI)给我呢?
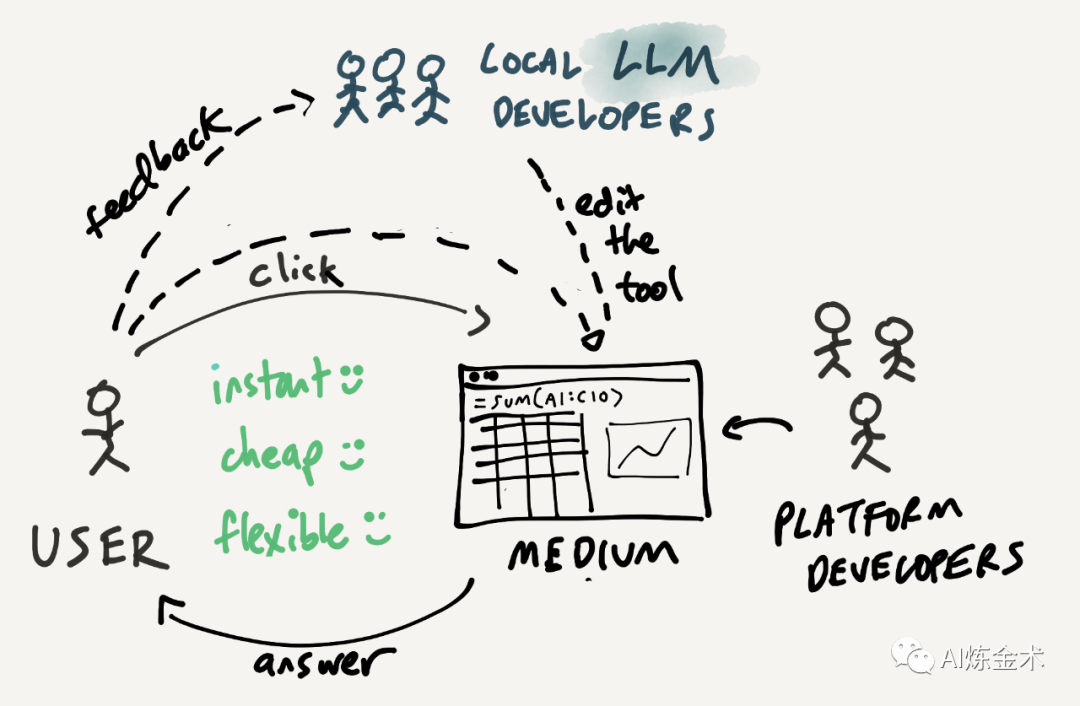
比如,现在的 SaaS 软件大部分都可以给不同角色配置不同的 Dashborad,这也可以理解为早期的定制化 GUI。如果极端到每一个人、每一个具体任务,只要是还需要用户后续摆弄摸索的,都提供一次性 GUI 呢?
从这个视角出发,AI-Native 的应用,不仅仅是应该在后台灵活组装 agent 的能力来交付结果,而且也需要在前台自适应创建大量一次性的、最适合完成这次单次任务 & 最适合这个用户的 GUI 方便用户使用。后台是一堆能力的乐高积木块,可以自由拼装,而且可以去网络上选择合适的第三方模块拼装进来;前台也是一堆 GUI 的乐高积木块,根据用户偏好和需求自由拼装,组装成最能够帮助用户达成目的的形态。
如果 GUI 交互界面可以快速生成、组装,那么理论上需要的软件或 SaaS 数量会大幅度减少。类似用 Notion 可以把一些简单的内部流程和 CMS 工具拼装出来,就会减少对专业工具需求。AI 创建新应用(GUI + 后台能力)比用 Notion 还要方便 100 倍,可能会进一步蚕食细分软件市场——为什么要买一个呢,自己生成一个就好呀,自己搞的还放心。换个比方,现在市面上餐厅五花八门,但如果有了完美的机器厨可以听懂客人的要求 & 拿后厨原料定制化炒菜,理论上所有餐厅就会同质化,大家去自己楼下餐厅就能吃到粤菜湘菜日本菜……市面上餐厅就会减少。
-
交互模式:什么情况下用默认 GUI,什么情况下用 LUI,什么时候成成一个一次性 GUI 给用户?
-
能力设计:如何解耦后台的能力,让 LLM 可以随时把能力拆解、重组形成一次性专业方案?
-
意图规范:用户如何和 LLM 交互来逐步清晰表达意图?
-
数据提取:如何识别模糊的意图,提取相应的、合适的数据来支持用户任务的完成?
-
用户赋能:什么时候应该用 Copilot 辅助用户,什么时候应该是 Autopiliot 帮忙直接搞定,什么时候应该是为用户生成专属 GUI 方便用户自己搞?
原来的 PM,很多时候只是写 PRD 和画交互的角色,但现在……活儿很重啊。
? https://www.geoffreylitt.com/2023/03/25/llm-end-user-programming.html?utm_source=bensbites&utm_medium=newsletter&utm_campaign=have-you-been-a-bard-boy
ChatGPT 之后,我们有一种倾向,就是把所有 UI 都设计成对话。
听了 Linus Lee 一个分享,很喜欢他的视角和框架:对话式 UI 给我们提供的是灵活性(flexibility),我们可以在其之上,用其他的 UI 来提高直觉性(intuitive)和易用性(easy to use),不要用一个对话框解决所有问题。
首先,哪怕我们认为就应该用对话式 UI,也不应该局限在 ChatGPT 模式上。因为 ChatGPT 的对话,和现实中对话相比有一个显著不同,就是缺乏上下文(context)。比如两个人面对面喝咖啡,一人看了一眼甜品柜,转头和朋友说”再来个拿破仑怎么样?“,她朋友大概率能 Get 到是问她要不要拿破仑蛋糕,而不是忽然要讨论历史问题;又比如你在一家公司工作了 3 年,多少都能有点了解你老板性格,比如她特别讨厌细节,那么当她要你“给我邮件说一下 X 项目进展”,你会默认只写要点。
ChatGPT 的上下文窗口很小(Claude 100k 虽然看起来很大,但我试下来体验也很糟),这就导致对话时其实要做“每次表达时要把所有信息(背景,偏好,前情提要……)都塞进来”的假设,这就很让人无语。
真实设计时,哪怕我们仍然以对话为 UI,我们也可以更多把上下文信息包含进去,比如用户正在什么软件里,打开了什么文档(当用户说”把这个文档发给 XX“的时候,至少知道”这个文档“是什么),鼠标在哪里,选择了什么(当用户想要改写一段话的时候,用鼠标选择这段话然后让 AI 改,比用嘴讲清楚到底是哪一段要更轻松)。
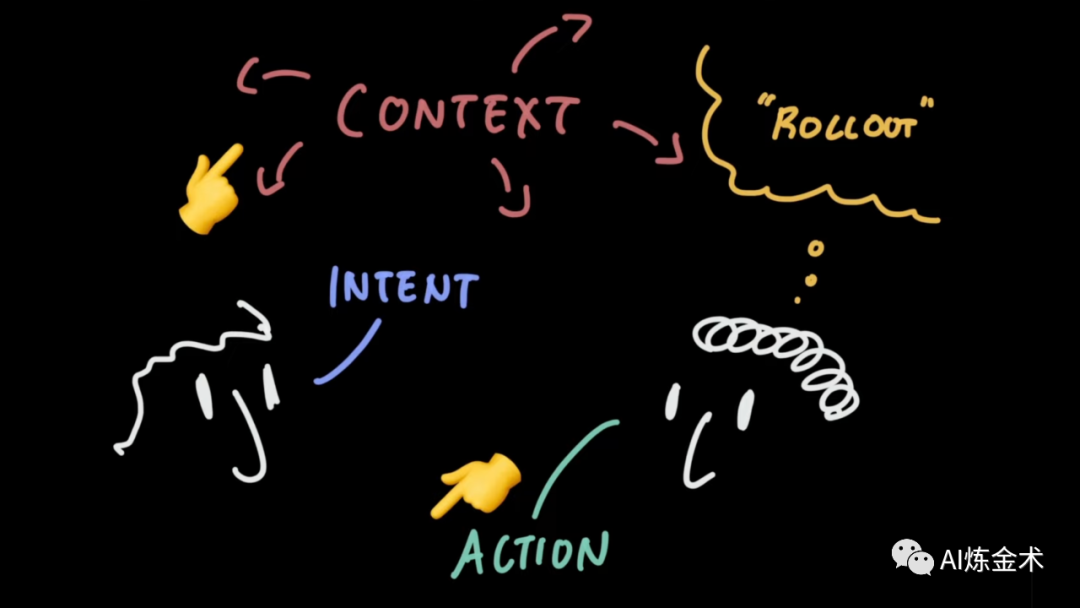
一次交互过程,不仅是你一句我一句对话,而应该拆解成 4 个部分:
-
-
上下文(context):解读用户指令和决定的场景相关信息
-
-
而在这个过程中,Linus 提示了一个很有意思的表达形式:名词,然后动词。
先在上下文中,把需要操作的对象标识出来(point and select),然后再看我们要对其做什么动作(action)。如果用其他 UI 标识更直觉、更方便(比如用鼠标选一段话,用相机拍摄一页书,把文件拖到框里,群里@一个人),如果用其他 UI 来展示动作更方便(比如右键菜单,比如命令行补全),就用啊。
Linus 觉得 LUI 增加了灵活性,但是降低了直觉性。具体来说,LUI 在给人直观引导方面,仍然有不如 GUI 的地方,比如初级用户面对一张白纸会很迷茫,不知道自己可以做什么。直接 LUI 的学习曲线过于陡峭,什么都有赖于用户的主动发现,这不是好的 onboarding 过程。GUI 给了更多的限制,但也让选项和路径明显,大家上手会更轻松。
而除了行动本身之外,也可以用其他的 UI 方式来闭环。比如给用户多个产出物选择(Midjourney 和 Jasper Template 都会产出多个结果让用户选),比如给用户更多后续交互提示(比如 New Bing 在 Chat 后浮现推荐的后续问题,比如百度里搜索美元汇率会出现 GUI)。
总的来说,Linus 认为一个好的对话式界面应该:
-
在 workspace 里有 agent(我的理解是能感知上下文)
-
充分利用丰富的共有上下文(最好是不用说话,就能知道我啥意思)
-
有一个让人愉悦的路径引导(不指望用户对着白纸搞清楚怎么用,能一步步引导用户掌握玩法)
-
搞不定了,总有对话框可以兜底(因为对话灵活,就类似客服电话里”按 0 呼叫人工坐席”)
-
把交互闭环掉,加快迭代进化(这也是应用积累壁垒的一种可能性)
AI 原生的产品设计,并不是说“加个 LLM 对话框做 Copilot”,而是需要基于 LLM 能力和限制,重新设计能力和交互,帮助用户完成他的 JTBD。
?? https://www.youtube.com/watch?v=rd-J3hmycQs