分布式计算模式之MR
MapReduce就是将复杂的、难以直接解决的大问题,分割为规模较小的、可直接解决的小问题。这些子问题相互独立且和原问题形式相同,可递归地求解,然后将子问题的答案合并。核心步骤为 1.分解原问题 2.求解子问题 3.合并解
工作原理
Map对应分,Reduce对应合。主要包括3种组件:
- Master:负责分配任务,协调任务运行,为Mapper分配map()函数,为Reducer分配reduce()函数
- Mapper worker:负责Map函数功能,即执行子任务
- Reducer worker:负责Reduce函数功能,即汇总各个子任务结果
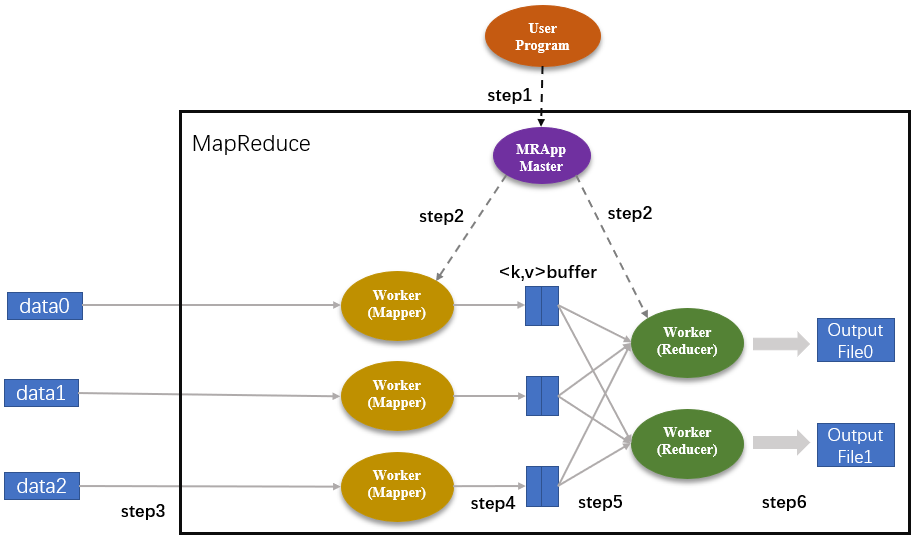
- 用户程序下发到MRAppMaster种,然后拆分为3个map子任务,2个reduce子任务;集群内MRAppMaster和worker节点都要任务的副本
- Master分别为Mapper和Reducer分配响应的Map和Reduce作业。作业数等于对应的子任务数
- 分配Map作业的Worker开始读取子任务的输入并抽取<key,value>键值对,传递给map函数
- map函数的输出存在环形缓冲区kvBuffer中,结果定期写入磁盘,存储在R个不同磁盘区。这里的R表示Reduce的作业数,图中为2,每个Map结果存储的位置都会上报MRAppMaster
- Master通知Reducer它负责的作业在哪个分区,Reducer远程读取中间键值对,通过排序使key相同的键值对聚集在一起
- Reducer将key相同的键值对合并,将统计结果作为输出存入分区
- MRAppMaster将R个分区的输出文件返回给用户程序,也可交给另一个MapReduce处理
可见MapReducer的工作流程主要分为5个阶段: Input、Splitting、Mapping、Reducing、Final Result
实践应用
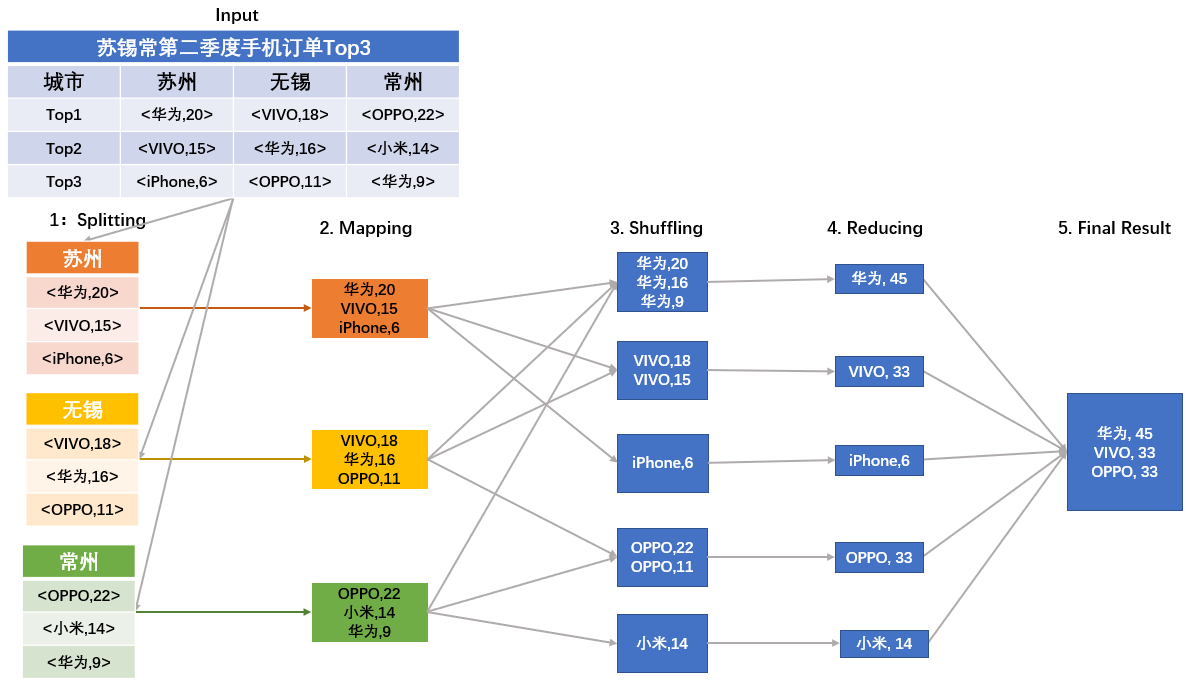
统计3个城市top3的手机品牌
- Splitting:根据地理位置划分
- 循环调用map()函数,统计每个品牌手机订单数,key为手机品牌,value为手机购买台数
- Suffling:读取Mapping阶段结果,将不同结果划分到不同区。这个阶段要对得到的结果进行排序整合才能执行下一阶段操作
- Reducing:归并同一品牌的购买次数
- 得到结果
Map/Reduce 作业和 map()/reduce() 函数是有区别的
- Map阶段是由一定数量的Map作业组成,是操作重复的并行任务。每个Map阶段的功能主要由map()函数实现。每个Map作业处理一个子任务要调用多次map()函数
- Reduce阶段是汇总任务结果,遍历Map阶段的结果而返回一个综合结果。reduce() 函数输入是一个key和对应的一组value,将key相同的数据合并。Reduce处理分区中间键值对是对每个不同key调用一次reduce()函数。
Fork-Join 计算模式
java提供的多线程并行处理框架,采用线程级的分而治之的计算模式。Fork阶段以递归方式将一个任务拆分为多个小任务放到cpu上处理;Join阶段将结果合并得到原始任务结果。但Fork-Join不能拓展,只适用于单个Jvm,多个小任务可相互通信,甚至“窃取”其他线程上子任务。MapReduce可大规模拓展,可跨计算机执行,各个小任务间不相互通信。
一个MapReduce的例子
use std::{collections::HashMap, thread};
fn main() {
let data = "86967897737416471853297327050364959
11861322575564723963297542624962850
70856234701860851907960690014725639
38397966707106094172783238747669219
52380795257888236525459303330302837
58495327135744041048897885734297812
69920216438980873548808413720956532
16278424637452589860345374828574668";
let mut join_vec = vec![];
let chunked_data = data.split_whitespace();
for (i, segment) in chunked_data.enumerate() {
join_vec.push(thread::spawn(move || -> HashMap<u32, i32> {
let mut map = HashMap::new();
segment.chars().for_each(|c| {
let num = c.to_digit(10).expect("should be digit");
match map.get_key_value(&num) {
Some((&k, &v)) => {map.insert(k, v + 1);}
None => {map.insert(num, 1);}
}
});
println!("thread {i} get result: {:?}", map);
map
}));
}
let mut final_result = HashMap::new();
join_vec.into_iter().for_each(|res| {
match res.join() {
Ok(map) => {
map.iter().for_each(|(&k, &v)| {
match final_result.get(&k) {
Some(old_result) => {
final_result.insert(k, v + old_result);
},
None => {
final_result.insert(k, v);
},
}
});
},
Err(err) => {
println!("thread fail: {:?}", err);
},
}
});
println!("final result: {:#?}", final_result);
}
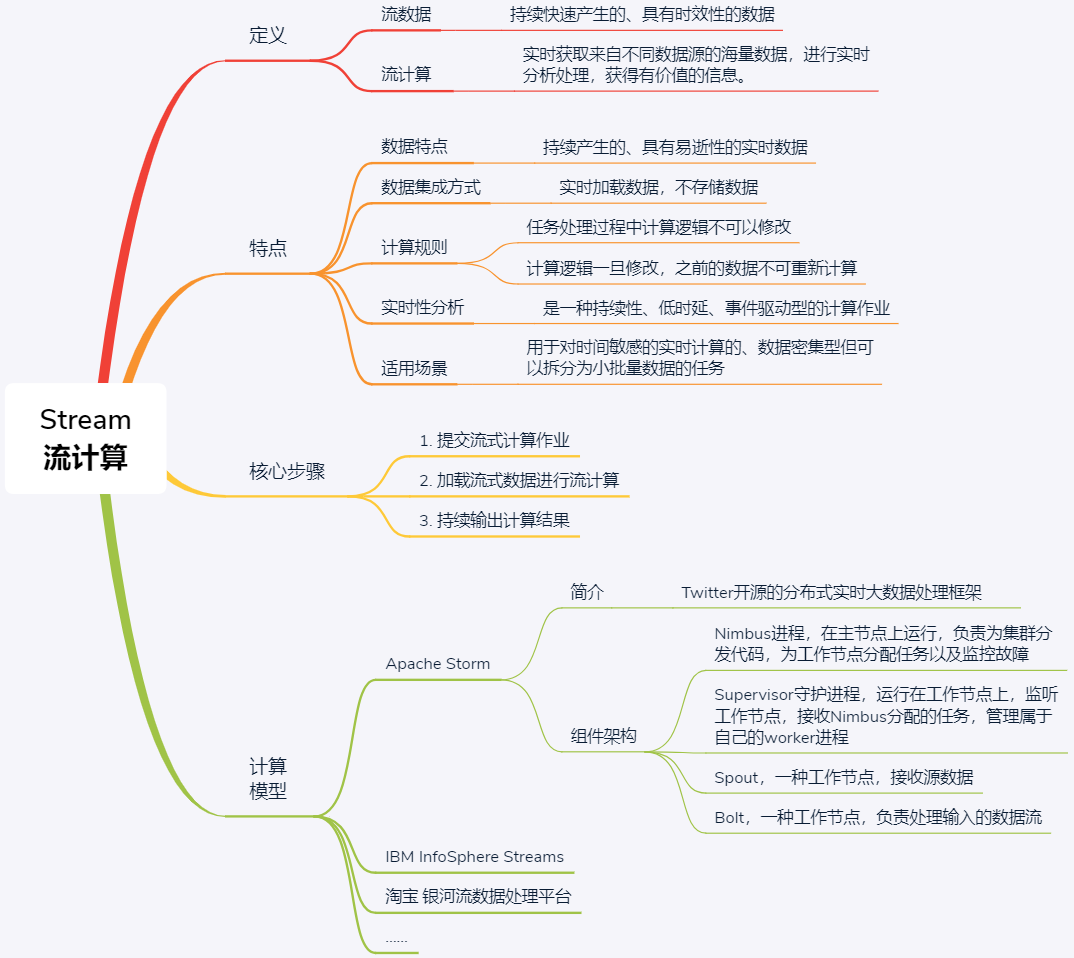
分布式计算模式之Stream
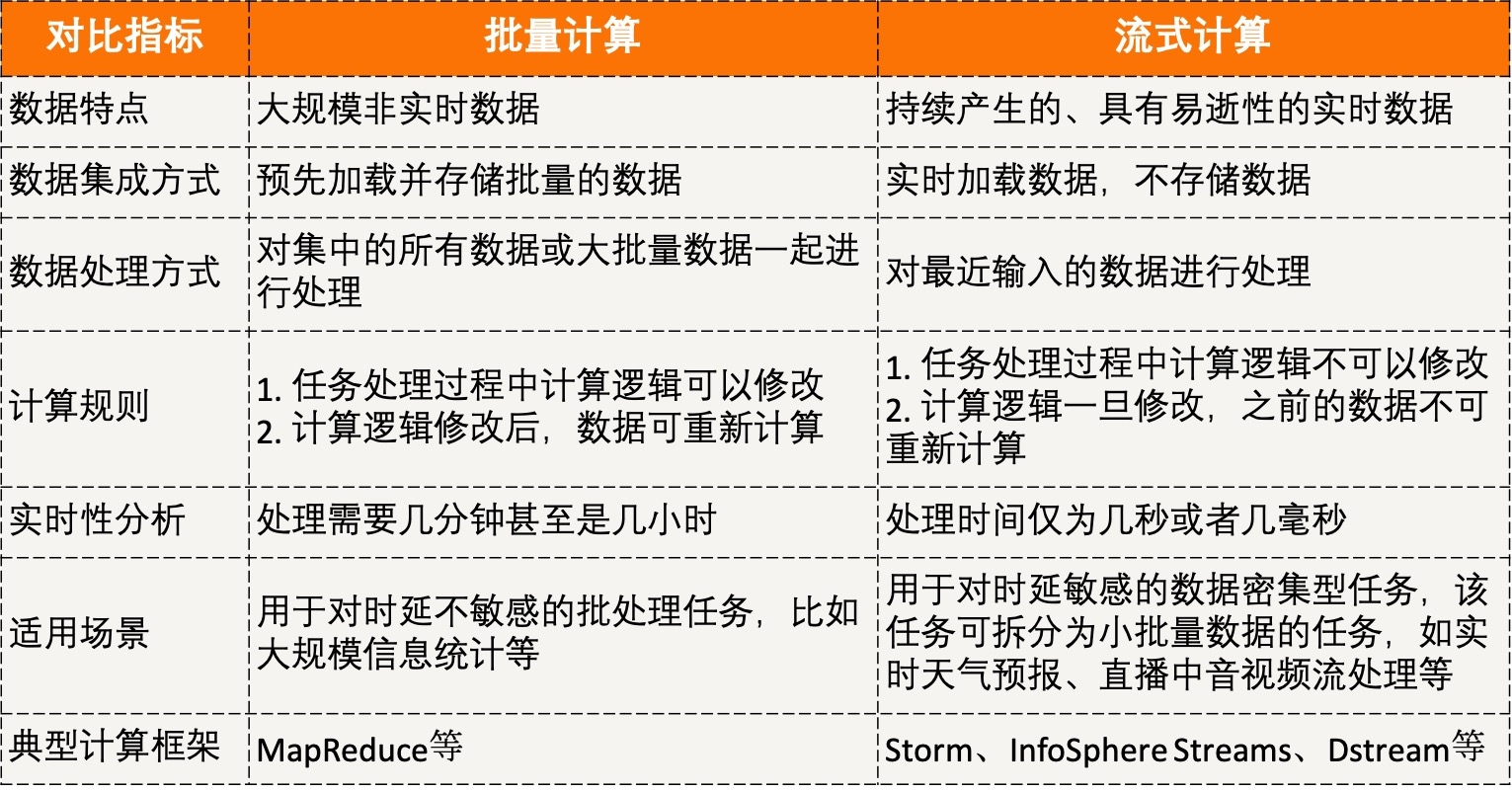
实时性任务针对流数据的处理,对处理时延要求很高,通常需要常驻服务进程,等待数据的随时到来并处理,以保证低时延。流数据的特征主要有:持续快速地到达;海量规模;实时性要求高;数据顺序无法保证。流式计算常用于数据密集型应用。流式计算属于持续性、低时延、事件驱动型计算作业。
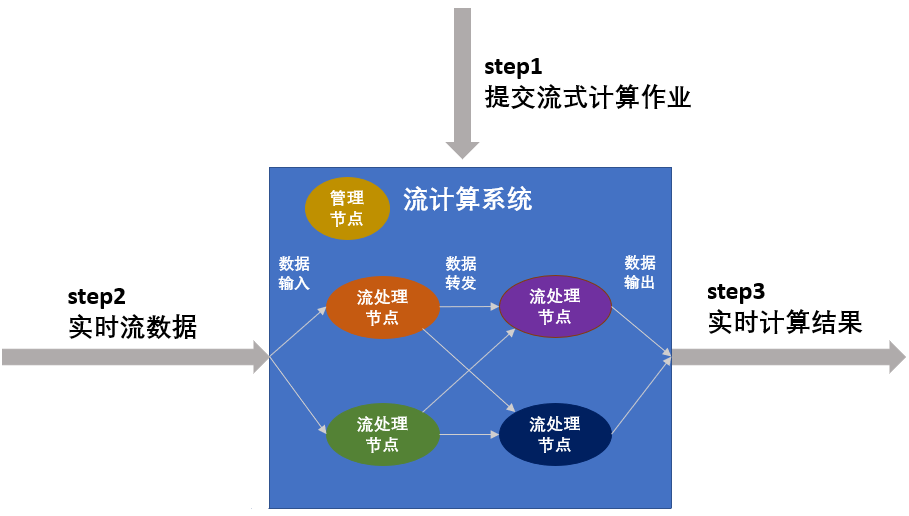
- 提交流式计算作业。要预定义逻辑,执行期间无法修改逻辑,暂停服务时无法存储流式数据
- 加载流式数据进行就是计算。有管理节点负责节点和任务的流动规则,节点个数与转发规则都在第一步提交
- 持续输出计算结果。
Storm 介绍
Storm上运行的是“计算拓扑”(Topologies),该逻辑永远在集群执行。有两种节点:master和worker
- master上运行名为“Nimbus”的守护进程,负责为集群分发代码,为worker分配任务与故障监控。一个Storm集群中只有一个Nimbus进程在工作
- worker上都运行名为“Supervisor”的守护进程,监听机器上的工作,接收Nimbus分配的任务,每个工作进程都执行一个子任务。一个正在运行的拓扑任务是由分布在许多计算机上的许多工作进程组成的
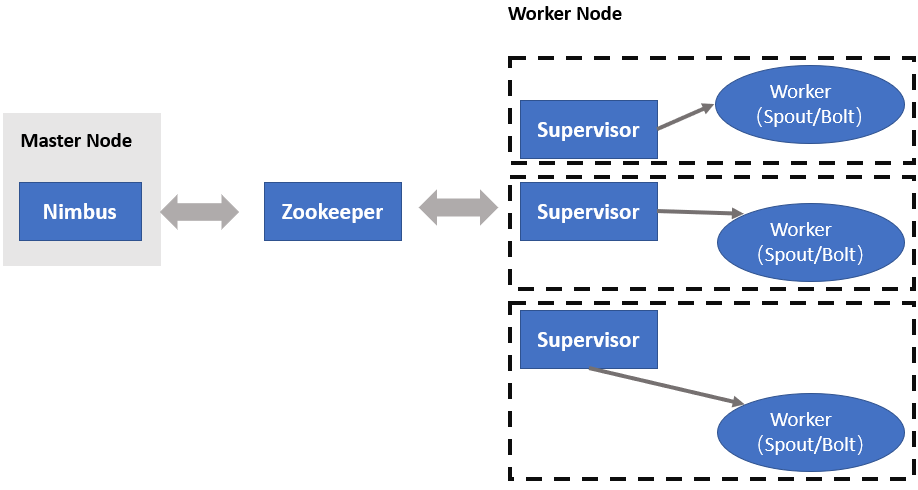
Nimbus和Supervisor通过zookeeper进行交互,Supervisor接收到任务分配的任务后,启动工作节点上Worker进程执行任务,一个计算任务可分为任务数据的读取和执行,Worker的两个组件分别为Spout和Bolt。要处理的数据被抽象为数据流,是一个无界序列,是分布式环境中并行创建、处理的一组元组。数据流可由域(fields)定义。spout和bolt运行用户自定义的功能。Storm上运行的计算拓扑是由一系列spout和bolt组成的有向无环图
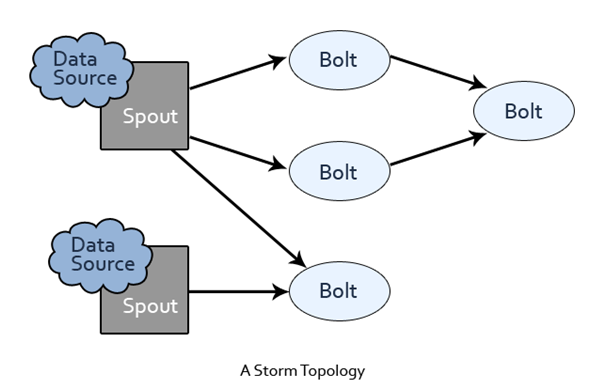
- Spout:接收数据源
- Bolt:处理数据,如filtering、functions、aggregations、joins等,得到的结果可传入下一个Bolt。
分布式计算模式之Actor
从计算过程或处理过程的维度,有Actor和流水线模式。用于维护每个进程间的数据、状态等信息。
Actor与面向对象的编程思想类似,封装了状态和行为,其他Actor无法直接观察、调用它。多个Actor通过消息进行通信,这种消息类似电子邮箱中的邮件,Actor收到消息后根据它执行。Actor模型定义了一套规则,定义了内部的计算逻辑与多个Actor间的通信规则。OOP中,当多个外部对象调用一个方法时可能导致死锁、竞争等问题,而Actor模型的消息通信是异步的,适用于高并发的分布式系统。正是因为异步执行,无法确定消息执行顺序。
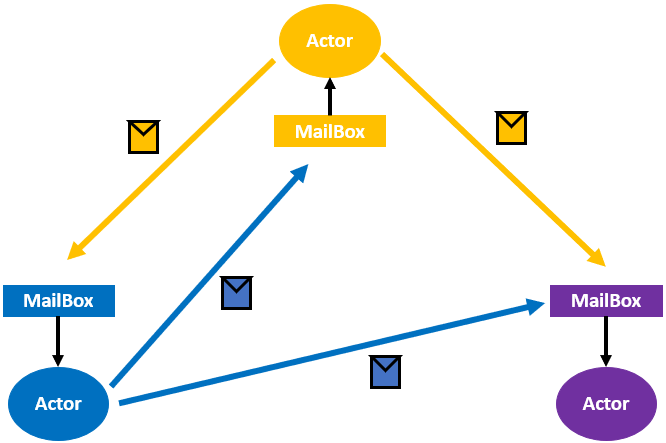
- 状态(State):Actor本身的信息,类似OOP对象中的属性,只有自己能够修改
- 行为(Behavior):Actor的计算处理操作,类似OOP的方法,只有收到消息时才会触发
- 消息(Mail):Actor间的通信方式,每个Actor都有自己的邮箱,一般按照FIFO进行处理
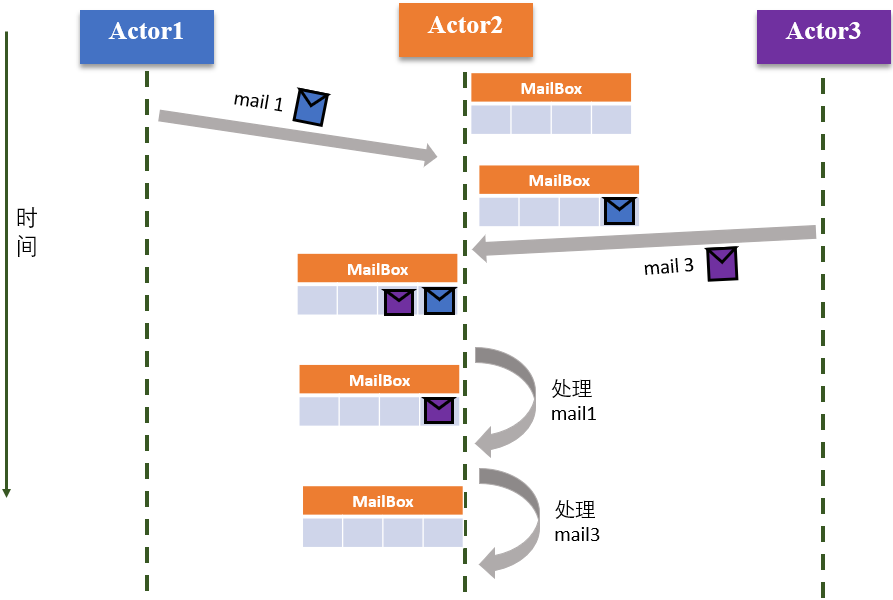
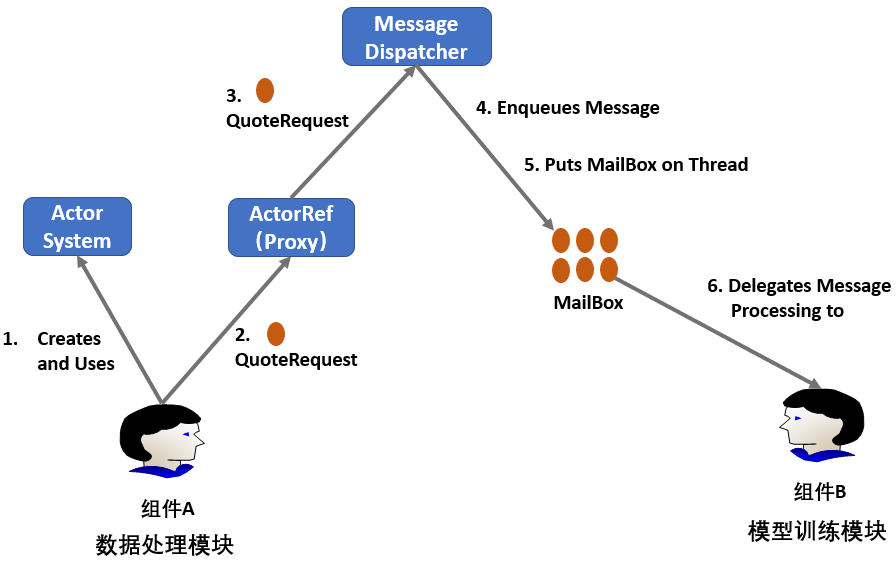
系统中不同组件/模块可视为不同Actor,例如某个神经网络应用的模块可视为组件A和B,训练过程中通过传递消息进行传递:
- A创建 Actor System,用于创建并管理多个Actor
- A创建一个消息并发给ActorRef,其是B对应Actor的一个代理
- ActorRef将消息传给Message Dispatcher 模块。其类似中转站,负责接收和转发消息
- Message Dispatcher 将消息加入B的MailBox的队尾
- Message Dispatcher 将MailBox加入线程线程。只有当MailBox是线程时,才能处理MailBox中的消息(不太懂???)
- B取出MailBox的队首消息并处理
Actor 关键特征
- 更高级抽象
- 非阻塞性
- 无需使用锁
- 并发度高
- 易拓展
不足:
- 提供了模块和封装,但缺失继承和分层。重用性小
- 可动态创建多个Actor,使得整个Actor模型的行为不断变化,在工程中不易实现,且会增加系统开销
- 无法保证消息顺序执行。因为所有消息都是异步,可通过阻塞Actor解决顺序问题,但这会影响效率
Akka集群如何检测Actor节点故障
集群中每个节点计算一个哈希值,组成哈希环选择相邻的k个节点作为监控节点。每个节点被k个监控节点监控,当某个监控节点发现其不可达时将其标注,通过Gossip传递给其他节点。
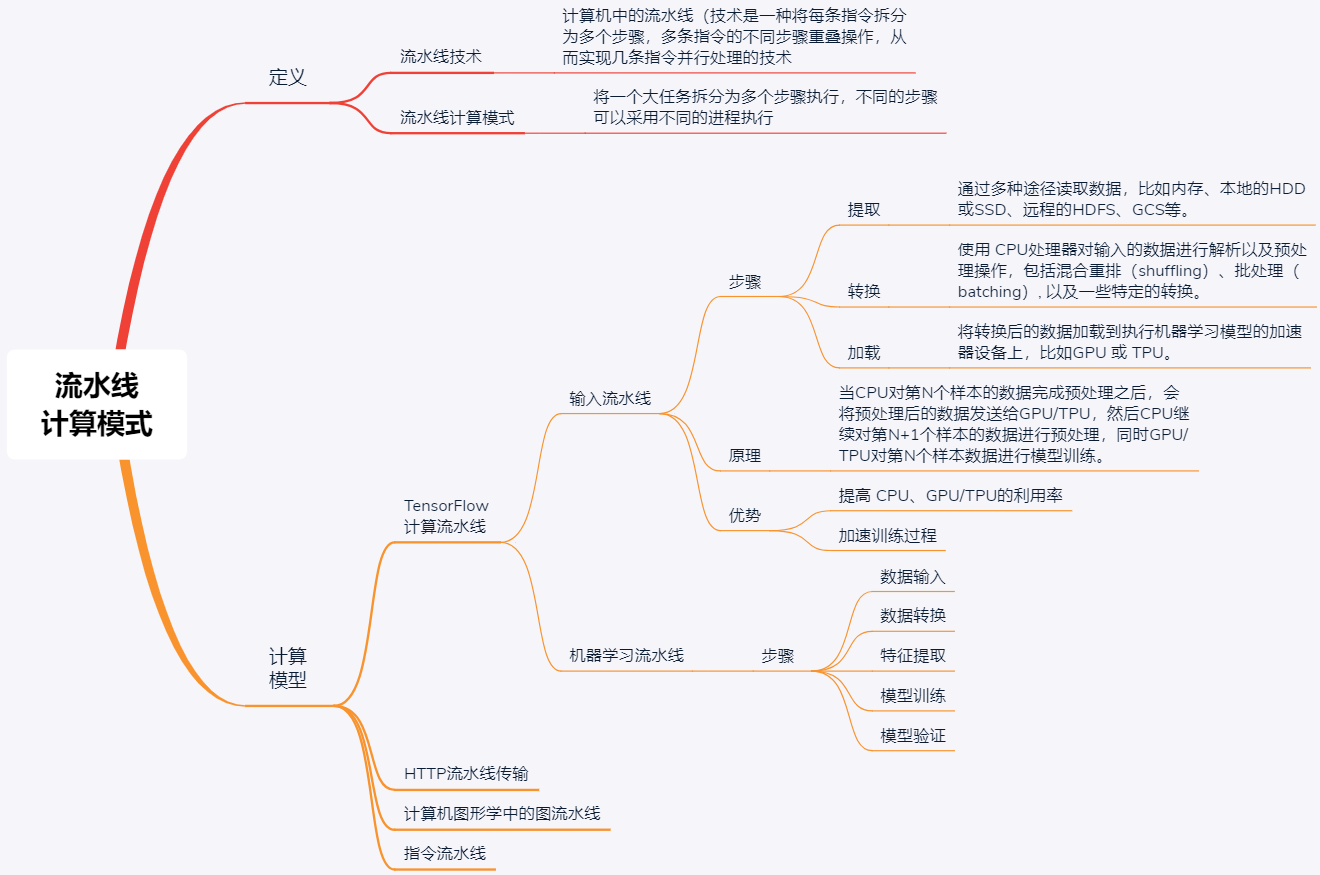
分布式计算模式之流水线
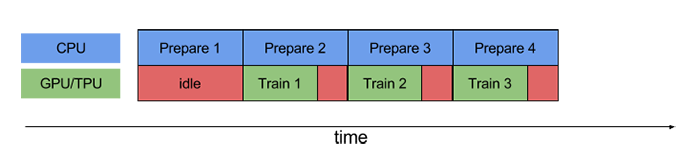
将一个大任务拆分为多个步骤执行,不同步骤采用不同进程执行,不同任务并行执行可提高效率。TensorFlow用流水线模式进行数据预处理,因此也称为 TensorFlow Training Input Pipelines。其主要包含3个步骤:
- 提取(Extract)
- 转换(Transform)
- 加载(Load)
也被称为ETL流水线,利用简单、可重用的数据片段构建负责的输入流水线。执行训练步骤,首先要提取并使用CPU转换数据,然后将其提供给GPU或TPU上运行的模型。不使用流水线如下:
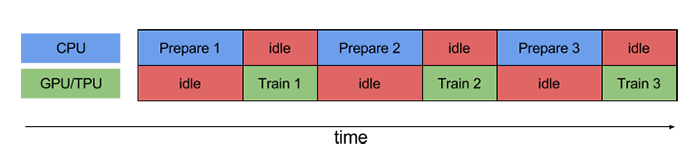
使用流水线: