完整代码
import requests import time import pandas as pd url = 'https://www.globalsources.com/api/gsol-trade-show-bff/hk-online/v1/search-all-exhibitors' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36', 'Sensorsid': '$device_id=18b3bbff2979e5-093596827e477f8-26031e51-1327104-18b3bbff298123a', 'Referer':'https://www.globalsources.com/trade-fair/hongkongshow/fashion?source=OS_HK_HP_TopTab', 'Sec-Ch-Ua-Mobile':'?0', 'Sec-Ch-Ua-Platform':"Windows", 'Sec-Fetch-Dest':'empty', 'Sec-Fetch-Mode':'cors', 'Sec-Fetch-Site':'same-origin' #可以加1个cookie,但是因为这个cookie是变化的,如果固定,爬到的数据就是有限的 } data = [] for page in range(1, 11): # 循环获取 1 到 10 页的数据 payload = { "categoryCode": "LIFESTYLE_FASHION_1", "pageNum": page, "pageSize": 40, "searchKey": "" } response = requests.post(url=url, json=payload, headers=headers) if response.status_code == 200: text = response.text try: json_data = response.json() for item in json_data['data']['list']: name = item['supplier'].get('companyName') boothid = item['boothId'] data.append([name, boothid]) except ValueError as e: print('解析json数据失败:', e) print('响应内容:', text) time.sleep(2) #for i,item in enumerate(data): #print(f"{i+1},{item[0]}, {item[1]}") df = pd.DataFrame(data, columns=['公司名', '展位']) df.to_excel('香港展会公司名单.xlsx', index=False) print("香港展会公司名单.xlsx 文件中。")
1、网址:https://www.globalsources.com/
2、这是一个post请求;
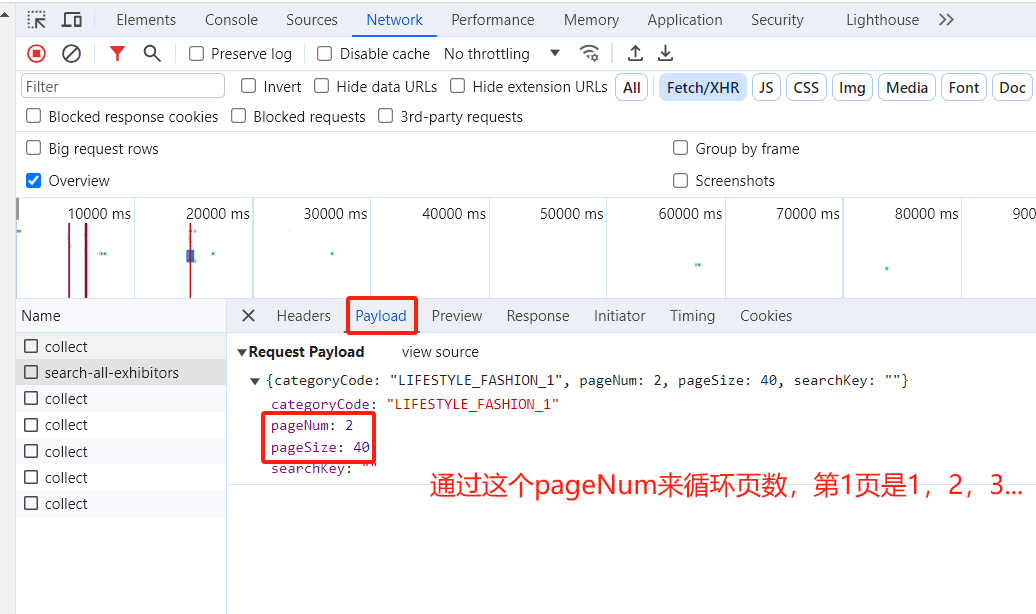
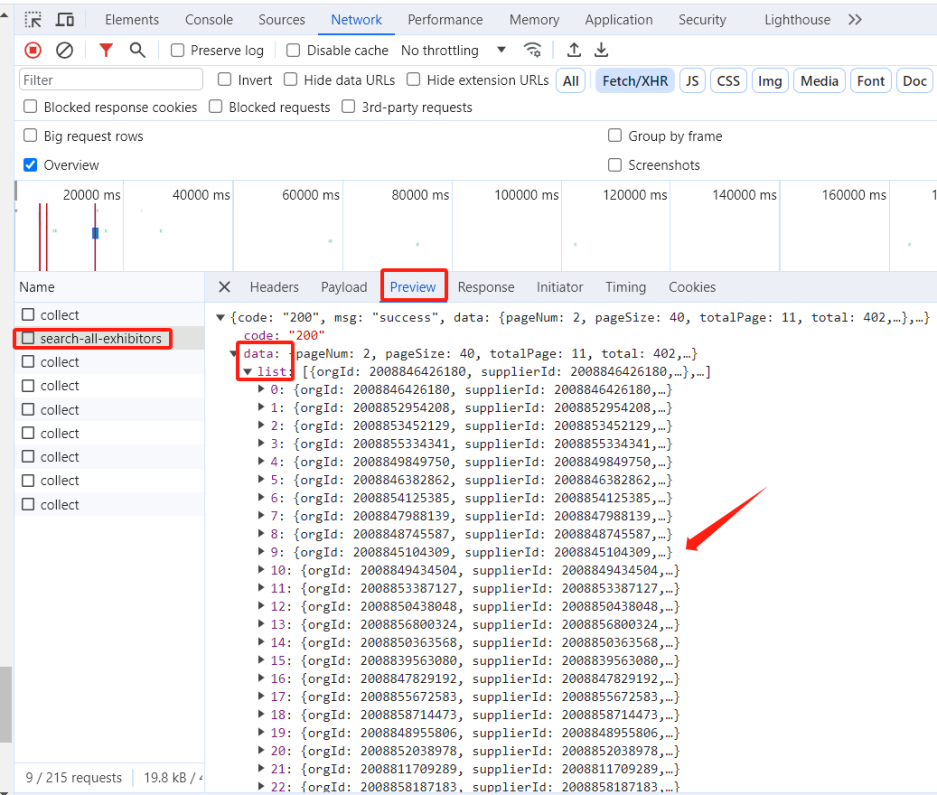
3、通过观察Python 爬虫中循环遍历多个页面,但是页面数没有直接体现在 URL 中,而是通过请求参数 payload 进行传递,所以要在payload中循环;
4、这里面有反爬机制,要封装好header头,把一些参数都放上去,本来要放cookie值的,但是这个cookie是有限的,试了一下固定cookie,但是只能爬到3页的数据。所以就没有固定Cookie;
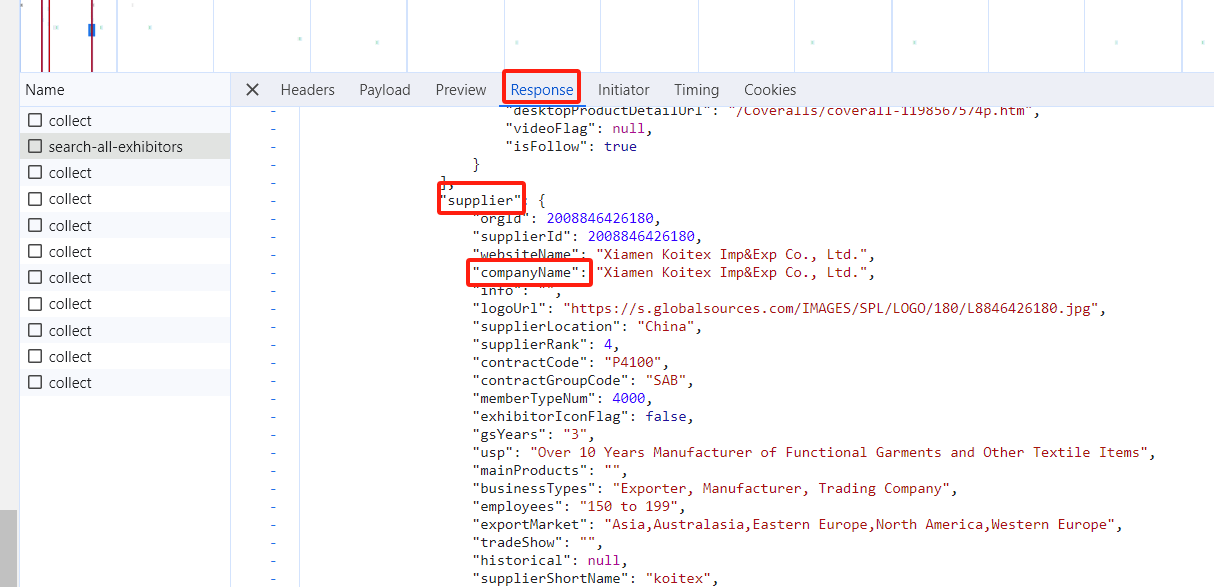
5、客户名称的值在companyNamename里面,上一层是supplier,所以写法为name = item['supplier'].get('companyName');展位取值写法为boothid = item['boothId']