Scipy
介绍
SciPy 是一个开源的 Python 算法库和数学工具包。
Scipy 是基于 Numpy 的科学计算库,用于数学、科学、工程学等领域,很多有一些高阶抽象和物理模型需要使用 Scipy。
SciPy 包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。
应用
Scipy 是一个用于数学、科学、工程领域的常用软件包,可以处理最优化、线性代数、积分、插值、拟合、特殊函数、快速傅里叶变换、信号处理、图像处理、常微分方程求解器等。
SciPy 包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。
NumPy 和 SciPy 的协同工作可以高效解决很多问题,在天文学、生物学、气象学和气候科学,以及材料科学等多个学科得到了广泛应用。
安装
python3 -m pip install -U pip
python3 -m pip install -U scipy
验证安装:
import scipy
print(scipy.__version__)
模块列表
以下列出了 SciPy 常用的一些模块及官网 API 地址:
| 模块名 | 功能 | 参考文档 |
|---|---|---|
| scipy.cluster | 向量量化 | cluster API |
| scipy.constants | 数学常量 | constants API |
| scipy.fft | 快速傅里叶变换 | fft API |
| scipy.integrate | 积分 | integrate API |
| scipy.interpolate | 插值 | interpolate API |
| scipy.io | 数据输入输出 | io API |
| scipy.linalg | 线性代数 | linalg API |
| scipy.misc | 图像处理 | misc API |
| scipy.ndimage | N 维图像 | ndimage API |
| scipy.odr | 正交距离回归 | odr API |
| scipy.optimize | 优化算法 | optimize API |
| scipy.signal | 信号处理 | signal API |
| scipy.sparse | 稀疏矩阵 | sparse API |
| scipy.spatial | 空间数据结构和算法 | spatial API |
| scipy.special | 特殊数学函数 | special API |
| scipy.stats | 统计函数 | stats.mstats API |
更多模块内容可以参考官方文档:https://docs.scipy.org/doc/scipy/reference/
scipy常量模块
SciPy 常量模块 constants 提供了许多内置的数学常数。
圆周率是一个数学常数,为一个圆的周长和其直径的比率,近似值约等于 3.14159,常用符号 \(\pi\) 来表示。
以下输出圆周率:
from scipy import constants
print(constants.pi)
以下输出黄金比例:
from scipy import constants
print(constants.golden)
我们可以使用 dir() 函数来查看 constants 模块包含了哪些常量:
from scipy import constants
print(dir(constants))
单位类型
常量模块包含以下几种单位:
-
公制单位
国际单位制词头(英语:SI prefix)表示单位的倍数和分数,目前有 20 个词头,大多数是千的整数次幂。 (centi 返回 0.01):from scipy import constants print(constants.yotta) #1e+24 print(constants.zetta) #1e+21 print(constants.exa) #1e+18 print(constants.peta) #1000000000000000.0 print(constants.tera) #1000000000000.0 print(constants.giga) #1000000000.0 print(constants.mega) #1000000.0 print(constants.kilo) #1000.0 print(constants.hecto) #100.0 print(constants.deka) #10.0 print(constants.deci) #0.1 print(constants.centi) #0.01 print(constants.milli) #0.001 print(constants.micro) #1e-06 print(constants.nano) #1e-09 print(constants.pico) #1e-12 print(constants.femto) #1e-15 print(constants.atto) #1e-18 print(constants.zepto) #1e-21 -
二进制,以字节为单位
返回字节单位 (kibi 返回 1024)。from scipy import constants print(constants.kibi) #1024 print(constants.mebi) #1048576 print(constants.gibi) #1073741824 print(constants.tebi) #1099511627776 print(constants.pebi) #1125899906842624 print(constants.exbi) #1152921504606846976 print(constants.zebi) #1180591620717411303424 print(constants.yobi) #1208925819614629174706176 -
质量单位
返回多少千克 kg。(gram 返回 0.001)。from scipy import constants print(constants.gram) #0.001 print(constants.metric_ton) #1000.0 print(constants.grain) #6.479891e-05 print(constants.lb) #0.45359236999999997 print(constants.pound) #0.45359236999999997 print(constants.oz) #0.028349523124999998 print(constants.ounce) #0.028349523124999998 print(constants.stone) #6.3502931799999995 print(constants.long_ton) #1016.0469088 print(constants.short_ton) #907.1847399999999 print(constants.troy_ounce) #0.031103476799999998 print(constants.troy_pound) #0.37324172159999996 print(constants.carat) #0.0002 print(constants.atomic_mass) #1.66053904e-27 print(constants.m_u) #1.66053904e-27 print(constants.u) #1.66053904e-27 -
角度换算
返回弧度 (degree 返回 0.017453292519943295)。from scipy import constants print(constants.degree) #0.017453292519943295 print(constants.arcmin) #0.0002908882086657216 print(constants.arcminute) #0.0002908882086657216 print(constants.arcsec) #4.84813681109536e-06 print(constants.arcsecond) #4.84813681109536e-06 -
时间单位
返回秒数(hour 返回 3600.0)。from scipy import constants print(constants.minute) #60.0 print(constants.hour) #3600.0 print(constants.day) #86400.0 print(constants.week) #604800.0 print(constants.year) #31536000.0 print(constants.Julian_year) #31557600.0 -
长度单位
返回米数(nautical_mile 返回 1852.0)。from scipy import constants print(constants.inch) #0.0254 print(constants.foot) #0.30479999999999996 print(constants.yard) #0.9143999999999999 print(constants.mile) #1609.3439999999998 print(constants.mil) #2.5399999999999997e-05 print(constants.pt) #0.00035277777777777776 print(constants.point) #0.00035277777777777776 print(constants.survey_foot) #0.3048006096012192 print(constants.survey_mile) #1609.3472186944373 print(constants.nautical_mile) #1852.0 print(constants.fermi) #1e-15 print(constants.angstrom) #1e-10 print(constants.micron) #1e-06 print(constants.au) #149597870691.0 print(constants.astronomical_unit) #149597870691.0 print(constants.light_year) #9460730472580800.0 print(constants.parsec) #3.0856775813057292e+16 -
压强单位
返回多少帕斯卡,压力的 SI 制单位。(psi 返回 6894.757293168361)。from scipy import constants print(constants.atm) #101325.0 print(constants.atmosphere) #101325.0 print(constants.bar) #100000.0 print(constants.torr) #133.32236842105263 print(constants.mmHg) #133.32236842105263 print(constants.psi) #6894.757293168361 -
面积单位
返回多少平方米,平方米是面积的公制单位,其定义是:在一平面上,边长为一米的正方形之面积。(hectare 返回 10000.0)。from scipy import constants print(constants.hectare) #10000.0 print(constants.acre) #4046.8564223999992 -
体积单位
返回多少立方米,立方米容量计量单位,1 立方米的容量相当于一个长、宽、高都等于 1 米的立方体的体积,与 1 公秉和 1 度水的容积相等,也与1000000立方厘米的体积相等。(liter返回0.001)。
from scipy import constants print(constants.liter) #0.001 print(constants.litre) #0.001 print(constants.gallon) #0.0037854117839999997 print(constants.gallon_US) #0.0037854117839999997 print(constants.gallon_imp) #0.00454609 print(constants.fluid_ounce) #2.9573529562499998e-05 print(constants.fluid_ounce_US) #2.9573529562499998e-05 print(constants.fluid_ounce_imp) #2.84130625e-05 print(constants.barrel) #0.15898729492799998 print(constants.bbl) #0.15898729492799998 -
速度单位
返回每秒多少米。(speed_of_sound 返回 340.5)。from scipy import constants print(constants.kmh) #0.2777777777777778 print(constants.mph) #0.44703999999999994 print(constants.mach) #340.5 print(constants.speed_of_sound) #340.5 print(constants.knot) #0.5144444444444445 -
温度单位
返回多少开尔文。(zero_Celsius 返回 273.15)。from scipy import constants print(constants.zero_Celsius) #273.15 print(constants.degree_Fahrenheit) #0.5555555555555556 -
能量单位
返回多少焦耳,焦耳(简称焦)是国际单位制中能量、功或热量的导出单位,符号为J。(calorie 返回 4.184)。from scipy import constants print(constants.calorie) #4.184 -
功率单位
返回多少瓦特,瓦特(符号:W)是国际单位制的功率单位。1瓦特的定义是1焦耳/秒(1 J/s),即每秒钟转换,使用或耗散的(以安培为量度的)能量的速率。(horsepower返回745.6998715822701)。from scipy import constants print(constants.hp) #745.6998715822701 print(constants.horsepower) #745.6998715822701 -
力学单位
返回多少牛顿,牛顿(符号为N,英语:Newton)是一种物理量纲,是力的公制单位。它是以建立经典力学(经典力学)的艾萨克·牛顿命名。。(kilogram_force返回9.80665)。from scipy import constants print(constants.dyn) #1e-05 print(constants.dyne) #1e-05 print(constants.lbf) #4.4482216152605 print(constants.pound_force) #4.4482216152605 print(constants.kgf) #9.80665 print(constants.kilogram_force) #9.80665
Scipy优化器
SciPy 的 optimize 模块提供了常用的最优化算法函数实现,我们可以直接调用这些函数完成我们的优化问题,比如查找函数的最小值或方程的根等。
求方程的根
NumPy 能够找到多项式和线性方程的根,但它无法找到非线性方程的根,如下所示:
x + cos(x)
因此我们可以使用 SciPy 的 optimze.root 函数,这个函数需要两个参数:
- fun - 表示方程的函数。
- x0 - 根的初始猜测。
该函数返回一个对象,其中包含有关解决方案的信息。
from scipy.optimize import root
from math import cos
def eqn(x):
return x + cos(x)
myroot = root(eqn, 0)
print(myroot.x)
# 查看更多信息
#print(myroot)
最小化函数
函数表示一条曲线,曲线有高点和低点。
高点称为最大值。
低点称为最小值。
整条曲线中的最高点称为全局最大值,其余部分称为局部最大值。
整条曲线的最低点称为全局最小值,其余的称为局部最小值。
可以使用 scipy.optimize.minimize() 函数来最小化函数。
minimize() 函接受以下几个参数:
-
fun - 要优化的函数
-
x0 - 初始猜测值
-
method - 要使用的方法名称,值可以是:'CG','BFGS','Newton-CG','L-BFGS-B','TNC','COBYLA',,'SLSQP'。
-
callback - 每次优化迭代后调用的函数。
-
options - 定义其他参数的字典:
{ "disp": boolean - print detailed description "gtol": number - the tolerance of the error }
\(x^2 + x + 2\) 使用 BFGS 的最小化函数:
from scipy.optimize import minimize
def eqn(x):
return x**2 + x + 2
mymin = minimize(eqn, 0, method='BFGS')
print(mymin)
scipy稀疏矩阵
稀疏矩阵(英语:sparse matrix)指的是在数值分析中绝大多数数值为零的矩阵。反之,如果大部分元素都非零,则这个矩阵是稠密的(Dense)。
在科学与工程领域中求解线性模型时经常出现大型的稀疏矩阵。
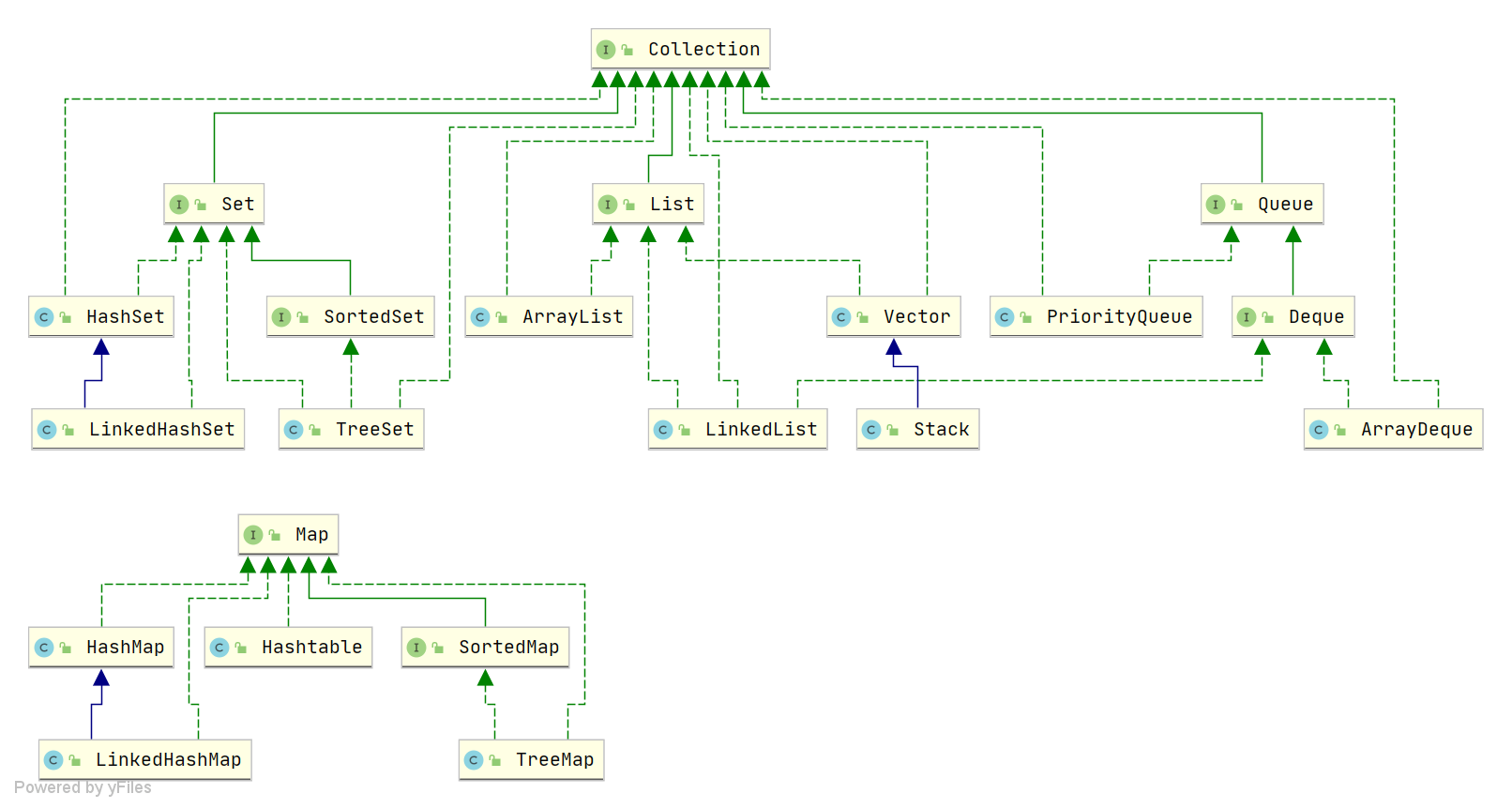
上述稀疏矩阵仅包含 9 个非零元素,另外包含 26 个零元。其稀疏度为 74%,密度为 26%。
SciPy 的 scipy.sparse 模块提供了处理稀疏矩阵的函数。
我们主要使用以下两种类型的稀疏矩阵:
- CSC - 压缩稀疏列(Compressed Sparse Column),按列压缩。
- CSR - 压缩稀疏行(Compressed Sparse Row),按行压缩。
本章节我们主要使用 CSR 矩阵。
CSR矩阵
我们可以通过向 scipy.sparse.csr_matrix() 函数传递数组来创建一个 CSR 矩阵。
# 创建 CSR 矩阵。
import numpy as np
from scipy.sparse import csr_matrix
arr = np.array([0, 0, 0, 0, 0, 1, 1, 0, 2])
print(csr_matrix(arr))
- data
使用 data 属性查看存储的数据(不含 0 元素):
import numpy as np
from scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
print(csr_matrix(arr).data)
- count_nonzero()
使用 count_nonzero() 方法计算非 0 元素的总数:
import numpy as np
from scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
print(csr_matrix(arr).count_nonzero())
- eliminate_zeros()
使用 eliminate_zeros() 方法删除矩阵中 0 元素:
import numpy as np
from scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
mat = csr_matrix(arr)
mat.eliminate_zeros()
print(mat)
- sum_duplicates()
使用 sum_duplicates() 方法来删除重复项:
import numpy as np
from scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
mat = csr_matrix(arr)
mat.sum_duplicates()
print(mat)
- tocsc()
csr 转换为 csc 使用 tocsc() 方法:
import numpy as np
from scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
newarr = csr_matrix(arr).tocsc()
print(newarr)
SciPy 图结构
图结构是算法学中最强大的框架之一。
图是各种关系的节点和边的集合,节点是与对象对应的顶点,边是对象之间的连接。
SciPy 提供了 scipy.sparse.csgraph 模块来处理图结构。
邻接矩阵
邻接矩阵(Adjacency Matrix)是表示顶点之间相邻关系的矩阵。
邻接矩阵逻辑结构分为两部分:V 和 E 集合,其中,V 是顶点,E 是边,边有时会有权重,表示节点之间的连接强度。
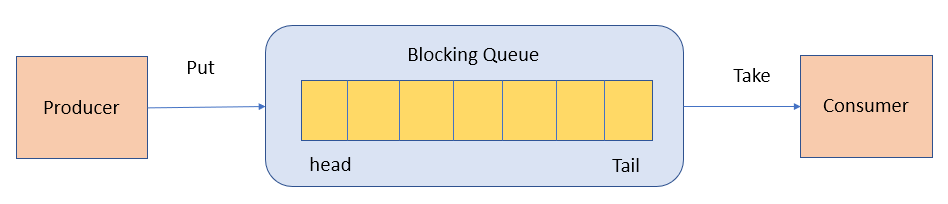
用一个一维数组存放图中所有顶点数据,用一个二维数组存放顶点间关系(边或弧)的数据,这个二维数组称为邻接矩阵。
邻接矩阵又分为有向图邻接矩阵和无向图邻接矩阵。
无向图是双向关系,边没有方向:
有向图的边带有方向,是单向关系:
连接组件
查看所有连接组件使用 connected_components() 方法。
import numpy as np
from scipy.sparse.csgraph import connected_components
from scipy.sparse import csr_matrix
arr = np.array([
[0, 1, 2],
[1, 0, 0],
[2, 0, 0]
])
newarr = csr_matrix(arr)
print(connected_components(newarr))
Dijkstra -- 最短路径算法
Dijkstra(迪杰斯特拉)最短路径算法,用于计算一个节点到其他所有节点的最短路径。
Scipy 使用 dijkstra() 方法来计算一个元素到其他元素的最短路径。
dijkstra() 方法可以设置以下几个参数:
- return_predecessors: 布尔值,设置 True,遍历所有路径,如果不想遍历所有路径可以设置为 False。
- indices: 元素的索引,返回该元素的所有路径。
- limit: 路径的最大权重。
# 查找元素 1 到 2 的最短路径:
import numpy as np
from scipy.sparse.csgraph import dijkstra
from scipy.sparse import csr_matrix
arr = np.array([
[0, 1, 2],
[1, 0, 0],
[2, 0, 0]
])
newarr = csr_matrix(arr)
print(dijkstra(newarr, return_predecessors=True, indices=0))
Floyd Warshall -- 弗洛伊德算法
弗洛伊德算法算法是解决任意两点间的最短路径的一种算法。
Scipy 使用 floyd_warshall() 方法来查找所有元素对之间的最短路径。
# 查找所有元素对之间的最短路径径:
import numpy as np
from scipy.sparse.csgraph import floyd_warshall
from scipy.sparse import csr_matrix
arr = np.array([
[0, 1, 2],
[1, 0, 0],
[2, 0, 0]
])
newarr = csr_matrix(arr)
print(floyd_warshall(newarr, return_predecessors=True))
Bellman Ford -- 贝尔曼-福特算法
贝尔曼-福特算法是解决任意两点间的最短路径的一种算法。
Scipy 使用 bellman_ford() 方法来查找所有元素对之间的最短路径,通常可以在任何图中使用,包括有向图、带负权边的图。
# 使用负权边的图查找从元素 1 到元素 2 的最短路径:
import numpy as np
from scipy.sparse.csgraph import bellman_ford
from scipy.sparse import csr_matrix
arr = np.array([
[0, -1, 2],
[1, 0, 0],
[2, 0, 0]
])
newarr = csr_matrix(arr)
print(bellman_ford(newarr, return_predecessors=True, indices=0))
深度优先顺序
depth_first_order() 方法从一个节点返回深度优先遍历的顺序。
可以接收以下参数:
- 图
- 图开始遍历的元素
# 给定一个邻接矩阵,返回深度优先遍历的顺序:
import numpy as np
from scipy.sparse.csgraph import depth_first_order
from scipy.sparse import csr_matrix
arr = np.array([
[0, 1, 0, 1],
[1, 1, 1, 1],
[2, 1, 1, 0],
[0, 1, 0, 1]
])
newarr = csr_matrix(arr)
print(depth_first_order(newarr, 1))
广度优先顺序
breadth_first_order() 方法从一个节点返回广度优先遍历的顺序。
可以接收以下参数:
- 图
- 图开始遍历的元素
# 给定一个邻接矩阵,返回广度优先遍历的顺序:
import numpy as np
from scipy.sparse.csgraph import breadth_first_order
from scipy.sparse import csr_matrix
arr = np.array([
[0, 1, 0, 1],
[1, 1, 1, 1],
[2, 1, 1, 0],
[0, 1, 0, 1]
])
newarr = csr_matrix(arr)
print(breadth_first_order(newarr, 1))
SciPy 空间数据
空间数据又称几何数据,它用来表示物体的位置、形态、大小分布等各方面的信息,比如坐标上的点。
SciPy 通过 scipy.spatial 模块处理空间数据,比如判断一个点是否在边界内、计算给定点周围距离最近点以及给定距离内的所有点。
三角测量
三角测量在三角学与几何学上是一借由测量目标点与固定基准线的已知端点的角度,测量目标距离的方法。
多边形的三角测量是将多边形分成多个三角形,我们可以用这些三角形来计算多边形的面积。
拓扑学的一个已知事实告诉我们:任何曲面都存在三角剖分。
假设曲面上有一个三角剖分, 我们把所有三角形的顶点总个数记为 p(公共顶点只看成一个),边数记为 a,三角形的个数记为 n,则 e=p-a+n 是曲面的拓扑不变量。也就是说不管是什么剖分,e总是得到相同的数值。e被称为称为欧拉示性数。
对一系列的点进行三角剖分点方法是 Delaunay() 三角剖分。
# 通过给定的点来创建三角形:
import numpy as np
from scipy.spatial import Delaunay
import matplotlib.pyplot as plt
points = np.array([
[2, 4],
[3, 4],
[3, 0],
[2, 2],
[4, 1]
])
simplices = Delaunay(points).simplices # 三角形中顶点的索引
plt.triplot(points[:, 0], points[:, 1], simplices)
plt.scatter(points[:, 0], points[:, 1], color='r')
plt.show()
凸包
凸包(Convex Hull)是一个计算几何(图形学)中的概念。
在一个实数向量空间 V 中,对于给定集合 X,所有包含 X 的凸集的交集 S 被称为 X 的凸包。X 的凸包可以用 X 内所有点(X1,...Xn)的凸组合来构造。
我们可以使用 ConvexHull() 方法来创建凸包。
# 通过给定的点来创建凸包:
import numpy as np
from scipy.spatial import ConvexHull
import matplotlib.pyplot as plt
points = np.array([
[2, 4],
[3, 4],
[3, 0],
[2, 2],
[4, 1],
[1, 2],
[5, 0],
[3, 1],
[1, 2],
[0, 2]
])
hull = ConvexHull(points)
hull_points = hull.simplices
plt.scatter(points[:,0], points[:,1])
for simplex in hull_points:
plt.plot(points[simplex,0], points[simplex,1], 'k-')
plt.show()
K-D 树
kd-tree(k-dimensional树的简称),是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索)。
K-D 树可以使用在多种应用场合,如多维键值搜索(范围搜寻及最邻近搜索)。
最邻近搜索用来找出在树中与输入点最接近的点。
KDTree() 方法返回一个 KDTree 对象。
query() 方法返回最邻近距离和最邻近位置。
查找到 (1,1) 的最邻近距离:
from scipy.spatial import KDTree
points = [(1, -1), (2, 3), (-2, 3), (2, -3)]
kdtree = KDTree(points)
res = kdtree.query((1, 1))
print(res)
距离矩阵
在数学中, 一个距离矩阵是一个各项元素为点之间距离的矩阵(二维数组)。因此给定 N 个欧几里得空间中的点,其距离矩阵就是一个非负实数作为元素的 N×N 的对称矩阵距离矩阵和邻接矩阵概念相似,其区别在于后者仅包含元素(点)之间是否有连边,并没有包含元素(点)之间的连通的距离的讯息。因此,距离矩阵可以看成是邻接矩阵的加权形式。
举例来说,我们分析如下二维点 a 至 f。在这里,我们把点所在像素之间的欧几里得度量作为距离度量。
欧几里得距离
在数学中,欧几里得距离或欧几里得度量是欧几里得空间中两点间"普通"(即直线)距离。使用这个距离,欧氏空间成为度量空间。相关联的范数称为欧几里得范数。较早的文献称之为毕达哥拉斯度量。
欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
from scipy.spatial.distance import euclidean
p1 = (1, 0)
p2 = (10, 2)
res = euclidean(p1, p2)
print(res)
曼哈顿距离
出租车几何或曼哈顿距离(Manhattan Distance)是由十九世纪的赫尔曼·闵可夫斯基所创词汇 ,是种使用在几何度量空间的几何学用语,用以标明两个点在标准坐标系上的绝对轴距总和。
曼哈顿距离 只能上、下、左、右四个方向进行移动,并且两点之间的曼哈顿距离是两点之间的最短距离。
曼哈顿与欧几里得距离: 红、蓝与黄线分别表示所有曼哈顿距离都拥有一样长度(12),而绿线表示欧几里得距离有6×√2 ≈ 8.48的长度。
余弦距离
余弦距离,也称为余弦相似度,通过测量两个向量的夹角的余弦值来度量它们之间的相似性。
0 度角的余弦值是 1,而其他任何角度的余弦值都不大于 1,并且其最小值是 -1。
# 计算 A 与 B 两点的余弦距离:
from scipy.spatial.distance import cosine
p1 = (1, 0)
p2 = (10, 2)
res = cosine(p1, p2)
print(res)
汉明距离
在信息论中,两个等长字符串之间的汉明距离(英语:Hamming distance)是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。
汉明重量是字符串相对于同样长度的零字符串的汉明距离,也就是说,它是字符串中非零的元素个数:对于二进制字符串来说,就是 1 的个数,所以 11101 的汉明重量是4。
- 1011101与1001001之间的汉明距离是2。
- 2143896与2233796之间的汉明距离是3。
- "toned"与"roses"之间的汉明距离是3。
# 计算两个点之间的汉明距离:
from scipy.spatial.distance import hamming
p1 = (True, False, True)
p2 = (False, True, True)
res = hamming(p1, p2)
print(res)
SciPy Matlab 数组
NumPy 提供了 Python 可读格式的数据保存方法。
SciPy 提供了与 Matlab 的交互的方法。
SciPy 的 scipy.io 模块提供了很多函数来处理 Matlab 的数组。
以 Matlab 格式导出数据
savemat() 方法可以导出 Matlab 格式的数据。
该方法参数有:
- filename - 保存数据的文件名。
- mdict - 包含数据的字典。
- do_compression - 布尔值,指定结果数据是否压缩。默认为 False。
# 将数组作为变量 "vec" 导出到 mat 文件:
from scipy import io
import numpy as np
arr = np.arange(10)
io.savemat('arr.mat', {"vec": arr})
注意:上面的代码会在您的计算机上保存了一个名为 "arr.mat" 的文件。
导入 Matlab 格式数据
loadmat() 方法可以导入 Matlab 格式数据。
该方法参数:
- filename - 保存数据的文件名。
返回一个结构化数组,其键是变量名,对应的值是变量值。
# 从 mat 文件中导入数组:
from scipy import io
import numpy as np
arr = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9,])
# 导出
io.savemat('arr.mat', {"vec": arr})
# 导入
mydata = io.loadmat('arr.mat')
print(mydata)
# 使用变量名 "vec" 只显示 matlab 数据的数组:
print(mydata['vec'])
从结果可以看出数组最初是一维的,但在提取时它增加了一个维度,变成了二维数组。
解决这个问题可以传递一个额外的参数 squeeze_me=True:
from scipy import io
import numpy as np
arr = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9,])
# 导出
io.savemat('arr.mat', {"vec": arr})
# 导入
mydata = io.loadmat('arr.mat', squeeze_me=True)
print(mydata['vec'])
SciPy 插值
什么是插值?
在数学的数值分析领域中,插值(英语:interpolation)是一种通过已知的、离散的数据点,在范围内推求新数据点的过程或方法。
简单来说插值是一种在给定的点之间生成点的方法。
例如:对于两个点 1 和 2,我们可以插值并找到点 1.33 和 1.66。
插值有很多用途,在机器学习中我们经常处理数据缺失的数据,插值通常可用于替换这些值。
这种填充值的方法称为插补。
除了插补,插值经常用于我们需要平滑数据集中离散点的地方。
如何在 SciPy 中实现插值?
SciPy 提供了 scipy.interpolate 模块来处理插值。
一维插值
一维数据的插值运算可以通过方法 interp1d() 完成。
该方法接收两个参数 x 点和 y 点。
返回值是可调用函数,该函数可以用新的 x 调用并返回相应的 y,y = f(x)。
# 对给定的 xs 和 ys 插值,从 2.1、2.2... 到 2.9:
from scipy.interpolate import interp1d
import numpy as np
xs = np.arange(10)
ys = 2*xs + 1
interp_func = interp1d(xs, ys)
newarr = interp_func(np.arange(2.1, 3, 0.1))
print(newarr)
单变量插值
在一维插值中,点是针对单个曲线拟合的,而在样条插值中,点是针对使用多项式分段定义的函数拟合的。
单变量插值使用 UnivariateSpline() 函数,该函数接受 xs 和 ys 并生成一个可调用函数,该函数可以用新的 xs 调用。
分段函数,就是对于自变量 x 的不同的取值范围,有着不同的解析式的函数。
# 为非线性点找到 2.1、2.2...2.9 的单变量样条插值:
from scipy.interpolate import UnivariateSpline
import numpy as np
xs = np.arange(10)
ys = xs**2 + np.sin(xs) + 1
interp_func = UnivariateSpline(xs, ys)
newarr = interp_func(np.arange(2.1, 3, 0.1))
print(newarr)
径向基函数插值
径向基函数是对应于固定参考点定义的函数。
曲面插值里我们一般使用径向基函数插值。
# Rbf() 函数接受 xs 和 ys 作为参数,并生成一个可调用函数
from scipy.interpolate import Rbf
import numpy as np
xs = np.arange(10)
ys = xs**2 + np.sin(xs) + 1
interp_func = Rbf(xs, ys)
newarr = interp_func(np.arange(2.1, 3, 0.1))
print(newarr)
Scipy 显著性检验
显著性检验(significance test)就是事先对总体(随机变量)的参数或总体分布形式做出一个假设,然后利用样本信息来判断这个假设(备择假设)是否合理,即判断总体的真实情况与原假设是否有显著性差异。
或者说,显著性检验要判断样本与我们对总体所做的假设之间的差异是纯属机会变异,还是由我们所做的假设与总体真实情况之间不一致所引起的。 显著性检验是针对我们对总体所做的假设做检验,其原理就是"小概率事件实际不可能性原理"来接受或否定假设。
显著性检验即用于实验处理组与对照组或两种不同处理的效应之间是否有差异,以及这种差异是否显著的方法。
SciPy 提供了 scipy.stats 的模块来执行Scipy 显著性检验的功能。
统计假设
统计假设是关于一个或多个随机变量的未知分布的假设。随机变量的分布形式已知,而仅涉及分布中的一个或几个未知参数的统计假设,称为参数假设。检验统计假设的过程称为假设检验,判别参数假设的检验称为参数检验。
零假设
零假设(null hypothesis),统计学术语,又称原假设,指进行统计检验时预先建立的假设。 零假设成立时,有关统计量应服从已知的某种概率分布。
当统计量的计算值落入否定域时,可知发生了小概率事件,应否定原假设。
常把一个要检验的假设记作 H0,称为原假设(或零假设)(null hypothesis),与H0对立的假设记作 H1,称为备择假设 (alternative hypothesis)
- 在原假设为真时,决定放弃原假设,称为第一类错误,其出现的概率通常记作 α;
- 在原假设不真时,决定不放弃原假设,称为第二类错误,其出现的概率通常记作 β
- α+β 不一定等于 1。
通常只限定犯第一类错误的最大概率 α, 不考虑犯第二类错误的概率 β。这样的假设 检验又称为显著性检验,概率 α 称为显著性水平。
最常用的 α 值为 0.01、0.05、0.10 等。一般情况下,根据研究的问题,如果放弃真假设损失大,为减少这类错误,α 取值小些 ,反之,α 取值大些。
备择假设
备择假设(alternative hypothesis)是统计学的基本概念之一,其包含关于总体分布的一切使原假设不成立的命题。备择假设亦称对立假设、备选假设。
备择假设可以替代零假设。
例如我们对于学生的评估,我们将采取:
- “学生比平均水平差” -— 作为零假设
- “学生优于平均水平” —— 作为替代假设。
单边检验
单边检验(one-sided test)亦称单尾检验,又称单侧检验,在假设检验中,用检验统计量的密度曲线和二轴所围成面积中的单侧尾部面积来构造临界区域进行检验的方法称为单边检验。
当我们的假设仅测试值的一侧时,它被称为"单尾测试"。
例子:
对于零假设:
“均值等于 k”
我们可以有替代假设:
- “平均值小于 k”
- “平均值大于 k”
双边检验
双边检验(two-sided test),亦称双尾检验、双侧检验.在假设检验中,用检验统计量的密度曲线和x轴所围成的面积的左右两边的尾部面积来构造临界区域进行检验的方法。
当我们的假设测试值的两边时。
例子:
对于零假设:
“均值等于 k”
我们可以有替代假设:
“均值不等于k”
在这种情况下,均值小于或大于 k,两边都要检查。
阿尔法值
阿尔法值是显著性水平。
显著性水平是估计总体参数落在某一区间内,可能犯错误的概率,用 α 表示。
数据必须有多接近极端才能拒绝零假设。
通常取为 0.01、0.05 或 0.1。
P 值
P 值表明数据实际接近极端的程度。
比较 P 值和阿尔法值(alpha)来确定统计显著性水平。
如果 p 值 <= alpha,我们拒绝原假设并说数据具有统计显著性,否则我们接受原假设。
T 检验(T-Test)
T 检验用于确定两个变量的均值之间是否存在显著差异,并判断它们是否属于同一分布。
这是一个双尾测试。
函数 ttest_ind() 获取两个相同大小的样本,并生成 t 统计和 p 值的元组。
# 查找给定值 v1 和 v2 是否来自相同的分布:
import numpy as np
from scipy.stats import ttest_ind
v1 = np.random.normal(size=100)
v2 = np.random.normal(size=100)
res = ttest_ind(v1, v2)
print(res)
# 只想返回 p 值
res = ttest_ind(v1, v2).pvalue
print(res)
KS 检验
KS 检验用于检查给定值是否符合分布。
该函数接收两个参数;测试的值和 CDF。
CDF 为累积分布函数(Cumulative Distribution Function),又叫分布函数。
CDF 可以是字符串,也可以是返回概率的可调用函数。
它可以用作单尾或双尾测试。
默认情况下它是双尾测试。 我们可以将参数替代作为两侧、小于或大于其中之一的字符串传递。
# 查找给定值是否符合正态分布:
import numpy as np
from scipy.stats import kstest
v = np.random.normal(size=100)
res = kstest(v, 'norm')
print(res)
数据统计说明
使用 describe() 函数可以查看数组的信息,包含以下值:
- nobs -- 观测次数
- minmax -- 最小值和最大值
- mean -- 数学平均数
- variance -- 方差
- skewness -- 偏度
- kurtosis -- 峰度
# 显示数组中的统计描述信息:
import numpy as np
from scipy.stats import describe
v = np.random.normal(size=100)
res = describe(v)
print(res)
正态性检验(偏度和峰度)
利用观测数据判断总体是否服从正态分布的检验称为正态性检验,它是统计判决中重要的一种特殊的拟合优度假设检验。
正态性检验基于偏度和峰度。
normaltest() 函数返回零假设的 p 值:
“x 来自正态分布”
偏度
数据对称性的度量。
对于正态分布,它是 0。
如果为负,则表示数据向左倾斜。
如果是正数,则意味着数据是正确倾斜的。
峰度
衡量数据是重尾还是轻尾正态分布的度量。
正峰度意味着重尾。
负峰度意味着轻尾。
# 查找数组中值的偏度和峰度:
import numpy as np
from scipy.stats import skew, kurtosis
from scipy.stats import normaltest
v = np.random.normal(size=100)
print(skew(v))
print(kurtosis(v))
# 查找数据是否来自正态分布:
print(normaltest(v))