inode和block概述
文件是存储在硬盘上的,硬盘的最小存储单位叫做扇区sector,每个扇区存储512字节。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个块block。这种由多个扇区组成的块,是文件存取的最小单位。块的大小,最常见的是4KB,即连续八个sector组成一个block。
文件数据存储在块中,那么还必须找到一个地方存储文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等,但不包含文件名。这种存储文件元信息的区域就叫做inode,中文译名为索引节点,也叫i节点。一个文件必须占用一个inode,至少占用一个block。
-
元信息 → inode
-
数据 → block
文件名存放在目录当中,但Linux系统内部不使用文件名,而是使用inode号码识别文件。对于系统来说文件名只是inode号码便于识别的别称。
stat - 查看inode信息
[root@localhost ~]# mkdir test [root@localhost ~]# echo "this is test file" > test.txt [root@localhost ~]# stat test.txt File: ‘test.txt’ Size: 18 Blocks: 8 IO Block: 4096 regular file Device: fd00h/64768d Inode: 33574994 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Context: unconfined_u:object_r:admin_home_t:s0 Access: 2021-08-15 19:55:05.920240744 +0800 Modify: 2021-08-15 19:55:05.920240744 +0800 Change: 2021-08-15 19:55:05.920240744 +0800 Birth: -
inode号码
表面上,用户通过文件名打开文件,实际上,系统内部将这个过程分为三步:
1.系统找到这个文件名对应的inode号码;
2.通过inode号码,获取inode信息;
3.根据inode信息,找到文件数据所在的block,并读出数据。
下面以文件"file1"来举例如何通过文件名读取文件数据
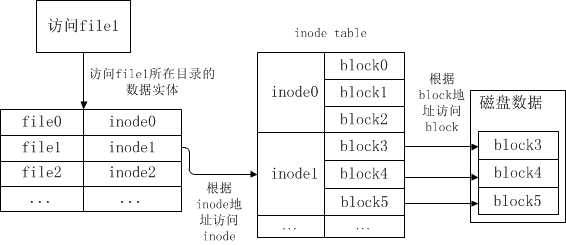
其实系统还要根据inode信息,看用户是否具有访问的权限,有就指向对应的数据block,没有就返回权限拒绝。
ls -i 直接查看文件 inode 号码,也可以通过 stat 查看文件 inode 信息查看 inode 号码
[root@localhost ~]# ls -i 33574991 anaconda-ks.cfg 2086 test 33574994 test.txt
inode总数
inode也会消耗硬盘空间,所以格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区,存放inode所包含的信息。每个inode的大小,一般是128字节或256字节。通常情况下不需要关注单个inode的大小,而是需要重点关注inode总数。inode总数在格式化的时候就确定了。
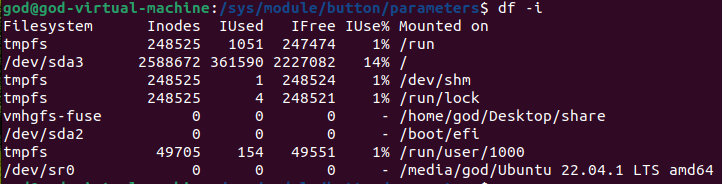
df -i - 查看硬盘分区的inode总数和已使用情况
inode耗尽故障
由于硬盘分区的inode总数在格式化后就已经固定,而每个文件必须有一个inode,因此就有可能发生inode节点用光,但硬盘空间还剩不少,却无法创建新文件。同时这也是一种攻击的方式,所以一些公用的文件系统就要做磁盘限额,以防止影响到系统的正常运行。
至于修复,很简单,只要找出哪些大量占用i节点的文件删除就可以了。
做个测试,
1. 先准备一个比较小的硬盘分区/dev/sdb1,并格式化挂载,这里挂载到了/data目录下
[root@localhost ~]# df -hT /data/ Filesystem Type Size Used Avail Use% Mounted on /dev/sdb1 xfs 29M 1.8M 27M 6% /data
2. 先测试可以正常创建文件
[root@localhost ~]# touch /data/test{1..5}.txt
[root@localhost ~]# ls /data/
test1.txt test2.txt test3.txt test4.txt test5.txt
3. 查看i节点的使用情况
[root@localhost ~]# df -i /data/ Filesystem Inodes IUsed IFree IUse% Mounted on /dev/sdb1 16385 8 16377 1% /data
4. 编写一个测试程序,创建大量空文件,用于耗尽此分区中的i节点数
[root@localhost ~]# vim killinode.sh #!/bin/bash i=1 while [ $i -le 16376 ] do touch /data/file$i let i++ done
5. 运行测试程序,结束后查看i节点占用情况,磁盘分区空间使用情况
[root@localhost ~]# sh killinode.sh [root@localhost ~]# df -i /data/ Filesystem Inodes IUsed IFree IUse% Mounted on /dev/sdb1 16385 16385 0 100% /data [root@localhost ~]# df -hT /data/ Filesystem Type Size Used Avail Use% Mounted on /dev/sdb1 xfs 29M 11M 19M 36% /data
6. 虽然还有很多剩余空间,但是i节点耗尽了,也无法创建创建新文件,这就是i节点耗尽故障
[root@localhost ~]# touch /data/newfile.txt
touch: cannot touch ‘/data/newfile.txt’: No space left on device
硬链接和软链接
硬链接
通过文件系统的inode引用数来产生的新的文件名,而不是产生新的文件,称为硬链接
一般情况下,每个inode号码对应一个文件名,但是Linux允许多个文件名指向同一个inode号码。意味着可以使用不同的文件名访问相同的内容
ln 源文件 目标
运行该命令以后,源文件与目标文件的inode号码相同,都指向同一个inode。inode信息中的引用数这时就会增加1。
当一个文件拥有多个硬链接时,对文件内容修改,会影响到所有文件名;但是删除一个文件名,不影响另一个文件名的访问。删除一个文件名,只会使得inode中的引用数减1。
需要注意的是不能对目录做硬链接。
软链接
类似于Windows的快捷方式功能的文件,可以快速连接到目标文件或目录,称为软链接
ln -s 源文件或目录 目标文件或目录
软链接就是再创建一个独立的文件,而这个文件会让数据的读取指向它链接的那个文件的文件名。例如,文件A和文件B的inode号码虽然不一样,但是文件A的内容是文件B的路径。读取文件A时,系统会自动将访问者导向文件B。这时,文件A就称为文件B的软链接soft link或者符号链接symbolic link。
这意味着,文件A依赖于文件B而存在,如果删除了文件B,打开文件A就会报错。这是软链接与硬链接最大的不同:文件A指向文件B的文件名,而不是文件B的inode号码,文件B的inode链接数不会因此发生变化。