1 序言
-
上一次使用Guava Cache框架还是在2年前浙江某大学的数据服务平台项目中,用于缓存用户的数据服务购物小车数据;
-
而这一次,是在基于Google Guava Cache + refreshAfterWrite特性来缓存Influxdb的物联网信号数据表的信号字段信息(为何缓存?因为查询Influxdb表实在太慢了,需要80-90s),发现了这么一种现象:
1)当guava cache缓存的数据过期后(假定过期时间为1小时),并没有主动删除;
2)仅当新的业务请求到来时,向guava cache框架获取数据时,cache框架会先懒式清理掉过期数据;然后,再从源头(Influxdb数据库)查询数据,而后返回。从而导致该业务请求会耗时非常长,以至于耗时80-90s,无法满足业务诉求、也无法满足最初缓存的目的;
3)当然,该业务请求之后(1小时之内)的请求会直接从cache框架中获取缓存数据,而不是从源头查询目标数据。因此不会受影响
-
本文基于上述背景下,由此彻底调研Google Guava Cache框架。其一,彻底研究Google Guava Cache框架,便于当前和未来使用本框架时能够更加得心应手;其二,基于一,确认是否能解决我的最初诉求;其三,如果不能,将放弃本地缓存方案,使用业界主流的共享外部内存方案(redis + 定时缓存调度 + 分布式锁)来解决我的问题。
-
如果对缓存解决方案的演变过程感兴趣、或者零经验的朋友,可参见从第2章节开始阅读;如果仅对Google Guava Cache框架及其原理感兴趣的朋友,可直接阅读第3章节。
-
全文较长,按需阅读。
2 缓存框架的演变
- 在我们日常开发中,如果某些数据会频繁的进行读取,并且很少会做修改,我们一般会对这些数据进行缓存,来提高读取的速度。
- 使用缓存之所以能提高性能,是因为读取速度比从磁盘或数据库中读取的速度更高。但是使用缓存并不是全部都是好处,因为存放缓存数据的空间一般都是CPU内存,或者Redis等,它们的空间更宝贵,是典型的空间换时间,所以需要放到缓存中的数据应该是真正需要缓存的。
2.1 本地缓存: JVM缓存
- 在最开始,没有其他第三方缓存方案时,如果我们需要将某个数据进行缓存,一般会通过一个Map结构来存放,使用缓存的唯一标识作为Map的key,要缓存的数据作为Map的value。
- 这种方式本质上是使用JVM的堆内存做为缓存空间。
- 使用这种方式的优点:
- 简单,只需要按照Map的API进行操作。
- 但也存在一些问题:
- 只能显式的对缓存数据进行写入和清除;
- 没有现成的淘汰策略,如果要实现淘汰策略则需要自己实现;
- 清除数据时没有回调机制;
2.2 本地缓存: Guava Cache、EhCache(本地缓存框架)
- 因为JVM缓存存在的一系列问题,所以出现了一些专门作为JVM缓存的工具,如:
- EhCache
- Guava Cache
Guava是google开源的一个公共java库,类似于Apache Commons,它提供了集合,反射,缓存,科学计算,xml,io等一些工具类库。
guava cache只是其中的一个模块。
使用Guva cache能够方便快速的构建本地缓存。
- 这些工具可以解决使用Map结构作为缓存的一些问题。如:
- 数据淘汰策略
- 清除回调...
- 当然,因为需要具备这些功能,则引入一些依赖变得必要,需要额外增加一些维护和系统的消耗。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>25.0-jre</version>
</dependency>
2.3 分布式缓存/外部缓存中间件: Redis、Memcached
- 不管是使用Map结构的JVM缓存,还是使用Guava Cache、EhCache等第三方工具,本质上都是使用JVM的堆内存作为缓存空间。
- 这样的方式只能满足在单节点使用,但是在分布式场景中,则需要每个节点都要有单独的空间进行数据缓存,并且在缓存数据需要更新时要对每个节点进行更新,在一些大厂的系统中,往往一个系统会有成百上千个节点,如果使用JVM缓存,在数据需要更新时,逐个节点更新,运维小哥哥估计又要爆粗口了,这样的方式显然是不可接受的。
- 于是就出现了分布式缓存中间件,如Redis、Memcached,在分布式环境下可以共享内存。
2.X 缓存框架的基础概念
2.x.1 缓存的最大容量与淘汰策略
- 由于本地缓存是将计算结果缓存到内存中,所以我们往往需要设置一个最大容量来防止出现内存溢出的情况。这个容量可以是缓存对象的数量,也可以是一个具体的内存大小。
在Guva中仅支持设置缓存对象的数量。
- 当缓存数量逼近或大于我们所设置的最大容量时,为了将缓存数量控制在我们所设定的阈值内,就需要丢弃掉一些数据。由于缓存的最大容量恒定,为了提高缓存的命中率,我们需要尽量丢弃那些我们之后不再经常访问的数据,保留那些即将被访问的数据。为了达到以上目的,我们往往会制定一些缓存淘汰策略,常用的缓存淘汰策略有以下几种:
- FIFO:First In First Out,先进先出。
一般采用队列的方式实现。这种淘汰策略仅仅是保证了缓存数量不超过我们所设置的阈值,而完全没有考虑缓存的命中率。所以在这种策略极少被使用。 - LRU:Least Recently Used,最近最少使用;
该算法其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
所以该算法是淘汰最后一次使用时间离当前最久的缓存数据,保留最近访问的数据。所以该种算法非常适合缓存“热点数据”。
但是该算法在缓存周期性数据时,就会出现缓存污染,也就是淘汰了即将访问的数据,反而把不常用的数据读取到缓存中。
为了解决这个问题,后续也出现了如LRU-K,Two queues,Multi Queue等进阶算法。 - LFU:Least Frequently Used,最不经常使用。
该算法的核心思想是“如果数据在以前被访问的次数最多,那么将来被访问的几率就会更高”。所以该算法淘汰的是历史访问次数最少的数据。
一般情况下,LFU效率要优于LRU,且能够避免周期性或者偶发性的操作导致缓存命中率下降的问题。但LFU需要记录数据的历史访问记录,一旦数据访问模式改变,LFU需要更长时间来适用新的访问模式,即:LFU存在历史数据影响将来数据的“缓存污染”效用。
后续出现LFU*,LFU-Aging,Window-LFU等改进算法。
合理的使用淘汰算法能够很明显的提升缓存命中率,但是也不应该一味的追求命中率,而是应在命中率和资源消耗中找到一个平衡。
在guava中默认使用LRU淘汰算法,而且在不修改源码的情况下也不支持自定义淘汰算法,这算是一种小小的遗憾吧。
3 Google Guava Framework
3.1 问题背景
假设一个场景,比如我们有一个产品要销售,而产品的基本信息如名称,售价,描述等信息需要频繁进行查询,如果每次查询时都从数据库中获取则会大大降低效率。我们使用Guava Cache进行缓存。
public class Product {
// 产品编码
private String code;
// 产品名称
private String name;
// 产品价格
private BigDecimal price;
// 产品描述
private String desc;
// 省略构造方法
// 省略getter,setter
}
3.2 基本使用
按照面向对象的思想,针对产品Product的缓存也会有一个具体的对象存在,所以需要先创建出一个Product的缓存对象。
public static LoadingCache<String, Product> buildCache() {
// step1 通过 CacheBuilder.newBuilder() 创建出一个可以创建缓存对象的构建器
CacheBuilder<Object, Object> builder = CacheBuilder.newBuilder();
// step2 使用`builder.build()`,则:可以创建出一个缓存对象`LoadingCache`
return builder.build(new CacheLoader<String, Product>() {//step3 在`build()`方法中需要传入一个`CacheLoader`对象,用于加载缓存数据
/**
* step4 当未命中缓存数据时,调用load方法获取
*/
@Override
public Product load(String key) throws Exception {
System.out.println("从数据库查询产品");
return new Product(key, "产品".concat(key), new BigDecimal(10), "自定义一个产品");
}
});
}
public static void main(String[] args) throws ExecutionException {
//有了这个LoadingCache对象之后,我们就可以从缓存对象中获取我们需要的数据了。
LoadingCache<String, Product> productCache = buildCache();
Product product1 = productCache.get("1001");
System.out.println(product1);
Product product2 = productCache.get("1001");
sSystem.out.println(product2);
}
执行结果:

从执行结果我们可以看出:
- 我们从缓存中第一次获取数据时会执行load()方法,所以打印了“从数据库查询产品”。
- 当我们第二次从缓存中获取数据时则并没有打印,说明没有执行load()方法,这代表命中了Guava Cache中的缓存数据。
3.3 核心属性
Guava Cache通过常用的builder模式来构造缓存,builder类为CacheBuilder,可以设置的属性包括:
private static final int DEFAULT_INITIAL_CAPACITY = 16;
private static final int DEFAULT_CONCURRENCY_LEVEL = 4;
private static final int DEFAULT_EXPIRATION_NANOS = 0;
private static final int DEFAULT_REFRESH_NANOS = 0;
int initialCapacity = UNSET_INT; //设置初始化大小,默认 16
int concurrencyLevel = UNSET_INT; //设置并发级别,默认 4
long maximumSize = UNSET_INT; //缓存最大大小
long maximumWeight = UNSET_INT; //缓存最大权重
Weigher<? super K, ? super V> weigher; //缓存权重计算器
Strength keyStrength; //key引用强度,强引用 or 弱引用
Strength valueStrength; //value引用强度
long expireAfterWriteNanos = UNSET_INT; //写过期时间
long expireAfterAccessNanos = UNSET_INT; //读过期时间
long refreshNanos = UNSET_INT; //刷新周期
Equivalence<Object> keyEquivalence; //key比较器
Equivalence<Object> valueEquivalence; //value比较器
RemovalListener<? super K, ? super V> removalListener; //entry移除监听器
Ticker ticker; //计时器
Supplier<? extends StatsCounter> statsCounterSupplier = NULL_STATS_COUNTER; //缓存统计器
3.4 核心原理
缓存构造
最后,通过CacheBuilder的build方法构造缓存,这里分为两种情况:
- 不包含加载器CacheLoader,构造缓存类:LocalManualCache
- 包含加载器CacheLoader,构造缓存类:LocalLoadingCache
/**
* Builds a cache, which either returns an already-loaded value for a given key or atomically
* computes or retrieves it using the supplied {@code CacheLoader}. If another thread is currently
* loading the value for this key, simply waits for that thread to finish and returns its loaded
* value. Note that multiple threads can concurrently load values for distinct keys.
*
* <p>This method does not alter the state of this {@code CacheBuilder} instance, so it can be
* invoked again to create multiple independent caches.
*
* @param loader the cache loader used to obtain new values
* @return a cache having the requested features
*/
public <K1 extends K, V1 extends V> LoadingCache<K1, V1> build(
CacheLoader<? super K1, V1> loader) {
checkWeightWithWeigher();
return new LocalCache.LocalLoadingCache<K1, V1>(this, loader);
}
/**
* Builds a cache which does not automatically load values when keys are requested.
*
* <p>Consider {@link #build(CacheLoader)} instead, if it is feasible to implement a
* {@code CacheLoader}.
*
* <p>This method does not alter the state of this {@code CacheBuilder} instance, so it can be
* invoked again to create multiple independent caches.
*
* @return a cache having the requested features
* @since 11.0
*/
public <K1 extends K, V1 extends V> Cache<K1, V1> build() {
checkWeightWithWeigher();
checkNonLoadingCache();
return new LocalCache.LocalManualCache<K1, V1>(this);
}
下面看一下这两个缓存类的定义:
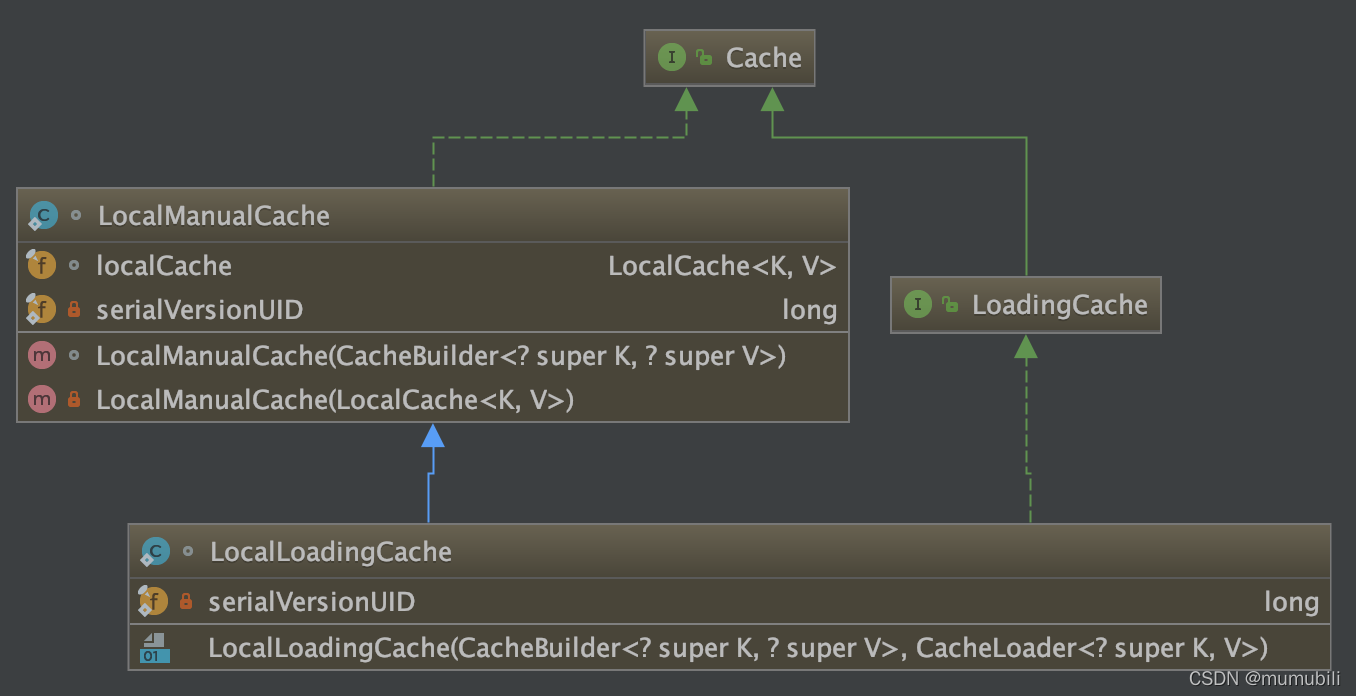
LocalManualCache
static class LocalManualCache<K, V> implements Cache<K, V>, Serializable {
final LocalCache<K, V> localCache;
LocalManualCache(CacheBuilder<? super K, ? super V> builder) {
this(new LocalCache<K, V>(builder, null));
}
private LocalManualCache(LocalCache<K, V> localCache) {
this.localCache = localCache;
}
// Cache methods
@Override
@Nullable
public V getIfPresent(Object key) {
return localCache.getIfPresent(key);
}
@Override
public V get(K key, final Callable<? extends V> valueLoader) throws ExecutionException {
checkNotNull(valueLoader);
return localCache.get(
key,
new CacheLoader<Object, V>() {
@Override
public V load(Object key) throws Exception {
return valueLoader.call();
}
});
}
@Override
public ImmutableMap<K, V> getAllPresent(Iterable<?> keys) {
return localCache.getAllPresent(keys);
}
@Override
public void put(K key, V value) {
localCache.put(key, value);
}
@Override
public void putAll(Map<? extends K, ? extends V> m) {
localCache.putAll(m);
}
@Override
public void invalidate(Object key) {
checkNotNull(key);
localCache.remove(key);
}
@Override
public void invalidateAll(Iterable<?> keys) {
localCache.invalidateAll(keys);
}
@Override
public void invalidateAll() {
localCache.clear();
}
@Override
public long size() {
return localCache.longSize();
}
@Override
public ConcurrentMap<K, V> asMap() {
return localCache;
}
@Override
public CacheStats stats() {
SimpleStatsCounter aggregator = new SimpleStatsCounter();
aggregator.incrementBy(localCache.globalStatsCounter);
for (Segment<K, V> segment : localCache.segments) {
aggregator.incrementBy(segment.statsCounter);
}
return aggregator.snapshot();
}
@Override
public void cleanUp() {
localCache.cleanUp();
}
// Serialization Support
private static final long serialVersionUID = 1;
Object writeReplace() {
return new ManualSerializationProxy<K, V>(localCache);
}
}
可以看到:
- LocalManualCache实现Cache接口,运用组合模式,在构造函数中构造了LocalCache类,Cache接口方法的实现都是委托给LocalCache完成的;
LocalLoadingCache
static class LocalLoadingCache<K, V> extends LocalManualCache<K, V>
implements LoadingCache<K, V> {
LocalLoadingCache(
CacheBuilder<? super K, ? super V> builder, CacheLoader<? super K, V> loader) {
super(new LocalCache<K, V>(builder, checkNotNull(loader)));
}
// LoadingCache methods
@Override
public V get(K key) throws ExecutionException {
return localCache.getOrLoad(key);
}
@Override
public V getUnchecked(K key) {
try {
return get(key);
} catch (ExecutionException e) {
throw new UncheckedExecutionException(e.getCause());
}
}
@Override
public ImmutableMap<K, V> getAll(Iterable<? extends K> keys) throws ExecutionException {
return localCache.getAll(keys);
}
@Override
public void refresh(K key) {
localCache.refresh(key);
}
@Override
public final V apply(K key) {
return getUnchecked(key);
}
// Serialization Support
private static final long serialVersionUID = 1;
@Override
Object writeReplace() {
return new LoadingSerializationProxy<K, V>(localCache);
}
}
}
LocalLoadingCache继承LocalManualCache类,并实现 LoadingCache 接口,在构造函数中同样构造了LocalCache类,LoadingCache接口方法同样是委托给 LocalCache 来完成的,下面着重分析下LocalCache的构造以及原理;
LocalCache
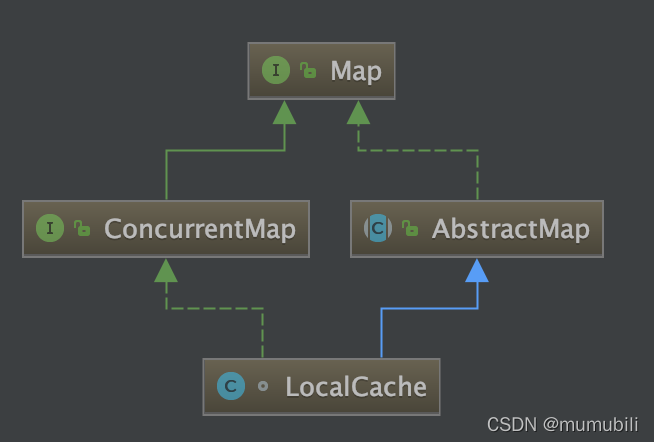
LocalCache继承结构如上,主要实现了AbstractMap和ConcurrentMap接口;
这里着重分析一下LocalCache的构造函数,以及几个核心接口源码实现;
构造方法
/**
* Creates a new, empty map with the specified strategy, initial capacity and concurrency level.
*/
LocalCache(
CacheBuilder<? super K, ? super V> builder, @Nullable CacheLoader<? super K, V> loader) {
concurrencyLevel = Math.min(builder.getConcurrencyLevel(), MAX_SEGMENTS);
keyStrength = builder.getKeyStrength();
valueStrength = builder.getValueStrength();
keyEquivalence = builder.getKeyEquivalence();
valueEquivalence = builder.getValueEquivalence();
maxWeight = builder.getMaximumWeight();
weigher = builder.getWeigher();
expireAfterAccessNanos = builder.getExpireAfterAccessNanos();
expireAfterWriteNanos = builder.getExpireAfterWriteNanos();
refreshNanos = builder.getRefreshNanos();
removalListener = builder.getRemovalListener();
removalNotificationQueue =
(removalListener == NullListener.INSTANCE)
? LocalCache.<RemovalNotification<K, V>>discardingQueue()
: new ConcurrentLinkedQueue<RemovalNotification<K, V>>();
ticker = builder.getTicker(recordsTime());
entryFactory = EntryFactory.getFactory(keyStrength, usesAccessEntries(), usesWriteEntries());
globalStatsCounter = builder.getStatsCounterSupplier().get();
defaultLoader = loader;
int initialCapacity = Math.min(builder.getInitialCapacity(), MAXIMUM_CAPACITY);
if (evictsBySize() && !customWeigher()) {
initialCapacity = Math.min(initialCapacity, (int) maxWeight);
}
// Find the lowest power-of-two segmentCount that exceeds concurrencyLevel, unless
// maximumSize/Weight is specified in which case ensure that each segment gets at least 10
// entries. The special casing for size-based eviction is only necessary because that eviction
// happens per segment instead of globally, so too many segments compared to the maximum size
// will result in random eviction behavior.
int segmentShift = 0;
int segmentCount = 1;
while (segmentCount < concurrencyLevel && (!evictsBySize() || segmentCount * 20 <= maxWeight)) {
++segmentShift;
segmentCount <<= 1;
}
this.segmentShift = 32 - segmentShift;
segmentMask = segmentCount - 1;
this.segments = newSegmentArray(segmentCount);
int segmentCapacity = initialCapacity / segmentCount;
if (segmentCapacity * segmentCount < initialCapacity) {
++segmentCapacity;
}
int segmentSize = 1;
while (segmentSize < segmentCapacity) {
segmentSize <<= 1;
}
if (evictsBySize()) {
// Ensure sum of segment max weights = overall max weights
long maxSegmentWeight = maxWeight / segmentCount + 1;
long remainder = maxWeight % segmentCount;
for (int i = 0; i < this.segments.length; ++i) {
if (i == remainder) {
maxSegmentWeight--;
}
this.segments[i] =
createSegment(segmentSize, maxSegmentWeight, builder.getStatsCounterSupplier().get());
}
} else {
for (int i = 0; i < this.segments.length; ++i) {
this.segments[i] =
createSegment(segmentSize, UNSET_INT, builder.getStatsCounterSupplier().get());
}
}
}
这里构造函数中包含的属性也主要是上面CacheBuilder传递的,下面着重解析如下几个属性:
- EntryFactory
- segments域字段
EntryFactory工厂类
/**
* Creates new entries.
*/
enum EntryFactory {
STRONG {
@Override
<K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return new StrongEntry<K, V>(key, hash, next);
}
},
STRONG_ACCESS {
@Override
<K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return new StrongAccessEntry<K, V>(key, hash, next);
}
@Override
<K, V> ReferenceEntry<K, V> copyEntry(
Segment<K, V> segment, ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) {
ReferenceEntry<K, V> newEntry = super.copyEntry(segment, original, newNext);
copyAccessEntry(original, newEntry);
return newEntry;
}
},
STRONG_WRITE {
@Override
<K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return new StrongWriteEntry<K, V>(key, hash, next);
}
@Override
<K, V> ReferenceEntry<K, V> copyEntry(
Segment<K, V> segment, ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) {
ReferenceEntry<K, V> newEntry = super.copyEntry(segment, original, newNext);
copyWriteEntry(original, newEntry);
return newEntry;
}
},
STRONG_ACCESS_WRITE {
@Override
<K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return new StrongAccessWriteEntry<K, V>(key, hash, next);
}
@Override
<K, V> ReferenceEntry<K, V> copyEntry(
Segment<K, V> segment, ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) {
ReferenceEntry<K, V> newEntry = super.copyEntry(segment, original, newNext);
copyAccessEntry(original, newEntry);
copyWriteEntry(original, newEntry);
return newEntry;
}
},
WEAK {
@Override
<K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return new WeakEntry<K, V>(segment.keyReferenceQueue, key, hash, next);
}
},
WEAK_ACCESS {
@Override
<K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return new WeakAccessEntry<K, V>(segment.keyReferenceQueue, key, hash, next);
}
@Override
<K, V> ReferenceEntry<K, V> copyEntry(
Segment<K, V> segment, ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) {
ReferenceEntry<K, V> newEntry = super.copyEntry(segment, original, newNext);
copyAccessEntry(original, newEntry);
return newEntry;
}
},
WEAK_WRITE {
@Override
<K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return new WeakWriteEntry<K, V>(segment.keyReferenceQueue, key, hash, next);
}
@Override
<K, V> ReferenceEntry<K, V> copyEntry(
Segment<K, V> segment, ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) {
ReferenceEntry<K, V> newEntry = super.copyEntry(segment, original, newNext);
copyWriteEntry(original, newEntry);
return newEntry;
}
},
WEAK_ACCESS_WRITE {
@Override
<K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return new WeakAccessWriteEntry<K, V>(segment.keyReferenceQueue, key, hash, next);
}
@Override
<K, V> ReferenceEntry<K, V> copyEntry(
Segment<K, V> segment, ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) {
ReferenceEntry<K, V> newEntry = super.copyEntry(segment, original, newNext);
copyAccessEntry(original, newEntry);
copyWriteEntry(original, newEntry);
return newEntry;
}
};
/**
* Masks used to compute indices in the following table.
*/
static final int ACCESS_MASK = 1;
static final int WRITE_MASK = 2;
static final int WEAK_MASK = 4;
/**
* Look-up table for factories.
*/
static final EntryFactory[] factories = {
STRONG,
STRONG_ACCESS,
STRONG_WRITE,
STRONG_ACCESS_WRITE,
WEAK,
WEAK_ACCESS,
WEAK_WRITE,
WEAK_ACCESS_WRITE,
};
static EntryFactory getFactory(
Strength keyStrength, boolean usesAccessQueue, boolean usesWriteQueue) {
int flags =
((keyStrength == Strength.WEAK) ? WEAK_MASK : 0)
| (usesAccessQueue ? ACCESS_MASK : 0)
| (usesWriteQueue ? WRITE_MASK : 0);
return factories[flags];
}
/**
* Creates a new entry.
*
* @param segment to create the entry for
* @param key of the entry
* @param hash of the key
* @param next entry in the same bucket
*/
abstract <K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next);
/**
* Copies an entry, assigning it a new {@code next} entry.
*
* @param original the entry to copy
* @param newNext entry in the same bucket
*/
// Guarded By Segment.this
<K, V> ReferenceEntry<K, V> copyEntry(
Segment<K, V> segment, ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) {
return newEntry(segment, original.getKey(), original.getHash(), newNext);
}
// Guarded By Segment.this
<K, V> void copyAccessEntry(ReferenceEntry<K, V> original, ReferenceEntry<K, V> newEntry) {
// TODO(fry): when we link values instead of entries this method can go
// away, as can connectAccessOrder, nullifyAccessOrder.
newEntry.setAccessTime(original.getAccessTime());
connectAccessOrder(original.getPreviousInAccessQueue(), newEntry);
connectAccessOrder(newEntry, original.getNextInAccessQueue());
nullifyAccessOrder(original);
}
// Guarded By Segment.this
<K, V> void copyWriteEntry(ReferenceEntry<K, V> original, ReferenceEntry<K, V> newEntry) {
// TODO(fry): when we link values instead of entries this method can go
// away, as can connectWriteOrder, nullifyWriteOrder.
newEntry.setWriteTime(original.getWriteTime());
connectWriteOrder(original.getPreviousInWriteQueue(), newEntry);
connectWriteOrder(newEntry, original.getNextInWriteQueue());
nullifyWriteOrder(original);
}
}
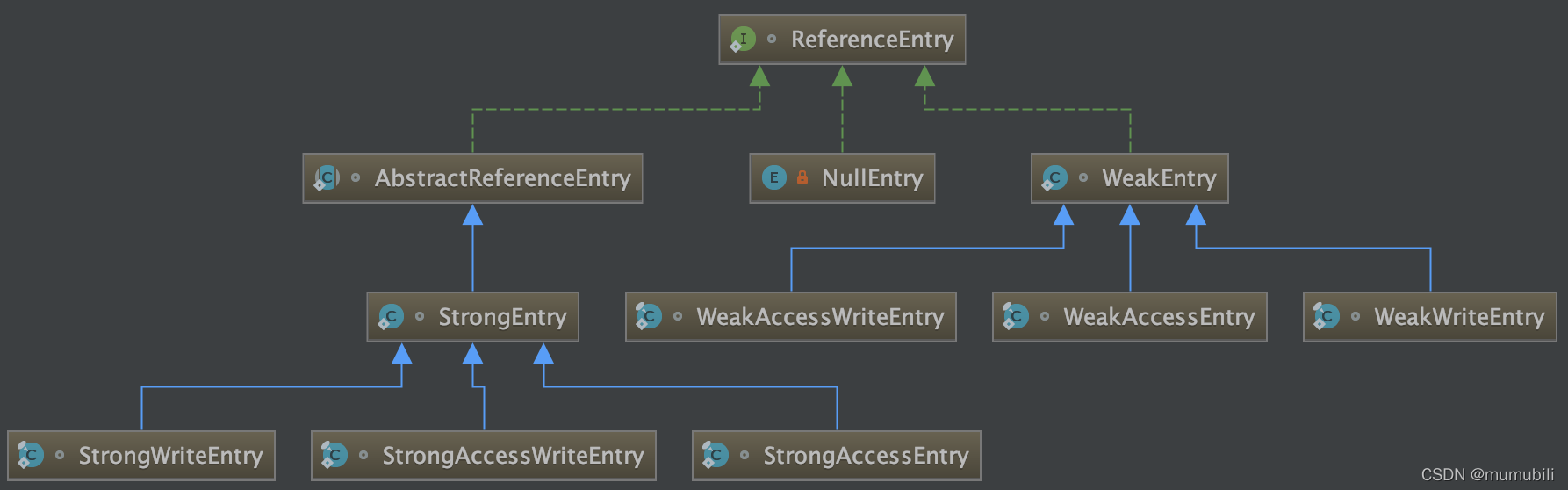
EntryFactory主要用于构造ReferenceEntry对象,包含new方法和copy方法;
ReferenceEntry表示每一个(key,value)缓存对象元素的实例对象;
这里主要是根据key的引用强度(强引用 or 弱引用)以及过期时间是根据writetime or accesstime分别实例化不同的对象,主要类继承结构如下:
Segment<K, V>[] segments域字段
segments表示缓存对象的存储结构,上面构造函数中详细说明了Segment的构造以及segmentSize和maxSegmentWeight是如何进行分配的;
Segment属性与构造函数
下面是Segment的属性和构造函数,通过注释可以较好的理解每个字段的含义;
static class Segment<K, V> extends ReentrantLock {
@Weak final LocalCache<K, V> map;
/**
* The number of live elements in this segment's region.
*/
volatile int count;
/**
* The weight of the live elements in this segment's region.
*/
@GuardedBy("this")
long totalWeight;
/**
* Number of updates that alter the size of the table. This is used during bulk-read methods to
* make sure they see a consistent snapshot: If modCounts change during a traversal of segments
* loading size or checking containsValue, then we might have an inconsistent view of state so
* (usually) must retry.
*/
int modCount;
/**
* The table is expanded when its size exceeds this threshold. (The value of this field is
* always {@code (int) (capacity * 0.75)}.)
*/
int threshold;
/**
* The per-segment table.
*/
volatile AtomicReferenceArray<ReferenceEntry<K, V>> table;
/**
* The maximum weight of this segment. UNSET_INT if there is no maximum.
*/
final long maxSegmentWeight;
/**
* The key reference queue contains entries whose keys have been garbage collected, and which
* need to be cleaned up internally.
*/
final ReferenceQueue<K> keyReferenceQueue;
/**
* The value reference queue contains value references whose values have been garbage collected,
* and which need to be cleaned up internally.
*/
final ReferenceQueue<V> valueReferenceQueue;
/**
* The recency queue is used to record which entries were accessed for updating the access
* list's ordering. It is drained as a batch operation when either the DRAIN_THRESHOLD is
* crossed or a write occurs on the segment.
*/
final Queue<ReferenceEntry<K, V>> recencyQueue;
/**
* A counter of the number of reads since the last write, used to drain queues on a small
* fraction of read operations.
*/
final AtomicInteger readCount = new AtomicInteger();
/**
* A queue of elements currently in the map, ordered by write time. Elements are added to the
* tail of the queue on write.
*/
@GuardedBy("this")
final Queue<ReferenceEntry<K, V>> writeQueue;
/**
* A queue of elements currently in the map, ordered by access time. Elements are added to the
* tail of the queue on access (note that writes count as accesses).
*/
@GuardedBy("this")
final Queue<ReferenceEntry<K, V>> accessQueue;
/** Accumulates cache statistics. */
final StatsCounter statsCounter;
Segment(
LocalCache<K, V> map,
int initialCapacity,
long maxSegmentWeight,
StatsCounter statsCounter) {
this.map = map;
this.maxSegmentWeight = maxSegmentWeight;
this.statsCounter = checkNotNull(statsCounter);
initTable(newEntryArray(initialCapacity));
keyReferenceQueue = map.usesKeyReferences() ? new ReferenceQueue<K>() : null;
valueReferenceQueue = map.usesValueReferences() ? new ReferenceQueue<V>() : null;
recencyQueue =
map.usesAccessQueue()
? new ConcurrentLinkedQueue<ReferenceEntry<K, V>>()
: LocalCache.<ReferenceEntry<K, V>>discardingQueue();
writeQueue =
map.usesWriteQueue()
? new WriteQueue<K, V>()
: LocalCache.<ReferenceEntry<K, V>>discardingQueue();
accessQueue =
map.usesAccessQueue()
? new AccessQueue<K, V>()
: LocalCache.<ReferenceEntry<K, V>>discardingQueue();
}
AtomicReferenceArray<ReferenceEntry<K, V>> newEntryArray(int size) {
return new AtomicReferenceArray<ReferenceEntry<K, V>>(size);
}
}
LocalCache核心接口实现
理解了上面LocalCache的构造以及Segment<K, V>[] segments的构造,下面着重分析下几个核心接口的实现原理;
put流程
@Override
public V put(K key, V value) {
checkNotNull(key);
checkNotNull(value);
int hash = hash(key);
return segmentFor(hash).put(key, hash, value, false);
}
@Override
public V putIfAbsent(K key, V value) {
checkNotNull(key);
checkNotNull(value);
int hash = hash(key);
return segmentFor(hash).put(key, hash, value, true);
}
put和putIfAbsent的流程类似,这里主要分析下put的流程:
- 通过hash定位该key应该位于哪个Segment
- 调用Segment的put方法完成键值的插入
下面会解析Segment的put流程;
get流程
@Override
@Nullable
public V get(@Nullable Object key) {
if (key == null) {
return null;
}
int hash = hash(key);
return segmentFor(hash).get(key, hash);
}
@Nullable
public V getIfPresent(Object key) {
int hash = hash(checkNotNull(key));
V value = segmentFor(hash).get(key, hash);
if (value == null) {
globalStatsCounter.recordMisses(1);
} else {
globalStatsCounter.recordHits(1);
}
return value;
}
@Nullable
public V getOrDefault(@Nullable Object key, @Nullable V defaultValue) {
V result = get(key);
return (result != null) ? result : defaultValue;
}
- 通过hash定位该key应该位于哪个Segment
- 调用Segment的get方法进行查询
下面会解析Segment的get流程;
getOrLoad流程
V get(K key, CacheLoader<? super K, V> loader) throws ExecutionException {
int hash = hash(checkNotNull(key));
return segmentFor(hash).get(key, hash, loader);
}
V getOrLoad(K key) throws ExecutionException {
return get(key, defaultLoader);
}
- 通过hash定位该key应该位于哪个Segment
- 调用Segment的get方法进行查询
下面会解析Segment的get流程;
refresh 流程
void refresh(K key) {
int hash = hash(checkNotNull(key));
segmentFor(hash).refresh(key, hash, defaultLoader, false);
}
同样委托给Segment进行refresh;
Segment核心流程
put流程
@Nullable
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock(); //每个segment写操作都需要加锁
try {
long now = map.ticker.read();
preWriteCleanup(now); //put前的一些操作,1.垃圾回收的键值进行移除 2.过期的键值进行移除
int newCount = this.count + 1;
if (newCount > this.threshold) { // ensure capacity
expand();
newCount = this.count + 1;
}
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
// Look for an existing entry.
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash
&& entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
// We found an existing entry.
ValueReference<K, V> valueReference = e.getValueReference();
V entryValue = valueReference.get();
if (entryValue == null) {
++modCount;
if (valueReference.isActive()) {
enqueueNotification(
key, hash, entryValue, valueReference.getWeight(), RemovalCause.COLLECTED);
setValue(e, key, value, now);
newCount = this.count; // count remains unchanged
} else {
setValue(e, key, value, now);
newCount = this.count + 1;
}
this.count = newCount; // write-volatile
evictEntries(e);
return null;
} else if (onlyIfAbsent) {
// Mimic
// "if (!map.containsKey(key)) ...
// else return map.get(key);
recordLockedRead(e, now);
return entryValue;
} else {
// clobber existing entry, count remains unchanged
++modCount;
enqueueNotification(
key, hash, entryValue, valueReference.getWeight(), RemovalCause.REPLACED);
setValue(e, key, value, now);
evictEntries(e);
return entryValue;
}
}
}
// Create a new entry.
++modCount;
ReferenceEntry<K, V> newEntry = newEntry(key, hash, first);
setValue(newEntry, key, value, now);
table.set(index, newEntry);
newCount = this.count + 1;
this.count = newCount; // write-volatile
evictEntries(newEntry);
return null;
} finally {
unlock();
postWriteCleanup();
}
}
put方法主要包含流程有:
- put前需要完成:
- 1)垃圾回收的键值进行移除
- 2)过期的键值进行移除
- 元素个数达到阈值threshold,调用expand方法进行扩容
- 查找table是否已存在,存在更新(onlyIfAbsent=true),不存在插入
- 调用evictEntries方法查看是否需要移除元素,移除accessTime最早的元素;
- 通知removalListener;
get流程
@Nullable
V get(Object key, int hash) {
try {
if (count != 0) { // read-volatile
long now = map.ticker.read();
ReferenceEntry<K, V> e = getLiveEntry(key, hash, now);
if (e == null) {
return null;
}
V value = e.getValueReference().get();
if (value != null) {
recordRead(e, now);
return scheduleRefresh(e, e.getKey(), hash, value, now, map.defaultLoader);
}
tryDrainReferenceQueues();
}
return null;
} finally {
postReadCleanup();
}
}
@Nullable
ReferenceEntry<K, V> getLiveEntry(Object key, int hash, long now) {
ReferenceEntry<K, V> e = getEntry(key, hash);
if (e == null) {
return null;
} else if (map.isExpired(e, now)) {
tryExpireEntries(now);
return null;
}
return e;
}
- 查询元素是否存在,不存在返回null
- 校验该元素是否过期,如果过期,清理所有过期元素,然后返回null;
- 校验value值是否为null(垃圾回收),如果为null,批次清理垃圾回收的元素,返回null
- value不为null,重新设置accessTime为now
- 是否配置了刷新周期,达到刷新周期,调用刷新函数进行刷新,refresh流程阐述如下;
refresh流程
/**
* Refreshes the value associated with {@code key}, unless another thread is already doing so.
* Returns the newly refreshed value associated with {@code key} if it was refreshed inline, or
* {@code null} if another thread is performing the refresh or if an error occurs during
* refresh.
*/
@Nullable
V refresh(K key, int hash, CacheLoader<? super K, V> loader, boolean checkTime) {
final LoadingValueReference<K, V> loadingValueReference =
insertLoadingValueReference(key, hash, checkTime);
if (loadingValueReference == null) {
return null;
}
ListenableFuture<V> result = loadAsync(key, hash, loadingValueReference, loader);
if (result.isDone()) {
try {
return Uninterruptibles.getUninterruptibly(result);
} catch (Throwable t) {
// don't let refresh exceptions propagate; error was already logged
}
}
return null;
}
ListenableFuture<V> loadAsync(
final K key,
final int hash,
final LoadingValueReference<K, V> loadingValueReference,
CacheLoader<? super K, V> loader) {
final ListenableFuture<V> loadingFuture = loadingValueReference.loadFuture(key, loader);
loadingFuture.addListener(
new Runnable() {
@Override
public void run() {
try {
getAndRecordStats(key, hash, loadingValueReference, loadingFuture);
} catch (Throwable t) {
logger.log(Level.WARNING, "Exception thrown during refresh", t);
loadingValueReference.setException(t);
}
}
},
directExecutor());
return loadingFuture;
}
- 插入LoadingValueReference,对新值进行加载
- 调用loadAsync进行异步加载
- 设置加载的新值并返回
RemovalListener流程
Guava Cache中的元素在移除的时候,支持自定义RemovalListener,完成对remove操作的监听,对应的监听接口为 RemovalListener,定义如下:
RemovalListener接口
/**
* An object that can receive a notification when an entry is removed from a cache. The removal
* resulting in notification could have occured to an entry being manually removed or replaced, or
* due to eviction resulting from timed expiration, exceeding a maximum size, or garbage collection.
*
* <p>An instance may be called concurrently by multiple threads to process different entries.
* Implementations of this interface should avoid performing blocking calls or synchronizing on
* shared resources.
*
* @param <K> the most general type of keys this listener can listen for; for example {@code Object}
* if any key is acceptable
* @param <V> the most general type of values this listener can listen for; for example
* {@code Object} if any key is acceptable
* @author Charles Fry
* @since 10.0
*/
@GwtCompatible
public interface RemovalListener<K, V> {
/**
* Notifies the listener that a removal occurred at some point in the past.
*
* <p>This does not always signify that the key is now absent from the cache, as it may have
* already been re-added.
*/
// Technically should accept RemovalNotification<? extends K, ? extends V>, but because
// RemovalNotification is guaranteed covariant, let's make users' lives simpler.
void onRemoval(RemovalNotification<K, V> notification);
}
RemovalNotification对象
实现子类通过onRemoval方法完成对remove操作的监听,这里监听的对象为RemovalNotification:
/**
* A notification of the removal of a single entry. The key and/or value may be null if they were
* already garbage collected.
*
* <p>Like other {@code Map.Entry} instances associated with {@code CacheBuilder}, this class holds
* strong references to the key and value, regardless of the type of references the cache may be
* using.
*
* @author Charles Fry
* @since 10.0
*/
@GwtCompatible
public final class RemovalNotification<K, V> extends SimpleImmutableEntry<K, V> {
private final RemovalCause cause;
/**
* Creates a new {@code RemovalNotification} for the given {@code key}/{@code value} pair, with
* the given {@code cause} for the removal. The {@code key} and/or {@code value} may be
* {@code null} if they were already garbage collected.
*
* @since 19.0
*/
public static <K, V> RemovalNotification<K, V> create(
@Nullable K key, @Nullable V value, RemovalCause cause) {
return new RemovalNotification(key, value, cause);
}
private RemovalNotification(@Nullable K key, @Nullable V value, RemovalCause cause) {
super(key, value);
this.cause = checkNotNull(cause);
}
/**
* Returns the cause for which the entry was removed.
*/
public RemovalCause getCause() {
return cause;
}
/**
* Returns {@code true} if there was an automatic removal due to eviction (the cause is neither
* {@link RemovalCause#EXPLICIT} nor {@link RemovalCause#REPLACED}).
*/
public boolean wasEvicted() {
return cause.wasEvicted();
}
private static final long serialVersionUID = 0;
}
父类SimpleImmutableEntry是一个不可变对象,定义如下:
/**
* An Entry maintaining an immutable key and value. This class
* does not support method <tt>setValue</tt>. This class may be
* convenient in methods that return thread-safe snapshots of
* key-value mappings.
*
* @since 1.6
*/
public static class SimpleImmutableEntry<K,V>
implements Entry<K,V>, java.io.Serializable
{
private static final long serialVersionUID = 7138329143949025153L;
private final K key;
private final V value;
/**
* Creates an entry representing a mapping from the specified
* key to the specified value.
*
* @param key the key represented by this entry
* @param value the value represented by this entry
*/
public SimpleImmutableEntry(K key, V value) {
this.key = key;
this.value = value;
}
/**
* Creates an entry representing the same mapping as the
* specified entry.
*
* @param entry the entry to copy
*/
public SimpleImmutableEntry(Entry<? extends K, ? extends V> entry) {
this.key = entry.getKey();
this.value = entry.getValue();
}
/**
* Returns the key corresponding to this entry.
*
* @return the key corresponding to this entry
*/
public K getKey() {
return key;
}
/**
* Returns the value corresponding to this entry.
*
* @return the value corresponding to this entry
*/
public V getValue() {
return value;
}
/**
* Replaces the value corresponding to this entry with the specified
* value (optional operation). This implementation simply throws
* <tt>UnsupportedOperationException</tt>, as this class implements
* an <i>immutable</i> map entry.
*
* @param value new value to be stored in this entry
* @return (Does not return)
* @throws UnsupportedOperationException always
*/
public V setValue(V value) {
throw new UnsupportedOperationException();
}
/**
* Compares the specified object with this entry for equality.
* Returns {@code true} if the given object is also a map entry and
* the two entries represent the same mapping. More formally, two
* entries {@code e1} and {@code e2} represent the same mapping
* if<pre>
* (e1.getKey()==null ?
* e2.getKey()==null :
* e1.getKey().equals(e2.getKey()))
* &&
* (e1.getValue()==null ?
* e2.getValue()==null :
* e1.getValue().equals(e2.getValue()))</pre>
* This ensures that the {@code equals} method works properly across
* different implementations of the {@code Map.Entry} interface.
*
* @param o object to be compared for equality with this map entry
* @return {@code true} if the specified object is equal to this map
* entry
* @see #hashCode
*/
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
return eq(key, e.getKey()) && eq(value, e.getValue());
}
/**
* Returns the hash code value for this map entry. The hash code
* of a map entry {@code e} is defined to be: <pre>
* (e.getKey()==null ? 0 : e.getKey().hashCode()) ^
* (e.getValue()==null ? 0 : e.getValue().hashCode())</pre>
* This ensures that {@code e1.equals(e2)} implies that
* {@code e1.hashCode()==e2.hashCode()} for any two Entries
* {@code e1} and {@code e2}, as required by the general
* contract of {@link Object#hashCode}.
*
* @return the hash code value for this map entry
* @see #equals
*/
public int hashCode() {
return (key == null ? 0 : key.hashCode()) ^
(value == null ? 0 : value.hashCode());
}
/**
* Returns a String representation of this map entry. This
* implementation returns the string representation of this
* entry's key followed by the equals character ("<tt>=</tt>")
* followed by the string representation of this entry's value.
*
* @return a String representation of this map entry
*/
public String toString() {
return key + "=" + value;
}
}
同时,RemovalNotification还包含一个RemovalCause对象,标识每次remove操作的原因:
/**
* The reason why a cached entry was removed.
*
* @author Charles Fry
* @since 10.0
*/
@GwtCompatible
public enum RemovalCause {
/**
* The entry was manually removed by the user. This can result from the user invoking
* {@link Cache#invalidate}, {@link Cache#invalidateAll(Iterable)}, {@link Cache#invalidateAll()},
* {@link Map#remove}, {@link ConcurrentMap#remove}, or {@link Iterator#remove}.
*/
EXPLICIT {
@Override
boolean wasEvicted() {
return false;
}
},
/**
* The entry itself was not actually removed, but its value was replaced by the user. This can
* result from the user invoking {@link Cache#put}, {@link LoadingCache#refresh}, {@link Map#put},
* {@link Map#putAll}, {@link ConcurrentMap#replace(Object, Object)}, or
* {@link ConcurrentMap#replace(Object, Object, Object)}.
*/
REPLACED {
@Override
boolean wasEvicted() {
return false;
}
},
/**
* The entry was removed automatically because its key or value was garbage-collected. This can
* occur when using {@link CacheBuilder#weakKeys}, {@link CacheBuilder#weakValues}, or
* {@link CacheBuilder#softValues}.
*/
COLLECTED {
@Override
boolean wasEvicted() {
return true;
}
},
/**
* The entry's expiration timestamp has passed. This can occur when using
* {@link CacheBuilder#expireAfterWrite} or {@link CacheBuilder#expireAfterAccess}.
*/
EXPIRED {
@Override
boolean wasEvicted() {
return true;
}
},
/**
* The entry was evicted due to size constraints. This can occur when using
* {@link CacheBuilder#maximumSize} or {@link CacheBuilder#maximumWeight}.
*/
SIZE {
@Override
boolean wasEvicted() {
return true;
}
};
/**
* Returns {@code true} if there was an automatic removal due to eviction (the cause is neither
* {@link #EXPLICIT} nor {@link #REPLACED}).
*/
abstract boolean wasEvicted();
}
RemovalListeners
RemovalListeners通过asynchronous方法将一个RemovalListener转变为一个可以异步执行的RemovalListener;
/**
* A collection of common removal listeners.
*
* @author Charles Fry
* @since 10.0
*/
@GwtIncompatible
public final class RemovalListeners {
private RemovalListeners() {}
/**
* Returns a {@code RemovalListener} which processes all eviction notifications using
* {@code executor}.
*
* @param listener the backing listener
* @param executor the executor with which removal notifications are asynchronously executed
*/
public static <K, V> RemovalListener<K, V> asynchronous(
final RemovalListener<K, V> listener, final Executor executor) {
checkNotNull(listener);
checkNotNull(executor);
return new RemovalListener<K, V>() {
@Override
public void onRemoval(final RemovalNotification<K, V> notification) {
executor.execute(
new Runnable() {
@Override
public void run() {
listener.onRemoval(notification);
}
});
}
};
}
}
3.5 核心特点
过期淘汰策略
Guava 提供了多种缓存过期策略,可以根据具体需求选择合适的策略,可以通过CacheBuilder在build()时同时指定。。以下是一些常见的缓存过期策略:
- 基于时间的过期策略:可以设置缓存项在固定时间后过期,使用
expireAfterWrite方法来指定写入后多久过期,或使用expireAfterAccess方法指定最后一次访问后多久过期。 - 基于大小的过期策略:可以设置缓存项的最大数量,当缓存项超过设定的最大数量时,根据 LRU(最近最少使用)算法删除过期的缓存项。
- 基于引用的过期策略:可以使用弱引用或软引用来保存缓存项,当垃圾回收器对这些引用对象进行回收时,缓存项也会被移除。
- 自定义的过期策略:Guava 还提供了自定义的缓存过期策略接口
CacheLoader,可以通过实现该接口来定义自己的过期策略。
需要特別注意:Guava 缓存只会在外部请求,并于写入或访问时进行过期检查,并不会自动定时检查。
/**
* LoadingCache 继承自 Cache,在构建 LoadingCache 时,需通过 CacheBuilder 的 build(CacheLoader<? super K1, V1> loader)构建
*/
public static LoadingCache<String, Product> buildCache() {
CacheBuilder<Object, Object> builder = CacheBuilder.newBuilder();
return builder
// 2秒未写入则淘汰
.expireAfterWrite(2, TimeUnit.SECONDS)
// 3秒未访问则淘汰
.expireAfterAccess(3,TimeUnit.SECONDS)
// 4秒未写入则刷新
.refreshAfterWrite(4,TimeUnit.SECONDS)
.build(new CacheLoader<String, Product>() {
@Override
public Product load(String key) throws Exception {
System.out.println("从数据库查询产品");
return new Product(key, "产品".concat(key), new BigDecimal(10), "自定义产品");
}
});
}
- expireAfterWrite:当缓存项指定时间未更新则淘汰;
- expireAfterAccess:当缓存项指定时间未访问则淘汰;
- refreshAfterWrite:当缓存项上次被更新后多久会被刷新。
- refreshAfterWrite这个策略比较特殊——1)当第一个请求执行load()把数据加载进缓存后,如果指定的过期时间是3秒,则在这3秒内获取缓存项都会从缓存中获取;2)在3秒后如果没有访问,缓存数据不会被淘汰;3)当有新的请求(requestX)访问时,才会清理过期数据、并执行load()方法重新加载,这个过程只会阻塞当前请求(requestX)的线程;4)如果在load()加载过程中有其他线程也访问同一个key,则:会立即返回原来的缓存数据,不会阻塞。
- refreshAfterWrite的机制会导致如果有很长一段时间没有访问,突然有多个线程访问时,会拿到旧值,这个旧值可能是很久以前的。
- 所以,一般都会使用 expireAfterAccess 和 refreshAfterWrite 搭配使用。缓存清除
- LoadingCache
- 顾名思义,它能够通过CacheLoader自发的加载缓存:
LoadingCache<Object, Object> loadingCache = CacheBuilder.newBuilder().build(
new CacheLoader<Object, Object>() {
@Override
public Object load(Object key) throws Exception {
return null;
}
}
);
// 获取缓存,当缓存不存在时,会通过CacheLoader自动加载源头的数据至缓存中,该方法会抛出ExecutionException
loadingCache.get("k1");
// 以不安全的方式获取缓存,当缓存不存在时,会通过CacheLoader自动加载,该方法不会抛出异常
loadingCache.getUnchecked("k1");
缓存清除
在实际场景中,在创建Cache对象时虽然指定了淘汰策略,某些情况下可能仍需要手动进行缓存的清除,来达到刷新缓存的目的。
- Cache.invalidate(key):按照key单个清除;
- Cache.invalidateAll(keys):按照keys批量清除;
- Cache.invalidateAll():清除所有缓存项;
清除回调
开始介绍JVM缓存时有说过,Guava Cache支持清除回调,可以在缓存被清除时执行一个回调方法,便于我们做一些分析和统计。
public static LoadingCache<String, Product> buildCache() {
CacheBuilder<Object, Object> builder = CacheBuilder.newBuilder();
return builder
.expireAfterAccess(3, TimeUnit.SECONDS)
// 注册一个缓存被清除时的监听器
.removalListener(removalNotification -> {
System.out.printf(
"产品:%s被清除,移除原因:%s \n"
, removalNotification.getKey()
, removalNotification.getCause()
);
})
.build(new CacheLoader<String, Product>() {
@Override
public Product load(String key) throws Exception {
System.out.println("从数据库查询产品");
return new Product(key, "产品".concat(key), new BigDecimal(10), "自定义产品");
}
});
}
由上面代码可以看出,只需要在CacheBuilder上注册一个监听器,便可以在缓存被清除时执行监听器中的代码。
需要注意的是,只支持注册一个监听器,如果重复注册,则会抛出在注册时抛出异常。
上面代码中的这种注册方式的监听器在缓存被移除时,监听器的执行和缓存清除的线程是同步执行的,也就是说,如果清除缓存中的代码运行时间较长,则对应的invalidate方法执行时间也会变长。
public static LoadingCache<String, Product> buildCache() {
CacheBuilder<Object, Object> builder = CacheBuilder.newBuilder();
return builder
.expireAfterAccess(3, TimeUnit.SECONDS)
// 注册异步监听
.removalListener(RemovalListeners.asynchronous(
removalNotification ->
System.out.printf(
"产品:%s被清除,移除原因:%s \n"
, removalNotification.getKey()
, removalNotification.getCause()
),
Executors.newSingleThreadExecutor()
)).build(new CacheLoader<String, Product>() {
@Override
public Product load(String key) throws Exception {
System.out.println("从数据库查询产品");
return new Product(key, "产品".concat(key), new BigDecimal(10), "自定义一个产品");
}
});
}
解决这个问题则可以通过RemovalListeners.asynchronous(Listener,Executor)注册一个异步事件监听器,不过需要给这个异步事件监听指定一个线程池。
如果在监听器代码执行过程中抛出异常,不管是同步监听器还是异步监听器,都不会影响监听器的运行,Guava会将异常丢弃。
3.X 小结
至此,Guava Cache利用LocalCache类完成了对其属性的支持,内部也主要是依赖Segment类完成锁同步实现分段锁机制,允许多个线程并发更新操作;
在上述的核心接口实现中,包括了过期时间处理、过期回收策略、缓存加载机制、元素移除与通知机制、垃圾回收处理、用前后索引实现链表的基本操作处理、队列Queue基本操作等等,完美完成了对其声明属性的支持;