NaLLM 项目总结
前后端分离,前端Vue3,后端Fastapi
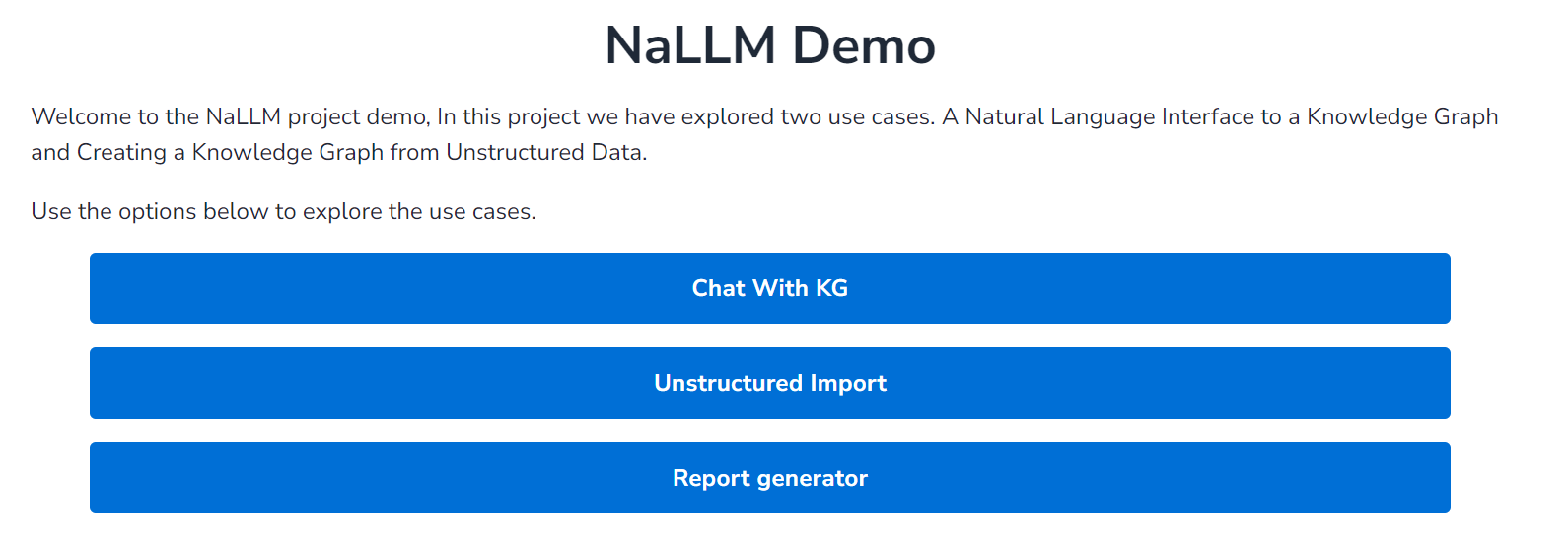
项目的整体界面如图:
主要实现三种功能:
-
Unstructured Import:实现非结构化文本的知识图谱提取和实体关系、去重等操作,最终返回提取的实体、关系和对应的属性,本项目也提供了将原始提取结果转换为CSV文件的类,便于结果的存储。
-
Chat with KG:用户实现与neo4j图数据库连接后,可以通过对话的方式实现询问知识图谱内部节点和关系以及对应的属性,大模型根据用户的问题自动的将问题转化为对应的Cypher查询,并执行Cypher查询后对结果进行润色,最终返回润色后的结果和对应的Cypher语句给界面。
-
Report generator:NaLLM项目初始连接的是关于公司主题的公开图数据库,这一部分主要是根据用户所选择的公司,返回公司的员工、位置、种类、基本概括等一些公司相关的信息(通过在知识图谱上执行一系列的Cypher查询)并将最后的结果以网页的形式展示给用户
先主要介绍后端的部分,(前端vue框架需要进一步的学习)。
后端整体架构结构是这样的:
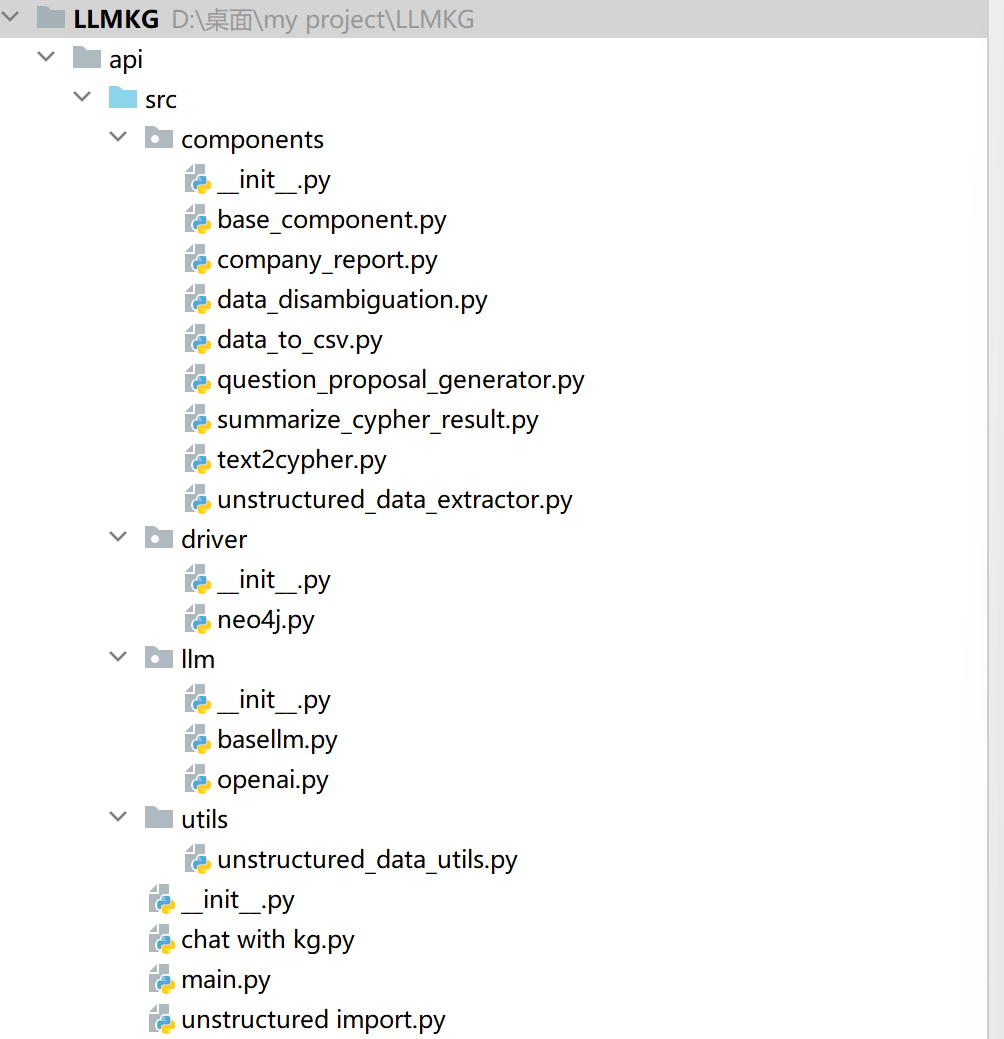
driver、llm、utils的文件夹主要实现一系列相关工具的调用。
其中driver中neo4j主要定义了图数据库连接相关的类,
这个类中query方法主要实现了给定连接的图数据库中cypher查询,执行cypher查询并返回处理结果,若cypher查询中存在错误时也会进行错误处理。
同时也实现schema提取,主要执行cypher语句实现图数据库中节点、关系属性以及关系本身提取。
llm中openai类实现了对大模型的调用,给定输入的system和user内容,输出大模型返回结果。同时也根据模型计算当前输入字符串的token数。
main函数主要是调用components中各种类的方法,实现知识图谱构建、知识图谱查询等的后端api。
项目核心为components,以不同的类为基础实现知识图谱构建、知识图谱查询等操作。
一. Unstructed import
这里面主要采用的为unstructed_data_extractor与data_disambiguation
1. unstructed_data_extractor
主要划分为DataExtractor(不带Schema)和DataExtractorWithSchema
两种是类似的
首先将原始待提取文本进行分块,每块大小的字符串长度为500,
同时计算每次最多输入多少token(大模型允许token数-system prompt的token数)。
尽可能多的将原始待提取文本对应的块塞入大模型的输入中,直到无法塞下。
这样就可以得到每轮输入的用户文本。
每轮输入的System prompt如下所示:
DataExtractor采用的System Prompt:
You are a data scientist working for a company that is building a graph database.
Your task is to extract information from data and convert it into a graph database.
Provide a set of Nodes in the form [ENTITY_ID, TYPE, PROPERTIES] and a set of relationships in the form [ENTITY_ID_1, RELATIONSHIP, ENTITY_ID_2, PROPERTIES].
It is important that the ENTITY_ID_1 and ENTITY_ID_2 exists as nodes with a matching ENTITY_ID.
If you can't pair a relationship with a pair of nodes don't add it.
When you find a node or relationship you want to add try to create a generic TYPE for it that describes the entity you can also think of it as a label.
You will be given a list of types that you should try to use when creating the TYPE for a node.
If you can't find a type that fits the node you can create a new one.
Example:
Data: Alice lawyer and is 25 years old and Bob is her roommate since 2001. Bob works as a journalist. Alice owns a the webpage www.alice.com and Bob owns the webpage www.bob.com.
Types: ["Person", "Webpage"]
Nodes:
["alice", "Person", {"age": 25, "occupation": "lawyer", "name":"Alice"}],
["bob", "Person", {"occupation": "journalist", "name": "Bob"}],
["alice.com", "Webpage", {"url": "www.alice.com"}],
["bob.com", "Webpage", {"url": "www.bob.com"}]
Relationships:
["alice", "roommate", "bob", {"start": 2021}],
["alice", "owns", "alice.com", {}],
["bob", "owns", "bob.com", {}]
采用的User prompt:
def generate_prompt_with_labels(data, labels) -> str:
return f"""
Data: {data}
Types: {labels}"""
这里的prompt主要是采用了one-shot的prompt,并且要求大模型直接从给定的输入的文本中提取出知识图谱。
在提取的过程中也会尝试使用大模型已经创建的labels来标记提取到的实体和关系,
若目前已有的labels无法来标记提取出的实体和关系,则尝试让大模型自己创造新的实体和关系对应的labels。
最后将每轮大模型的输出文本存储到results列表中,
最终在results列表中通过正则表达式匹配的方法得到所有的实体和关系。
DataExtractorWithSchema是类似的,不过区别在于Prompt的不同:
System Prompt
Only add nodes and relationships that are part of the schema.
If you don't get any relationships in the schema only add nodes.
Example:
Schema:
Nodes: [Person {age: integer, name: string}]
Relationships: [Person, roommate, Person]
User Prompt:
def generate_prompt_with_schema(data, schema) -> str:
return f"""
Schema: {schema}
Data: {data}"""
其他处理部分都是一致的。
评价:
1. 数据提取的过程中,并未采用任何的数据集进行测试并评价大模型的提取效果。
因此,我认为可以采用Wikipedia和Wikidata(Wikipedia对应的知识图谱)为基础来实现知识图谱抽取和知识图谱抽取效果的评价。之前分享的浙江大学DeepKE-LLM项目已经构造多个待抽取文本和抽取后三元组的example。其中待抽取文本为150-300左右的段落,并且DeepKE-LLM项目将文本划分为12个主题,一千条记录,包含中文和英文。可以选择其中的一个或多个主题来作为输入。下面是一个example(JSON格式):
{"id": 1000000,
"cate": "Building",
"input": "Krasinski Square is a square located in the center of Warsaw, the capital of Poland. This square is famous for its numerous historical buildings. The history of the square dates back to the late 18th century.",
"relation":
[{"head": "Krasinski Square", "relation": "creation time", "tail": "the late 18th century"},
{"head": "Krasinski Square", "relation": "located in", "tail": "Warsaw"}, {"head": "Warsaw", "relation": "located in", "tail": "Poland"}]}
这个数据集的缺陷在于没有涉及到长文本的提取和没有涉及到属性提取。
不过可以以此为基础来做。
-
一般情况下,用户并不乐意直接提供一大段文本用来实现知识图谱的构建。因此可以通过输入关键词的形式,并采用爬虫机制,抓取相关的文本文档,并以抓取到的信息为基础,进行知识图谱的构建。例如,如果要做人物主题的知识图谱,用户输入关键词“欧拉”,之后采用爬虫抓取描述欧拉相关的维基百科信息,根据抓取到的信息为基础实现KG构建。
-
关于长文本的处理:
NaLLM项目是直接将文本进行简单的分割再抽取,这样很容易直接丢失上下文信息。考虑引入如下的机制:
(1)保留上下文信息:
这里引入的第一种技巧就是summary,这点主要是保留上下文的信息,有助于三元组和属性的抽取和完善。
\[summary_i = summary(summary_{i-1},text_i) \] 需要注意的是 \(summary_{i-1}\)和\(text_i\)权重不同,结果也会不太一样。如果\(summary_{i-1}\)的权重比较大 ,则每次保留的上下文信息也就会越多越完善,但是每次可输入新的文本就会变少,总的消耗的token数和资源就会越。如果\(summary_{i-1}\)的权重较大,则每次保留上下文信息更少,可输入的文本就会变多,但是最终提取的完善度和精确度就会下降。
关于权重的控制,我认为主要是通过控制summary的长度来实现。
第二种技巧就是采用滑动窗口的方式实现,以防文本中三元组的不同部分划分到不同的块中。