1 代理池搭建?
# ip代理
-每个设备都会有自己的IP地址
-电脑有ip地址---》访问一个网站---》访问太频繁---》封ip
-收费:靠谱稳定--提供api
-免费:不稳定--自己写api用
-开源的:https://github.com/jhao104/proxy_pool
免费代理---》爬取免费代理---》验证---》存到redis中
flask搭建web---》访问某个接口,随机获取ip
# 搭建步骤:
1 git clone git@github.com:jhao104/proxy_pool.git
2 pycharm中打开
3 安装依赖:创建虚拟环境 pip install -r requirements.txt
4 修改配置文件: DB_CONN = 'redis://127.0.0.1:6379/0'
5 运行调度程序和web程序
# 启动调度程序
python proxyPool.py schedule
# 启动webApi服务
python proxyPool.py server
6 api介绍
/ GET api介绍 None
/get GET 随机获取一个代理 可选参数: ?type=https 过滤支持https的代理
/pop GET 获取并删除一个代理 可选参数: ?type=https 过滤支持https的代理
/all GET 获取所有代理 可选参数: ?type=https 过滤支持https的代理
/count GET 查看代理数量 None
/delete GET 删除代理 ?proxy=host:ip
# http和https代理
-以后使用http代理访问http的地址
-使用https的代理访问https的地址
2 代理池使用?
# 公网
# 内网
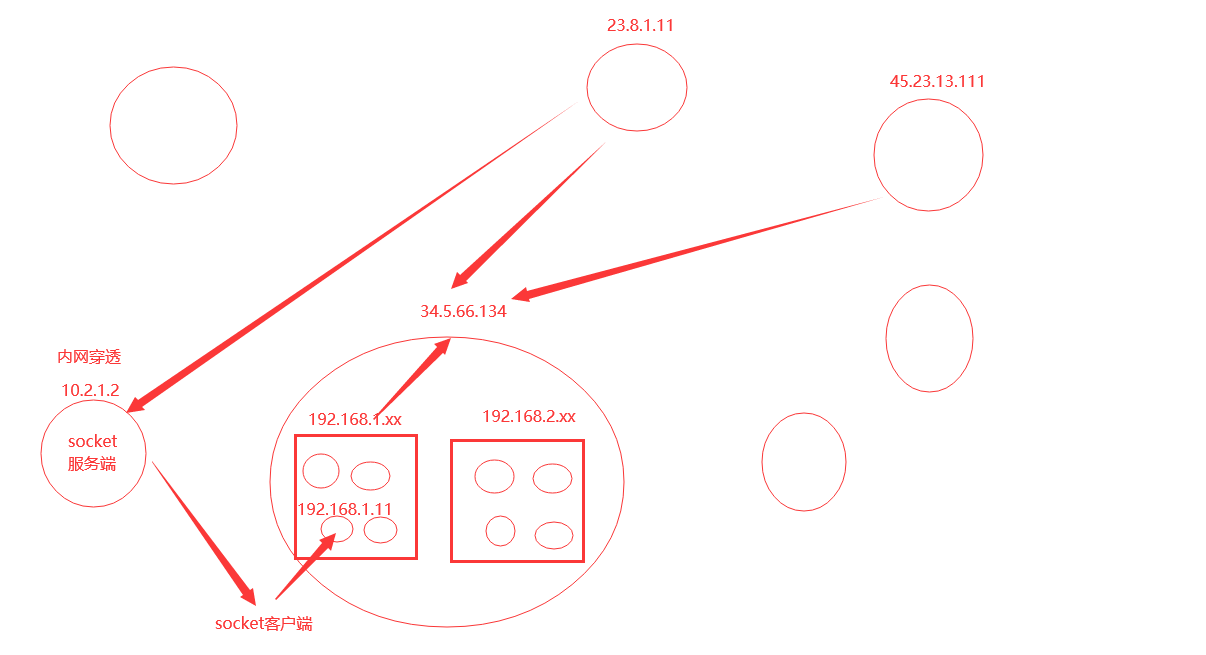
2.1 搭建django后端测试
import requests
res = requests.get('http://192.168.1.252:5010/get/?type=http').json()['proxy']
proxies = {
'http': res,
}
print(proxies)
# 我们是http 要使用http的代理
respone = requests.get('http://139.155.203.196:8080/', proxies=proxies)
print(respone.text)
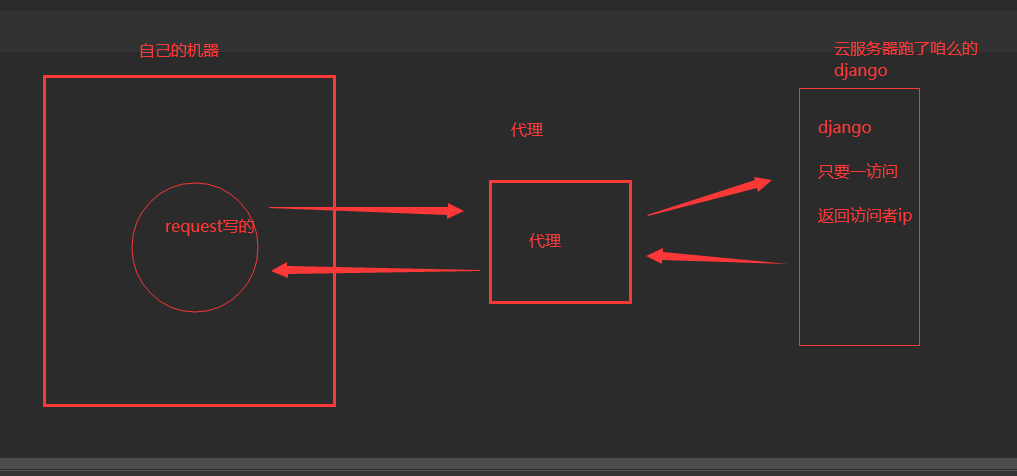
# 步骤:
1 写个django,只要访问,就返回访问者ip
2 部署在公网上---》python manage.py runserver 0.0.0.0:8000
3 本机使用代理测试
import requests
res1 = requests.get('http://192.168.1.63:5010/get/?type=http').json()
dic = {'http': res1['proxy']}
print(dic)
res = requests.get('http://47.93.190.59:8000/', proxies=dic)
print(res.text)
# 补充:
代理有 透明和高匿
透明的意思:使用者最终的ip是能看到的
高匿:隐藏访问者真实ip,服务端看不到
3 爬取某视频网站?
# 目标:
爬取该网站的视频,保存到本地 https://www.pearvideo.com/
import requests
import re
# 请求地址是:
# https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0
res = requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0')
# print(res.text)
# 解析出视频地址---》正则
video_list = re.findall('<a href="(.*?)" class="vervideo-lilink actplay">', res.text)
# print(video_list)
for video in video_list:
video_id = video.split('_')[-1]
url = 'https://www.pearvideo.com/' + video
print(url) # 向视频详情发送请求---》解析出页面中mp4视频地址---》直接下载即可
header = {
'Referer': url
}
res_json = requests.get(f'https://www.pearvideo.com/videoStatus.jsp?contId={video_id}&mrd=0.14435938848299434',
headers=header).json()
mp4_url = res_json['videoInfo']['videos']['srcUrl']
real_mp4_url = mp4_url.replace(mp4_url.split('/')[-1].split('-')[0], 'cont-%s' % video_id)
print(real_mp4_url)
# 把视频保存到本地
res_video = requests.get(real_mp4_url)
with open('./video/%s.mp4' % video_id, 'wb') as f:
for line in res_video.iter_content(1024):
f.write(line)
# res=requests.get('https://www.pearvideo.com/video_1526860')
# print(res.text)
# 第一层反扒:需要携带referfer
# header = {'Referer': 'https://www.pearvideo.com/video_1527879'}
# res = requests.get('https://www.pearvideo.com/videoStatus.jsp?contId=1527879&mrd=0.14435938848299434', headers=header)
# print(res.text)
# 反扒二:
# https://video.pearvideo.com/mp4/adshort/20190311/ 1698982998222 -13675354_adpkg-ad_hd.mp4 返回的
# https://video.pearvideo.com/mp4/adshort/20190311/ cont-1527879 -13675354_adpkg-ad_hd.mp4 能播的
# s = 'https://video.pearvideo.com/mp4/adshort/20190311/1698982998222-13675354_adpkg-ad_hd.mp4'
# print(s.replace(s.split('/')[-1].split('-')[0], 'cont-1527879'))
4 爬取新闻?
# 没有一个解析库---》用正则---》解析库--》html/xml
import requests
# pip install BeautifulSoup4
from bs4 import BeautifulSoup
res = requests.get('https://www.autohome.com.cn/news/1/#liststart')
# print(res.text)
# 找到页面中所有的类名叫article ul标签
soup = BeautifulSoup(res.text, 'html.parser')
# bs4的查找
ul_list = soup.find_all(class_='article', name='ul') # 所有的类名叫article ul标签
print(len(ul_list))
# 循环再去没一个中,找出所有li
for ul in ul_list:
li_list = ul.find_all(name='li')
for li in li_list:
h3 = li.find(name='h3')
if h3:
title = h3.text
url = 'https:' + li.find(name='a')['href']
desc = li.find(name='p').text
reade_count = li.find(name='em').text
img = li.find(name='img')['src']
print(f'''
文章标题:{title}
文章地址:{url}
文章摘要:{desc}
文章阅读数:{reade_count}
文章图片:{img}
''')
# 爬5页--->把图片保存到本地--->把打印的数据存储到mysql中--》建个表
5 bs4介绍和遍历文档树?
# BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库,解析库
# pip install beautifulsoup4
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b><span>lqz</span></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'html.parser') # 解析库可以使用 lxml,速度快(必须安装) 可以使用python内置的 html.parser
# print(soup.prettify())
### 重点:遍历文档树
#遍历文档树:即直接通过标签名字选择,特点是选择速度快,但如果存在多个相同的标签则只返回第一个
#1、用法 通过 . 遍历
# res=soup.html.head.title
# res=soup.p
# print(res)
#2、获取标签的名称
# res=soup.html.head.title.name
# res=soup.p.name
# print(res)
#3、获取标签的属性
# res=soup.body.a.attrs # 所有属性放到字典中 :{'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
# res=soup.body.a.attrs.get('href')
# res=soup.body.a.attrs['href']
# res=soup.body.a['href']
# print(res)
#4、获取标签的内容
# res=soup.body.a.text #子子孙孙文本内容拼到一起
# res=soup.p.text
# res=soup.a.string # 这个标签有且只有文本,才取出来,如果有子孙,就是None
# res=soup.p.strings
# print(list(res))
#5、嵌套选择
# 下面了解
#6、子节点、子孙节点
# print(soup.p.contents) #p下所有子节点
# print(list(soup.p.children)) #得到一个迭代器,包含p下所有子节点
# print(list(soup.p.descendants)) #获取子子孙节点,p下所有的标签都会选择出来
#7、父节点、祖先节点
# print(soup.a.parent) #获取a标签的父节点
# print(list(soup.a.parents) )#找到a标签所有的祖先节点,父亲的父亲,父亲的父亲的父亲...
#8、兄弟节点
# print(soup.a.next_sibling) #下一个兄弟
# print(soup.a.previous_sibling) #上一个兄弟
#
print(list(soup.a.next_siblings)) #下面的兄弟们=>生成器对象
# print(soup.a.previous_siblings) #上面的兄弟们=>生成器对象