一致性哈希主要用于分布式系统解决数据存储与访问的负载问题,极大的提高了可用性与扩展性。分布式系统往往是把数据分布到不同的节点,这些节点可以动态的加入或离开集群,这样就需要考虑一些问题,如果按照传统的hash算法进行数据分布,动态扩缩节点就需要对数据进行rehash,数据量大或请求数多的时候,对系统负荷比较大,并不是一个好的解决方案,一致性哈希就是用于解决这个问题。
传统的Hash算法
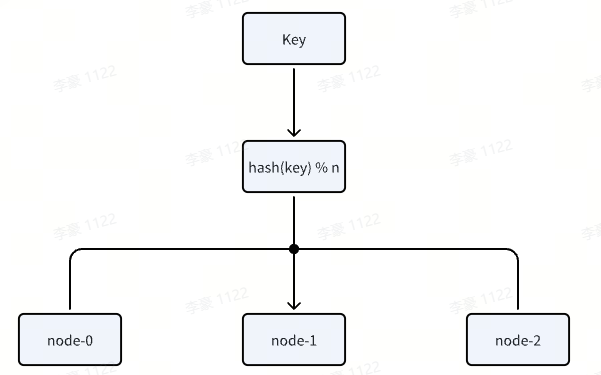
假如现在有6000万的数据量,通过唯一标识将数据分布到三台机器上,通常是用 Hash 唯一标识后再 Mod 存储节点N,Hash(unique_key) % N ,这里N = 3,但是这种方案会存在一个问题,存储节点发生变化的时候,Hash(unique_key) % N 整体的计算结果也会发生变化,就比如原本是Hash(unique_key) % 3,现在变为了Hash(unique_key) % 4 ,整体的数据都会进行rehash重新分布,数据量庞大的时候就会导致整体系统的数据命中率极大降低。
传统Hash算法示例图:
一致性哈希算法
一致性哈希算法主要用于数据分片与负载算法。他在传统Hash算法的基础上进行优化,增加了范围的概念,它由原本Hash运算固定的节点值改为处于某一个范围,而这个范围内的数据值会对应到一个节点上,从而达到数据的定位效果,所有的范围会组成一个环,这个环就是哈希环。好处就是,在进行扩缩节点的时候,只会影响到某一范围内的的数据,而不是像传统Hash算法一样对整个分布式的节点或数据进行重新分片与迁移。
一致性哈希本质性上也是一种取模运算,但他不是按照机器数,而是一个固定的值,这个固定值通常是2^32,这主要是因为IP地址由4组8位2进制组成,这样每个IP都在环上都有了对应的节点。

一致性哈希算法基本逻辑逻辑
服务器首先会根据IP地址进行Hash运算,运算后进行mod 2^32,这样就可以得到一个确定的值,将这个值映射到Hash环上,得到一个对应的服务节点。数据存储或访问的时候也通过Hash(key) mod 2^32 的值所属范围寻找对应节点。
案例:
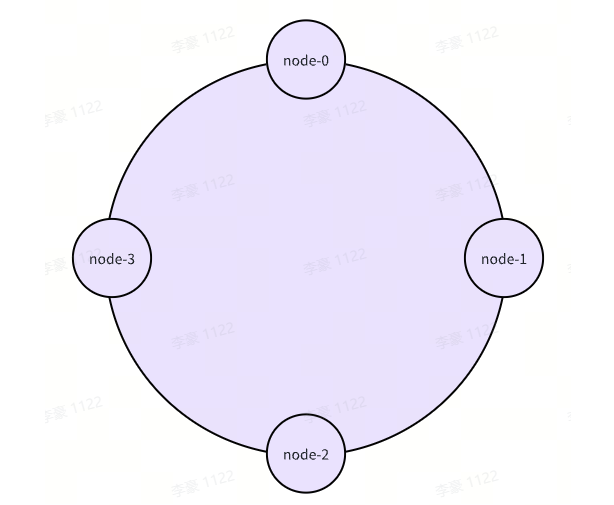
首先需要先将4台服务器IP映射到Hash环上,hash(服务器ip)% 2^32,并对映射的四个节点标记为:node-0、node-1、node-2、node-3,其中顺时针取范围,node0 -node1 范围属于node1
node1 -node2 范围属于node2
node2 -node3 范围属于node3
node3 -node4 范围属于node4

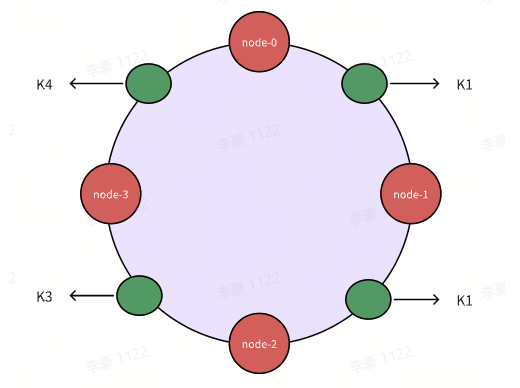
这个时候有四条数据需要存储,分别为"slim"、"stan"、"smith"、"Jack",经过Hash运算后这四条数据在Hash上的分为别K1、K2、K3、K4 如下图,由图可知顺时针范围,K1属于node-1节点,K2属于node-2节点,K3属于node-3节点,K4属于node-0节点。这样就可以找到对应的服务器节点,这就是一致性哈希的工作原理。
服务器扩缩节点及问题
服务器增加
假如新增了一个节点node4,这个节点经过运算后,落在了node3与node0之间,那么可以将node3-node4范围之间的数据迁移到node4即可。其他同理
服务器减少
假如node-2节点要下线,这个时候原本node1-node2范围的数据只需要迁移到node3节点即可。
数据倾斜
假如只有node1和node2两个节点,大量的数据分布在node1范围怎么办呢?这个时候node2资源过剩,这不是浪费资源嘛。
这个时候可以通过虚拟节点来解决这个问题,首先将虚拟节点映射到哈希环,然后将虚拟节点映射到真实节点即可解决问题。