文件操作
【1】基本流程
(1)文件操作
-
操作
- 打开读文件内容
r
with open('01.txt', 'r', encoding='utf-8') as f: data = f.read() print(data)- 打开写文件内容
w
# 普通语句 f = open('01.txt', 'w', encoding='utf-8') f.write('my hobby is music') f.close() # with语句 with open('01.txt', 'w', encoding='utf-8') as f: f.write('fuck my life')- 追加 a
with open('01.txt', 'a', encoding='utf-8') as f: f.write('\n' + 'life\'s a struggle') # fuck my life life's a struggle - 打开读文件内容
【2】控制文件读写格式
-
大前提:
- tb模式不能单独使用,必须和r/w/a之一结合使用
-
t(默认的):文本模式
- 读写文件都是以字符串为单位的
- 只能针对文本文件
- 必须指定encoding参数
-
b:二进制模式
- 读写文件都是以bytes/二进制为单位的
- 可以针对所有文件
- 一定不能指定encoding参数
(1)t模式的使用
-
文本类型,读内容和写内容都是字符串格式
- wt
with open('01.txt','wt',encoding='utf-8') as f: f.write('fuck my life')- rt
with open('01.txt', 'rt', encoding='utf-8') as f: data = f.read() print(data, type(data)) # hello <class 'str'>- at
with open('01.txt', 'at', encoding='utf-8') as f: f.write('world') # helloworld
(2)b模式的使用
-
二进制模式,读内容和写进去的内容必须都是二进制格式
- wb
import requests response = requests.get('https://pics1.baidu.com/feed/5bafa40f4bfbfbeda5be3a2d00f9c33baec31f96.jpeg@f_auto?token=45ef4b460b6c5929ae74318d4fd239d1') data = response.content with open('douyu.png','wb') as f: f.write(data)
- rb
with open('01.jpg','rb') as f:
data= f.read()
print(data)

(3)文件拷贝小练习
- 编写文件拷贝工具
- 输入一个文件地址 --- 把文件读出来
- 输入一个文件地址 --- 把当前文件内容拷贝到新的地址和新的文件里面
path_start = input('原始地址:>>>>').strip()
path_end = input('目标地址:>>>').strip()
model = {1: 'wb', 2: 'rb'}
print(f"{path_start} to {path_end} :>>> 已开始!")
with open(path_start, model[2]) as read_f, open(path_end, model[1]) as write_f:
write_f.write(read_f.read())
print(f"{path_start} to {path_end} :>>> 已完成!")
【3】文件操作的详细用法
(1)read相关
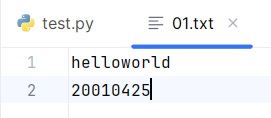
- readline()只读文本内的一行
with open('01.txt', 'r', encoding='utf-8') as f:
data = f.readline()
print(data)
- for循环读取
with open('01.txt', 'r', encoding='utf-8') as f:
for line in f:
print(line) # helloworld
#20010425
- readlines()将文件中的每一行内容读出来,读出来以后放到一个列表中
with open('01.txt', 'r', encoding='utf-8') as f:
data = f.readlines()
print(data) # ['helloworld\n', '20010425']
(2)write相关
- 写的三种操作
- write:一次性全部写入
with open('02.txt', 'w', encoding='utf-8') as f:
f.write('fuck my life')
- writelines写的内容可以是一个可迭代的列表
- 弊端:每个字符全部首尾拼接,无法自主的添加\n
with open('02.txt', 'w', encoding='utf-8') as f:
f.writelines(['heart', 'god']) # heartgod
- a模式下的writelines,不会覆盖写,而是首尾拼接
with open('02.txt', 'a', encoding='utf-8') as f:
f.writelines(['heart', 'god']) # heartgod
【4】生成式
(1)列表生成式
num_list = [i for i in range(0, 10)]
print(num_list) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print([i for i in range(0, 10)])
- 相乘
test_list1 = [1, 2, 3]
test_list2 = [2, 4, 6]
print([x * y for x in test_list1 for y in test_list2]) # [2, 4, 6, 4, 8, 12, 6, 12, 18]
test_list1 = [1, 2, 3]
test_list2 = [2, 4, 6]
list_four = [x * y for x, y in zip(test_list1, test_list2)]
print(list_four) # [2, 8, 18]
(2)字典生成式
dict_one = {}
for key in range(3):
for value in range(2):
dict_one[key] = value
print(dict_one) # {0: 1, 1: 1, 2: 1}
my_dict = {key: value for key in range(3) for value in range(2)}
print(my_dict) # {0: 1, 1: 1, 2: 1}
深浅拷贝
- 如果是浅copy,只会复制一层,如果copy的对象中有可变数据类型,修改可变数据类型还会影响拷贝的对象
# 原对象
original_list = [1, 2, [3, 4]]
# 使用浅拷贝创建拷贝对象
copied_list = copy.copy(original_list)
# 修改原对象中的可变数据类型
original_list[2].append(5)
print("原对象:", original_list) # 原对象: [1, 2, [3, 4, 5]]
print("拷贝对象:", copied_list) # 拷贝对象: [1, 2, [3, 4, 5]]
- 如果是深copy,完整复制,无论可变或不可变,都是创建出新的来,以后再改原对象,都不会对copy出的对象造成影响
import copy
# 原对象
original_list = [1, 2, [3, 4]]
# 使用深拷贝创建拷贝对象
copied_list = copy.deepcopy(original_list)
# 修改原对象中的可变数据类型
original_list[2].append(5)
print("原对象:", original_list)
print("拷贝对象:", copied_list)
(1)总结
- 浅拷贝只复制顶层对象
- 而深拷贝会递归复制整个对象结构。
异常处理
- 捕捉异常可以使用try/except语句。
- try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。
- 如果你不想在异常发生时结束你的程序,只需在try里捕获它。
(1)普通语法
try:
# 正常可能会触发异常的代码
except ExceptionType as e:
# 触发异常后执行的代码
try:
name = "heart"
name[0] = 'h'
except Exception as e:
print(f"触发异常 :>>>> {e}")
# 触发异常 :>>>> 'str' object does not support item assignment
(2)异常分支语法
try:
# 正常的操作
...
except:
# 发生异常,执行这块代码
...
else:
# 如果没有异常执行这块代码
...
try:
# 正常的操作
age = int(input('请输入你的年龄:>>>'))
except ValueError:
# 发生异常,执行这块代码
print('Invalid input! Please enter a valid integer.')
...
else:
# 如果没有异常执行这块代码
print(f"Your age: {age}")
...
(3)无论是否发生异常都将执行最后的代码
finally块中的代码无论是否发生异常都将被执行,常用于资源的释放、清理等操作。
try:
# 正常执行的代码
...
except:
# 发生异常,执行这块代码
finally:
#退出try时总会执行
...
try:
result = 10 / 0
except ZeroDivisionError as e:
print(f"Error: {e}")
finally:
print("Finally block is executed")