许多公司为用户提供神经网络预测服务,应用范围广泛。然而,目前的预测系统会损害一方的隐私:要么用户必须将敏感输入发送给服务提供商进行分类,要么服务提供商必须将其专有的神经网络存储在用户的设备上。前者损害了用户的个人隐私,而后者暴露了服务提供商的专有模式。
我们设计、实现并评估了DELPHI,这是一个安全的预测系统,允许双方在不泄露任何一方数据的情况下执行神经网络推理。DELPHI通过同时联合设计密码学和机器学习来解决这个问题。我们首先设计了一种混合加密协议,在通信和计算成本上比之前的工作有所提高。其次,我们开发了一个规划器,自动生成神经网络架构配置,导航我们的混合协议的性能精度权衡。与之前最先进的工作相比,这些技术使我们的在线预测延迟提高了22倍。
1 介绍
机器学习的最新进展推动了神经网络推理在语音助手[Bar18]和图像分类[Liu+17b]等流行应用中的越来越多的部署。然而,在许多此类应用程序中使用推理会引起隐私问题。例如,Kuna [Kun]和Wyze [Wyz]等家庭监控系统(HMS)使用专有的神经网络对用户家庭视频流中的物体进行分类,如停在用户家附近的汽车,或到家里参观的人的面孔。这些模型是这些公司业务的核心,培训成本很高。
为了使用这些模型,要么用户必须将他们的流上传到HMS的服务器(然后通过流评估模型),要么HMS必须将其模型存储在用户的监控设备上(然后执行分类)。这两种方法都不能令人满意:第一种方法要求用户将包含他们日常活动敏感信息的视频流上传到另一方,而第二种方法要求HMS在每台设备上存储其模型,从而允许用户和竞争对手窃取专有模型。
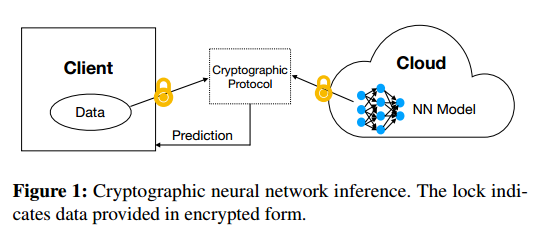
为了缓解这些隐私问题,最近的一些工作提出了(卷积)神经网络[Gil+16;卫生部+ 17;刘+ 17;Juv+18]通过利用专业的安全多方计算(MPC) [Yao86;高尔+ 87]。在较高的级别上,这些协议通过加密用户的输入和服务提供商的神经网络进行操作,然后定制用于计算加密数据的技术(如同态加密或秘密共享),以对用户的输入运行推断。在协议执行结束时,预期的一方(或几方)学习推断结果;双方都不了解对方的任何信息。该协议流程如图1所示。
不幸的是,这些加密预测协议仍然不适合部署在现实世界的应用程序中,因为它们需要在在线执行期间使用大量的加密工具。这些工具需要大量的计算,通常需要用户和服务提供者之间进行大量的通信。此外,这种成本随着模型的复杂性而增加,使得这些协议不适合用于当今实践中使用的最先进的神经网络架构。例如,使用GAZELLE [Juv+18]这样的最先进的协议来对ResNet-32 [He+16]这样的最先进的深度神经网络执行推理需要约82秒,并导致超过560MB的通信。
我们的贡献。 在本文中,我们提出了DELPHI,一种用于真实神经网络架构的密码预测系统。DELPHI通过密码学和机器学习的精心联合设计来实现其性能。DELPHI提供了一种新的混合密码预测协议,以及一个计划器,可以调整机器学习算法,以利用我们协议的性能精度权衡。我们的技术使我们能够在比以前的工作中考虑的更现实的网络架构上执行加密预测。例如,在ResNet-32上使用DELPHI进行密码预测,在线阶段仅需要3.8秒,通信60MB,分别比GAZELLE提高了22倍和9倍。
1.1技术
我们现在在较高的层次上描述了DELPHI卓越性能背后的技术。
性能目标。 现代卷积神经网络由许多层组成,每个层包含一个子层用于线性操作,一个子层用于非线性操作。常见的线性运算包括卷积、矩阵乘法和平均池化。非线性操作包括激活函数,如流行的ReLU(整流线性单元)函数。
因此,实现现实神经网络的加密预测需要(a)构建用于评估线性和非线性层的有效子协议,以及(b)将这些子协议的结果相互链接。
之前的工作。以往几乎所有的密码预测协议都使用重量级密码工具来实现这些子协议,这导致计算和通信成本远远高于同等的明文成本。更糟糕的是,许多协议在协议的延迟敏感在线阶段使用这些工具,即当用户获取输入并希望获得其分类时。(这与延迟敏感度较低的预处理阶段相反,后者发生在用户输入可用之前)。
例如,最先进的GAZELLE协议的在线阶段使用了大量的加密技术,如线性同态加密和乱码电路。正如我们在7.4节中所展示的,这会导致大量的预处理和在线成本:对于通过CIFAR-100训练的流行网络架构ResNet-32, GAZELLE在预处理阶段需要~ 158秒和8GB的通信,在预处理阶段需要~ 50秒和5GB的通信,在在线阶段需要~ 82秒和600MB的通信。
1.1.1 DELPHI协议
为了在真实的神经网络上获得良好的性能,DELPHI建立在GAZELLE技术的基础上,开发了用于评估线性和非线性层的新协议,最大限度地减少了重型加密工具的使用,从而最大限度地减少了预处理和在线阶段的通信和计算成本。我们首先简要介绍一下GAZELLE协议,因为它是DELPHI协议的基础。
起点:GAZELLE。 GAZELLE [Juv+18]是一种最先进的卷积神经网络加密预测系统。GAZELLE使用优化的线性同态加密(LHE)方案[Elg85;Pai99;Reg09;Fan+12],可以直接对密文进行线性操作。为了计算非线性层,GAZELLE使用乱码电路[Yao86]来计算ReLU所需的位操作。最后,由于神经网络中的每一层都由交替的线性和非线性层组成,GAZELLE还描述了如何通过基于相加秘密共享的技术在前面提到的两个原语之间有效地来回切换。
如上所述,GAZELLE在在线阶段使用大量密码学导致了效率和通信开销。为了减少这些管理费用,我们采取如下措施。
降低线性操作的成本。为了降低线性运算的在线计算成本,我们采用GAZELLE将LHE密文上繁重的密码运算转移到预处理阶段。我们的关键见解是,在用户输入可用之前,服务提供者对线性层的输入M(即该层的模型权重)是已知的,因此我们可以在预处理期间使用LHE创建M的秘密共享。之后,当用户的输入在在线阶段可用时,所有线性操作都可以直接在秘密共享数据上执行,而不需要调用像LHE这样的重型加密工具,也不需要执行矩阵向量乘法的交互。
这种技术的好处是双重的。首先,在线阶段只需要传输秘密共享而不是密文,这立即导致线性层的在线通信减少了8倍。其次,由于在线阶段只对素数字段的元素进行计算,并且由于我们的系统使用了具体的32位素数,因此我们的系统可以利用最先进的CPU和GPU库来计算线性层;详见章节7.2和备注4.2。
降低非线性作业的成本。 虽然上述技术已经显著减少了计算时间和通信成本,但两者的主要瓶颈仍然是评估ReLU激活函数的乱码电路的成本。为了使成本最小化,我们使用了另一种方法[Gil+16;刘+ 17;卫生部+ 17;Cho+18]它更适合于有限域元的计算:计算多项式。更详细地说,DELPHI用多项式(具体地说,二次)近似代替ReLU激活。这些可以通过标准协议安全有效地计算[Bea95]。
由于这些协议只需要在每次乘法时通信少量常量的字段元素,因此使用二次近似可以显著降低每次激活时的通信开销,而无需引入额外的通信轮。同样,由于底层乘法协议只需要一些廉价的有限域操作,计算成本也降低了几个数量级。具体而言,安全计算二次近似的在线通信成本和计算成本分别比乱码电路的相应成本小192倍和10000倍。
然而,这种性能的提高是以底层神经网络的准确性和可训练性为代价的。先前的工作已经确定二次近似在某些设置中提供了良好的精度[Moh+17;刘+ 17;Gho + 17;Cho + 18]。与此同时,之前的工作[Moh+17]和我们自己的实验都表明,在许多设置中,简单地用二次近似替换ReLU激活会导致精度严重下降,并且可以将训练时间增加几个数量级(如果训练收敛的话)。为了克服这一问题,我们开发了一种使用ReLUs和二次近似的混合密码协议,以达到良好的精度和效率。
计划有效地使用混合密码协议。 事实证明,确定哪些ReLU激活应该用二次近似代替并不简单。事实上,正如我们在第5节中解释的那样,简单地用二次近似代替任意的ReLU激活会降低结果网络的准确性,甚至会导致网络无法训练。
因此,为了找到合适的位置或网络配置,我们设计了一个规划器,自动发现哪些relu要替换为二次近似,以最大限度地使用近似的数量,同时仍然确保精度保持在指定的阈值以上。
我们的计划背后的洞察力是适应神经结构搜索(NAS)和超参数优化的技术(见[Els+19;Wis+19]用于这些领域的深入调查)。也就是说,我们采用这些技术来发现在给定的神经网络架构中应该近似哪些层,并优化所发现网络的超参数。详见第5节。
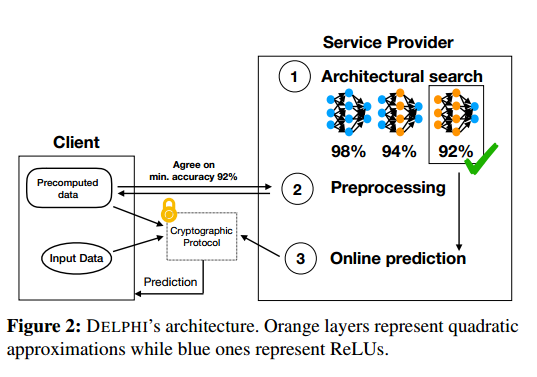
整个系统。 DELPHI将上述见解结合到一个内聚系统中,服务提供商可以使用该系统自动生成满足提供商指定的性能和准确性标准的加密预测协议。更详细地说,服务提供者以可接受的精度和性能阈值调用DELPHI的计划器。规划器输出一个满足此目标的优化架构,然后DELPHI使用该架构实例化一个具体的密码预测协议,该协议利用我们上面的密码技术。
这种密码学和机器学习的联合设计使DELPHI能够有效地为网络提供比以往任何工作都更深入的密码预测。例如,在第7节中,我们展示了使用DELPHI为流行的ResNet-32架构提供推理,只需要60MB的通信和3.8秒的时间。
2系统概述
2.1系统设置
在系统设置中有两方:客户端和服务提供者(或服务器)。在我们系统的明文版本中,服务提供者通过API使用其内部模型以服务的形式提供预测。客户端通过将数据传输给服务提供者,使用这个API对自己的数据运行预测。服务提供者使用适当的神经网络运行预测,然后将预测结果发送回客户端。在DELPHI中,双方通过提供各自的输入来共同执行安全预测。服务提供者的输入是神经网络,而客户端的输入是用于预测的私有输入。
2.2威胁模型
DELPHI的威胁模型类似于之前的安全预测作品GAZELLE [Juv+18]和MiniONN [Liu+17a]。更具体地说,DELPHI是为两方半诚实环境设计的,其中只有一方被对手破坏。此外,这个对手永远不会偏离协议,但它将试图从它收到的消息中了解有关其他方私人输入的信息。
2.3隐私目标
DELPHI的目标是让客户只学习两部分信息:神经网络的架构和推理的结果;所有其他关于客户端私有输入和服务器神经网络模型参数的信息都应该被隐藏。具体来说,我们的目标是实现一个强大的基于模拟的安全定义;参见定义4.1。
像之前的所有工作一样,DELPHI并不隐藏关于网络架构的信息,例如网络中每一层的尺寸和类型。对于之前的工作,这通常不是问题,因为体系结构独立于训练数据。然而,由于DELPHI的规划器使用训练数据来优化二次近似,揭示网络架构会揭示关于数据的一些信息。具体地说,在优化“层网络”时,规划者做出“二元选择”,因此最多只能揭示关于训练数据的比特信息。因为'对于实际网络来说非常小(例如,' = 32对于ResNet32),这个泄漏可以忽略不计。这种泄漏可以通过使用差分私有训练算法[Sho+15;阿坝+ 16]
与大多数先前的密码预测系统一样,DELPHI不隐藏预测结果所揭示的信息。在我们看来,防范利用这种泄漏的攻击是DELPHI解决的一个补充问题。事实上,这种攻击甚至已经成功地针对那些通过要求客户端将其输入上传到服务器而“完美”隐藏模型参数的系统[Fre+14;吃+ 15;Fre + 15;吴+ 16 b;+ 16]。此外,针对这些攻击的常用缓解措施,如差异隐私,可以与DELPHI的协议结合使用。我们将在第8.2节中更详细地讨论这些攻击和可能的缓解措施。
2.4系统架构及工作流程
DELPHI的体系结构由两个部分组成:用于评估神经网络的混合加密协议,以及用于优化给定神经网络以配合我们的协议使用的神经网络配置规划器。下面我们将概述这些组件,然后通过描述家庭监控系统(HMS)中加密预测的端到端工作流程来演示如何在实践中使用这些组件。
混合密码协议。 DELPHI的密码预测协议包括两个阶段:离线预处理阶段和在线推理阶段。离线预处理阶段独立于客户端输入(定期更改),但假设服务器的模型是静态的;如果这个模型改变了,那么双方都必须重新运行预处理阶段。经过预处理后,在在线推理阶段,客户端向我们专门的安全两方计算协议提供输入,并最终学习推理结果。我们注意到我们的协议提供了两种不同的评估非线性层的方法:第一种以更差的离线和在线效率为代价提供了更好的准确性,而另一种降低了准确性,但提供了更好的离线和在线效率。
计划。 为了帮助服务提供商在这两种互补方法评估非线性层的性能和准确性之间进行权衡,DELPHI采用了一种有原则的方法,设计了一个计划器,生成混合这两种方法的神经网络,以最大限度地提高效率,同时仍能达到服务提供商所需的准确性。我们的规划器将神经结构搜索(NAS)以一种新颖的方式应用于密码设置,以便自动发现正确的架构。
例2.1 (HMS工作流)。 如第1节所述,家庭监控系统(HMS)使用户能够监视房屋内外的活动。近期HMSes [Kun;Wyz]使用神经网络来判断给定的活动是否是恶意的。如果是,他们会提醒用户。在这种情况下,隐私对用户和HMS提供商都很重要,这使得DELPHI成为理想的选择。为了使用DELPHI来提供强大的隐私,HMS提供商按照以下步骤进行。
HMS提供商首先调用DELPHI的规划器来优化其基线全relu神经网络模型。然后,在HMS设备空闲期间,设备和HMS服务器运行此模型的预处理阶段。如果设备在本地检测到可疑活动,它可以运行在线推断阶段以获得分类。根据这个结果,它可以决定是否提醒用户
备注2.2(适用于DELPHI的应用程序)。 例2.1表明,DELPHI最适合于以下应用:有足够的计算能力用于预处理,推理是延迟敏感的,但执行频率不足以耗尽预处理材料的储备。这类应用的其他例子包括谷歌Lens [Goo]等系统中的图像分类。
3 密码原语
4加密协议
在DELPHI中,我们引入了一种用于加密预测的混合加密协议(见图4)。我们的协议对之前工作中提出的协议(如MiniONN [Liu+17a]和GAZELLE [Juv+18])进行了两个关键改进。首先,DELPHI将协议分为预处理阶段和在线阶段,这样大部分繁重的密码计算都在预处理阶段执行。其次,DELPHI引入了两种不同的评估非线性函数的方法,为用户提供了准确性和性能之间的权衡。第一种方法使用乱码电路来评估ReLU激活函数,而第二种方法使用安全评估ReLU的多项式近似。前者提供了最大的精度,但效率低,而后者计算成本低,但降低了精度。(我们注意到,下面我们描述了一个用于评估任何多项式近似的协议,但在本文的其余部分,我们只限制自己使用二次近似,因为这些是最有效的。)
符号。 设R是一个有限环。设HE = (KeyGen, Enc,Dec,Eval)是明文空间R上的线性同态加密。服务器持有一个模型M,由“层M1,…”, M”。客户端持有一个输入向量x∈rn。
我们现在给出一个加密预测协议的正式定义。直观地说,该定义保证了协议执行后,一个半诚实的客户端(即遵循协议规范的客户端)只学习神经网络的架构和推断的结果;关于服务器神经网络模型参数的所有其他信息都是隐藏的。类似地,半诚实的服务器不了解任何关于客户端输入的信息,甚至不了解推断的输出。
定义4.1。 一个服务器之间的协议Π,其输入模型参数为M = (M1,…,M '),客户端以特征向量x作为输入,如果满足以下保证,则是一个加密预测协议。
-
正确性。 在服务器持有的每一组模型参数M和客户端的每一个输入向量x上,协议结束时客户端的输出是正确的预测M(x)。
-
安全性。
-
腐败的客户端。 我们要求一个损坏的、半诚实的客户端不了解服务器的网络参数M。形式上,我们要求存在一个有效的模拟器Sim_C,使得View^{\prod}_C\approx Sim_C(x,out),并且View^{\prod}_C表示执行Π时客户端的视图(视图包括客户端的输入、随机性和协议的记录),out表示推理的输出。
-
腐败的服务器。 我们要求损坏的、半诚实的服务器不了解客户机的私有输入x的任何信息。形式上,我们要求存在一个有效的模拟器Sim_S,使View^{\prod}_S\approx Sim_S(M),其中View^{\prod}_S表示执行Π时服务器的视图。
-
DELPHI协议分两个阶段进行:预处理阶段和在线阶段,我们将在后面的小节中详细介绍这两个阶段。
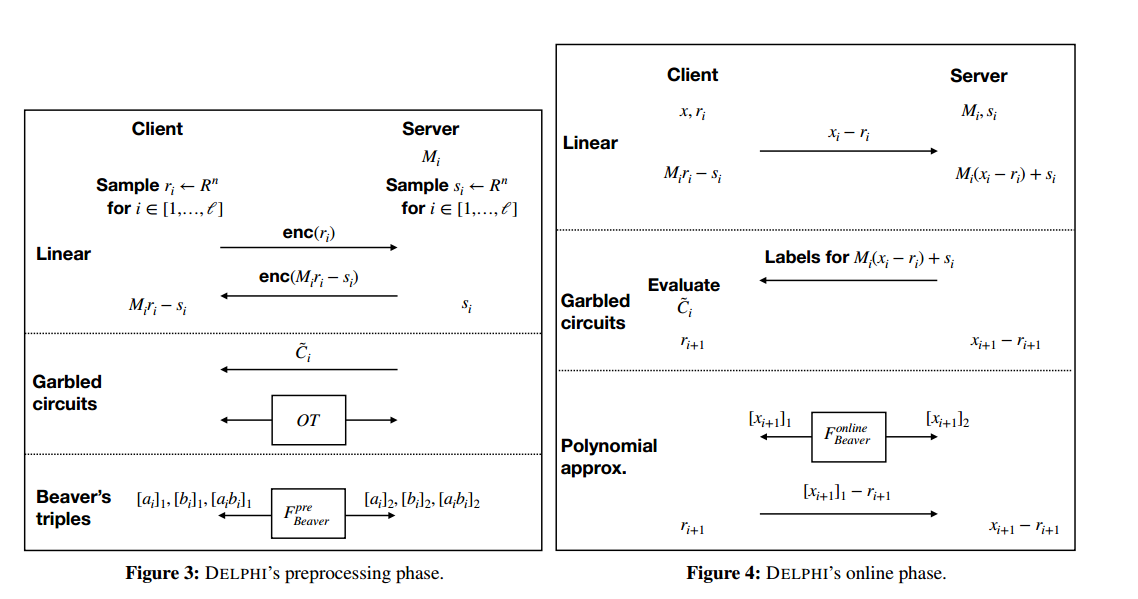
4.1预处理阶段
在预处理过程中,客户端和服务器预先计算在线执行过程中可以使用的数据。这个阶段可以独立于输入值执行,也就是说,DELPHI可以在任何一方的输入已知之前运行这个阶段。
1、客户端运行HE.KeyGen获取公钥pk和密钥sk。
2、对于每一个i\in[l],客户端和服务器分别选择随机屏蔽向量r_i,s_i \gets R^n。
3、客户端发送HE.Enc(pk, ri)到服务器。服务器使用HE.Eval计算HE.Enc(pk, Mi·ri−si),并将此密文发送给客户端。
4、客户端对上述密文进行解密,获得每一层的(Mi·ri−si)。服务器为每一层保存si,因此,客户端和服务器拥有Mi·ri的加法秘密共享。
5、这一步取决于激活类型:
-
(a) ReLU: 服务器通过图5所示的混淆电路C来构造\tilde{C}。它将\tilde{C}发送到客户端,同时,服务器和客户端通过无关传输(OT)交换对应于
ri+1和Mi·ri−si的输入线的标签。 -
(b) 多项式近似: 客户端和服务器运行Beaver的三重乘法生成协议来生成一些Beaver的乘法三元组.
4.2在线
在线阶段分为两个阶段:设置和层评估。
4.2.1 启动
客户端在输入x时,将x−r1发送给服务器。服务器和客户端现在拥有x的附加秘密共享。
4.2.2 层次评估
在第i层的开始,客户端持有ri,服务器持有xi−ri,其中xi是通过计算输入x上的神经网络的第(i−1)层(x1设为x)得到的向量。这个不变量将对每一层保持。我们现在描述了第i层的计算协议,它由线性函数和激活函数组成。
线性层。 服务器端计算Mi (xi−ri) +si,确保客户端和服务器端共享Mi·xi的附加秘密。
非线性层。 线性函数之后,服务器端持有Mi (xi−ri) + si,客户端持有Mi·ri−si。有两种评估非线性层的方法:用于ReLU的乱码电路,或用于多项式近似的Beaver乘法:
-
乱码电路
-
服务器将
Mi (xi−ri) +si对应的乱码标签发送给客户端。 -
客户端使用上述标签和OT(脱机阶段)获得的标签对乱码电路\tilde{C}进行评估,得到一次性的填充密文OTP(x_{i+1}−r_{i+1})。然后它将此输出发送到服务器。
-
服务器使用一次性填充键获取x_{i+1}−r_{i+1}。
-
-
多项式近似
-
客户端和服务器运行Beaver的乘法过程来计算接近这一层的多项式。在过程结束时,客户端持有[xi+1]_1,服务器持有[xi+1]_2。
-
客户端计算[xi+1]_1−r_{i+1}并发送给服务器。服务器将该值加上[xi+1]_2,得到x_{i+1}−r_{i+1}。
-
输出层。 服务器将x_l−r_l发送给客户端,客户端将其与r_l相加以学习x_l。

备注 4.2(有限域中的定点算法)。到目前为止的讨论假设在有限环上进行算术运算。然而,神经网络推理的流行实现对浮点数执行算术运算。我们通过使用浮点数的定点表示,并将这种定点算法嵌入到我们的环形算法中来解决这个问题。
具体而言,我们的实现工作于由素数 2138816513 定义的 32 位素数有限域,并使用 15 位定点表示。这种参数选择可以在结果溢出素数域的容量之前实现两个定点数的单次乘法。为了防止值随着乘法次数呈指数增长(从而溢出),我们使用了 [Moh+17] 中的一个技巧,它允许我们简单地截断定点值的额外 LSB。即使结果是秘密共享的,这个技巧也能奏效,尽管是以 1 位错误为代价的。
与 Slalom [Tra+19] 类似,我们对素数域的选择也使我们能够将我们的域算法无损地嵌入到 64 位浮点算法中。更详细地说,64 位浮点数可以表示 2^{−53} ,...,2^{53} 范围内的所有整数。因为我们的线性层协议的在线阶段需要一个定点矩阵乘以一个秘密共享向量,结果是一个 ∼ 45 位整数,因此可以用 64 位浮点数完全精确地表示.这使我们的实现能够将最先进的 CPU 和 GPU 库用于线性代数。
4.3 安全
定理 4.3。假设存在乱码电路、线性同态加密和用于 Beaver 的三元组生成和乘法过程的安全协议,上述协议是一个密码预测协议(见定义 4.1)。
证明。 下面我们先针对客户端损坏的情况介绍模拟器,然后针对服务端损坏的情况介绍模拟器。我们在附录 B 中提供了一个依赖于这些模拟器的混合论证。
5 Planner
DELPHI 的规划器采用服务提供商的神经网络模型(以及其他约束)并生成满足服务提供商的准确性和效率目标的新神经网络架构。该规划器的核心是一种神经架构搜索 (NAS) 算法,使服务提供商能够自动找到此类网络架构。下面我们对这个关键组件进行了高度概述,并描述了我们的规划器如何使用它。
背景:神经结构搜索。 最近,机器学习研究在神经架构搜索 (NAS) [Els+19;智慧+19]。 NAS 的目标是自动发现最能满足一组用户指定约束的神经网络架构。大多数 NAS 算法通过(部分)训练许多不同的神经网络、评估它们的准确性并选择性能最好的神经网络来实现这一点.
我们的规划器概述。 DELPHI 的规划器,当输入基线 all-ReLU 神经网络时,以两种模式运行。当再训练不可能或不需要时(例如,如果训练数据不可用,或者如果提供者无法负担 NAS 所需的额外计算),规划器将以第一种模式运行,并简单地输出基线网络。如果再训练(以及 NAS)是可行的,那么规划器将训练数据和最小可接受预测精度 t 的约束作为附加输入,然后使用 NAS 来发现最大化二次近似数量的网络配置,同时仍然实现大于 t 的精度。我们的规划器然后进一步优化此配置的超参数。更详细地说,在第二种模式中,我们的规划器使用 NAS 来优化给定 t 的候选网络配置的以下属性:(a) 二次近似的数量,(b) 这些近似的放置(即,其中的层ReLU 替换为近似值),以及 (c) 训练超参数,如学习率和动量。
前面是一个简短的描述,省略了很多细节。下面,我们将描述我们如何解决使 NAS 适应这种设置所需的挑战(第 5.1 节),我们对 NAS 算法的具体选择(第 5.2 节),以及详细的伪代码最终算法(图 6)。

5.1 为DELPHI的planner适配NAS
挑战 1:训练候选网络。之前的工作 [Moh+17;吉尔+16;高+17; Cho+18] 和我们自己的实验表明,使用二次逼近的网络在训练和部署方面具有挑战性:二次激活会导致底层梯度下降算法发散,从而导致精度低下。直觉上,我们认为这种行为是由这些函数的大而交替的梯度引起的。
为了解决这个问题,我们使用了以下技术:
-
梯度和激活裁剪:在训练期间,我们修改优化器以使用梯度值裁剪,这有助于防止梯度爆炸 [Ben+94]。特别是,我们将所有梯度的值剪裁为小于 2。我们进一步修改我们的网络以使用 ReLU6 激活函数 [Kri10],以确保激活后值的幅度最多为 6。这可以防止错误在两者之间复合推理和训练。
-
渐进式激活交换:我们的实验确定,尽管存在剪裁,但梯度仍在快速爆炸,尤其是在包含更高比例近似值的更深网络中。为了克服这个问题,我们利用了以下见解:直觉上,ReLU6 和 ReLU 的(截断的)二次近似应该共享相对相似的梯度,因此应该可以使用 ReLU6 最初引导下降到一个稳定的区域,其中梯度是更小,然后使用近似的梯度在该区域内进行细粒度调整。
我们通过修改训练过程来利用这种洞察力,逐渐将已经训练过的 allReLU6 网络转换为具有所需数量和二次近似位置的网络。更详细地说,我们的训练过程将每个激活表示为二次和 ReLU6 激活的加权平均值,即 act(x):= wq·quad(x)+wrReLU(x)使得 wq +wr = 1。一开始,wq = 0 和 wr = 1。然后我们的训练算法逐渐增加 wq 并减少 wr,最终 wq = 1 和 wr = 0。
这种技术还提高了 NAS 的运行时间,因为它不再需要从头开始训练每个候选网络配置。
挑战二:高效优化配置。 回想一下,我们的规划器旨在优化二次近似的数量、它们在网络中的位置以及训练超参数。尝试在单个 NAS 执行中优化所有这些变量会导致很大的搜索空间,而在这个搜索空间中找到有效的网络需要相应较长的时间。
为了解决这个问题,我们将单片 NAS 执行分成独立的运行,负责优化不同的变量。例如,对于具有 n 个非线性层的架构,对于 m < n 的相关选择,我们首先执行 NAS 以找到具有 m 个近似层的高分架构,然后再次执行 NAS 以优化这些架构的训练超参数。在此过程结束时,我们的规划器输出具有不同性能-准确性权衡的各种网络。
挑战 3:优先考虑高效配置。 我们规划者的目标是选择包含最大数量近似值的配置,以最大限度地提高效率。但是,具有大量近似值的网络配置需要更长的训练时间,并且可能比具有较少近似值的网络准确度略低。由于传统的 NAS 文献侧重于简单地最大化效率,因此在此默认设置中使用 NAS 会导致选择较慢的网络而不是更高效的网络,这些网络的准确性略低于较慢的网络。为了克服这个问题,我们通过设计一个新的评分函数 score(·) 来改变 NAS 为候选网络分配“分数”的方式,该函数可以平衡优先精度和性能。我们在第 7 节中的实验表明,此功能使我们能够选择既高效又准确的网络。
score(N) := acc(N)(1+ \frac{\#quad.activations}{\#total.activations} )
$$
5.2 选择NAS算法
到目前为止的讨论与 NAS 算法的选择无关。在我们的实现中,我们决定使用流行的基于群体的训练算法 [Jad+17],因为它可以直接为我们的用例定制它,并且因为它有许多优化的实现(比如 [Lia+18] ]).
基于群体的训练 (PBT) [Jad+17] 维护了一个候选神经网络群体,它在一系列时间步长上进行训练。在每个时间步结束时,它通过用户指定的评分函数衡量每个候选网络的性能,并将性能最差的候选网络替换为性能最好的候选网络的变异版本(变异函数由用户指定) .在优化过程结束时,PBT 输出它找到的性能最佳的候选网络架构(以及用于训练它们的超参数)。
6 系统实施
DELPHI 的密码协议是用 Rust 和 C++ 实现的。我们使用SEAL同态加密库[Sea]实现HE,并依赖fancy-garbling library3进行乱码电路。为了确保高效的预处理阶段,我们在 SEAL 中重新实现了 GAZELLE 的线性层高效算法;这可能是独立的利益。 DELPHI 的规划器是用 Python 实现的,并使用 Tune [Lia+18] 中的可扩展 PBT [Jad+17] 实现。
备注 6.1(重新实现 GAZELLE 的算法)。 Riazi 等人 [Ria+19] 指出,GAZELLE 的实现不为 HE 提供电路隐私,这可能会导致有关线性层的信息泄漏。为了解决这个问题,他们建议使用更大的参数来确保电路隐私。(需要注意的是,这些参数导致的性能比使用 GAZELLE 的高度优化参数更差。)因为 DELPHI 在我们的预处理阶段使用 GAZELLE 的算法,我们试图修改 GAZELLE 的实现 4 以使用电路私有参数。然而,事实证明这很困难,因此我们决定在支持这些参数的 SEAL 中重新实现这些算法。
7 评价
我们将评估分为三个部分来回答以下问题
-
第 7.2 节:DELPHI 构建块的效率如何?
-
第 7.3 节:DELPHI 的规划器是否为现实的神经网络(例如 ResNet-32)提供了效率和准确性之间的良好平衡?
-
第 7.4 节:使用 DELPHI 为此类神经网络提供预测服务的延迟和通信成本是多少?
7.1 评估设置
所有密码学实验都是在 AWS c5.2xlarge 实例上进行的,该实例拥有 3.0GHz 的 Intel Xeon 8000 系列机器 CPU 和 16GB RAM。客户端和服务器分别在位于 us-west-1(加利福尼亚北部)和 us-west-2(俄勒冈)区域的两个此类实例上执行。客户端和服务器执行各使用 4 个线程。机器学习实验是在配备 NVIDIA Tesla V100 GPU 的各种机器上进行的。我们的机器学习和密码协议实验依赖于以下数据集和架构:
-
CIFAR-10 是一个标准化数据集,由分为 10 个类别的 (32 × 32) RGB 图像组成。训练集包含 50,000 张图像,而测试集包含 10,000 张图像。我们的实验使用 MiniONN [Liu+17a] 中指定的 7 层 CNN 架构。这样做可以让我们将我们的协议与之前的工作进行比较
-
CIFAR-100 包含与 CIFAR-10 相同数量的训练和测试图像,但将它们分为 100 个类而不是 10 个。这种增加的复杂性需要具有更多参数的更深网络,因此我们的实验使用流行的 ResNet-32 架构在 [He+16] 中介绍。我们注意到,之前没有关于安全推理的工作试图评估他们在困难数据集(如 CIFAR100)或深度网络架构(如 ResNet-32)上的协议。
每当我们将 DELPHI 与 GAZELLE 进行比较时,我们都会通过将我们重新实现线性和非线性层的相关子协议的成本相加来估算 GAZELLE 协议的成本。我们这样做是因为没有端到端的 GAZELLE 协议实现;只有个别的子协议被执行。
7.2 微基准
我们提供了 DELPHI 在线性和非线性层上的性能的微基准测试,并将两者与 GAZELLE 进行了比较。
7.2.1 线性运算
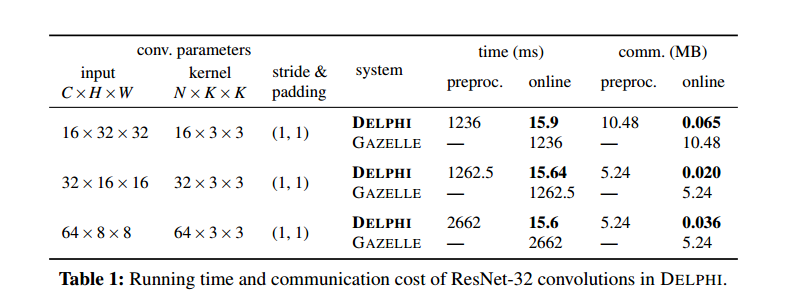
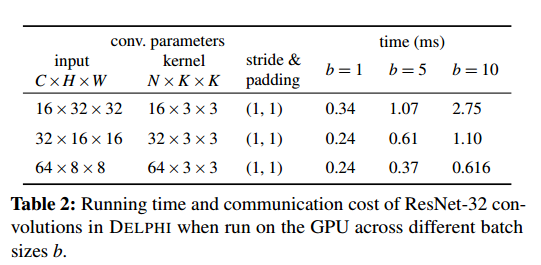
下面我们重点关注卷积运算的性能,因为它们构成了神经网络线性运算的大部分成本。卷积的复杂性取决于输入的维度、卷积核的大小和数量,以及填充和步幅(后一个参数决定了将核应用于输入的频率)。在表 1 中,我们评估了 ResNet-32 中使用的卷积的成本。关键要点是我们的在线时间比 GAZELLE 小 80 多倍,我们的在线交流少 150 多倍。另一方面,我们的预处理时间和通信量高于 GAZELLE,但最多等于 GAZELLE 的在线时间和通信量。
优化 GPU 操作。如备注 4.2 中所述,DELPHI 对素数域的选择使 DELPHI 能够使用标准 GPU 库来评估在线阶段的卷积层。但是,这样做需要将层权重和输入复制到 GPU 内存中,并将每个线性层的输出复制回 CPU 内存。此复制可能会产生大量开销。为了摊销它,可以将不同输入的卷积批处理在一起。在表 2 中,我们报告了批量大小为 1、5 和 10 的成本。关键要点是,对于单卷积,这些成本比表 1 中的等效成本低 50-100 倍以上,并且对于批量卷积,成本似乎与批量大小呈次线性关系。
7.2.2 ReLU 和二次激活
回想一下,我们用于评估 ReLU 激活的协议使用了乱码电路。我们的 ReLU 电路遵循 [Juv+18] 中的设计,并进行了一些额外的优化。为了评估二次激活,我们的协议使用 Beaver 的乘法过程 [Bea95],它需要从服务器向客户端发送一个场元素,反之亦然,然后需要双方进行一些廉价的本地场操作。两种激活的通信和计算成本如表 3 所示

7.3 DELPHI的规划器
为了证明我们的规划器的有效性,我们需要证明 (a) 二次激活是 ReLU 激活的有效替代品,并且 (b) 规划器找到的网络提供比全 ReLU 网络更好的性能。在我们下面的实验中,我们使用 80% 的训练数据在规划器中训练网络,剩下的 20% 作为验证集。规划器根据验证准确性对候选网络进行评分,但最终报告的准确性是测试集的准确性。
二次激活是有效的。我们需要证明,不仅我们的规划器输出的网络具有良好的准确性,而且二次激活不是多余的。也就是说,我们需要证明网络没有学会“忽略”二次激活。这是一个问题,因为之前的工作 [Mol+17; Liu+18] 表明现代神经网络架构可以被“修剪”以去除无关参数和激活,同时仍然保持几乎相同的精度
我们通过在两种模式下运行我们的规划器来证明这一点。在第一种模式中,我们的规划器被配置为寻找使用二次激活的高性能网络,而在第二种模式中,它被配置为寻找使用恒等函数而不是二次激活的网络,直觉是如果二次激活无效,那么使用身份函数的网络也会表现得一样好。图 7(对于 CIFAR-10)和图 8(对于 CIFAR-100)显示了不同数量的非 ReLU 层的运行结果。总之,这些结果表明我们的规划器输出的网络实现了与全 ReLU 基线相当的性能。此外,随着非 ReLU 层数的增加,使用恒等激活函数的性能最佳网络的准确度远低于使用二次激活函数的等效网络。
规划好的网络表现更好。为了评估我们的规划器找到提供良好性能的网络的能力,我们运行规划器来生成具有不同数量(比如 k)的二次层的网络。然后,我们将这些网络中的 ReLU 激活数与全 ReLU 网络(如 GAZELLE 支持的网络)中的激活数进行比较。图 9 说明了 CIFAR-100 上 ResNet32 的这种比较。我们观察到我们的规划器发现的网络始终具有比全 ReLU 基线更少的激活。

7.4 DELPHI 的密码协议
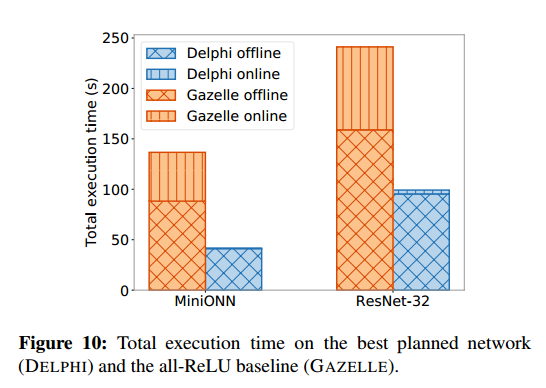
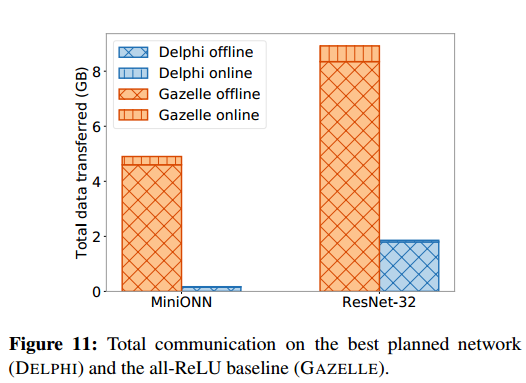
我们通过展示 DELPHI 的预处理阶段和在线阶段比之前的工作 (GAZELLE) 显着节省延迟和通信成本来证明 DELPHI 加密协议的有效性。图 10 和 11 总结了我们的规划者发现的网络的这种改进;接下来我们提供详细的评测。
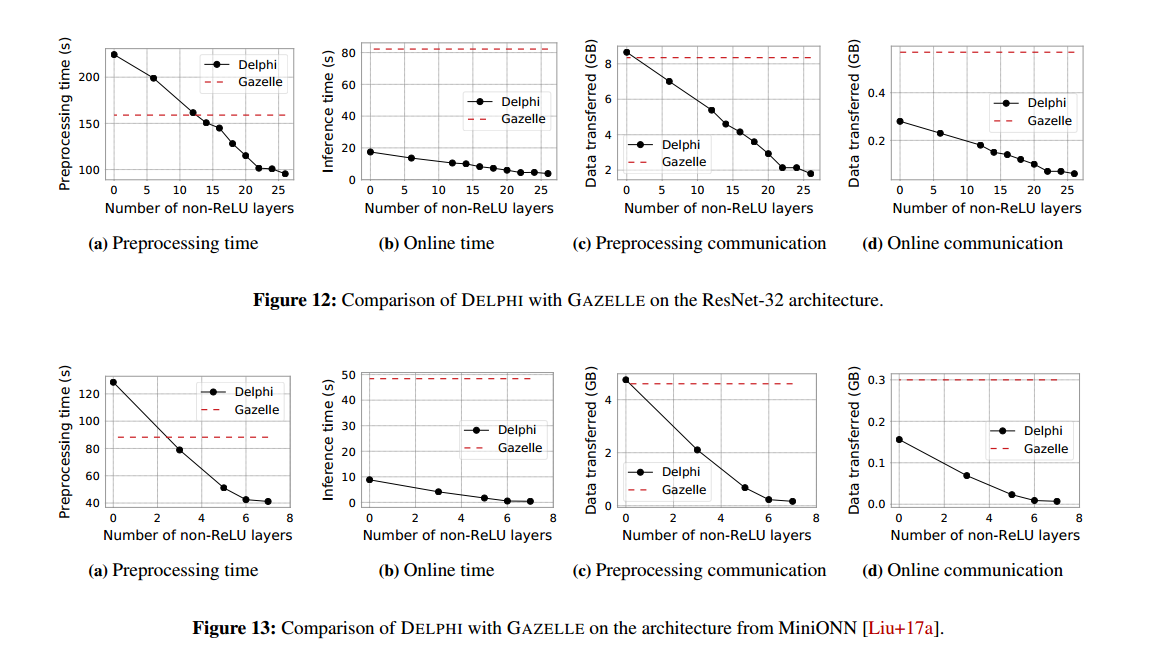
预处理阶段。 图 12a 和 13a 分别比较了在 CIFAR-100 上的 ResNet32 和 CIFAR-10 上的 MiniONN 架构上执行 DELPHI 和 GAZELLE 预处理阶段所需的时间。在这两种情况下,我们都观察到,在具有大量 ReLU 激活的网络上,DELPHI 的预处理时间比 GAZELLE 的要长。这是因为DELPHI需要对每个线性层额外进行预处理。然而,随着近似激活次数的增加,DELPHI 的预处理时间迅速减少到低于 GAZELLE,因为 ReLU 的乱码电路比近似激活的预处理阶段要昂贵得多。对于图 12c 和 13c中的通信成本,可以观察到类似的趋势。 总体而言,对于我们的规划器输出的最高效网络,DELPHI 需要的预处理时间减少 1.5-2 倍,通信时间减少 6-40 倍。
在线阶段。 图 12b 和 13b 分别比较了在 CIFAR-100 上的 ResNet32 和 CIFAR-10 上的 MiniONN 架构上执行 DELPHI 和 GAZELLE 在线阶段所需的时间。在这两种情况下,我们都观察到 GAZELLE 使用 HE 来处理线性层会产生显着的计算成本。此外,随着近似激活次数的增加,DELPHI 和 GAZELLE 之间的差距越来越大。对于图 12d 和 13d中的通信成本,可以观察到类似的趋势。 总体而言,对于我们的规划器输出的最高效网络,DELPHI 需要 22-100 倍的时间来执行其在线阶段,并且减少 9-40 倍的通信。
8 相关工作
我们首先在第 8.1 节中讨论用于安全执行机器学习算法的密码技术。然后,在第 8.2 节中,我们讨论了从预测中恢复有关模型的信息的模型推理攻击,以及针对这些攻击的对策。最后,在第 8.3 节中,我们讨论了先前关于神经架构搜索的工作。
8.1 安全机器学习
安全推理问题可以通过通用安全计算技术解决,如安全两方(2PC)计算[Yao86; Gol+87],完全同态加密(FHE)[Gen09],或同态秘密共享(HSS)[Boy+16]。然而,由此产生的协议将遭受可怕的通信和计算复杂性。例如,使用 2PC 计算函数的成本随着该函数的(算术或布尔)电路的大小而增长。在我们的设置中,被计算的函数是神经网络本身。评估网络需要矩阵向量乘法,并且用于该运算的电路随着输入的大小呈二次方增长。因此,使用通用的 2PC 协议进行安全推理将导致计算和通信中的直接二次爆炸。
同样,尽管为提高 FHE 的效率做出了一系列努力 [Bra+11; 11 世代;范+12;哈尔+18; Hal+19]和HSS[Boy+17],它们的计算开销还是很大的,不适合在我们的场景中使用。
因此,似乎有必要为安全机器学习设计专门的协议,并且确实有很长的前期工作[Du+04;刘+06;栏+09;尼克+13a;尼克+13b;山姆+15;博斯+15;吴+16a;怡安+16; Sch+19] 正是这样做的。这些工作通常分为两类:那些专注于安全训练的,以及那些专注于安全推理的。由于安全训练不是本文的重点,因此我们省略了讨论,而是专注于安全推理的先前工作。大多数这些早期工作都集中在更简单的机器学习算法上,例如 SVM 和线性回归。为这些更简单的算法设计密码协议通常比我们为神经网络设置推理更容易处理。
因此,在本节的其余部分,我们将讨论专注于神经网络安全推理的先前工作。这项工作一般分为以下几类: (a) 基于 2PC 的协议; (b) 基于 FHE 的协议; (c) 基于 TEE 的协议; (d) 在多方模型中工作的协议。
基于2PC的协议。 SecureML [Moh+17] 是首批关注神经网络安全学习和预测问题的系统之一。然而,它完全依赖于通用的 2PC 协议来做到这一点,导致在现实网络上的性能不佳。 MiniONN [Liu+17a] 使用 SPDZ 协议来计算线性层和多项式近似激活。与 DELPHI 不同,MiniONN 为线性层中的每个乘法生成乘法三元组;对于输入大小为 n 的层,与 DELPHI 的 n 相比,MiniONN 需要 n 2 个离线和在线通信。
GAZELLE [Juv+18] 是与我们最相似的系统:它对线性层使用基于 HE 的高效协议,同时使用乱码电路来计算非线性激活。然而,它在在线阶段依赖大量的密码操作导致协议在计算和通信方面比 DELPHI 的协议更昂贵(请参阅第 7 节进行全面比较)。
DeepSecure [Rou+18] 和 XONN [Ria+19] 使用乱码电路为权重均为布尔值的受限类二值化神经网络 [Cou+15] 提供安全推理。此限制使这些协议能够构建一个仅使用固定次数往返的协议。DeepSecure 还修剪输入神经网络以减少激活次数。 Ball 等人 [Bal+19] 最近还构建了一个安全推理协议,该协议依赖于 [Bal+16] 的乱码方案。与 XONN 和 DeepSecure 不同,[Bal+19] 的协议支持通用神经网络。尽管进行了优化,但这些工作中的每一个都面临着巨大的具体成本,因为每个工作都在乱码电路内执行矩阵向量乘法。
EzPC [Cha+17],在输入程序的高级描述时,综合实现该程序的加密协议。编译后的协议智能地混合使用算术和布尔 2PC 协议来提高效率。
基于 FHE 的协议。 CryptoNets [Gil+16] 是第一个尝试优化和定制 FHE 方案以进行安全推理的工作。尽管进行了优化,但 FHE 的局限性意味着 CryptoNets 仅限于只有几层深度的网络,即使对于这些网络,它也只有在处理一批输入时才会变得高效。近期论文[Hes+17;布鲁+18;布+18;赵+18; San+18] 开发了不同的方法来优化 CryptoNets 范例,但生成的协议仍然需要数十分钟才能对比我们在此考虑的网络小得多的网络提供预测。
CHET [Dat+19] 将神经网络的高级规范编译为基于 FHE 的推理协议。为了有效地使用 FHE,CHET 必须用多项式近似替换所有 ReLU,这会损害大型网络的准确性。
基于 TEE 的协议。 有两种使用可信执行飞地 (TEE) 进行推理的方法:(a) 通过服务器端飞地进行推理,其中客户端将其输入上传到服务器的飞地,以及 (b) 在客户端飞地中进行推理,其中客户端提交查询存储在客户端飞地中的模型。
Slalom 和 Privado 是依赖服务器端飞地的协议示例。 Slalom [Tra+19] 与 DELPHI 一样,将推理分为离线和在线阶段,在线阶段使用附加秘密共享。与 DELPHI 不同,Slalom 使用英特尔 SGX 硬件飞地 [McK+13] 来安全地计算离线和在线阶段。 Privado [Top+18] 将神经网络编译成不经意的神经网络,这意味着计算转换后的网络不需要对秘密数据进行分支。他们使用不经意的网络在英特尔 SGX 飞地内执行推理。 Slalom 的实现表明它不会无意识地实现线性或非线性层。
MLCapsule [Han+18] 描述了一个通过客户端飞地执行推理的系统。 Apple 使用客户端安全飞地执行指纹和面部匹配以授权用户 [App19]。
一般来说,大多数基于 TEE 的密码推理协议比依赖密码的协议(如 DELPHI)提供更高的效率。这种效率的提高是以威胁模型较弱为代价的,该模型需要对硬件供应商的信任和 enclave 的实施。此外,由于协议执行发生在对抗性环境中,任何侧信道泄漏都更加危险(因为对手可以小心地操纵执行以强制进行这种泄漏)。确实,过去几年出现了一些强大的侧信道攻击[Bra+17;哈+17;得到+17;莫格+17;施+17;万+17; Van+18] 对抗英特尔 SGX 和 ARM TrustZone 等流行飞地
多方的协议。 上面的讨论集中在两方协议上,因为在我们看来,安全推理自然地映射到这种设置。尽管如此,许多作品 [Ria+18;摇摆+18;铁; Bar+19] 改为针对三方设置,其中模型的份额在两个非共谋服务器之间分配,客户端必须与这些服务器交互以获得它们的预测。
8.2 预测中的模型泄漏
预测API攻击[Ate+15;自由+15;吴+16b;贸易+16;翔+17; Jag+19] 的目标是学习关于服务器模型或训练数据的私人信息,只允许访问任意查询的预测结果。
除了速率限制和查询审计 [Jag+19] 之外,没有针对预测 API 攻击的一般防御措施。但是,可以防御特定类别的攻击。例如,可以使用差异私有训练 [Sho+15; Aba+16] 来训练不泄露有关底层训练数据的敏感信息的神经网络。
DELPHI 的保证是对任何此类缓解措施提供的保证的补充。事实上,只要付出足够的努力,这些技术就可以集成到 DELPHI 中,以提供更强大的隐私保证;我们把它留给未来的工作。
8.3 神经结构搜索
最近,机器学习研究在神经架构搜索 (NAS) 领域取得了快速进展(参见 [Els+19; Wis+19] 调查)。该领域的目标是开发通过优化网络的超参数来自动优化神经网络属性(如准确性和效率)的方法。通常优化的超参数示例包括卷积核的大小、层数以及梯度下降算法的参数,如学习率和动量。在这项工作中,我们仅依靠 NAS 算法来优化网络中二次逼近层的放置,因为 ReLU 激活是我们系统中的瓶颈。
- Delphi Cryptographic Inference Networks Servicedelphi cryptographic inference networks cryptographic cryptographic failures control warrior 密码学cryptographic sat functions inference mlcommons-inference inference computer learning vision classification exploiting questions inference inference paddle react typescript inference fixing