在本章中,我们将学习Julia中实现分布式算法的基本工具。我们介绍了Julia中的用于分布式计算的两种主要编程模型:1)Julia标准库附带的基于任务的模型;2)Julia与消息传递接口MPI的绑定。
学习完本章节后,我们应该能够:
- 使用两种不同的编程模型(基于任务的模型和MPI)在Julia中实现分布式算法。
- 了解两种模型之间的主要区别。
本次notebook中,我们将学习Julia中的分布式计算的基础知识,我们将关注Julia标准库中提供的分布式模块,讨论以下问题:
- 如何创建Julia进程
- 如何远程执行代码
- 如何发送和接收数据
如何创建Julia进程
首先,我们得需要多个进程才能并行运行算法。在本节中,我们将讨论Julia中创建新进程的不同方法。
本地添加进程
创建并行计算进程的最简单方法就是将它们本地添加到当前的Julia会话中。这是通过以下命令来完成的,想要使用并行计算,首先要load “Distributed” module,这个模块包含了所需的所有function:
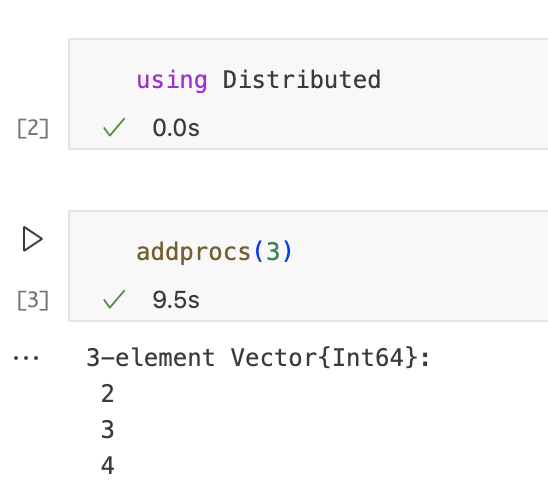
这创建了3个新的Julia进程,默认情况下,它们在与当前Julia会话相同的计算机上本地运行,如果可能的话使用多个内核。然而,也可以在其他机器上启动新进程,只要它们是互连的。
tips:我们还可以在从命令行启动Julia时通过“-p”命令行参数来启动新进程。例如,“$ julia -p 3”将启动带有3个额外进程的Julia。
每个进程运行一个单独的Julia实例
添加新进程时,我们可以想象3个新的Julia REPL已经在后台启动。Distributed模块的要点是提供一种协调所有这些Julia进程以并行运行代码的方法。要注意的是,每个进程都在单独的Julia实例中运行。这意味着,每个进程都有自己的内存空间,因此它们不共享内存。这导致了分布式内存并行性,并允许在不同的机器上运行进程。
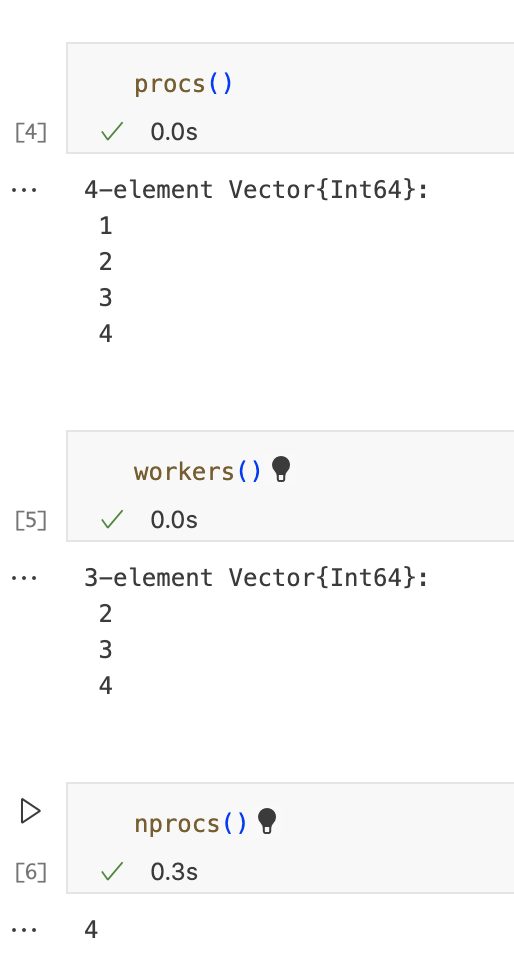
有关进程的基本信息
以下函数提供有关底层进程的基本信息,如果有多个进程可用,则第一个进程成为main或者master,其他的为workers。如果只有一个进程,则它同时是主进程和第一个工作进程。
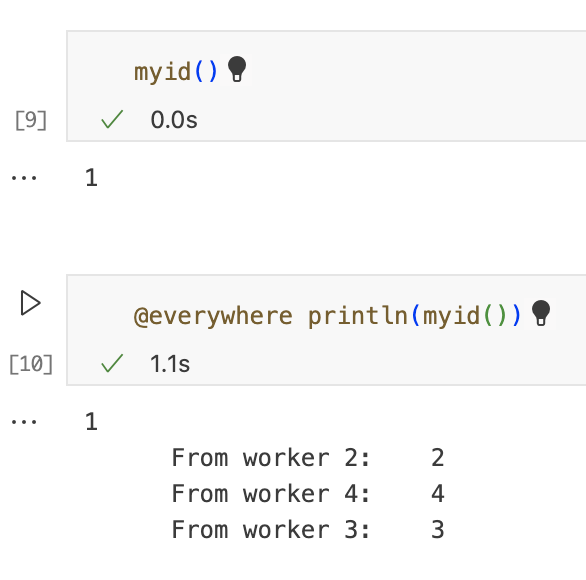
在上一个单元格中,我们使用了宏“@everywhere”在所有可用的进程上评估给定代码。因此,每个进程将打印自己的进程id。
在其他机器上创建worker
对于大型并行计算,通常需要并行使用不同的计算机。函数addprocs还提供了一种低级的方法来启动其他机器中的工作程序。下边代码示例中,在server1中建立3个worker,在server2中建立4个worker。在幕后,Julia通过ssh连接到其他机器并在那里启动新进程。为了使其工作,需要正确配置本地计算机和远程服务器。
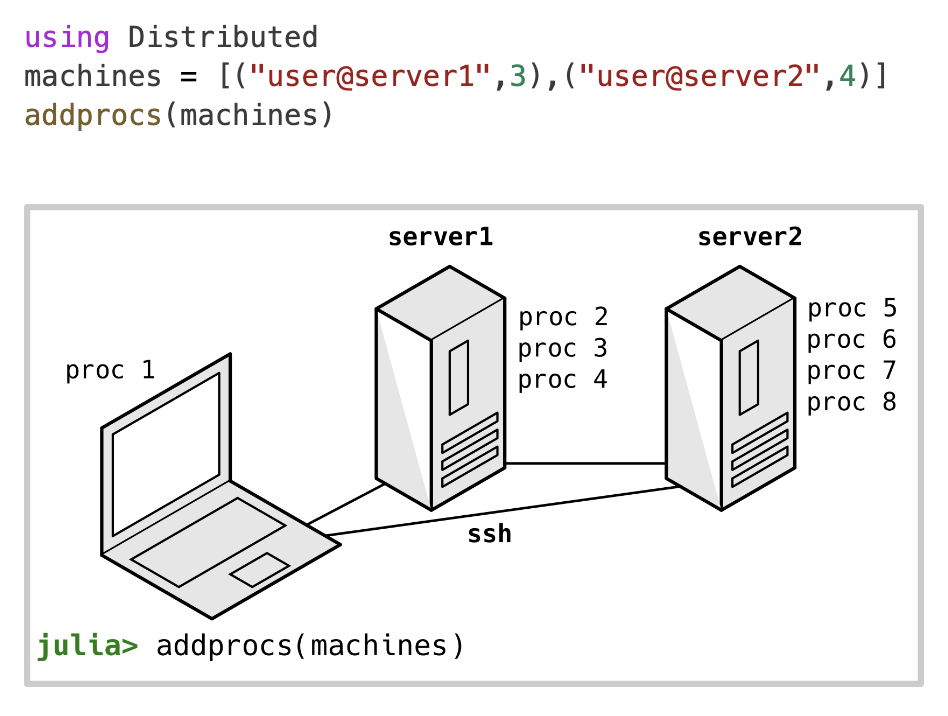
使用ClusterManagers.jl添加worker
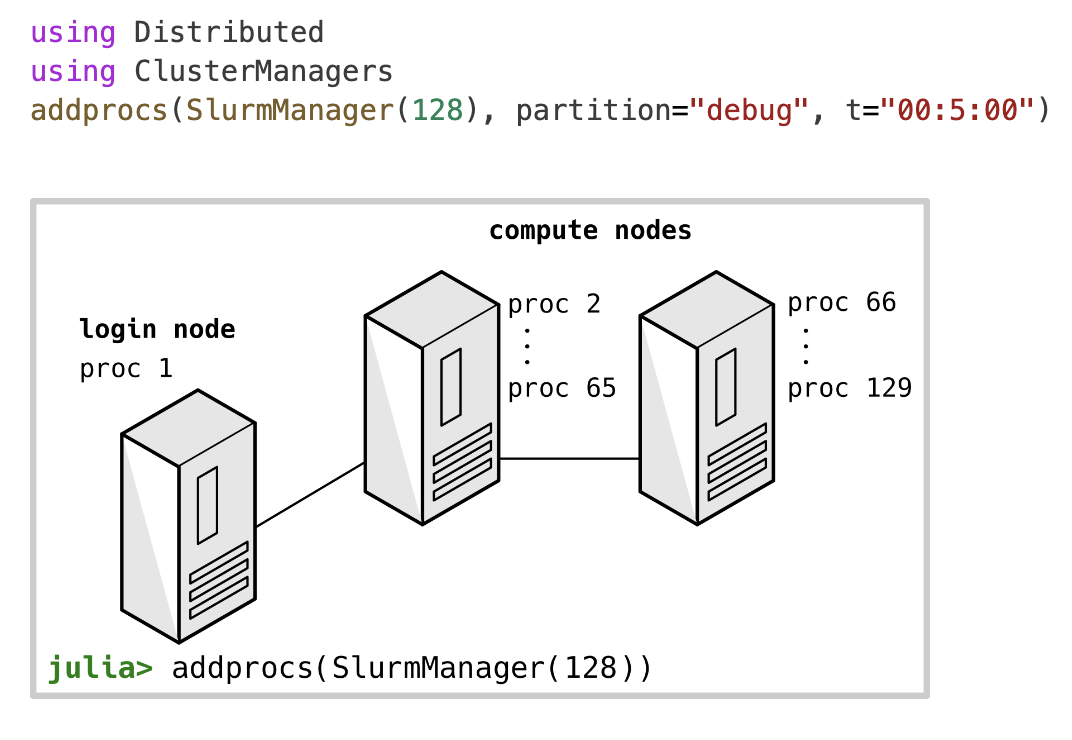
以前在其他机器上启动worker的方式非常低级,我们有一个名为ClusterManagers.jl的Julia包可以帮助在许多场景中远程创建工作线程。例如,当从计算机集群中的登录节点运行以下代码时,它将向分配128个线程的集群队列提交作业。将为每个线程生成一个worker。如果计算节点有64个核心,则将使用2个计算节点来创建包含128个工作线程。
远程执行代码
我们已经在Julia汇总添加了新进程,那么让我们开始使用吧。
Function remotecall
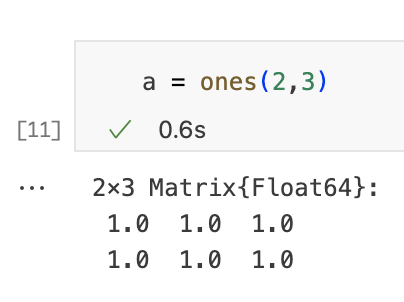
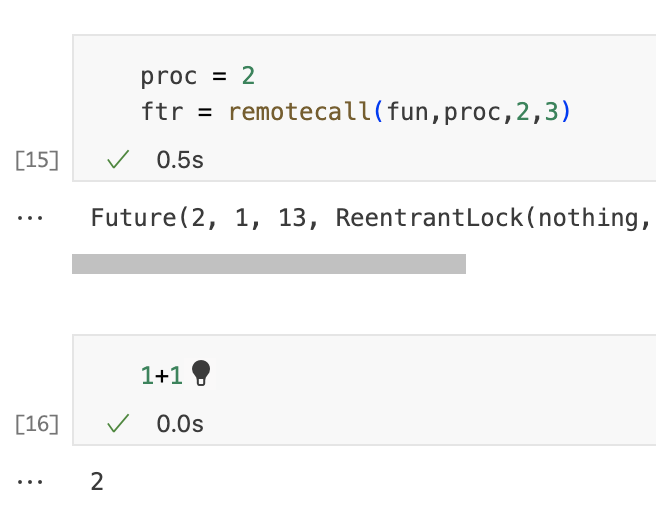
我们可以使用远程处理器做的最基本的事情就是执行给定的函数。这是通过使用remotecall function来完成的。为了清楚地比较本地和远程执行的情况,我们先在本地调用一个函数,然后再远程调用。下一个单元使用函数ones在本地创建矩阵。
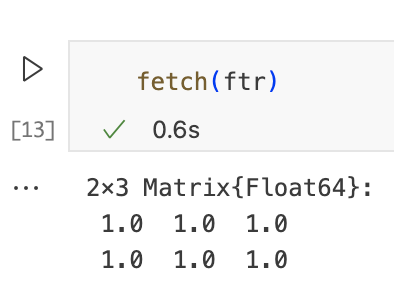
下一个单元格执行相同的操作,但是在进程2上进行远程操作。请注意,remotecall采用我们想要远程执行的函数、我们想要执行的进程的ID以及最后的函数参数。

请注意,remotecall不返回底层函数的结果,而是返回Future。该对象表示对远程进程上运行的任务的引用。要将结果的副本移动到当前进程,我们可以使用fetch,当fetch结果时,我们需要等待任务完成。
remotecall是异步的
需要注意的是,remotecall不会等待远程进程完成。It turns immediately.可以通过远程调用一下函数来检查这一点,该函数会休眠10秒,然后生成一个矩阵。

当运行下一个单元时,它将立即返回,尽管远程进程将休眠10秒。我们甚至可以并行运行代码。要尝试此操作,请在worker中运行远程调用时执行第二个单元。
但是在获取结果的时候,当前进程会阻塞等待,直到结果在远程进程中可用并达到目的地。
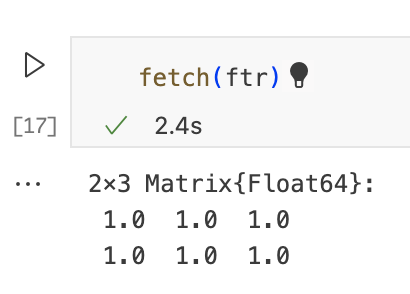
有用的宏:@spawnat
我们可以看到,为了使用remotecall,我们编写了辅助的匿名函数。他们需要包装我们想远程执行的代码。编写这些函数可能很乏味。宏@spaqnat从给定的代码块生成一个辅助函数并调用remotecall。例如,以下两个单元格是等效的:

@async与@spawnat
两者之间的关系是显而易见的,从用户的角度来看,它们的工作方式几乎相同。但是,@async生成一个在当前进程中异步运行的任务,而@spawnat在远程进程中并且执行一个任务。在两种情况下,获取结果都使用fetch。
在Julia中,:any 表示任务(Task)的目标位置可以是任何可用的工作进程。当你使用 @spawnat 宏时,你可以指定一个工作进程的标识符,告诉Julia将任务发送到特定的工作进程执行。然而,有时你可能希望任务能够在任何可用的工作进程上执行,而不需要指定一个具体的工作进程。
另一个有用的宏:@fetchfrom
宏' @fetchfrom '是' @spawnat '的阻塞版本。它阻塞并返回相应的结果,而不是' Future '对象,以下两者是等价的。


Data movement
这是分布式内存计算的关键部分,通常是其主要计算瓶颈之一。在使用诸如此类的函数时,了解我们正在移动的数据对于remotecall在Julia中编写高效的分布式算法非常重要。Julia还提供了一种特殊类型的通道,称为远程通道,用于在进程之间发送和接收数据。
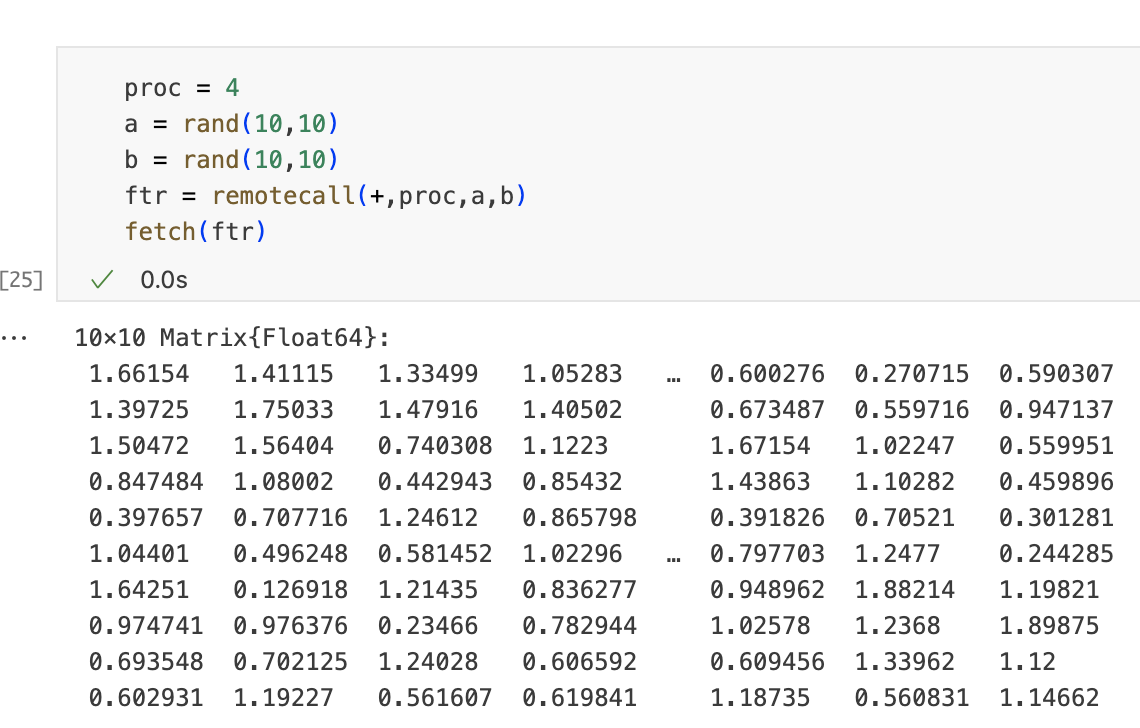
Data movement in remotecall/fetch(Explicit)
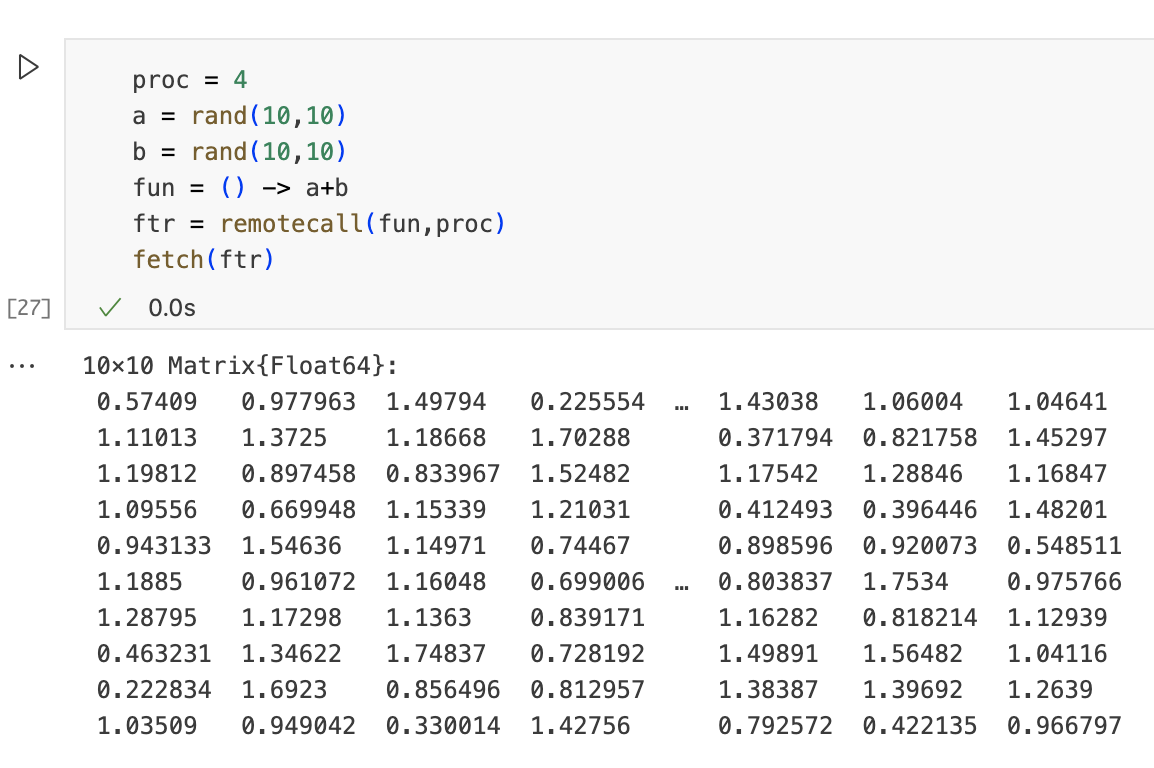
当使用' remotecall '时,我们向远程进程发送一个函数及其参数。在这个例子中,我们将函数名' + '和矩阵' a '和' b '发送给进程4。当获取结果时,我们从进程4中获得矩阵的副本。
我们发送可200个integer,接收100个integer。
隐式数据移动(Implicit)
数据移动可能是隐式的,当我们远程执行捕获变量的函数时,通常会发生这种情况。在下边的示例中,我们仍将矩阵a和b发送到进程4,即使它们在远程调用中不作为参数出现。这些变量被匿名函数捕获,并将被发送到进程4,与Explicit发送的数据量相同。
通过远程channel进行Explicit数据移动
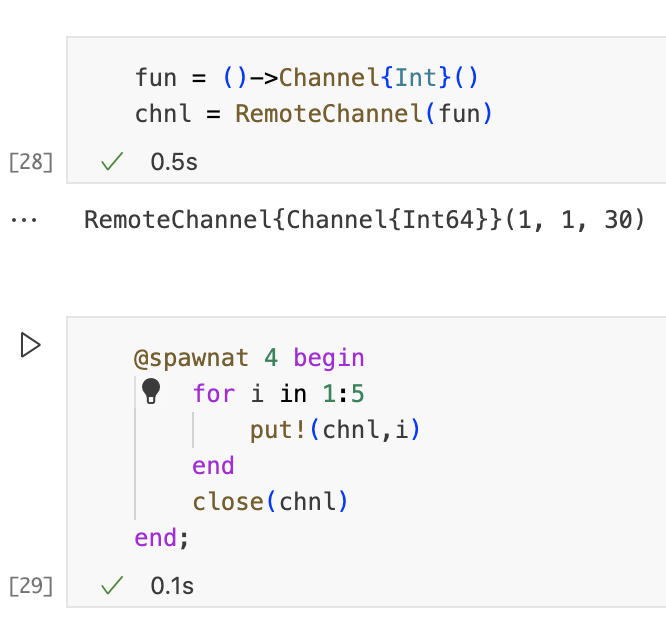
在进程之间移动数据的另一种方法是使用远程管道。它们的用法与在任务之间移动数据的传统channel十分相似,但是也有一些重要区别。在下一个单元中,我们创建一个远程通道。进程4输入几个值并关闭通道。与传统通道一样,对put!的调用是阻塞的,但下一个单元不会阻塞主进程,因为对put!的调用在进程4上异步运行。
我们可以使用take!从任何进程的远程通道获取值。运行下一个单元格几次,由于通道关闭,它应该产生错误。

这是行不通的!
我们确实需要远程通道来通信不同的进程。标准频道不起作用。例如,下面的代码将在' take! '处阻塞。Worker 4将接收到通道的另一个副本,并将值放入其中。在主进程中定义的通道将保持空,这将使采取!阻止。

Remote channels can be buffered
就像传统通道一样,远程通道可以进行缓冲。缓冲区存储在拥有远程通道的进程中。默认情况下,这对应于创建远程通道的进程,但它可以是不同的进程。例如,进程3将是owner:
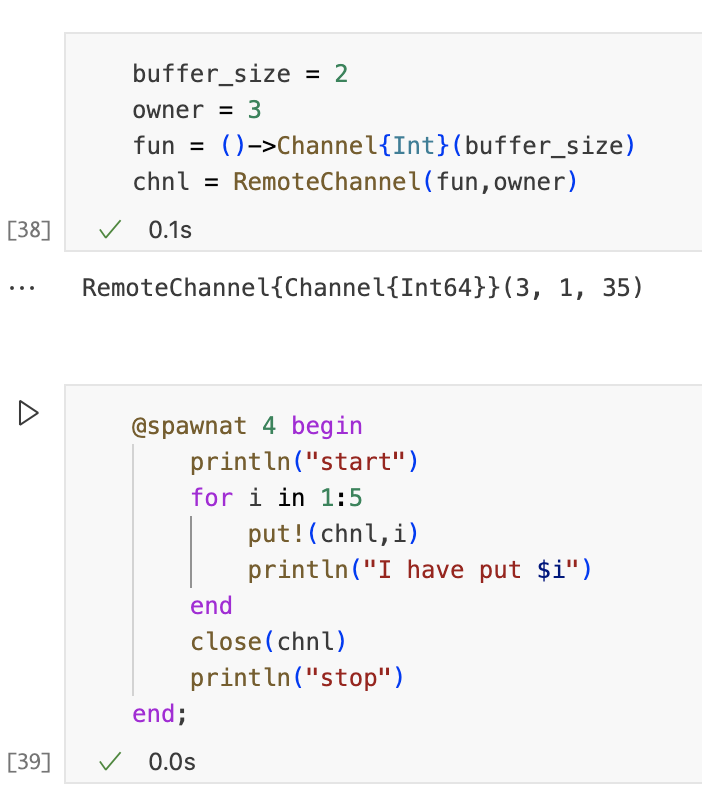

请注意,由于通道是缓冲的,worker4可以在任何调用take!之前开始将值放入其中。
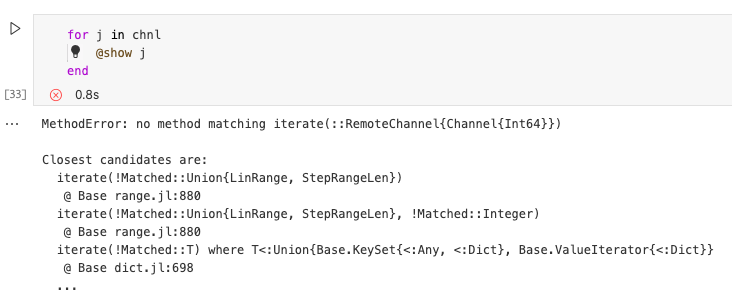
远程通道不可迭代
与传统通道的一个区别就是远程通道无法迭代,让我们重复一下上边的例子:

尝试在for循环中迭代通道,但是由于通道不可迭代,因此会导致错误。
如果我们想从远程通道获取值并在通道关闭时自动停止,我们可以组合while循环和try-catch语句。这是有效的,因为take!在通道关闭时会引发错误,这将执行catch块并中断循环。
Questions
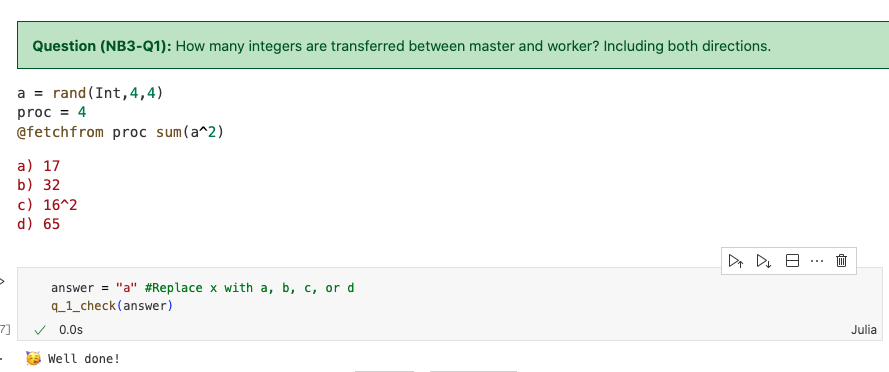
解析:本地向远程传递16个数字,远程返回1个,则一共17个。
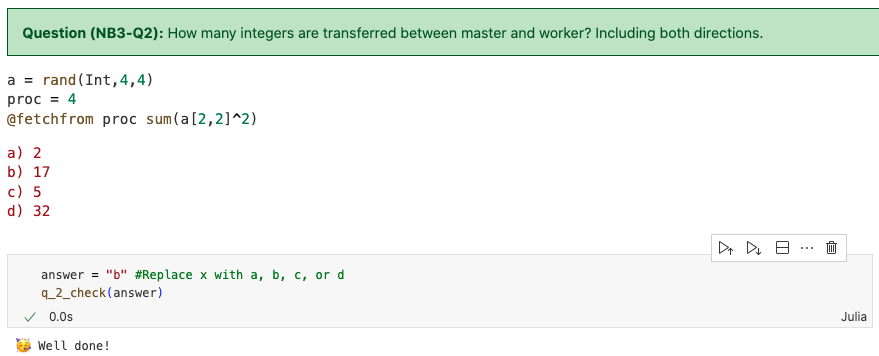
解析:我们将整个矩阵的元素发送过去,但是只计算一个元素,答案仍然是17个。如果在倒数第二行加一行a22 = a[2,2],然后最后一行写成sum(a22 ^ 2),则通信的数字数量就为两个。
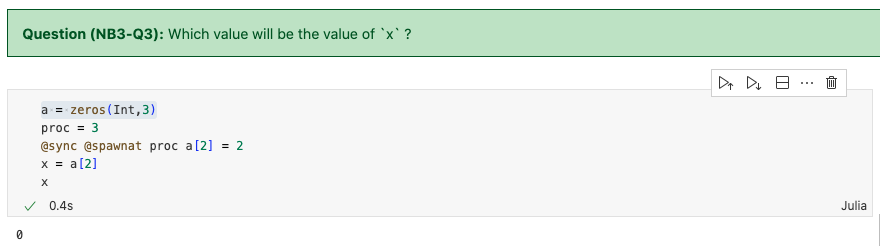
解析:答案是0,因为我们将a的副本发送到proc4,但是本地的a并没有改变,则x仍为原来的数值0。
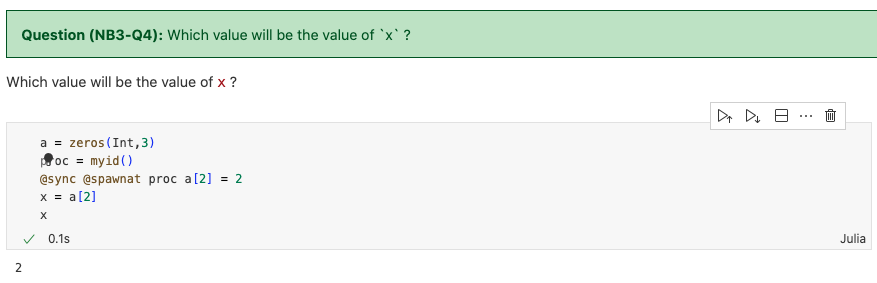
解析:因为发送的proc是本进程,因此改变是在本地进行的,it will update the local copy。去掉@sync之后,结果会变成0,是因为什么呢?

因为我们schedule一个task,而不等待task运行完成,因此,在task还没运行的时候,本地的值还没有update,返回仍然是0.
Reminder
每个进程运行在一个独立的Julia实例中,特别是,这意味着每个进程可以加载不同的函数或包。因此,确保我们运行的代码在相应的进程中的定义是十分重要的。
Functions are defined in a single process
在运行并行代码时,这是一个常见的陷阱。如果我们在一个进程中定义了一个函数,那么它在其他进程中是不可用的。下一个示例将对此进行说明。下一个单元格最后一行中的远程调用将失败,因为函数'spleep_ones'只在本地进程中定义。
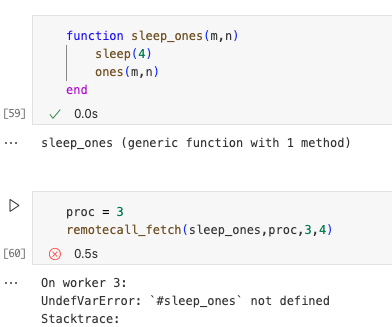
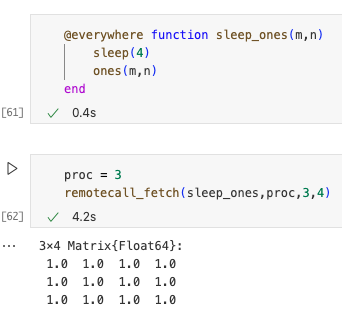
为了解决这个问题,我们可以使用宏在所有进程上定义该函数@everywhere。
匿名函数随处可用
如果函数有名称,Julia只会将函数名称发送到相应的进程。然后,Julia在远程进程中查找相应的函数代码并执行。这就是为什么该函数也需要在远程进程中定义。但是,如果函数是匿名的,Julia中需要将完整的函数定义发送到远程进程。这就是为什么匿名函数不需要用@everywhere来在远程调用中工作的原因。

每个进程独立使用包
当在一个进程中使用某个包时,它在其他进程中不可用。例如,如果我们在当前进程加载LinearAlgebra包并在另一个进程中使用其导出函数之一,我们将收到错误。
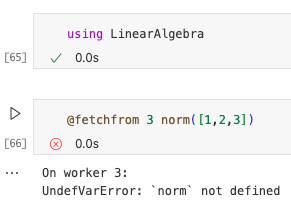
为了解决这个问题,我们可以使用宏@everywhere在所有进程上加载包。

每个进程都有自己的active package environment
这是另一个非常常见的错误来源,如果激活当前目录,不会对其他进程产生影响。
当激活当前文件夹以后,进程2仍然在使用全局环境。
为了解决这个问题,我们需要激活所有进程的当前目录。
并行化代码的简单方法
有用的宏:@distributed
当我们想执行由独立的小迭代组成的非常大的for循环时,可以使用该宏。为了说明这一点,我们再次考虑计算p的函数。

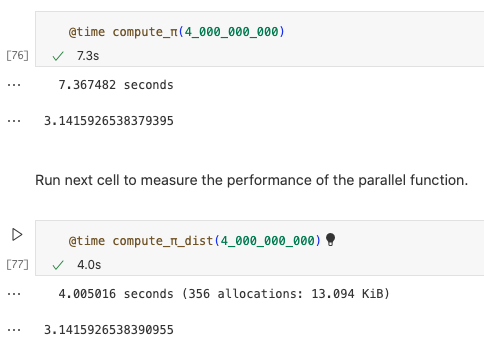
并行化此函数可能需要对诸如remotecall之类的低级函数进行一些处理,但是使用@distributed就很简单了。该宏使用可用进程运行for循环,并使用给定的缩减函数(本例中为“+”)选择性地缩减结果。

运行下边的单元格测量串行函数在n较大时的性能,至少运行两次,消除编译时间。
有用的功能:pmap
当我们想要调用一个非常昂贵的函数进行少量评估并且我们想要将这些评估分布在可用进程上时,可以使用此函数。为了说明pmap的用法,考虑如下示例。这个代码生成60个30*30的矩阵,目标是计算所有这些奇异值分解。众所周知,对于大型矩阵,此操作的成本很高。因此这是一个适用于pmap的完美场景。
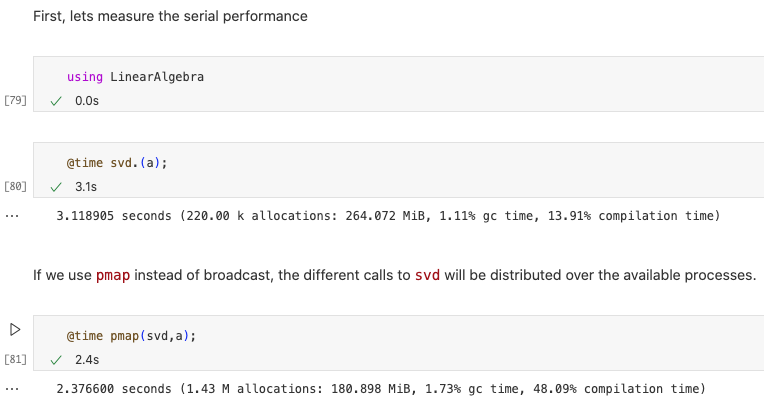
首先我们测试串行的性能,接着,使用pmap而不是broadcast,则不同的svd调用将分布在可用的进程上,运行时间降低。
总结
我们本节了解了Julia分布式计算的基础知识。编程模型本质上是task和channel在多台机器上并行计算的扩展。低级函数是remotecall和remotechannel,但是还有一些其他函数和宏,例如pmap和@distributed,可以简化并行算法的实现。