Kylin&CDH理论基础
一、维度与度量
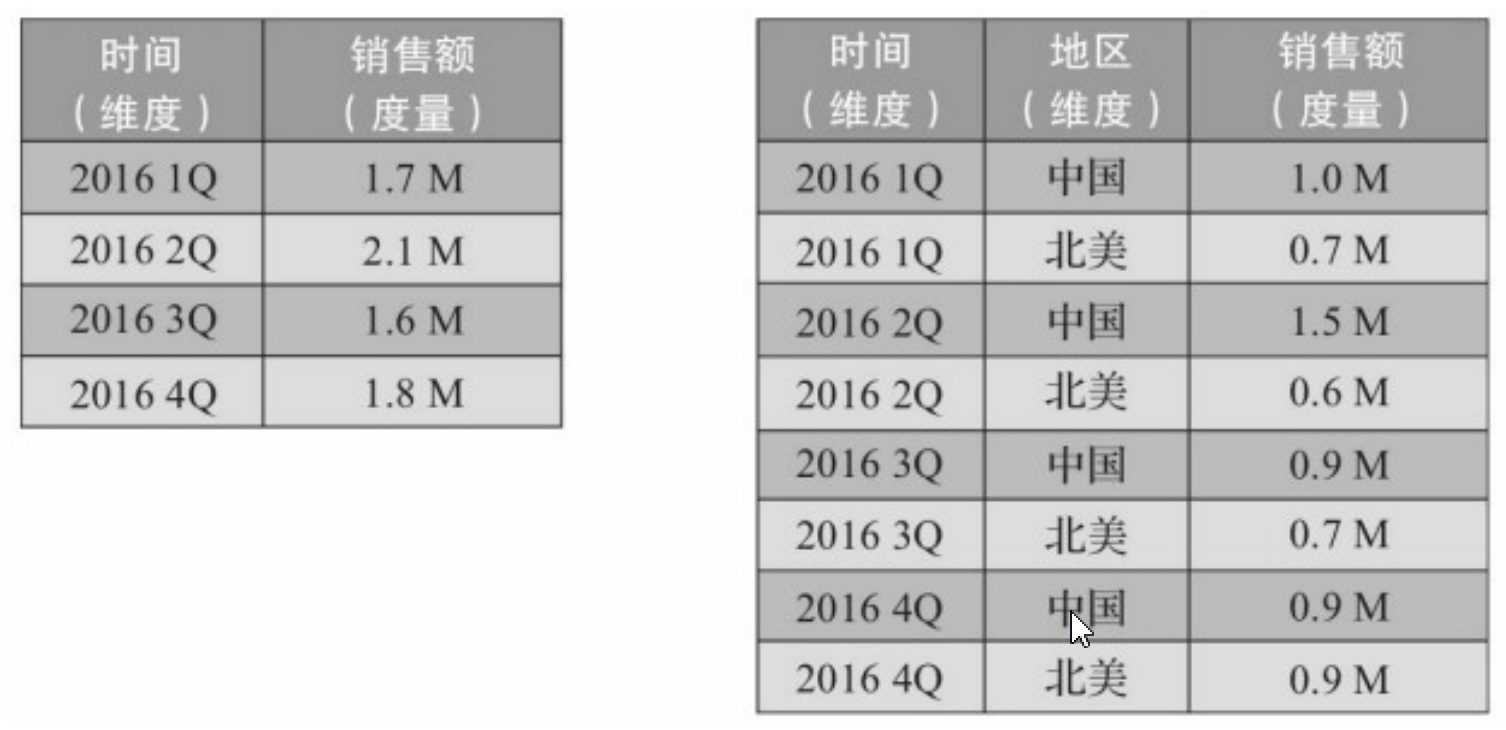
维度是观察数据的角度。比如电商的销售数据,可以从时间维度来观察,进一步细化时间和地区维度来观察。
度量是被聚合的统计值,也是聚合运算的结果。知道维度和度量,可以对数据模型上的所有字段进行分类,要么维度,要么度量,由此就出现了根据维度、度量做预计算的Cube理论。
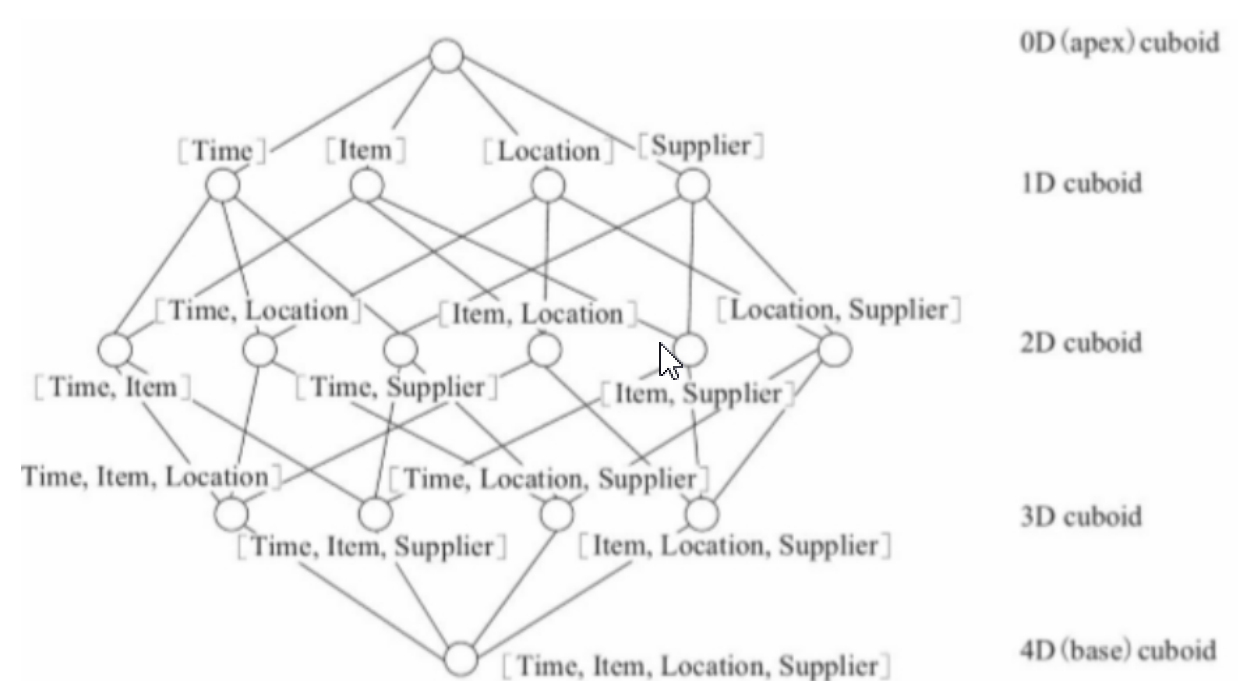
给定一个数据模型,我们可以对其上所有维度进行组合。对于N个维度来说,所有组合的可能性有 2N种。对每一种维度的组合,将度量做聚合运算,运算的结果保存为一个物化视图,称为 Cuboid,将所有维度组合的Cuboid作为一个整体,被称为Cube。简单来说,一个cube就是许多按维度聚合的物化视图得到集合。
二、Cube模型
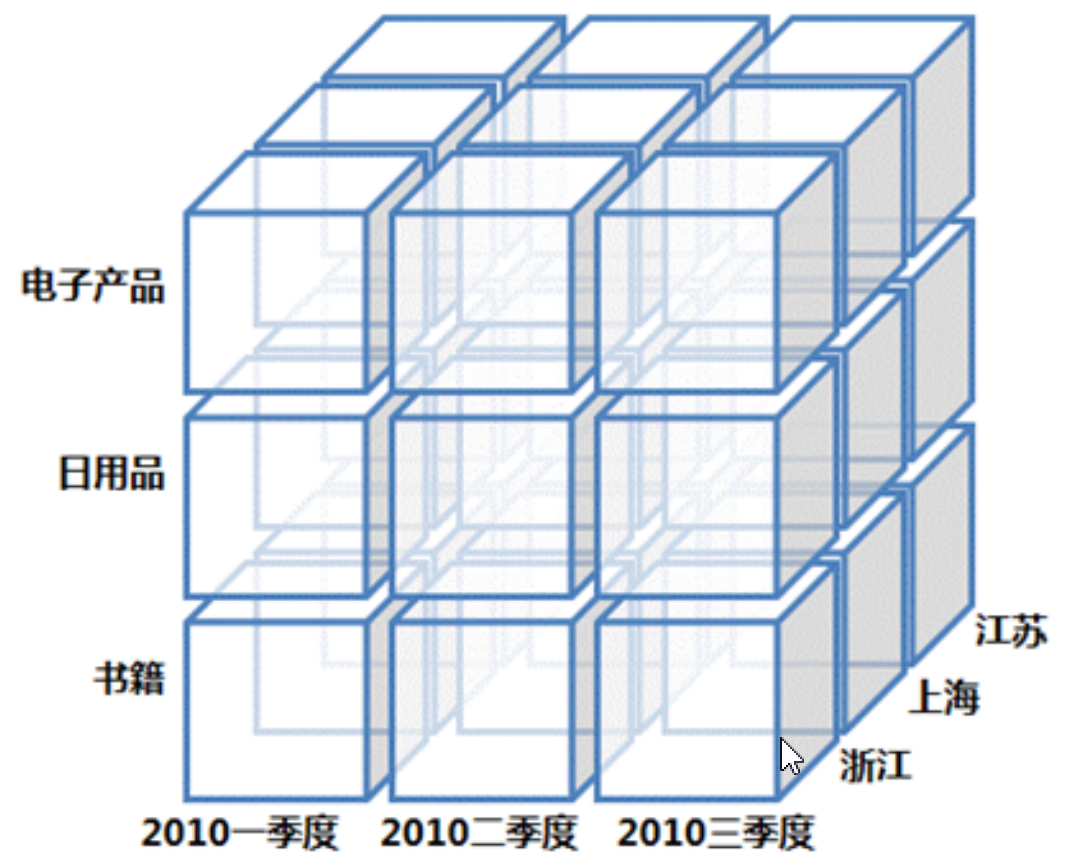
cube模型是以多维数组的方式,物化到存储系统中,加快后续的查询。类似魔方的形状,由于cube做了提前预聚合,因此性能上非常优秀,但是有一个问题,生成cube需要大量的时间、空间。维度的预处理可能造成数据的膨胀。一个多维数据集称为一个OLAP Cube,Cuboid是其中一个组合数据集。如:城市、品类、月份这三个维度,形成共八种组合数据集,其中的城市、品种形成的数据集表示一个Cuboid。
- 电商数据

- 例如:基于时间和基于地址计算GMV总和
select Time, Location, Sum(GMV) as GMV from Sales group by Time,Location
kylin基于cube预查询,解决了千亿条、万亿条记录的秒级查询问题,并且打破时间随着数据量成线性增长的这个问题。查询效率图如下:
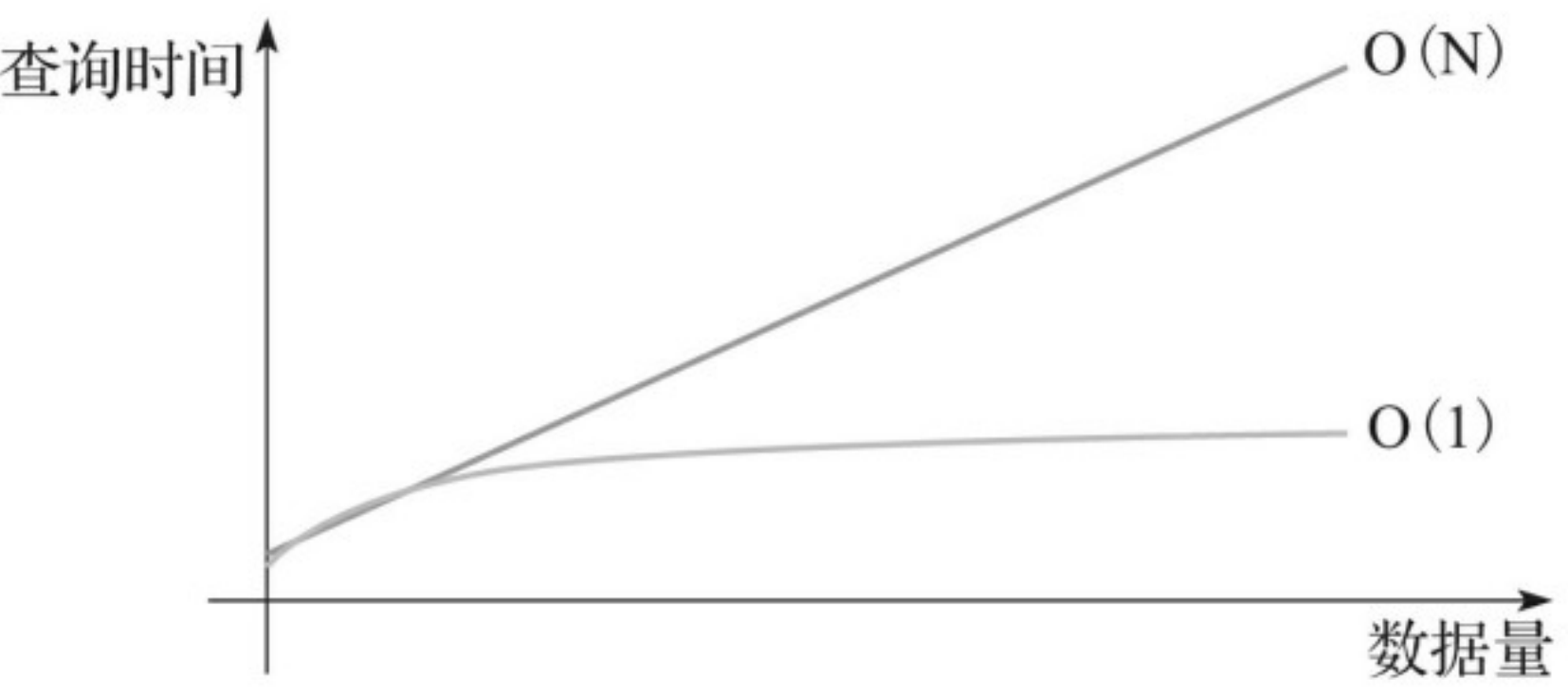
三、框架介绍
pache Kylin™ 是一个开源的分布式分析引擎,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,能够处理TB乃至PB级别的分析任务,能够在亚秒级查询巨大的Hive表,并支持高并发。
作为一个 SQL 加速层,Kylin 可以下接各种数据源,例如 Hive/Kafka,上接各种 BI 系统,比如Tableau,PowerBI。
- 核心优势
Apache Kylin的主要特点包括支持 SQL 接口、支持超大数据集、亚秒级响应、可伸缩性、高吞吐率、BI 工具集成等。
Apache Kylin提供了丰富的API,以与现有的BI工具集成,具体包括如下内容。
ODBC接口:与Tableau、Excel、Power BI等工具集成。
JDBC接口:与Saiku、BIRT等Java工具集成。
Rest API:与JavaScript、Web网页集成。
分析师可以沿用他们最熟悉的BI工具与Kylin一同工作,或者在开放的API上做二次开发和深度定制。
- 工作原理
Apache Kylin的工作原理本质上是MOLAP(多维在线分析处理),也就是多维立体分析。
Apache Kylin的工作原理对数据做cube预计算,利用计算的结果加速查询,具体工作如下:
1、指定数据模型(雪花模型、星型模型、星座模型),定义维度和度量。
2、预计算Cube,计算所有Cuboid并保存为物化视图。
3、执行查询时,读取Cuboid,运算,产生查询结果。
总结:Kylin的核心思想是Cube预计算,理论基础是空间换时间,把复杂度的聚合运算、多表连接等操作转换成对预计算结果的查询。
四、技术架构
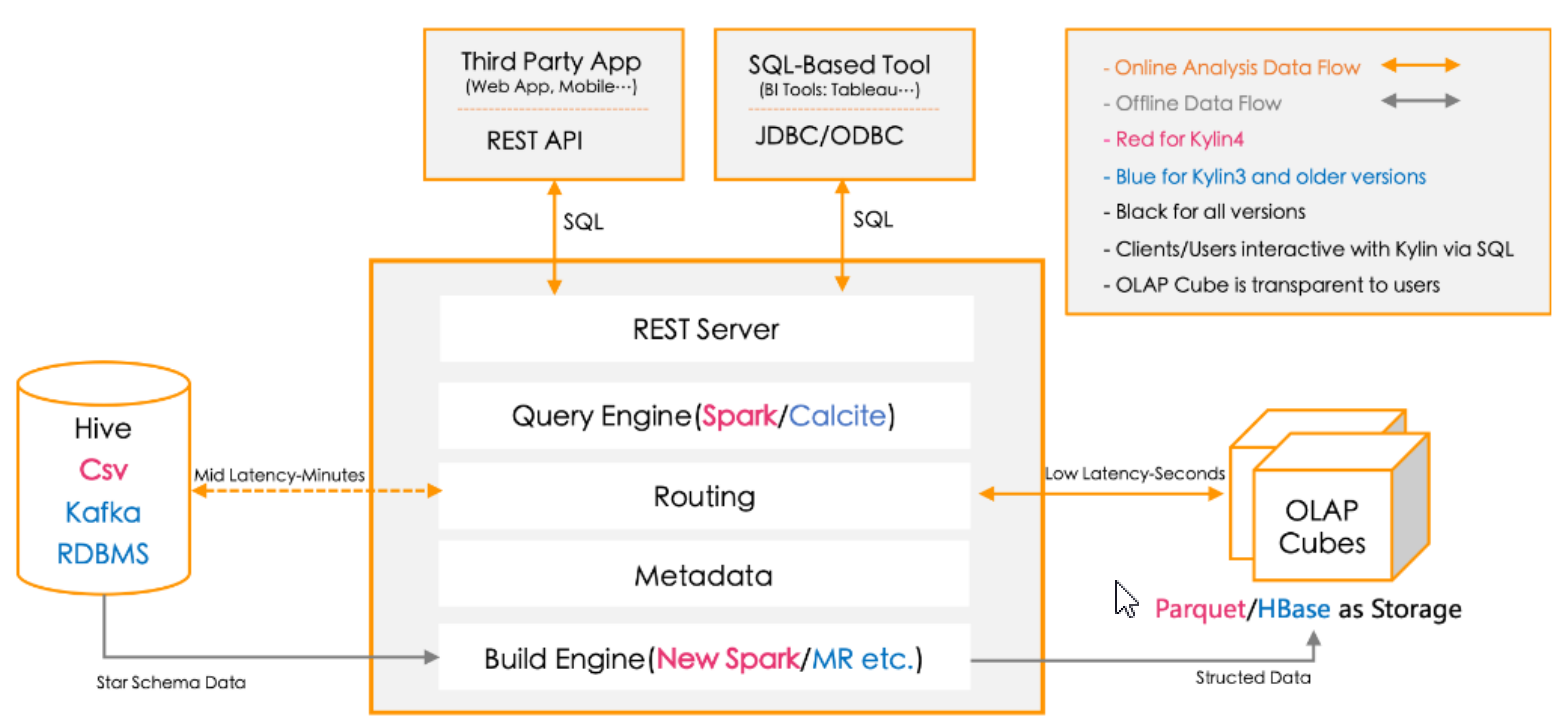
- Kylin系统主要分为在线查询和离线构建两个部分:在线查询主要由上半区组成,离线构建在下半区
- 离线构建:
- 离线数据源在左边,主要是Hadoop、Hive、kafka和RDBMS,保存这待分析的用户数据。
- 下方构建引擎从数据源中抽取数据,选择mapreduce或spark进行构建cube。
- 数据以关系表形式输入,符合星型模型或雪花模型
- 构建后的cube保存在右侧的存储引擎中,默认是用Hbase存储引擎。
- 在线查询:
- 完成离线构建后,用户可以从上方查询系统发送SQL来进行查询分析。
- Kylin提供了多样的Rest API、JDBC/ODBC接口。无论从哪个接口进入,最终SQL都会来到REST服务层,再转交给查询引擎进行处理。
- 查询引擎解析SQL,生成基于关系表的逻辑执行计划,然后将其转译为基于Cube的物理执行计划,最后查询预计算生成的Cube产生结果。整个过程不访问原始数据源。
- 总结:hive查询时间随着数据量的增长而线性增长,kylin使用预计算技术打破了这一点,kylin在数据集规模上的局限性主要取决于维度的个数和基数,而不是数据集的大小,所以Kylin能更好地 支持海量数据集的查询。而也正是预计算技术,kylin的查询速度非常快,亚秒级响应。
- 构建过程
1、选择Model
2、选择维度
3、选择指标
4、cube设计(包括维度和 rowkeys)
5、构建cube(mr 程序,hbase 存储元数据信息及计算好的数据信息)
五、增量Cube
Cube划分为多个Segment,每个Segment用起始时间和结束时间来标志。
Segment代表一段时间内源数据的预计算结果,查询基于时间维度、也可以是timestamp或者string。
大部分情况下一个Segment的起始时间等于它之前那个Segment的结束时间,同理它结束时间等于它后面那个Segemnt的起始时间。(拉链表)
同一个 Cube 下不同的 Segment 除了背后的源数据不同之外,其他如结构定义、构建过程、优化方 法、存储方式等都完全相同。
- 自动合并机制
由于Segment太多会影响查询效率,所以需要定时进行合并,用户就可以在配置文件中设置AUTO_MERGE、THREOLDS自动合并的阈值,用户可以根据自己的需求设置合并的阈值,一般设置两个就够了,两个值是大合并(major merge)和小合并(minor merge),合并时优先进行大合并,然后进行小合并,合并的标准并不是依赖于Segment的大小,而是基于Segment的时间。
例如:大合并28天,小合并7天,当一个Segment被创建并且设置为Ready,就是触发合并机制,从今天一次向前进行计算,看前面所有的Segment是否能凑够大合并的阈值,如果不能达到大阈值,会退而求其之选择小合并阈值,已经达到阈值的segment不会参与合并。

- 保留Segement
从碎片管理的角度来说,自动合并是将多个 Segment 合并为一个 Segment ,以达到清理碎片的目 的。保留 Segment 则是从另外一个角度帮助实现碎片管理,那就是及时清理不再使用的 Segment 。
在很多业务场景 中,只会对过去一段时间内的数据进行查询,例如对于某个只显示过去1 年数据 的报表,支撑它的 Cube 事实上只需要保留过去一年内的 Segment 即可。由于数据在 Hive 中往往 已经存在备份,因此无需再在 Kylin 中备份超过一年的历史数据。
- 数据持续更新
举例来说,假设现在有100个 Segment ,每个 Segment 代表过去的一天的数据, Segment 按照起 始时间排序。在合并时,我们只能挑选前面 93个 Segment 进行合并,如果不小心把第94个 Segment 也一起合并了,那么 当我们试图刷新过去7天(94~100)的 Segment 的时候,会发现为 了刷新第94天的数据,不得不将1~93的数据一并重新计算,这对于刷新来说是一种极大的浪费。 而且最差的情况就是即使使用之前所介绍的自动合并的功能,类似的问题也仍然存在。
六、Kylin资源调节和优化
- 资源调优
由于kylin是基于第三组件的工具,它在计算和保存数据时都是在第三方大数据组件中完成的,所以一般资源调优就是对HBASE有关参数进行优化
kylin.storage.hbase.table-name-prefix:默认值为 KYLIN_
kylin.storage.hbase.namespace:指定 HBase 存储默认的 namespace,默认值为default
kylin.storage.hbase.coprocessor-local-jar:指向 HBase 协处理器有关 jar 包
kylin.storage.hbase.coprocessor-mem-gb:设置 HBase 协处理器内存大小,默认值为3.0(GB)
kylin.storage.hbase.run-local-coprocessor:是否运行本地 HBase 协处理器,默认值为 FALSE
kylin.storage.hbase.coprocessor-timeout-seconds:设置超时时间,默认值为 0
kylin.storage.hbase.region-cut-gb:单个 Region 的大小,默认值为 5.0
kylin.storage.hbase.min-region-count:指定最小 Region 个数,默认值为 1
kylin.storage.hbase.max-region-count:指定最大 Region 个数,默认值为 500
kylin.storage.hbase.hfile-size-gb:指定 HFile 大小,默认值为 2.0(GB)
kylin.storage.hbase.max-scan-result-bytes:指定扫描返回结果的最大值,默认值为5242880(byte),即 5(MB)
kylin.storage.hbase.compression-codec:是否压缩,默认值为 none,即不开启压缩
kylin.storage.hbase.rowkey-encoding:指定 Rowkey 的编码方式,默认值为FAST_DIFF
kylin.storage.hbase.block-size-bytes:默认值为 1048576
kylin.storage.hbase.small-family-block-size-bytes:指定 Block 大小,默认值为 65536(byte),即 64(KB)
kylin.storage.hbase.owner-tag:指定 Kylin 平台的所属人,默认值为whoami@kylin.apache.org
kylin.storage.hbase.endpoint-compress-result:是否返回压缩结果,默认值为TRUE
kylin.storage.hbase.max-hconnection-threads:指定连接线程数量的最大值,默认值为 2048
kylin.storage.hbase.core-hconnection-threads:指定核心连接线程的数量,默认值为 2048
kylin.storage.hbase.hconnection-threads-alive-seconds:指定线程存活时间,默认值为 60
kylin.storage.hbase.replication-scope:指定集群复制范围,默认值为 0
kylin.storage.hbase.scan-cache-rows:指定扫描缓存行数,默认值为 1024
- Cube设计
kylin.cube.ignore-signature-inconsistency:Cube desc中的signature信息能保
证Cube不被更改为损坏状态,默认值为 FALSE
kylin.cube.aggrgroup.max-combination:指定一个 Cube 的聚合组 Cuboid 上限,默
认值为 32768
kylin.cube.aggrgroup.is-mandatory-only-valid:是否允许 Cube 只包含 Base
Cuboid,默认值为 FALSE,当使用 Spark Cubing 时需设置为 TRUE
kylin.cube.rowkey.max-size:指定可以设置为 Rowkeys 的最大列数,默认值为 63,且
最大不能超过 63
kylin.cube.allow-appear-in-multiple-projects:是否允许一个 Cube 出现在多个项
目中
kylin.cube.gtscanrequest-serialization-level:默认值为 1
kylin.metadata.dimension-encoding-max-length:指定维度作为Rowkeys时使用
fix_length编码时的最大长度,默认值为 256
kylin.web.hide-measures: 隐藏一些可能不需要的度量,默认值是RAW
kylin.cube.size-estimate-ratio:普通的 Cube,默认值为 0.25
kylin.cube.size-estimate-memhungry-ratio:已废弃,默认值为 0.05
kylin.cube.size-estimate-countdistinct-ratio:包含精确去重度量的 Cube 大小估计,默认值为 0.5
kylin.cube.size-estimate-topn-ratio:包含 TopN 度量的 Cube 大小估计,默认值为0.5
kylin.cube.algorithm:指定 Cube 构建的算法,参数值可选 auto,layer 和 inmem,默认值为 auto
kylin.cube.algorithm.layer-or-inmem-threshold:默认值为 7
kylin.cube.algorithm.inmem-split-limit:默认值为 500
kylin.cube.algorithm.inmem-concurrent-threads:默认值为 1
kylin.job.sampling-percentage:指定数据采样百分比,默认值为 100
- Kylin优化
Aggravation Group:聚合组,将维度拆分为多个组,计算的时间以组进行计算,组内查询的效率高,组外查询低。
举例:业务场景有4个维度,分别为ABCD,如果聚合组含有的维度为ABCD的话,它的Cuboid为 2^4=16个。 但是此时如果AB是一个聚合组,CD是一个聚合组,那么Cuboid的个数就是22+22=8个, 相当于缩减了一半。即原来2(K+M+N)个Cuboid可以减少到2K+2M+2N个。
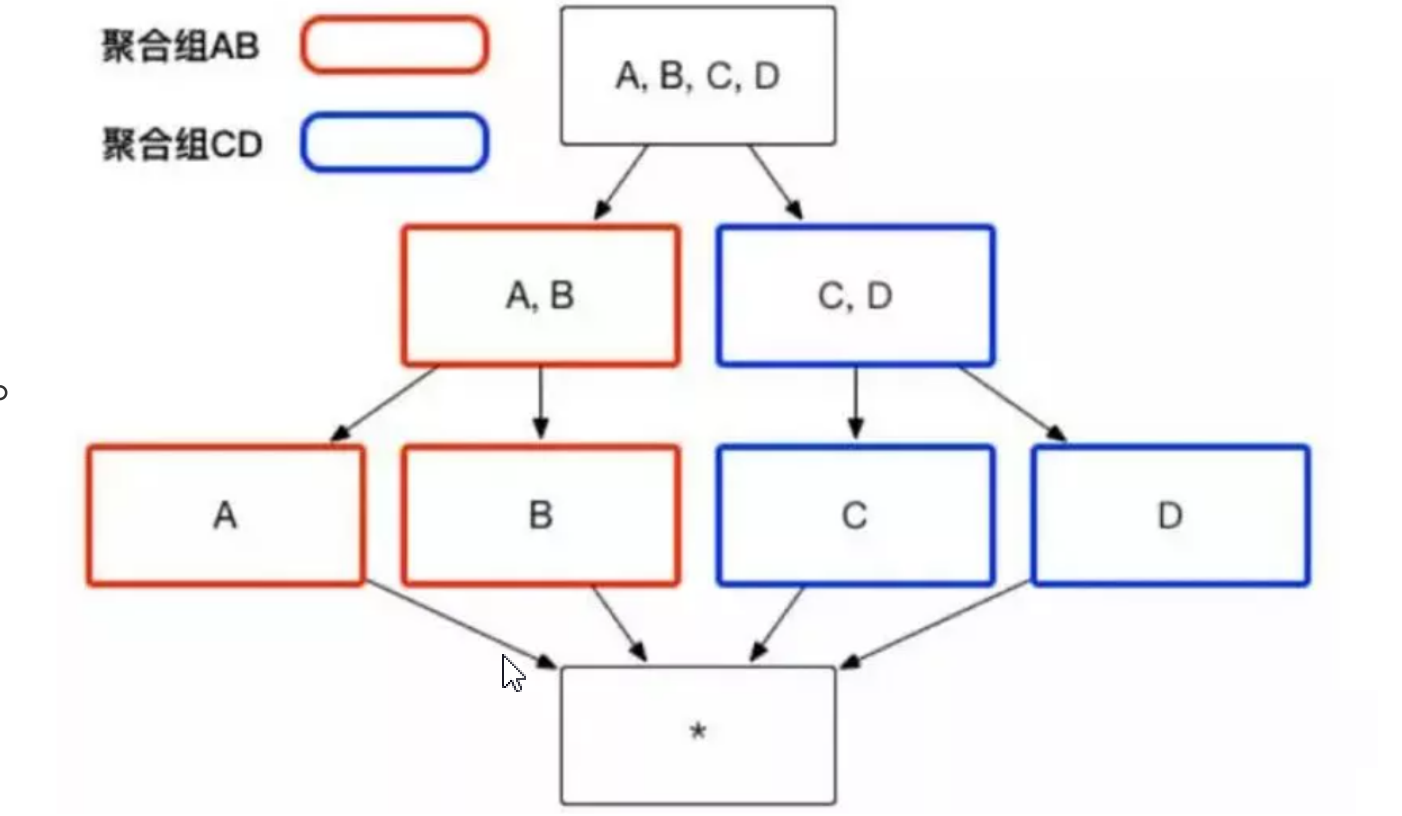
Joint Dimensions:联合维度,有些维度必须一起出现或者都不出现,他们可以组成联合维度。
例如:如有 A B C D 四个维度, B C维度作为联合维度,则最后只要生成7个维度,如下图所示:其中红色维度为无需生成的维度,黑色维度为需要生成的维度。

Hierarchy Dimensions:有些维度必须一起出现或者都不出现,他们可以组成联合维度。何为层次维度,具有上下级层次关系的维度 时间维度 年—>月—>日 地区维度 国家(country)—>省份(province)—> 城市(city)将有这样关系的维度设置为层次关系,并且将它们设置为层次维度的话,cuboid数量将下降。
向上卷:查询维度基于上一级层次维度查询下一级维度的事实表信息。
向下钻:查询维度基于下一级层次维度查询上一级维度的事实表信息。
例如:如果有三个维度A,B,C 设置为层次维度,那么Cuboid数量将由2^3减为3+1(ABC、AB、 A、空)。
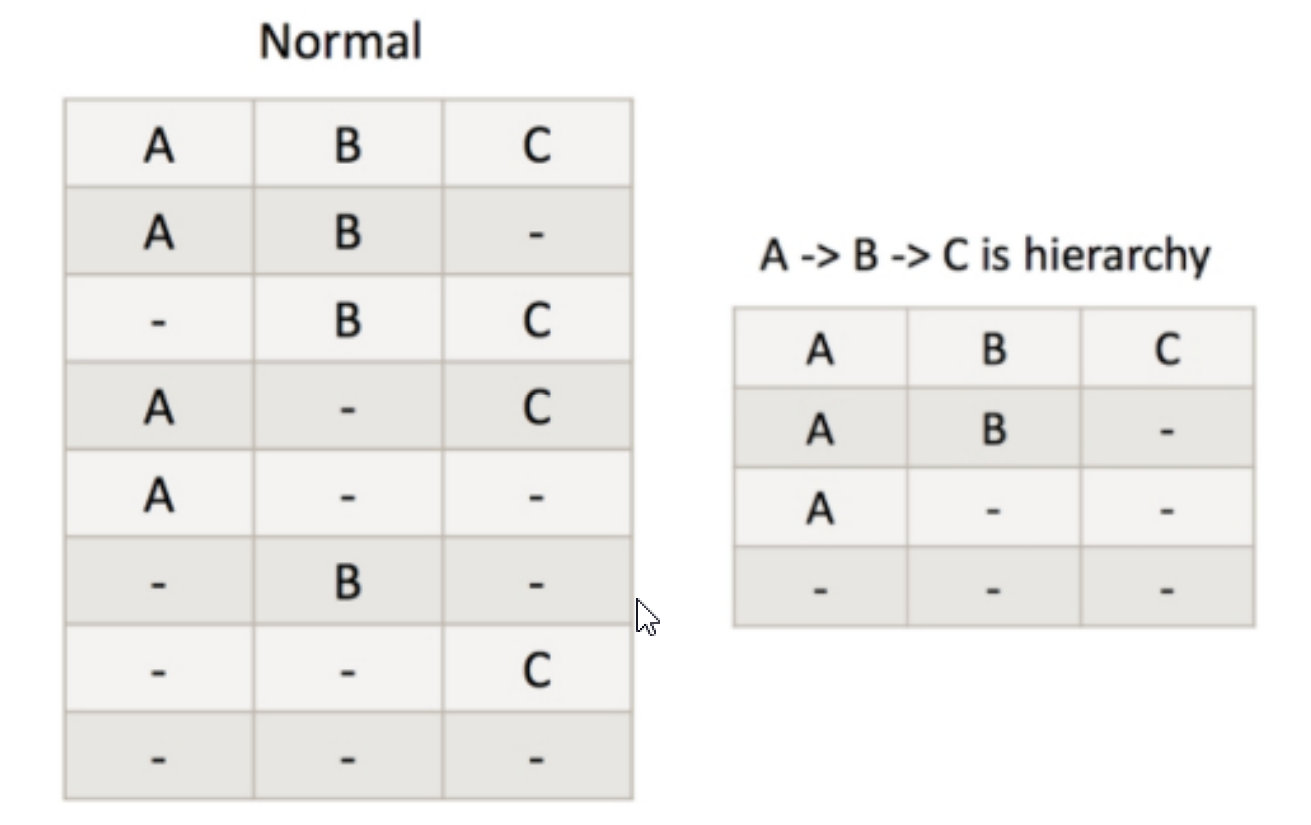
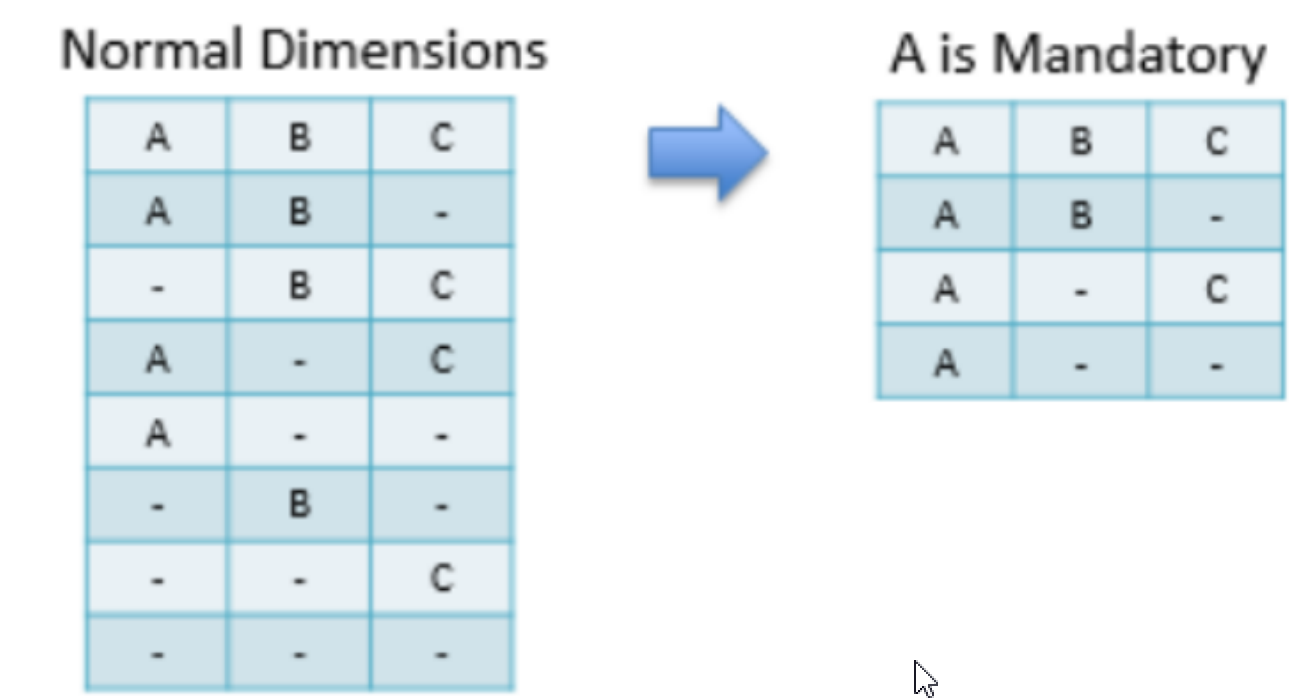
Mandatory Dimensions: 如果一个维度被定义为强制维度,那么这个分组产生的所有 Cuboid 中每一个 Cuboid 都会包含该维度。
衍生维度:计算的时候尽可能少的使用维度,维度使用的越多计算的量就越大,使用主键来代替维度表的属性。(也就是我们使用的多表查询,关联主外键进行多表查询!)
时间维度表,里面充斥着用途各异的时间维度,例如每个日期所处的季度、月份等。这些维度可以被地 用来进行各个时间粒度上的聚合分析,而不需要进行额外的上卷( Roll Up )操作。但是为了这个目的 一下子引入这么多个维度,导致 Cube 中总共的 Cuboid 数量呈现爆炸式的增长往往是得不偿失的。

Cube 的最大物理维度数量 (不包括衍生维度) 是 63,但是不推荐使用大于 30 个维度的 Cube,会引起维度灾难。
- Rowkey编码优化
编码(Encoding)代表了该维度的值应使用何种方式进行编码,合适的编码能够减少维度对空间 的占用,例如,我们可以把所有的日期都用三个字节进行编码,相比于字符串存储,或者是使用长 整数形式存储的方法,我们的编码方式能够大大减少每行Cube数据的体积。而Cube中可能存在数 以亿计的行数,使用编码节约的空间累加起来将是一个非常巨大的数字。
具体优化方案:Kylin rowkey 的编码和压缩选择、维度在 rowkey 中顺序的调整、
将过滤频率较高的列放置在过滤频率较低的列之前、
将基数高的列放置在基数低的列之前、
在查询中被用作过滤条件的维度有可能放在其他维度的前面、
充分利用过滤条件来缩小在 HBase 中扫描的范围, 从而提高查询的效率。
总之:RowKey字符大小越小越好!!!!!
七、CDH6.3.2平台介绍
试想一下,1000台服务器的集群,最少要花费多长时间来搭建好Hadoop集群,包括Hive、Hbase、Flume、Kafka、Spark等等。光从部署的角 度来看就是一个非常耗费时间的举动。
只给你一天时间,完成以上工作?
对于以上集群进行hadoop版本升级,你会选择什么升级方案,最少要花费多长时间?
升级之后的新版本的Hadoop,与Hive、Hbase、Flume、Kafka、Spark等等兼容?
原生的apache存在着如下问题:
版本管理混乱 部署过程繁琐、
升级过程复杂 兼容性差
安全性低
所以我们一般会选择发行版,平台化操作。比较常见的如下
- Cloudera’s Distribution Including Apache Hadoop(CDH)
- Hortonworks Data Platform (HDP 收费) 最为熟知的两个免费的基于Apache Hadoop社区版衍生出来的。 我们今天就给大家介绍CDH的使用。
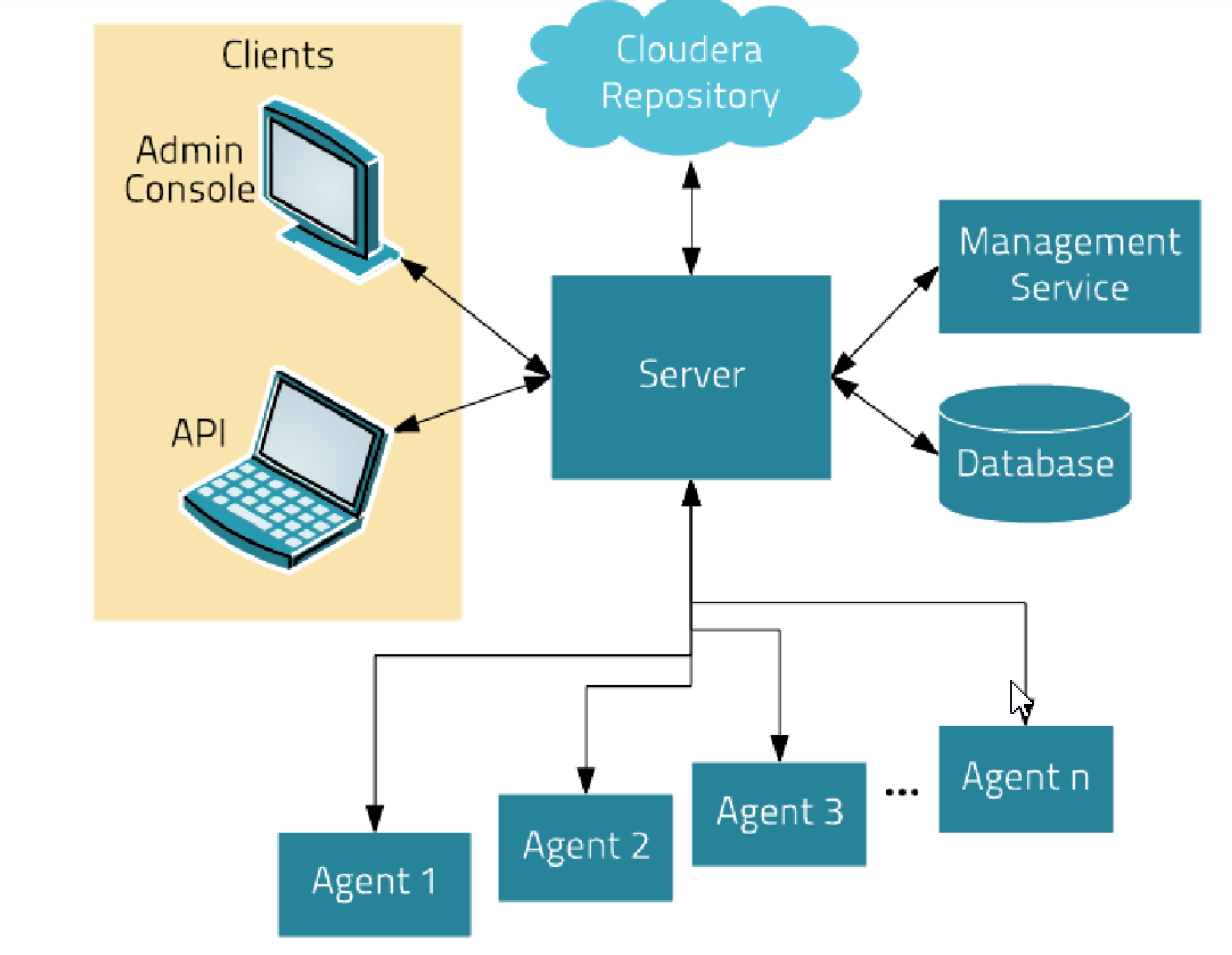
- Cloudera Manager是一个拥有集群自动化安装、中心化管理、集群监控、报警功能的一个工具,使得安装集群从几天的时间缩短在几个小时 内,运维人员从数十人降低到几人以内,极大的提高集群管理的效率。
- CDH全称Cloudera's Distribution, including Apache Hadoop(分布式云hadoop集群),是Hadoop众多分支中的一种,由Cloudera维护,基于稳定版本的Apache Hadoop 构建,提供了Hadoop的核心(可扩展存储,分布式计算),并且有非常友好的基于Web的用户界面。 整体版本划分清晰,版本更新速度快,支持Kerberos安全认证。
- 架构