前言 本文提出了DependencyViT,可以在没有任何标签的情况下诱导视觉依赖,既可用于自监督预训练范式,也可用于弱监督预训练范式。
本文转载自极市平台
作者 | Garfield
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!

原文链接:https://arxiv.org/abs/2304.03282
代码链接:https://github.com/dingmyu/DependencyViT
1. 引言
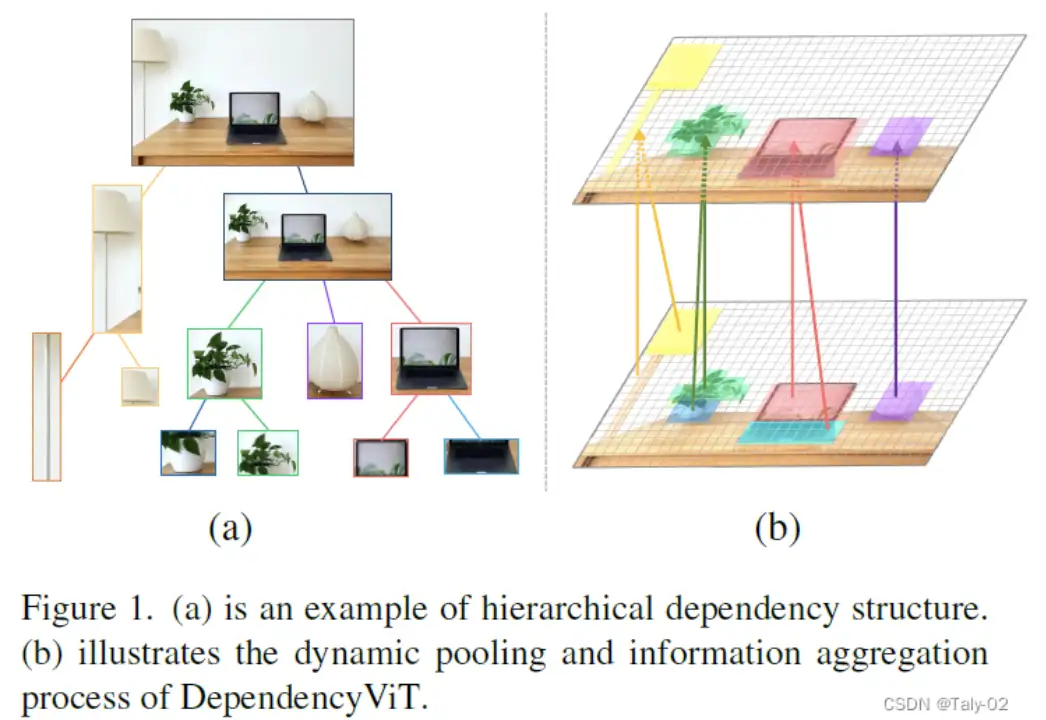
人类对我们周围的环境有丰富的心理表征。在查看图像时(见图 1(a)),我们可以识别场景,也可以快速将其分解为具有依赖性的层次元素,例如,由屏幕和键盘组成的笔记本电脑放在桌子上。这种在对象(和/或其部分)之间构建依赖关系的能力是人类智能的基石,使我们能够感知、交互和推理世界。图像依赖解析是一种任务,目的是将图像分割成区域,并根据它们的语义角色分配标签。一些经典的图像依赖解析算法的例子是:
- 基于图的方法,使用图割或归一化割来根据像素相似度将图像划分为区域。
- 基于概率的方法,使用贝叶斯网络或马尔可夫随机场来建模像素标签和图像特征的联合分布
- 基于句法的方法,使用语法或树结构来表示图像区域之间的层次关系。
同样,人机交互方法从手动标注的标签中学习两个对象之间的关系,例如,一个男孩“拿着”冰淇淋。除非提供详尽且耗时的手动注释,否则此类方法难以学习分层视觉结构,例如对象的不同部分。最近,vision-language (VL) 的方法具有归纳出hierarchical的object dependencies关系。然而,之前的工作都存在两个关键问题:1)解析严重依赖于自然语言或人类注释的监督而不是图像本身;2)它们的解析结构是基于预训练对象检测模型的对象级别,如 Faster/Mask-RCNN ,阻碍了它们在部分级和非检测器场景中的通用性。
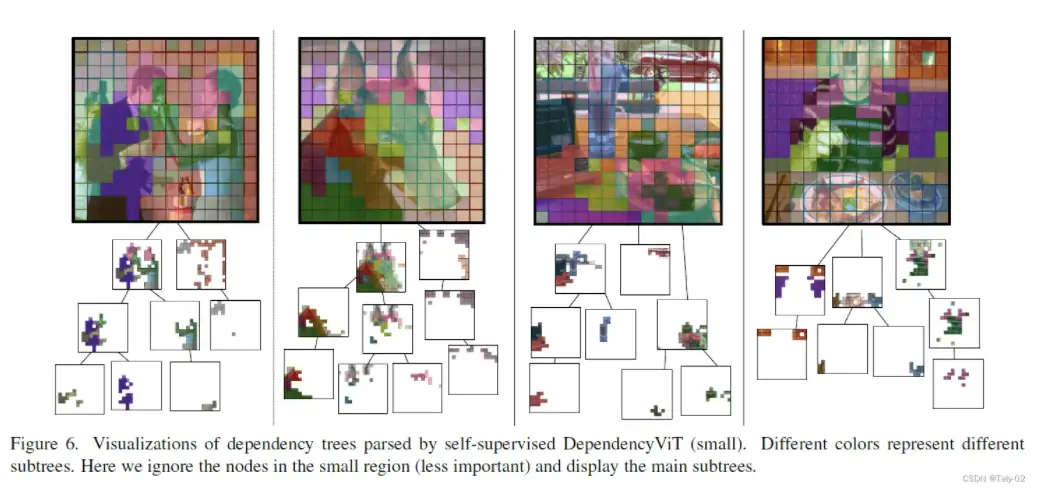
本文回答了上述问题自然提出的一个问题:我们能否有效地获取object dependencies吗?目前,可视化解析的工作主要集中在语义分割和实例分割两方面。与基于检测器的工作依赖于预先训练的检测器不同,它们在像素级上解析图像,这是资源密集型和昂贵的。受视觉变形器[26]的启发,它将图像补丁作为输入,并利用自我注意来执行tokens之间的交互,作者提出在tokens级别上构建一个描述依赖性的tree。将补丁作为基本元素并基于它们构建树结构有两个好处:1)它统一了部分级和对象级的依赖关系,所有这些依赖关系都被表述为子树;2)在dependencies结构中,信息可以从叶子聚合到父结点(如图所示),从而产生路径上不同部分和对象的表示层次结构。
本文提出的主要方法称为DependencyViT(DependencyVit),它是计算机视觉任务的backbone模型。它基于反向的自我注意力,可以从自我监督或弱监督信号中自动捕获图像补丁之间的依赖关系。该模型使用了一种名为反向注意力的新型神经运算符,它可以自然捕获图像斑块之间的长期视觉依赖关系。该模型被制定为依赖关系图,其中注意力反向的子tokens经过训练,使其关注其父tokens并按照标准化概率分布发送信息。通过这种设计,等级自然会从反向的attention层中浮现出来,dependencies tree是在不受监督的情况下逐步从叶子节点诱导到根节点。该模型具有多种优点,包括能够通过不同的子树在图像中表示实体及其部分、动态视觉池以及在各种计算机视觉任务中表现出色。
2. 方法
2.1 Reversed Attention
在计算机视觉领域中,注意力机制是一种用于提高模型性能的技术,它通过加权关注输入图像中的不同部分,从而使模型能够更好地处理复杂的视觉任务。具体来说,计算机视觉中的注意力机制可以分为两种类型:空间注意力机制和通道注意力机制。空间注意力机制是一种用于关注图像中不同位置的机制。它通过对每个像素点进行加权,将模型的注意力集中在最重要的像素上,从而提高模型的性能。常用的空间注意力机制包括SENet、CBAM等。通道注意力机制是一种用于关注图像中不同通道的机制。它通过对每个通道进行加权,将模型的注意力集中在最重要的通道上,从而提高模型的性能。常用的通道注意力机制包括Squeeze-and-Excitation模块、SKNet等。此外,注意力机制也可以与卷积神经网络中的不同层级结合使用,从而提高模型的性能。例如,在多尺度图像分割任务中,可以使用注意力机制来关注不同尺度下的特征图,以提高模型在不同尺度下的表现。
2.2 Dependency Block
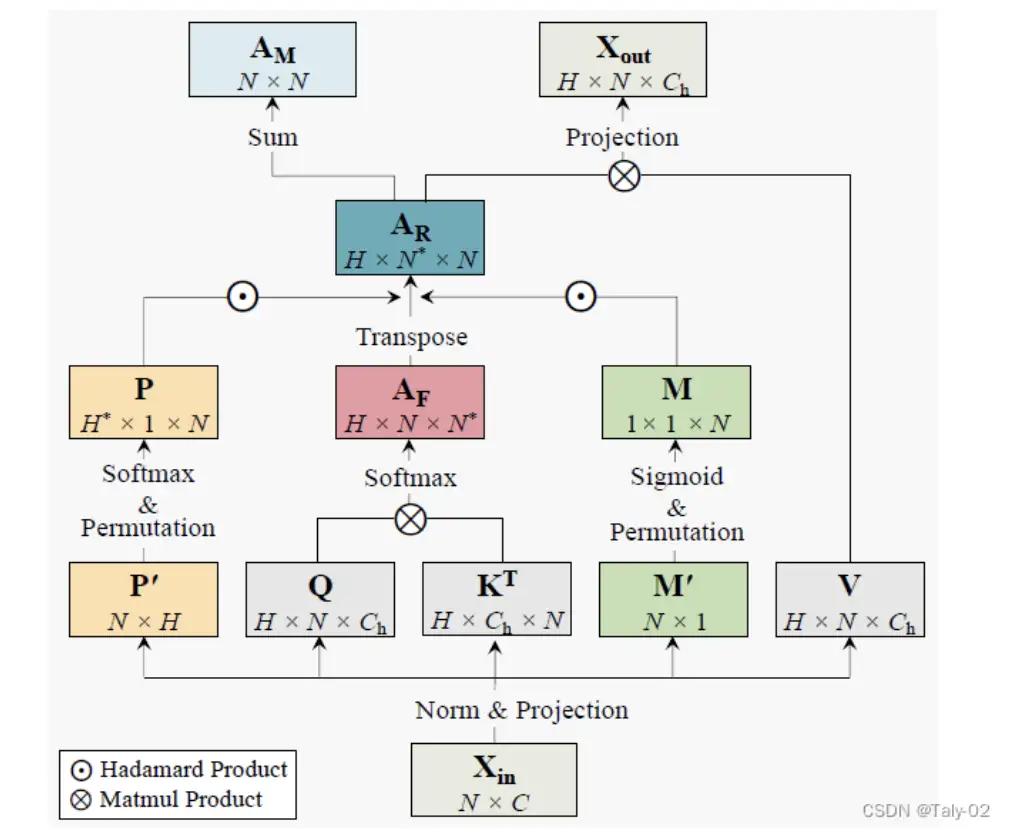
简单地应用转置注意力矩阵并不能保证诱导出良好的依赖图。这是因为:(i)一个token可以关注的令牌数量是由多个注意力头控制的,因此依赖图不是唯一的。(ii) 不同子树的贡献没有很好地区分。在图像分类等一些下游任务中,前景树和背景树应该是不同的。为了解决以上问题:我们进一步引入两个模块:head selector和message controller。
head selector的 反向注意力层是一种新颖的神经运算符,可以捕获图像补丁之间的长期视觉依赖关系。它被制定为依赖关系图,在该图中,子token被训练为关注其父token并按照标准化概率分布发送信息。这与传统的自我注意力形成鲜明对比,在传统的自我注意力中,代币从其他token那里收集信息。通过这种设计,等级自然会从反向的注意力层中浮现出来,依赖树是在不受监督的情况下逐步从叶子节点诱导到根节点。MLP 层是标准的前馈神经网络,用于处理反向注意力层的输出。它对输入要素进行非线性变换,并将它们映射到更高维度的空间。这有助于捕获输入要素之间更复杂的关系。依赖块的功能是捕获图像补丁之间的视觉依赖关系,从叶子节点诱发依赖树到根节点,并将输入特征映射到高维空间以捕获更复杂的关系。
2.3 Dynamic Pooling based on Dependencies
我们的Dependency Block能够学习token之间的动态和综合信息流以进行依赖归纳。直观地说,有了这种视觉依赖性,场景理解就可以用更少的计算量来简化,因为大部分信息都可以由几个节点表示。受此启发,作者引入了一种Dynamic Pooling方案,大大降低了计算成本(即 FLOPs 和 GPU 内存),并提出了一种轻量级模型 DependencyViT-Lite。dependencyvit-Lite 通过记录被修剪的节点与其父节点之间的关系来修剪收到的信息最少的叶子节点,以减少内存和资源成本,同时通过从其父节点处进行聚合来检索被修剪的节点,使其即使在移除token的情况下也能执行密集的预测任务。
3. 实验

本文使用 ImageNet 数据集对模型进行预训练,并使用不同的数据集(包括 PASCAL VOC、COCO 和 ADE20K)评估其在各种计算机视觉任务中的性能。
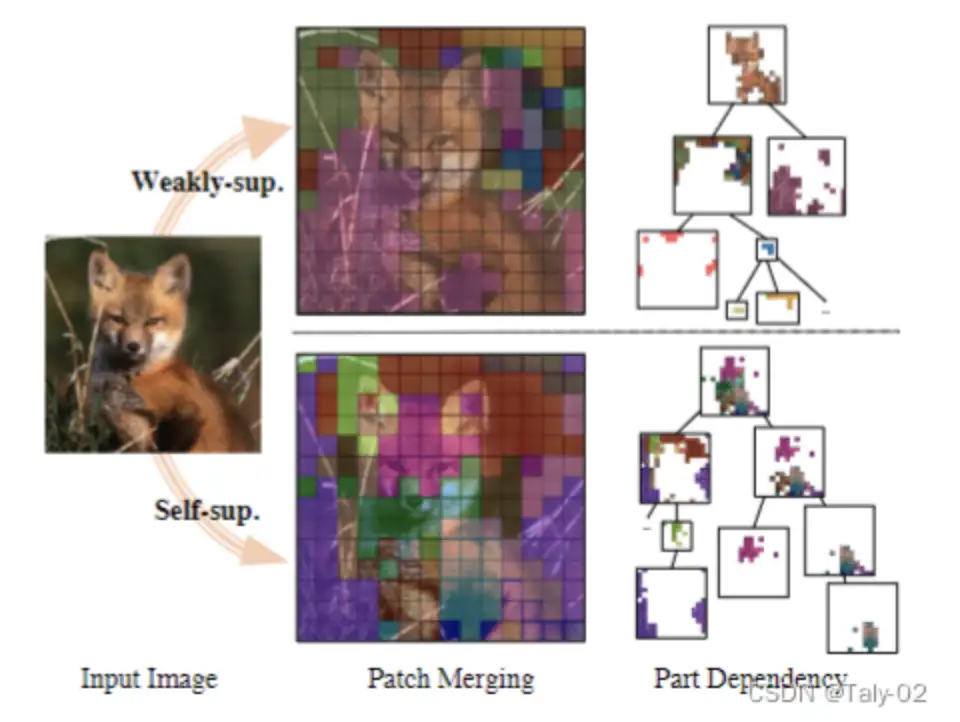
Unsupervised Part Segmentation
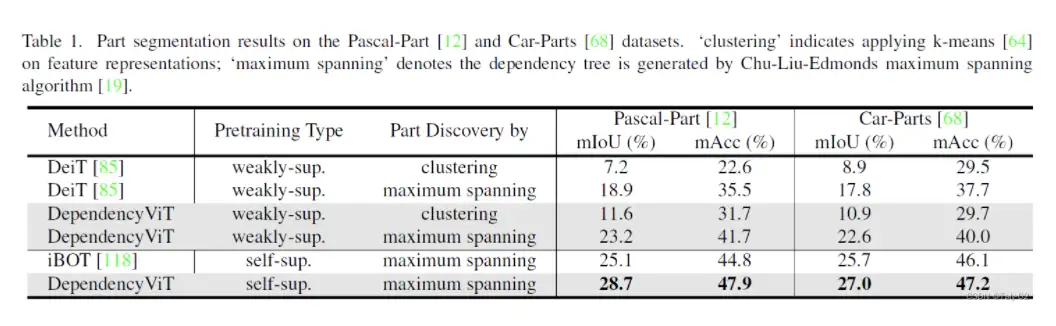
有以下几个结论:
- DependencyVit 对视觉依赖关系解析非常有效,如无监督部分分段任务所示。
- 在弱监督模型和自监督模型中,DependencyVit 的表现都优于基准方法。
Unsupervised Saliency Detection
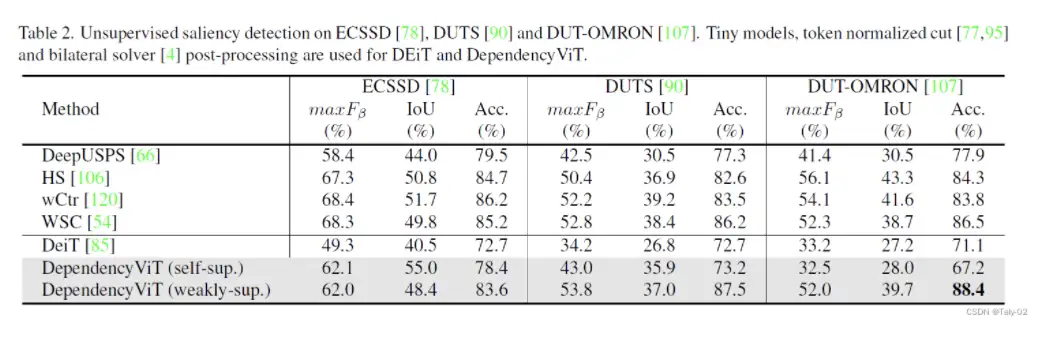
有以下几个结论:
- 由于其内置的分层依赖关系,DependencyVit 可以进行对象级理解,与其他方法相比,可以实现卓越的无监督显著性检测。
- 在特征表示中添加软依赖掩码可显著提高DependencyVit在学习对象级理解方面的性能。
Visual Recognition
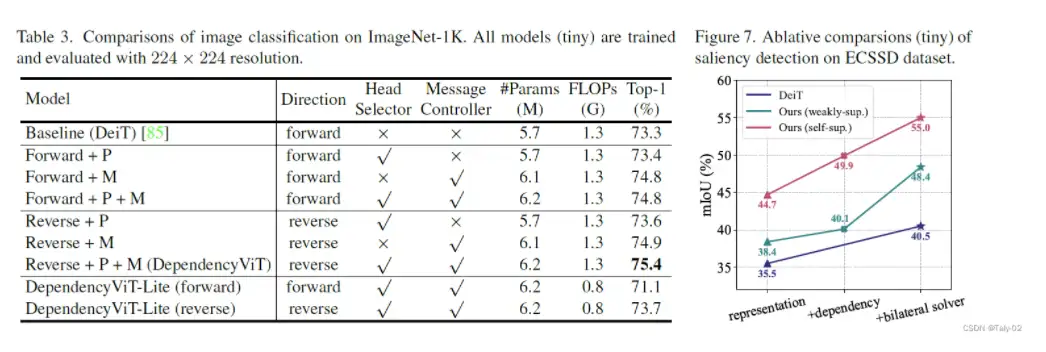
DependencyVit在视觉识别任务中的表现优于所有baseline,而DependencyVit-Lite是最高效的模型,性能良好,证明了渐进式动态池的有效性。
4. 讨论
本文的实际含义在于,它提出了一种用于计算机视觉任务的新模型,该模型可以捕获图像补丁之间的视觉依赖关系,并在无人监督的情况下诱发依赖树。该模型具有多种优点,包括能够通过不同的子树在图像中表示实体及其部分、动态视觉池以及在各种计算机视觉任务中表现出色。该模型既可用于自监督预训练范式,也可用于弱监督预训练范式,并且可以应用于各种计算机视觉任务,例如无监督部分和显著性分割、识别和检测。拟议的模型有可能提高自动驾驶、机器人和监控等各种应用中计算机视觉系统的准确性和效率。
本文的一个局限性是,所提出的模型在非常大的数据集或更复杂的场景上可能表现不佳。此外,尽管该模型在各种计算机视觉任务上具有良好的性能,但它可能不是所有任务和场景的最佳选择。最后,本文没有对模型的计算和内存要求进行详细分析,这可能是某些应用论文关注的问题。
该论文同时提出了未来工作的几个方向,包括探索使用DependencyVit进行其他计算机视觉任务,例如视频分析和三维场景理解。作者还建议研究不同类型视觉特征的使用,并将其他信息(例如对象属性和关系)纳入模型中。最后,作者建议将该模型与其他技术(例如图神经网络和强化学习)结合使用。
5. 结论
该论文提出了一种名为DependencyVit的新模型,用于计算机视觉任务。该模型使用一种名为反向注意力的新型神经运算符来捕获图像tokens之间的视觉依赖关系,并在无监督的情况下诱导出从叶子节点到根节点的依赖树。该模型具有多种优点,包括能够通过不同的子树在图像中表示实体及其部分、Dynamic Pooling以及在各种计算机视觉任务中表现出色。该论文得出的结论是,DependencyVit是用于计算机视觉任务的有效而高效的模型,可用于自监督和弱监督预训练的范式。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
一次性分割一切,比SAM更强,华人团队的通用分割模型SEEM来了
CVPR'23|向CLIP学习预训练跨模态!简单高效的零样本参考图像分割方法
CVPR23 Highlight|拥有top-down attention能力的vision transformer
【CV技术指南】咱们自己的CV全栈指导班、基础入门班、论文指导班 全面上线!!
CVPR 2023|21 篇数据集工作汇总(附打包下载链接)
CVPR 2023|两行代码高效缓解视觉Transformer过拟合,美图&国科大联合提出正则化方法DropKey
ViT-Adapter:用于密集预测任务的视觉 Transformer Adapter
CodeGeeX 130亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
CVPR 2023 深挖无标签数据价值!SOLIDER:用于以人为中心的视觉
上线一天,4k star | Facebook:Segment Anything