字符编码
一、什么是字符编码?
- 人类在与计算机交互时,用的都是人类能读懂的字符,如中文字符、英文字符、日文字符等
- 计算机却只能读懂二级制的字符,我们就需要将这些字符翻译成计算机能读懂的,而翻译的过程
- 须参照一个特定的标准,这样的对应关系的表,我们就称之为字符编码表,字符编码就是翻译的过程
二、字符编码的发展
[1]一家独大(ASCII)
(1)ASCII表的诞生
- 现代计算机起源于美国,所以最先考虑仅仅是让计算机识别英文字符,于是诞生了ASCII表
(2)ASCII表的特点
- 只有英文字符与数字的一一对应关系
- 一个英文字符对应1Bytes,1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符
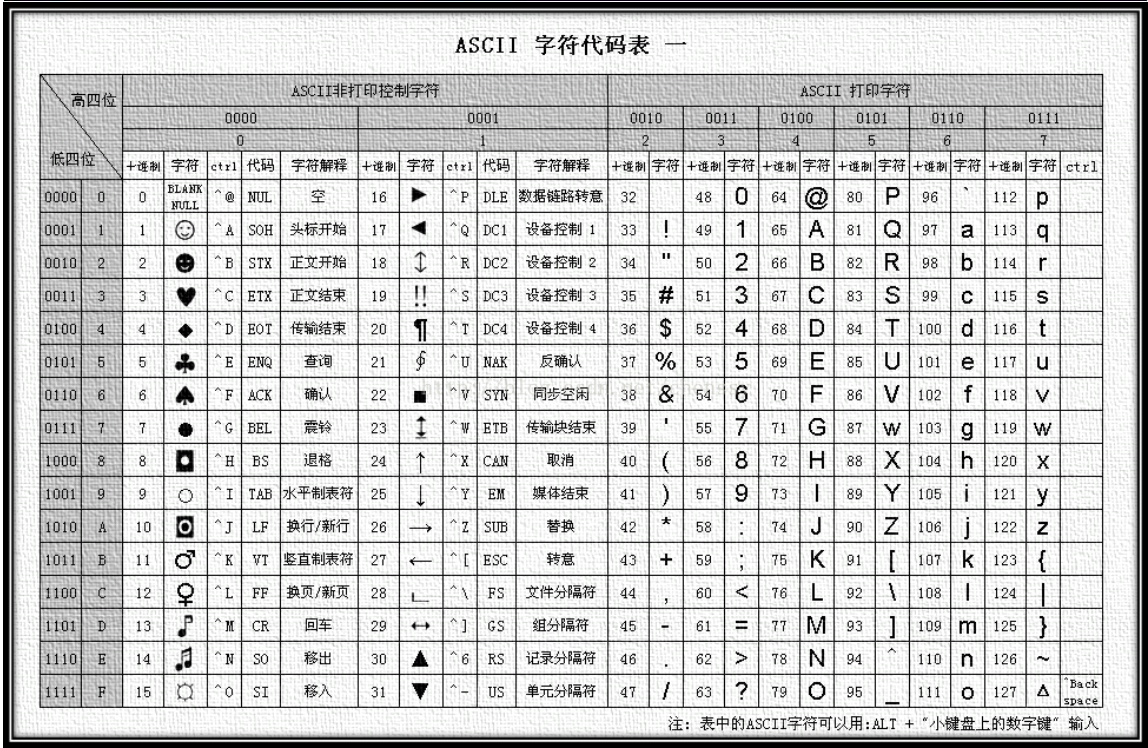
(3)字母对照ASCII表
[2]诸侯割据(ASCII/GBK/Shift_JIS)
- 为了让计算机能够识别中文和英文,中国人定制了
GBK
(1)GBK表的特点
-
只有中文字符、英文字符和数字的对应关系
-
一个英文字符对应1Bytes 一个中文字符对应2Bytes
- 1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符
- 2Bytes=16bit,16bit最多包含65536个数字,可以对应65536个字符,足够表示所有中文字符
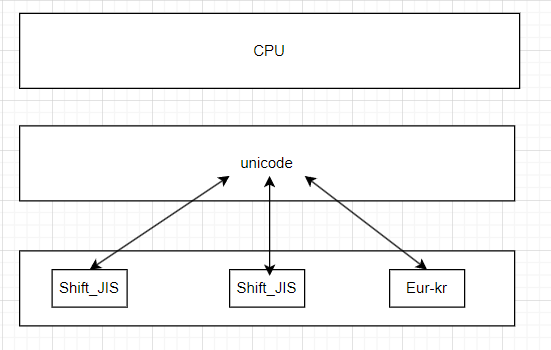
(2)各国不同的编码表
- 日文字符、英语字符和数字的对应关系的
Shifi_JIS表 - 韩文字符、英文字符和数字的对应关系的
Euc-kr表
(3)各国编码表的共存特点
- 一、一对应,使用时准确快捷,,不会出现乱码问题。
- 问题是,不同国家的计算机只有各自的编码对照,无法互通。
- 我们希望不管输入哪个国家的字符计算机的都能够识别,这样就需要定制一个万国字符的编码表
[3]一统天下
- unicode于1990年开始研发,1994年正式公布
(1)unicode的特点
- 存在所有语言的所有字符与数字的对应关系,万国编码表
- 与传统的字符编码表都有对应关系。
- 由于某些地区或者某些老系统仍会沿用之前各地的传统编码表,unicode编码表需要和这些表有着对应。
(2)字符的存储
- 文本编辑器输入任何字符都是最新存在于内存中,是unicode编码的
- 存放于硬盘中,则可以转换成任意其他编码,只要该编码可以支持相应的字符
三、编码与解码
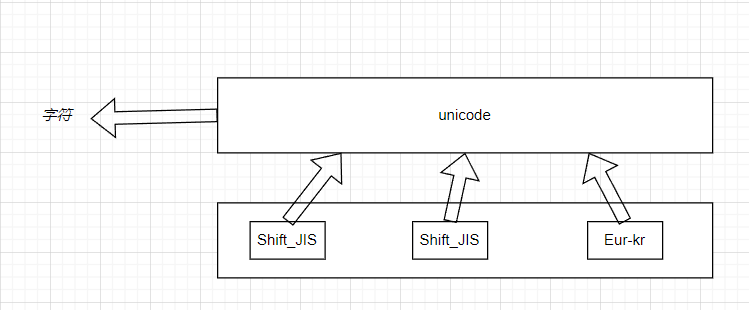
[1]编码
-
由字符转换成内存中的unicode,以及由unicode转换成其他编码的过程,都称为编码encode
# 编码 name = "桃源氏" print(name.encode('utf-8')) # b'\xe6\xa1\x83\xe6\xba\x90\xe6\xb0\x8f' print(name.encode('gbk')) # b'\xcc\xd2\xd4\xb4\xca\xcf'
[2]解码
- 由内存中的unicode转换成字符,以及由其他编码转换成unicode的过程,都称为解码decode
- 在诸多文件类型中,只有文本文件的内存是由字符组成的,因而文本文件的存取也涉及到字符编码的问题
# 解码
code_1 = b'\xe6\xa1\x83\xe6\xba\x90\xe6\xb0\x8f'
print(code_1.decode('utf-8'))
code_2 = b'\xcc\xd2\xd4\xb4\xca\xcf'
print(code_2.decode('gbk'))
四、utf-8的诞生
[1]为什么会出现utf-8
- 理论上是可以将内存中unicode格式的二进制直接存放于硬盘中的
- 但由于unicode固定使用两个字节来存储一个字符
- 如果多国字符中包含大量的英文字符时,使用unicode格式存放会额外占用一倍空间(英文字符其实只需要用一个字节存放即可)
- 然而空间占用并不是最致命的问题
- 最致命地是当我们由内存写入硬盘时会额外耗费一倍的时间
- 所以将内存中的unicode二进制写入硬盘或者基于网络传输时必须将其转换成一种精简的格式
- 这种格式即utf-8(全称Unicode Transformation Format,即unicode的转换格式)
- 我们日常使用的字符编码都是utf8编码,但是,utf系列还有utf16 utf32... utf8mb4
- utf8只能存储正常的字符,utf8mb4可以存储表情
- 多国字符—√—>内存(unicode格式的二进制)——√—>硬盘(utf-8格式的二进制)
[2]为什么不直接使用utf-8
- 历史遗留问题
- 许多老的机器和硬盘里都还使用着Unicode的编码文件。
- 要等个几十年后,老编码的文件都淘汰掉之后,所有的硬盘和内存都是用utf-8,Unicode便真正退出了舞台
五、字符编码的应用
- 为了解决乱码问题,乱码问题无非两种,读乱了和存乱了。
[1]问题
(1)存乱了
- 如果用户输入的内容中包含中文和日文字符,如果单纯以shift_JIS存,日文可以正常写入硬盘,而由于中文字符在shift_jis中没有找到对应关系而导致存乱了
(2)读乱了
- 如果硬盘中的数据是shift_JIS格式存储的,采GBK格式读入内存就读乱了
[2]解决方法
- 保证存的时候不乱
- 在由内存写入硬盘时,必须将编码格式设置为支持所输入字符的编码格式
- 保证存的时候不乱
- 在由硬盘读入内存时,必须采用与写入硬盘时相同的编码格式