1 引入mmap
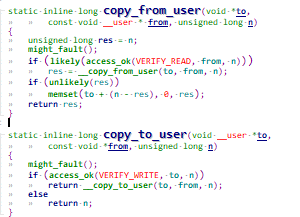
应用程序和驱动程序之间传递数据时,可以通过 read、write 函数进行, 用户态和内核态的数据交互一般用copy_from_user,copy_to_user。这种方式在数据量比较小时没什么问题;但是数据量比较大时效率就太低了。比如更新 LCD 显示时,如果每次都让 APP 传递一帧数据给内核,假设 LCD 采用1024x600x32 bpp 的格式,一帧数据就有1024x600x32/8=2.3MB 左右,而且一般为了显示动态画面,LDC输出fps要求是60fps or 30 fps,那么一秒数据量为30x2.3 = 70M左右,显然copy_from_user,copy_to_user的方式不再适合。
改进的方法就是让程序可以直接读写驱动程序中的 buffer,这可以通过mmap 实现(memory map),把内核的 buffer 映射到用户态,让 APP 在用户态直接读写。

1.1 内存映射现象
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int a;
int main(int argc, char **argv)
{
if (argc != 2) {
printf("Usage: %s <number>\n", argv[0]);
return -1;
}
a = strtol(argv[1], NULL, 0);
printf("a's address = 0x%lx, a's value = %d\n", &a, a);
while (1) {
sleep(10);
}
return 0;
}
在 PC 上如下编译(必须静态编译):
gcc -o test test.c -staitc
分别后台执行 test 程序 2 次。最后执行 ps,可以看到这 2 个程序同时存在,这 2 个程序里 a 变量的地址相同,但是值不同。

2 个程序同时运行,它们的变量a的地址都是一样的:0x6bc3a0;
2 个程序同时运行,它们的变量a的值是不一样的,一个是 111,另一个是 123。
来分析一下:
2个程序同时在内存中运行,它们的值不一样,所以变量 a 的物理内存地址肯定不同(2个变量存放不是同一个地方);
但是打印出来的变量 a 的地址却是一样的。怎么回事?
这里要引入虚拟地址的概念:CPU 发出的地址是虚拟地址,它经过MMU(Memory Manage Unit,内存管理单元)映射到物理地址上,对于不同进程的同一个虚拟地址,MMU 会把它们映射到不同的物理地址。
总结:虽然虚拟地址一样,但物理地址不一样,这个是mmu的功劳,将同一虚拟地址映射到不同物理地址。
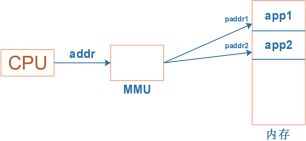
当前运行的是 app1 时,MMU 会把 CPU 发出的虚拟地址 addr 映射为物理地址paddr1,用 paddr1 去访问内存。
当前运行的是 app2 时,MMU 会把 CPU 发出的虚拟地址 addr 映射为物理地址paddr2,用 paddr2 去访问内存。
MMU 负责把虚拟地址映射为物理地址,虚拟地址映射到哪个物理地址去?可以执行 ps 命令查看进程 ID,然后执行“cat /proc/[PID]/maps”得到虚拟地址空间映射关系。

00400000-004b6000 r-xp 00000000 08:04 2228541 /home/book/ftp/a.out
006b6000-006bc000 rw-p 000b6000 08:04 2228541 /home/book/ftp/a.out
006bc000-006bd000 rw-p 00000000 00:00 0
021c8000-021eb000 rw-p 00000000 00:00 0 [heap]
7ffe18738000-7ffe18759000 rw-p 00000000 00:00 0 [stack]
7ffe187f9000-7ffe187fc000 r--p 00000000 00:00 0 [vvar]
7ffe187fc000-7ffe187fd000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 --xp 00000000 00:00 0 [vsyscall]
第一行地址范围显示权限为可读可执行,表示该程序代码段(.text)
第二行地址范围显示权限为可读可写, 表示该程序的数据段(.data)
第三行地址范围显示权限为可读可写, 表示该程序的数据段(.data)刚才变量a地址就在这段地址范围内
第四行地址范围是堆空间(.heap段),malloc的内存就会处于这段
第5行地址范围是栈空间(.stack段),局部变量处于这段
p表示private, s表示share, 再来看一个使用动态库的进程,比如bash

2 mmap内核态的描述
每一个 APP对应了很多虚拟地址空间,比如栈空间,堆空间,数据段,代码段等等。
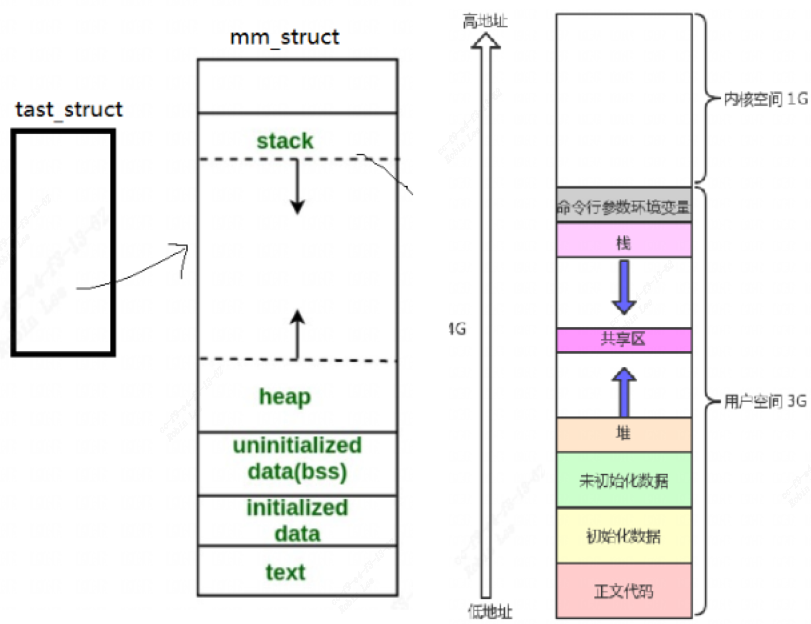
因此在内核里都有一个 tast_struct,这个结构体中保存有内存信息:mm_struct。而虚拟地址、物理地址的映射关系保存在页目录表中:
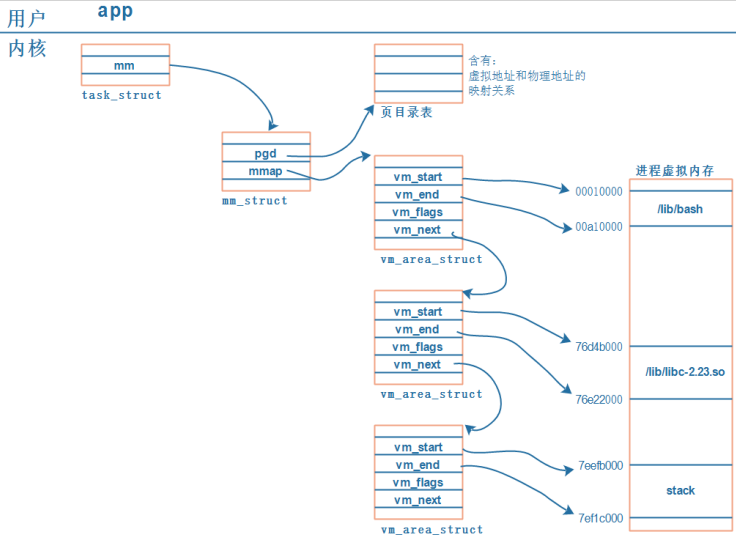
1. 每个 APP 在内核中都有一个 task_struct 结构体,它用来描述一个进程;
2. 每个 APP 都要占据内存,在 task_struct 中用 mm_struct 来管理进程占用的内存;
3. 内存有虚拟地址、物理地址,mm_struct 中用 mmap 来描述虚拟地址,用 pgd 来描述对应的物理地址。(注意:pgd,Page Global Directory,页目录)
4. 每个 APP 都有一系列的 VMA:virtual memory,即mmap会指向vm_area_struct, 比如 APP 含有代码段、数据段、BSS 段、栈等等,还有共享库。这些单元会保存在内存里,它们的地址空间不同,权限不同(代码段是只读的可运行的、数据段可读可写),内核用一系列的 vm_area_struct 来描述它们。
6. vm_area_struct 中的 vm_start、vm_end 是虚拟地址。
7. vm_area_struct 中虚拟地址如何映射到物理地址去? 每一个 APP 的虚拟地址可能相同,物理地址不相同,这些对应关系保存在 pgd 中。
3 页表映射
页表是存在ddr中的一段连续地址空间,页表里面存放了要映射的物理地址集合,页表分为很多个页表项。
ARM 架构支持一级页表映射,也就是说 MMU 根据 CPU 发来的虚拟地址可以找到第 1 个页表,从第 1 个页表里就可以知道这个虚拟地址对应的物理地址。一级页表里地址映射的最小单位是 1M。
ARM 架构还支持二级页表映射,也就是说 MMU 根据 CPU 发来的虚拟地址先找到第 1 个页表,从第 1 个页表里就可以知道第 2 级页表在哪里;再取出第 2 级页表,从第 2 个页表里才能确定这个虚拟地址对应的物理地址。二级页表地址映射的最小单位有 4K、1K,Linux 使用 4K。
一级页表项里的内容,决定了它是指向一块物理内存,还是指问二级页表,一个页表项格式如下图:
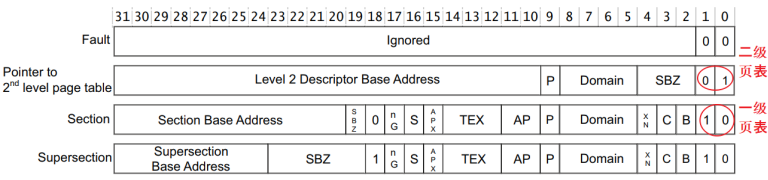
3.1 一级页表映射
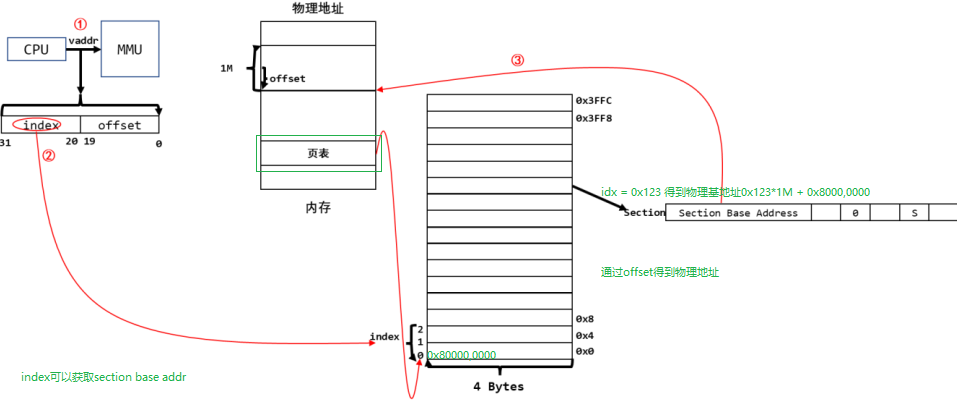
arm32系统中,一个页表项占4个byte, 32bit,它分为一级页表项和二级页表项,通过bit[1:0]区分,一级页表项保存有物理地址,用bit[31:20] 共12位表示段基地址,有1M物理内存。比如cpu发出虚拟地址0x12345678, MMU通过bit[31:20]发现为0x123,也就是从第0x123个页表项中找到Section Base Address, 比如第0个页表项中物理及地址为0x8000,0000, 那么第0x123个页表项目物理基地址就是0x123 * 1M + 0x8000,0000,也就是0x9230,0000, 因为每一个一级页表项物理内存大小为1M.
段内偏移是 0x45678,那么最终通过一级页表映射最终映射到物理地址就为0x0x9230,0000 + 0x45678,也就是0x9234,5678。
Section Base Address的数量为多少呢?一共12bit,也就是4096个,每一个1级页表项大小为1M, 因此总共可表示4G。对于 32 位的系统,虚拟地址空间有 4G,4G/1M=4096。所以一级页表要映射整个 4G 空间的话,刚好需要 4096 个页表项。
所以 CPU 要访问虚拟地址 0x12345678 时,实际上访问的是 0x81045678 的物理地址。
3.2 二级页表映射
一级页表项每项有1M空间, 一级页表映射时是吧虚拟地址的1M映射到物理地址的1M连续空间,但有时我们的程序没有那么大,显然用1M太浪费空间。 那么引入二级页表映射来映射更小的块,对于二级页表,每一块可以是1K, 4K,64K, Linux系统一般使用4K, 对应Small Page, 64K对应的是大页(Large Page), 1K对应的是Tine Page(一般很少用)。
二级页表映射过程:
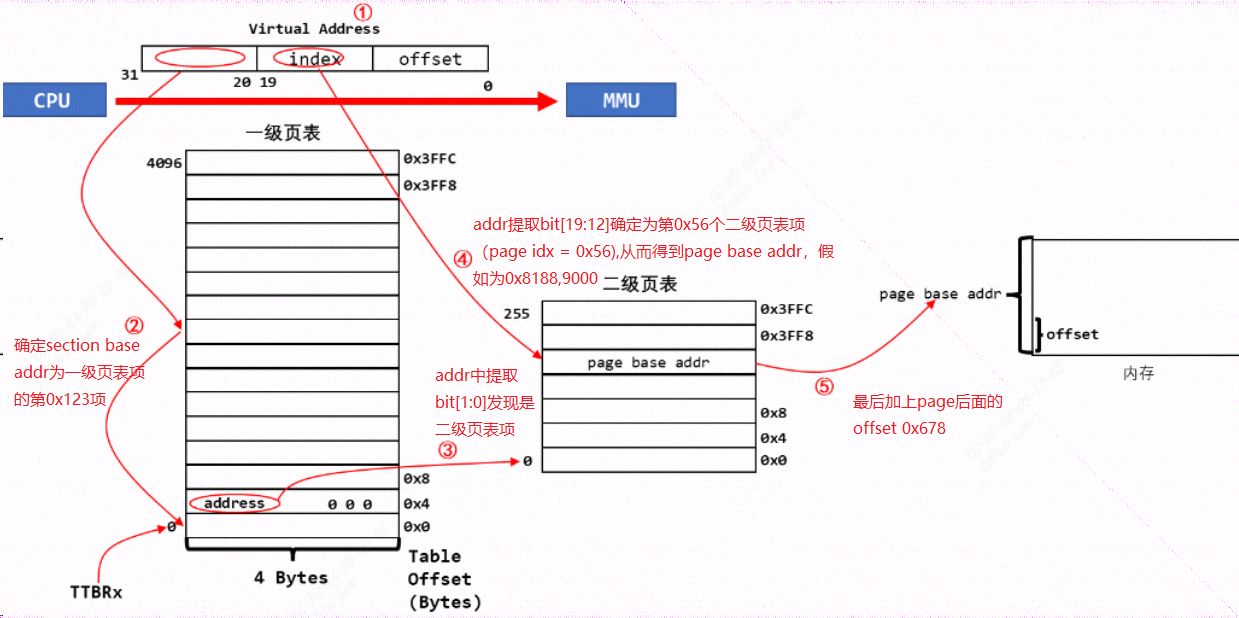
首先设置好一级页表、二级页表,并且把一级页表的首地址告诉 MMU,比如0x8000,0000。
二级页表首先也是要经过一级页表映射,用bit[31:20] 共12位表示段基地址,找到对应的一级页表项比如0x123项,通过这一项里面的bit[1:0]发现它是一个二级页表项(注意不再是取出1M的物理地址),然后根据二级页表项的bit[19:12]这8位得到二级页表是得到索引0x45,表示为第0x45个二级页表项。从这个二级页表项中取出里面的物理地址,比如为addr。
二级页表格式如下:
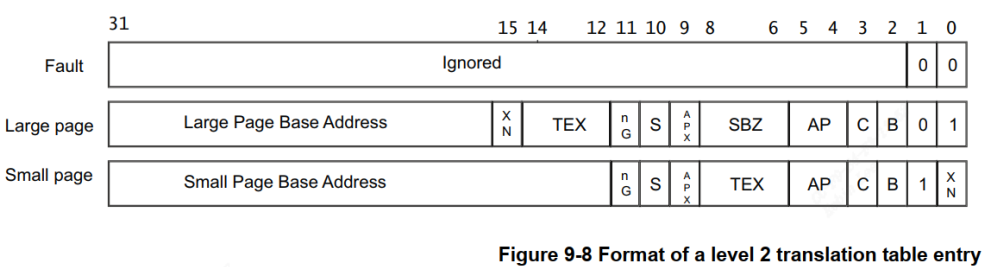
可以看到里面含有64k(Large Page) 4k(Small Page)或 1K(Tine) 物理空间的基地址 page base addr,假设从第0x45个二级页表项取出的物理地址为0x8188,9000。然后offset=0x678, 那么它跟 vaddr[11:0] 组 合 得 到 物 理 地 址 : 0x8188,9000 + 0x678 = 0x8188,9678,所以 CPU 要访问虚拟地址 0x1234,5678 时,实际上访问的是 0x8188,9678 的物理地址, 根据bit[1:0]得到映射的大小为4K(linux Small Page)。假如这里不使用二级页表映射,理论去计算对应物理地址则会是0x8180,0000往后1M内存,显然浪费了。
4 mmap函数调用过程
从上面内存映射的过程可以知道,要给 APP 新开劈一块虚拟内存,并且让它指向某块内核buffer,我们要做这些事:
- 得到一个 vm_area_struct,它表示 APP 的一块虚拟内存空间:
很 幸 运 , APP 调 用 mmap 系 统 函 数 时 , 内 核 就 帮 我 们 构 造 了 一 个vm_area_stuct 结构体。里面含有虚拟地址的地址范围、权限,属性。 - 确定物理地址:
你想映射某个内核 buffer,你需要得到它的物理地址,这得由你提供。 - 给 vm_area_struct 和物理地址建立映射关系
APP 里调用 mmap 时,导致的内核相关函数调用过程如下:
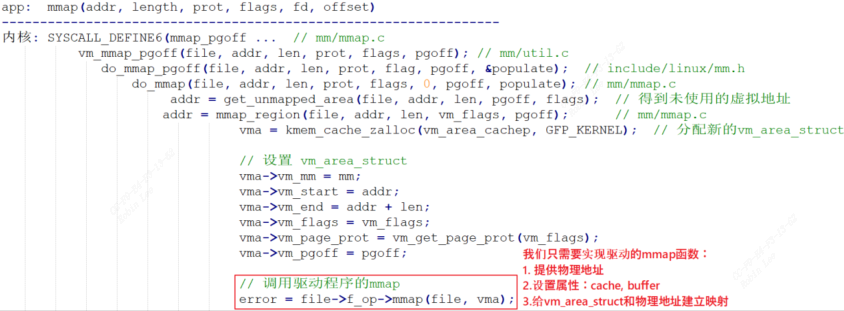
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
int munmap(void *addr, size_t length);
可以传入一个addr虚拟地址,需要用户自己malloc。也可以将addr设置为NULL,让linux内核帮你产生一段内存映射,返回虚拟地址给你。
内核得到可用的虚拟地址后会分配一个vm_area_struct, 用来描述一块虚拟地址空间,里面有这块虚拟地址空间的起始地址、结束地址、权限信息。最后会调用驱动里面的mmap函数,参数为刚刚分配的vm_area_sruct。
那么需要再驱动程序实现mmap函数,主要包括:
1.提供物理地址
2.设置属性,cache,buffer
3.给vm_area_stuct和物理地址建立映射
4.1 vm_area_struct描述
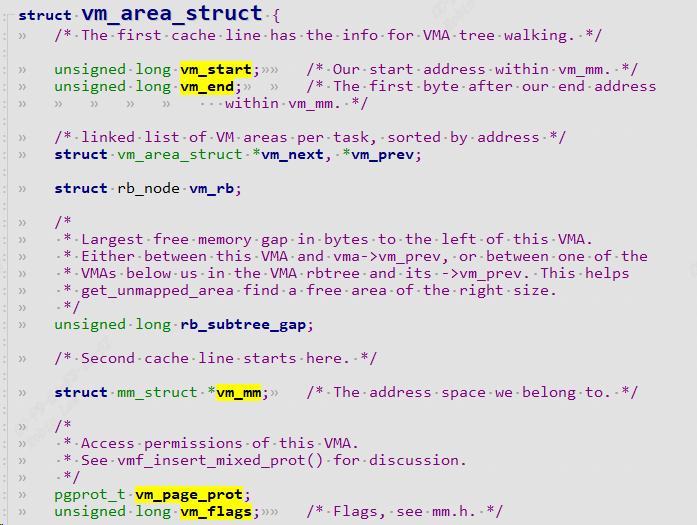
/*
* This struct describes a virtual memory area. There is one of these
* per VM-area/task. A VM area is any part of the process virtual memory
* space that has a special rule for the page-fault handlers (ie a shared
* library, the executable area etc).
*/
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
/*
* Largest free memory gap in bytes to the left of this VMA.
* Either between this VMA and vma->vm_prev, or between one of the
* VMAs below us in the VMA rbtree and its ->vm_prev. This helps
* get_unmapped_area find a free area of the right size.
*/
unsigned long rb_subtree_gap;
/* Second cache line starts here. */
struct mm_struct *vm_mm; /* The address space we belong to. */
/*
* Access permissions of this VMA.
* See vmf_insert_mixed_prot() for discussion.
*/
pgprot_t vm_page_prot;
unsigned long vm_flags; /* Flags, see mm.h. */
它表示的是一块连续的虚拟地址空间区域,给进程使用的,地址空间范围是0~3G,对应的物理页面都可以是不连续的.
主要成员有起始地址、结束地址、权限信息,属性信息。
vm_flags:可读,可写,可执行权限,私有,共享等权限
vm_pgoff:使用cache?使用buffer?
4.1 引入cache和buffer
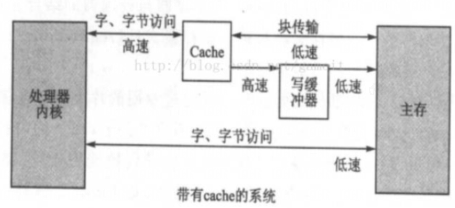
使用 mmap 时,需要有 cache、 buffer 的知识。下图是 CPU 和内存之间的关系,有 cache、 buffer(写缓冲器)。 Cache 是一块高速内存;写缓冲器相当于一个 FIFO,可以把多个写操作集合起来一次写入内存。
当程序运行时有“局部性原理”,这又分为时间局部性、空间局部性。举个例子:
int i;
int a = 0;
for (i = 0; i < 100; i++) {
a++;
}
时间局部性:
a++在很短的时间内被重复写了100次,与此同时i也被访问了100次,像这种在某个时间点访问了存储器的特定位置,反复地访问这个位置被称为“时间局部性”。
空间局部性:
访问变量a的同时也访问了它周围临近变量i, 像这种访问了存储器的特定位置,很可能在不久的将来访问它附近的位置被称作”空间局部性“, 那么为什么不用buffer or cache把它一次性访问完呢?
根据“局部性原理”,引入 cache和buffer。
读数据:
- 要读取内存指定addr处的数据时,先看看cache中有没有addr的数据,如果有则直接从cache返回数据,这一过程叫做cache命中(cache hit)。
- 假如cache中没有该addr的数据,触发cache miss, 那么会从addr读一段连续数据进去,注意:它不是仅仅读入一个数据,而是读入一行数据(cache line)。
- 那么CPU 短时间内很可能会再次用到甚至多次用到这个 addr 的数据或者周围临近的数据,那么就可以直接从cache快速的获取数据。这样弥补了时间和空间上的”局部性“。
写数据:
- CPU 写数据时,可以直接写内存,这很慢;也可以先把数据写入 cache,这很快.
- cache 中的数据终究是要写入内存的啊,这有 2 种写策略:
2.1 写通(write through):
◆ 数据要同时写入 cache 和内存,所以 cache 和内存中的数据保持一致,但是它的效率很低。能改进吗?可以!使用“写缓冲器”:cache 大哥,你把数据给我就可以了,我来慢慢写,保证帮你写完。
◆ 有些写缓冲器有“写合并”的功能,比如 CPU 执行了 4 条写指令:写第 0、 1、 2、 3 个字节,每次写 1 字节;写缓冲器会把这 4 个写操作合并成一个写操作:写 word。对于内存来说,这没什么差别,但是对于硬件寄存器,这就有可能导致问题。
◆ 所以对于寄存器操作,不会启动 buffer 功能;对于内存操作,比如 LCD 的显存,可以启用 buffer 功能(cpu直接用write buffer进行操作frame buffer内存)
2.2 写回(write back):
◆ 新数据只是写入 cache,不会立刻写入内存, cache 和内存中的数据并不一致。
◆ 新数据写入 cache 时,这一行 cache 被标为“脏” (dirty);当cache 不够用时,才需要把脏的数据写入内存。
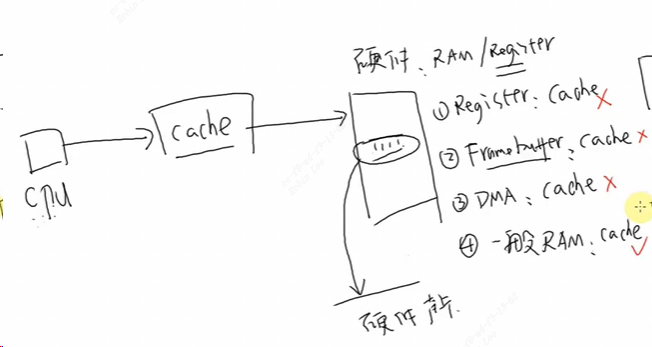
对内存或者变量进行写操作可以使用写回功能,可以大幅提高效率。但是要注意 cache 和内存中的数据很可能不一致。这在很多时间要小心处理:比如 CPU 产生了新数据, DMA 把数据从内存搬到网卡,这时候就要 CPU 执行命令先把新数据从 cache 刷到内存。反过来也是一样的, DMA 从网卡得过了新数据存在内存里, CPU 读数据之前先把 cache中的数据丢弃。下图举例说明哪些硬件可以用或者不能用cache:
是否使用 cache、是否使用 buffer,就有 4 种组合(位于arch\arm\include\asm\pgtable-2level.h):

以s3c2440芯片为例,上面 4 种组合对应下表中的各项:
| 是否启用 cache | 是否启用 buffer | 说明 |
|---|---|---|
| 0 | 0 | Non-cached, non-buffered (NCNB)读、写都直达外设硬件 |
| 0 | 1 | Non-cached buffered (NCB)读、写都直达外设硬件;写操作通过 buffer 实现, CPU 不等待操作完成, CPU 会马上执行下一条指令 |
| 1 | 0 | Cached, write-through mode (WT),写通 读: cache hit 时从 cahce 读数据; cache miss 时已入一行数据到 cache;写:通过 buffer 实现, CPU 不等待写操作完成, CPU 会马上执行下一条指令 |
| 1 | 1 | Cached, write-back mode (WB),写回 读: cache hit 时从 cahce 读数据; cache miss 时已入一行数据到 cache;写:通过 buffer 实现, cache hit 时新数据不会到达硬件,而是在 cahce 中被标为“脏”; cache miss 时,通过 buffer写入硬件, CPU 不等待写操作完成, CPU 会马上执行下一条指令 |
◼ 第 1 种是不使用 cache 也不使用 buffer,读写时都直达硬件,这适合寄存器的读写。
◼ 第 2 种是不使用 cache 但是使用 buffer,写数据时会用 buffer 进行优化,可能会有“写合并”,这适合显存的操作。因为对显存很少有读操作,基本都是写操作,而写操作即使被“合并”也没有关系。
◼ 第 3 种是使用 cache 不使用 buffer,就是“ write through”,适用于只读设备:在读数据时用 cache 加速,基本不需要写。
◼ 第 4 种是既使用 cache 又使用 buffer,适合一般的内存读写