第四部分 管理
第二十八章 迅速培养SRE加入on-call
如何给新手带上喷气背包,同时保证老手的速度不受影响?
成功的 SRE 团队离不开信任一一为了维持全球化服务的正常运转,我们必须信任 on-call团队了解系统如何运行,可以诊断系统的异常情况,善于利用资源和寻求帮助,以及可以在压力下保持镇静快速解决问题。那么,仅仅考虑“新手需要学习哪些知识才能参与 "on-cal1” 是不够的,根据上述需求,我们还需要考虑以下问题:
- 现有的 on-call 工程师如何能够评估新手是否已经准备好参加on-call?
- 我们如何能够更好地利用新员工带来的激情与好奇心,使老员工也能从中获利?
- 组织哪些活动不仅可以丰富团队知识,还能够获得大家的喜爱?

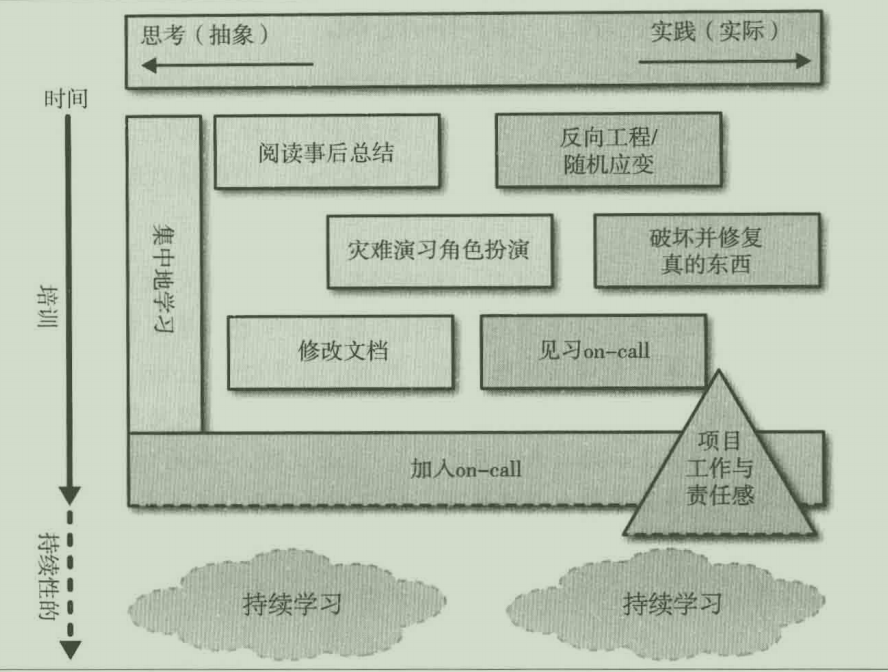
- X 轴代表工作类型的范围,从抽象的,一直到具体的工作。
- Y轴代表时间。从上至下,新加人的 SRE 通常对系统和服务知识了解很少,阅读之前故障的事后总结对他们很有帮助。新的 SRE 也可以试图从基本元素出发反向工程整个系统,因为他们本来对系统也没有任何了解。当学员对系统有一定程度的了解,并且已经进行了一些实际操作时,SRE 就可以参与见习 on-call了,同时可以修订文档中不完善或者过时的部分。
阅读上述图表的一些建议:
- 正式参加on-call是SRE新员工的一个重要里程碑,在这之后,学习过程将基本靠自己主导,是未定义的——所以SRE 参与on-call之后的培训计划都是用虚线标注的。
- 三角形的“项目工作”意味着新项目刚开始都很小,随着时间推移,复杂程度逐渐增大,所需投入也在增加,很有可能在参与on-call之后还会继续。
- 这里的某些活动是抽象性的,还有些是被动性的。其他的一些活动,则是非常具体和非常具有主动性的。还有一些活动是混合型的。这样的安排是为了满足不同学习方式的人,让他们都能找到适合自己的活动。
- 为了使培训效果最优,培训课程应该节奏合理:有些可以立即开始,有些则应该在SRE 正式参见on-call之前开始,而其他的则应该是持续性的,同时要求SRE老员工也参与的。在SRE正式参加on-call之前,应该处于持续不断的学习过程中
培训初期:重体系,而非混乱
SRE学员肯定会存在以下问题
- 我现在正在做的是什么工作?
- 我现在的进度如何?
- 什么时候我能积累到足够的经验参加on-call?
系统性、累积性的学习方式
在系统中加入某种顺序性,以便新的 SRE 成员可以建立某种学习路径。任何类型的系统性培训都要比直接处理随机出现的工单和琐事要好,但是我们应该有选择地将一些理论性和实践性的学习组合到一起:一些新成员经常会用到的、系统的抽象概念应该优先而学员也应该尽早进行真实的实践操作.
了解任何一个技术栈,或者任何一个子系统都需要一个起始点。我们应该考虑将培训按照类似作用分组,还是按照常用的执行顺序分组。
目标性强的项目工作,而非琐事
常见的新手项目类似于:
- 在服务技术栈中增加一个小的,但是用户可见的功能修改,接下来跟随这个修改直到发布到生产环境中。了解开发环境的配置和二进制文件的发布流程可以确保他们和开发团队联系密切
- 针对现有的服务监控盲点增加新的监控。新手需要了解监控逻辑,同时将这些异常情况与系统知识相结合。
- 选择一个还没有被自动化的痛点进行自动化,使得新的SRE 可以给团队成员减轻一些日常负担,从而受到团队的欣赏
培养反向工程能力和随机应变能力
反向工程:弄明白系统如何工作
统计学和比较性思维:在压力下坚持科学方法论
随机应变的能力:当意料之外的事情发生时怎么办
将知识串联起来:反向工程某个生产环境服务
有抱负的 on-call 工程师的5哥特点
对事故的渴望:事后总结的阅读和书写(事后总结如果被束之高阁是没有什么用的。每个团队必须收集,并目整理有价值的事后总结文档,将它们用于未来新手的教育材料。某些事后总结文档就是需要死记硬背的,某些事后总结文档可以作为“课程”进行教授,可以让学员了解大型系统的结构性弱点,或者新奇的故障方式,这些都是非常有价值的)
故障处理分角色演习(SRE成员身陷于各种监控图表组成的迷宫中,必须要解决用户请求延迟过高的问题,或者是防止数据中心崩溃,又或者是防止某个错误的 Google Doodle 被显示在网页上。)
破坏真的东西,并且修复它们
维护文档是学徒任务的一部分
对学员来说:
- 这个文档可帮助学员了解运维系统的边界
- 通过学习这个文档,学员可以了解系统的重要组件,以及背后的原因。当他们掌握了这些系统的知识之后,可以去了解其他更广泛的知识,而不是纠结于一些可以通过日后学习得来的细节问题。
对导师和管理者来说:
- 学员的学习进度可以通过检查列表来反映,检查列表可以回答以下问题:
一学员今天学习的是哪一节?
一哪一节是最让人困惑的? - 对其他团队成员来说:文档成为一种社会契约,只有掌握这个文档的员工才能加入 on-call。这个学习检查列表成为一个知识的标准,所有的团队成员都必须符合这个标准。
在快速变化的环境中,文档可能很快就过期了。当学员开始熟悉学习列表的规范和格式后,会要求他们提供某一章节的修改部分这些修改必须经过列在表上的资深SRE的评审才能提交。
尽早、尽快见习 on-call(当一个报警发生时,新手SRE 并不是问题解决的负责人,这样可以让他们在没有任何压力的情况下进行操作。他们现在可以亲眼观察故障发展,而不是在事后学习。学员可以和主 on-call 共享一个终端,或者仅仅是坐在一起讨论。在故障解决后的某个合适时机on-call 可以和学员一起讨论背后的处理逻辑和过程。这种活动可以帮助见习学员记住更多细节。)
第二十九章 处理中断性任务
紧急警报、工单,以及其他的持续性运维活动
第三十章 通过嵌入SRE的方式帮助团队从运维过载中恢复
第一阶段:了解服务,了解上下文
第二阶段:分享背景知识
第三阶段:主导改变
第三十一章 SRE与其他团队的沟通与协作
只有在不得已的情况下才应该跨地域开发项目,但是这同时也会带来一定的好处。跨地域工作需要更多的沟通,工作完成得也更慢;但是好处是一一如果你能协调好的话——则会有更高的产能。单地项目其实也可能会导致其他人不知道你正在做什么,所以这两种做法其实都有一定成本。
第三十二章 SRE参与模式的演进历程(略)
第三十三章 其他行业的实践经验
灾难预案与演习
从组织架构层面坚持不懈地对安全进行关注
关注任何细节
冗余容量
模拟以及进行线上灾难演习
培训与考核
对详细的需求收集和系统设计的关注
事后总结的文化
将重复性工作自动化
我们所调研的各个行业在对待自动化的问题上各有不同。某些行业信任人多过自动化。美国核动力海军通过一系列交叉管理流程来避免自动化。例如,根据 Jeff Stevenson的经历,操作某个阀门需要一个操作员、一个监督员,以及一个船员与负责监控该操作的工程负责人保持通话。这些操作过程是极为人工化的,因为担心自动化系统可能不会发现人能注意到的问题。潜艇上的操作是由一条信任的人工决策链管理的一一一系列人而非单独一个人。核动力海军同时担心自动化和计算机运行速度太快,以至于它们可能造成非常严重且无法挽回的问题。当面对核反应堆时,缓慢而稳健的方法比快速完成任务更重要
第三十四章 结语
为什么飞行过程中的所有其他元素一一安全性、容量、速度、可靠性一一都发生了翻天覆地的变化,而仍然只有两名飞行员呢?这里的答案与Google SRE 运维大规模、超复杂的系统的方法是一致的。飞机操作系统的人机接口都是精心设计过的,简单易用、易于学习,使得飞行员可以正常操纵飞机飞行。同时,这些界面又提供了足够的灵活性飞行员也经过了大量训练,使得他们可以很快、很可靠地应对紧急情况。飞机驾驶舱是由理解复杂系统的人设计的,他们知道如何用一种可扩展的、易于理解的方式给飞行员提供数据。飞机中的系统都具有很多本书中提到的各种特性:高可用性、性能极度优化变更管理、监控与报警、容量规划,以及应急处理。
最终,SRE的目标也是如此。SRE 团队应该越精简越好,他们所操作的东西应该更抽象而非更具体。SRE 团队依赖各种后备系统和精心设计的 API来运维。同时,SRE也应对系统的运作原理、运维方式、故障模式以及应急处理方式非常了解一一这些都是在日常工作中学到的。
附录F 生产环境会议记录示范


???完结撒花???