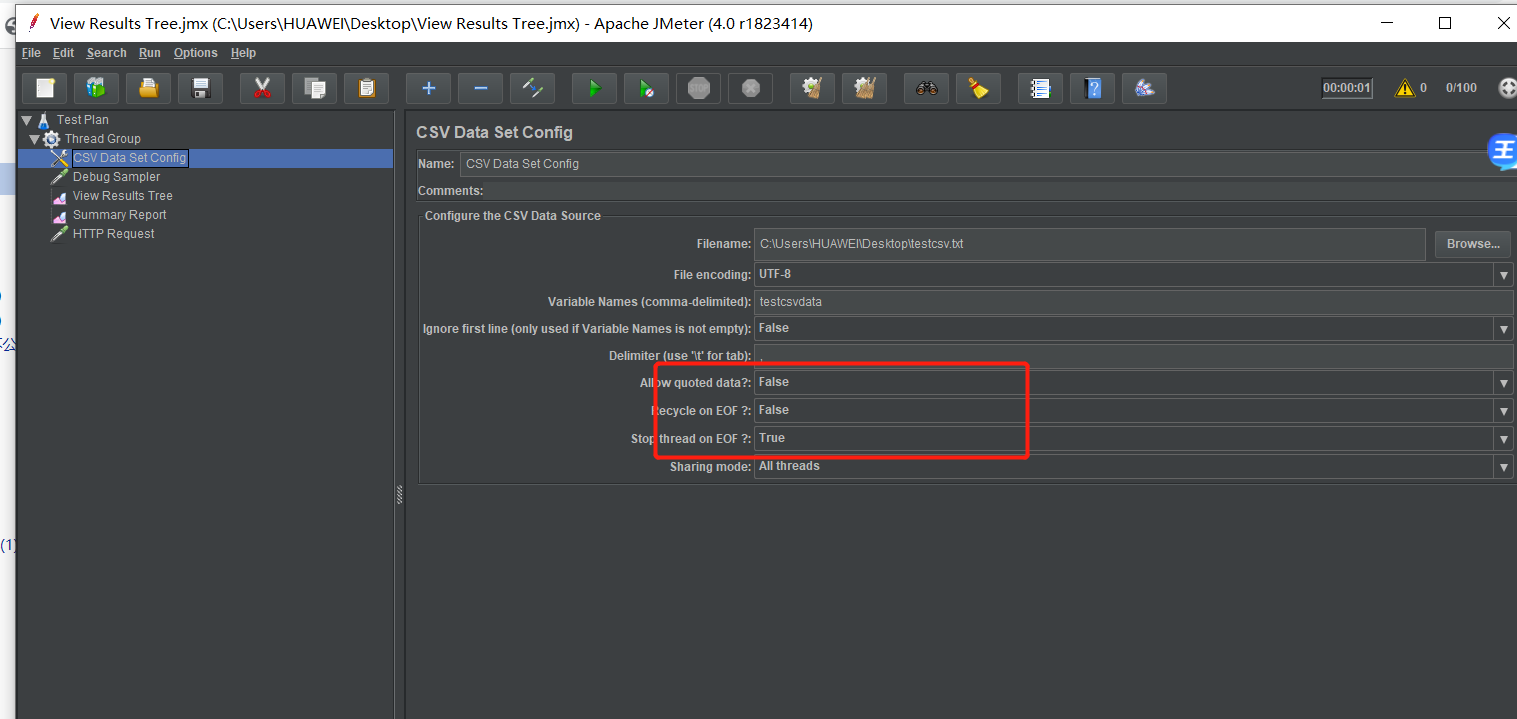
如果想csv里的数据只使用一次

==================================
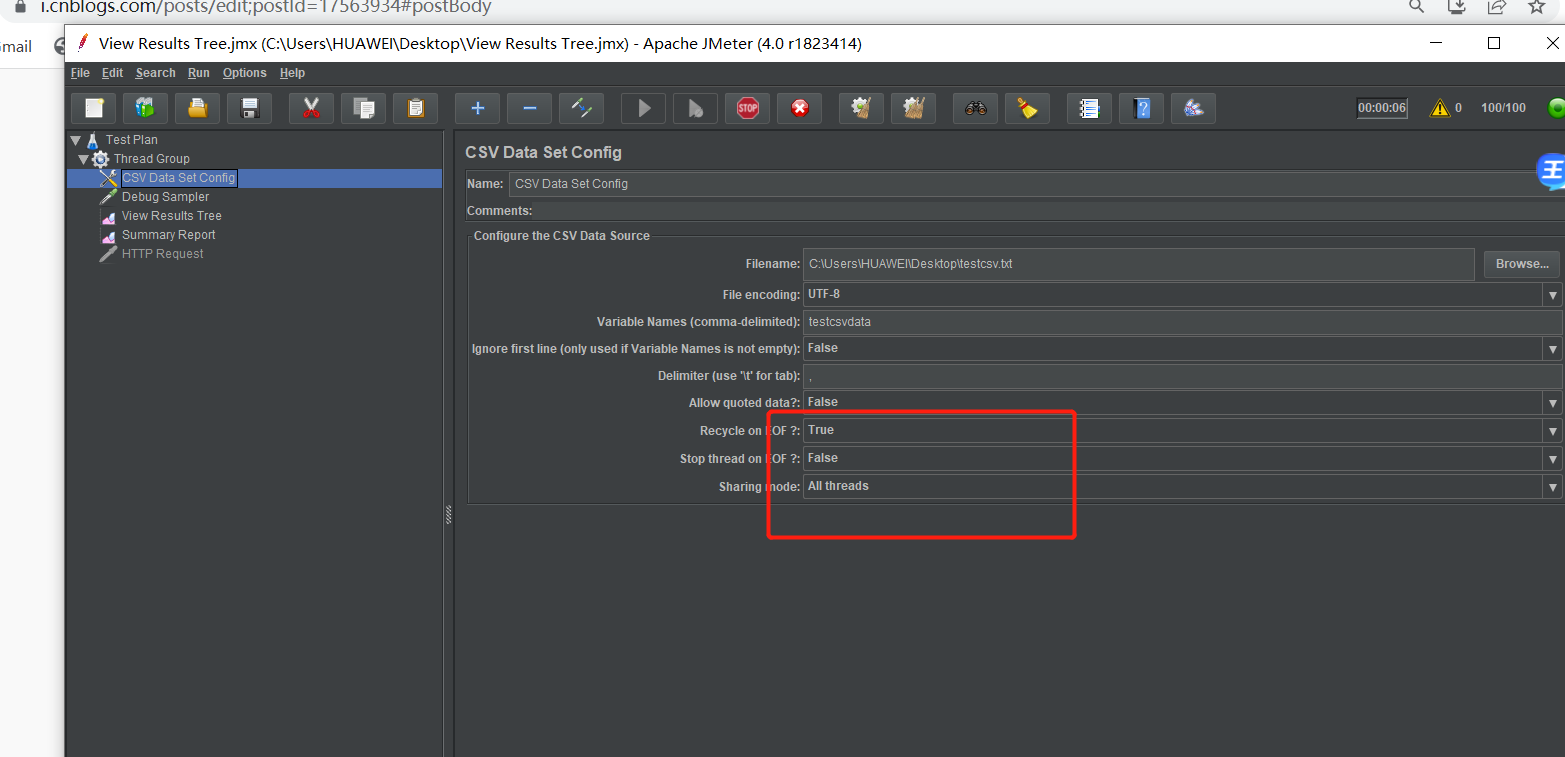
遇到空行不结束
循环往复执行
-------------------------------------------------------------
current thread 慎用,因为是随机的
[bot] 非常抱歉,我之前的回答中的 "Random Order" 配置选项是错误的。实际上,在 JMeter 的 "CSV Data Set Config" 元件中,并没有提供直接的 "Random Order" 选项。
要实现随机读取策略,您可以通过以下方式进行操作:
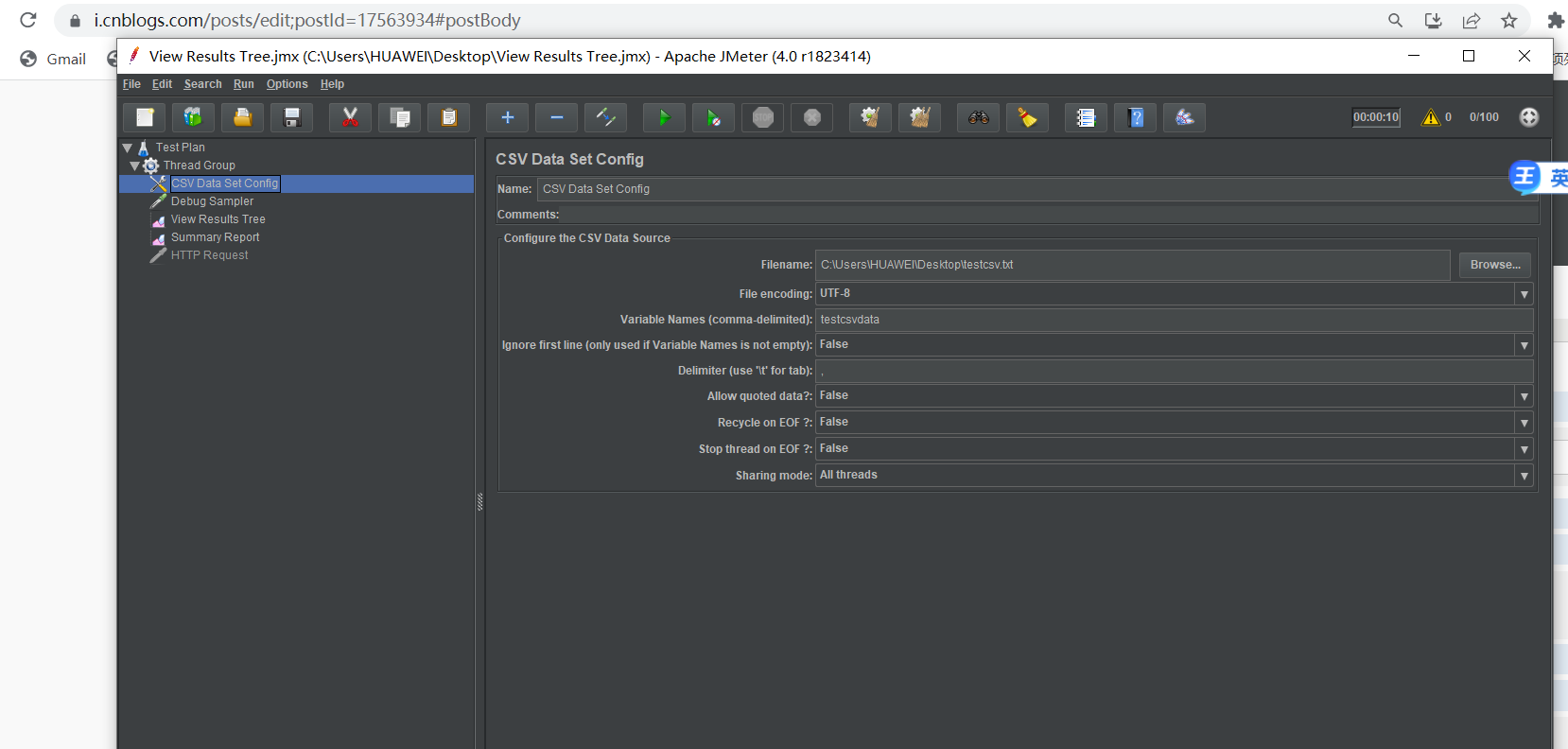
1. 在 "CSV Data Set Config" 元件的配置界面,将 "Recycle on EOF"(到达文件末尾后重新开始)和 "Stop thread on EOF"(到达文件末尾时停止线程)选项都设置为 "False"。
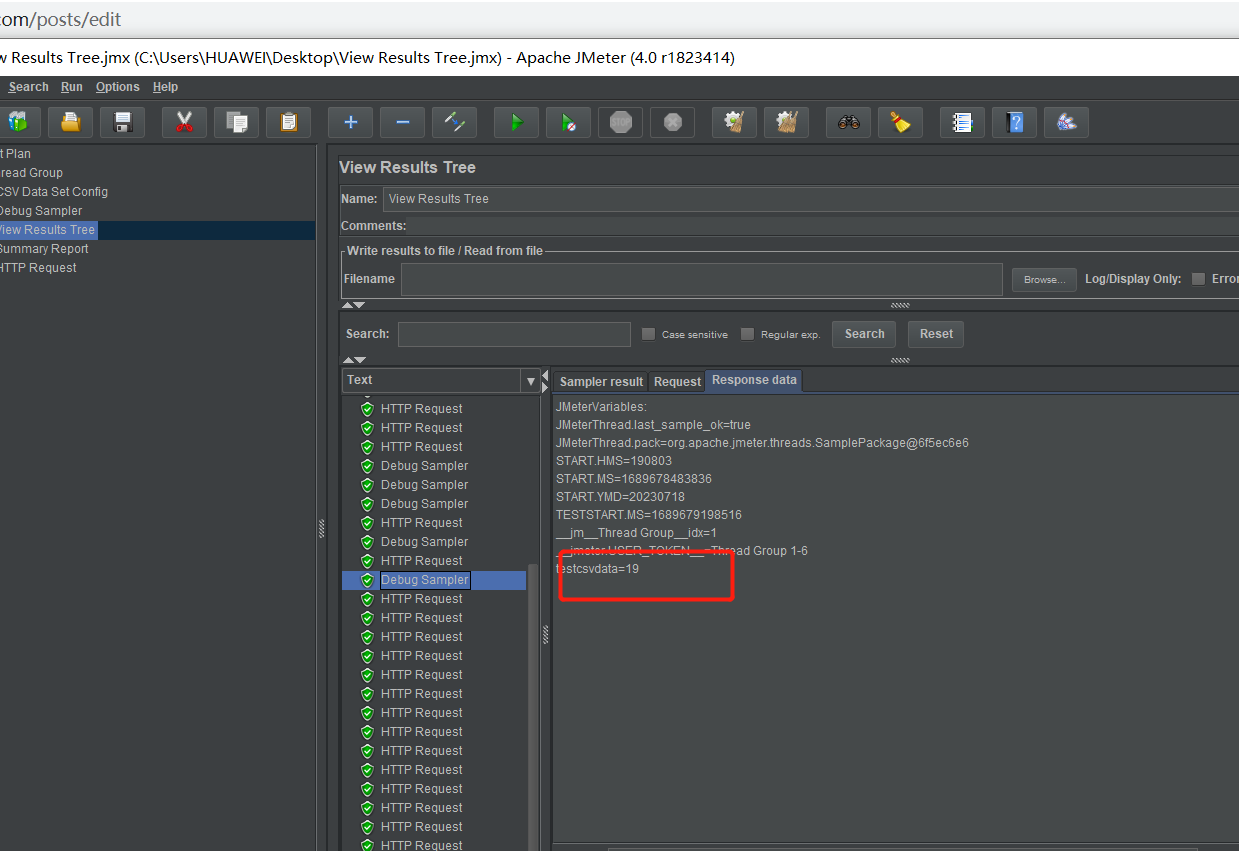
2. 在 "CSV Data Set Config" 元件的配置界面,将 "Sharing Mode"(共享模式)设置为 "Current thread"(当前线程拥有)。
这样配置后,在每个线程中,每次请求都会随机选择 CSV 文件中的一行作为测试数据。
请注意,由于 JMeter 并没有提供直接的随机读取选项,上述配置只是一种近似的实现方式。如果您需要更精确的随机读取策略,可以考虑自定义开发或使用其他的插件/扩展来实现。
的 "Sharing Mode"(共享模式)选项有以下几种不同的选项:
1. All threads(所有线程):选择此选项时,所有线程将共享同一个 CSV 文件,并且每个线程按照顺序读取文件的下一行。这意味着所有线程将以相同的顺序使用文件中的数据行。如果线程数大于数据行数,那么一些线程将重新开始使用文件的开头行,形成循环。这是默认选项。
2. Current thread(当前线程):选择此选项时,每个线程将独立地读取 CSV 文件中的行。每个线程读取文件时,它会锁定文件并移至下一个可用行。这意味着每个线程都会以不同的顺序使用文件中的数据行,而且线程之间不会共享行。这对于需要线程独立处理数据的情况非常有用。
3. Current thread group(当前线程组):选择此选项时,同一线程组内的线程将共享同一个 CSV 文件,而不同线程组之间不共享数据。每个线程组内的线程按照顺序读取文件的下一行。这意味着同一线程组内的线程将以相同的顺序使用文件中的数据行。如果线程组的线程数大于数据行数,一些线程组的线程将重新开始使用文件的开头行,形成循环。
这些选项允许您根据测试需求来配置线程之间如何共享和读取 CSV 文件中的数据。您可以根据测试场景的需要选择适当的共享模式,无论是所有线程共享数据还是线程独立处理数据。