2023数据采集与融合技术实践作业4
实验4.1
- 要求:
- 熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内
容。
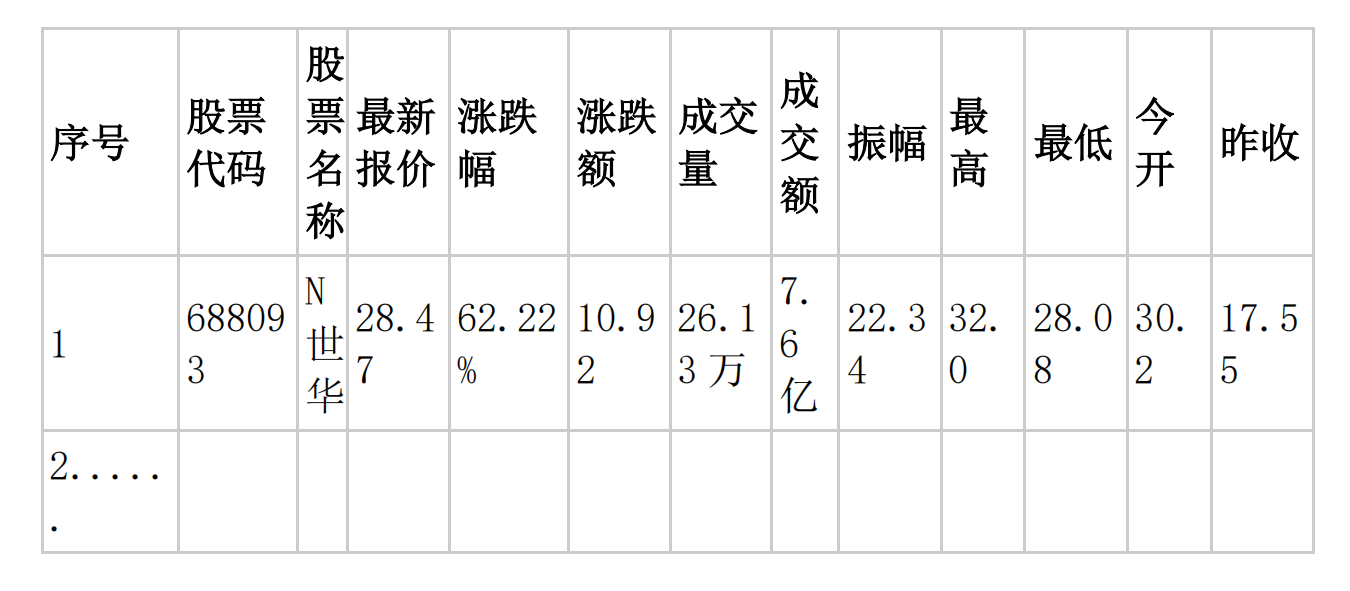
- 使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
候选网站:东方财富http://quote.eastmoney.com/center/gridlist.html#hs_a_board
- 输出信息:
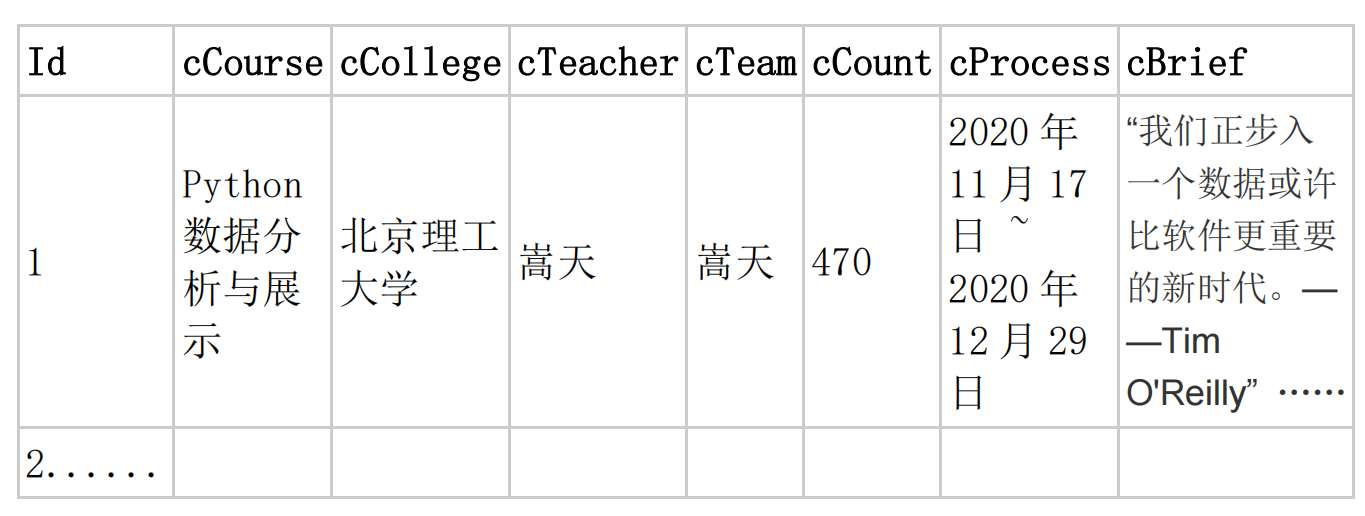
MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
码云链接:https://gitee.com/Alynyn/crawl_project/blob/master/作业4/1.py
- code
1.py代码
import time
import pymysql
from selenium.webdriver.common.by import By
from selenium import webdriver
def start_spider():
# 数据爬取函数
global items
time.sleep(3)
trs = driver.find_elements(By.XPATH,'//tbody/tr')
for tr in trs:
NO = tr.find_element(By.XPATH,'./td[1]').text #序号
code = tr.find_element(By.XPATH,'./td[2]').text #股票代码
title = tr.find_element(By.XPATH, './td[3]').text #名称
rec_price = tr.find_element(By.XPATH,'./td[5]').text #最新报价
updown_percent = tr.find_element(By.XPATH,'./td[6]').text #涨跌幅
updown_sum = tr.find_element(By.XPATH,'./td[7]').text # 涨跌额
deal_amount = tr.find_element(By.XPATH,'./td[8]').text # 成交量
deal_sum = tr.find_element(By.XPATH,'./td[9]').text # 成交额
swing = tr.find_element(By.XPATH,'./td[10]').text # 振幅
max = tr.find_element(By.XPATH,'./td[11]').text # 最高
min = tr.find_element(By.XPATH,'./td[12]').text # 最低
today = tr.find_element(By.XPATH,'./td[13]').text # 今开
yesterday = tr.find_element(By.XPATH,'./td[14]').text # 昨放
items.append([NO,code,title,rec_price,updown_percent,updown_sum,deal_amount,deal_sum,swing,max,min,today,yesterday])
def save_data(items):
# 将数据保存到数据库当中
mydb = pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
password="123456",
database="spider",
charset='utf8'
)
cursor = mydb.cursor()
cursor.execute('''CREATE TABLE IF NOT EXISTS Stock
(NO VARCHAR(256),
code VARCHAR(256),
title VARCHAR(256),
rec_price VARCHAR(256),
updown_percent VARCHAR(256),
updown_sum VARCHAR(256),
deal_amount VARCHAR(256),
deal_sum VARCHAR(256),
swing VARCHAR(256),
max VARCHAR(256),
min VARCHAR(256),
today VARCHAR(256),
yesterday VARCHAR(256)
)''')
mydb.commit()
for item in items:
sql = "insert into Stock values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
cursor.execute(sql, (item[0],item[1],item[2],item[3],item[4],item[5],item[6],item[7],item[8],item[9],item[10],item[11],item[12]))
mydb.commit()
mydb.close()
print("以上数据已保存到数据库!")
# 实现不同页面跳转
details = {
"沪深A股": "#hs_a_board",
"上证A股": "#sh_a_board",
"深证A股": "#sz_a_board"
}
driver = webdriver.Chrome()
for key in details.keys():
url = "http://quote.eastmoney.com/center/gridlist.html" + details[key]
print(key+ ":" +url)
driver.get(url)
driver.implicitly_wait(3)
items = []
start_spider()
for item in items:
print(item)
save_data(items)
driver.quit()
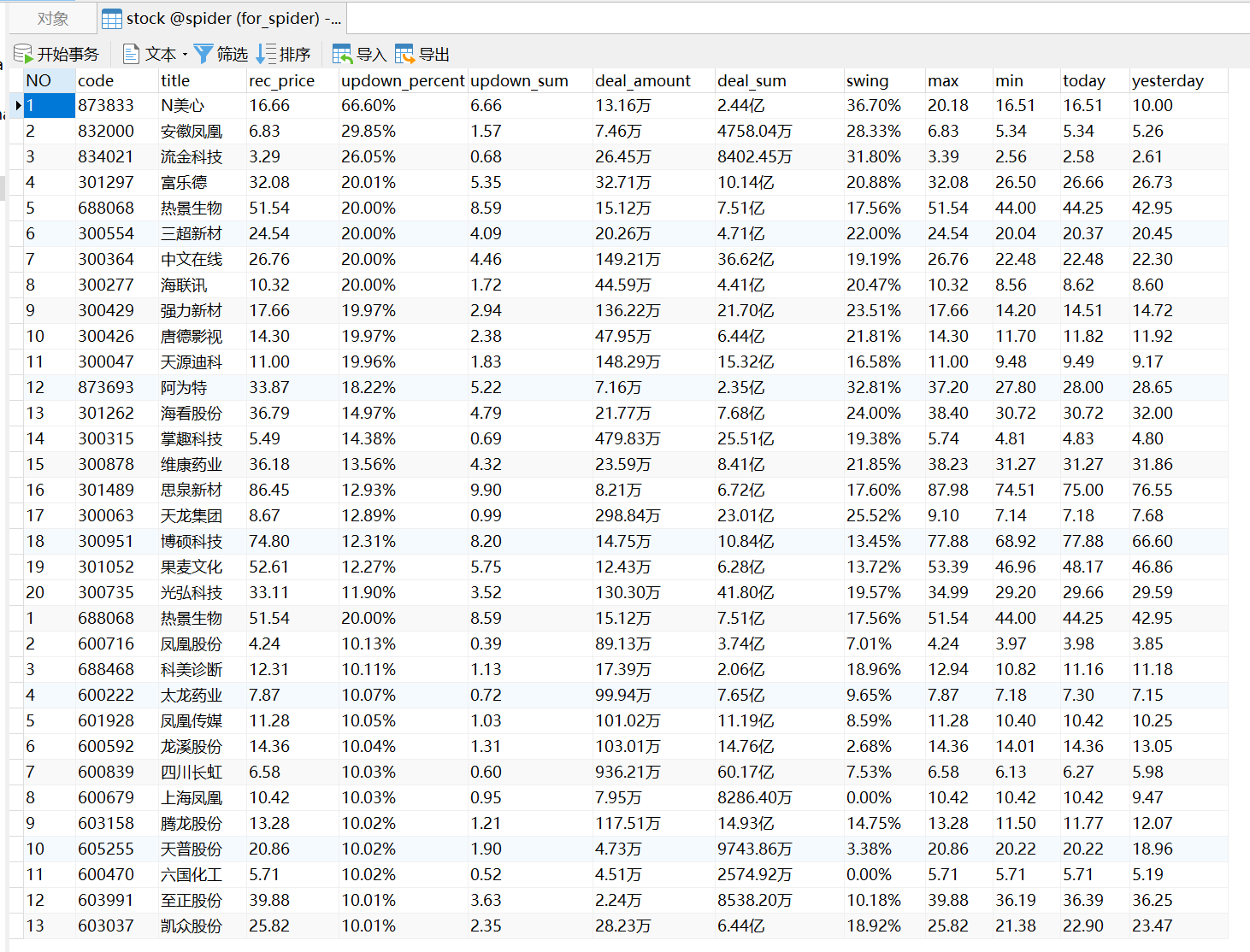
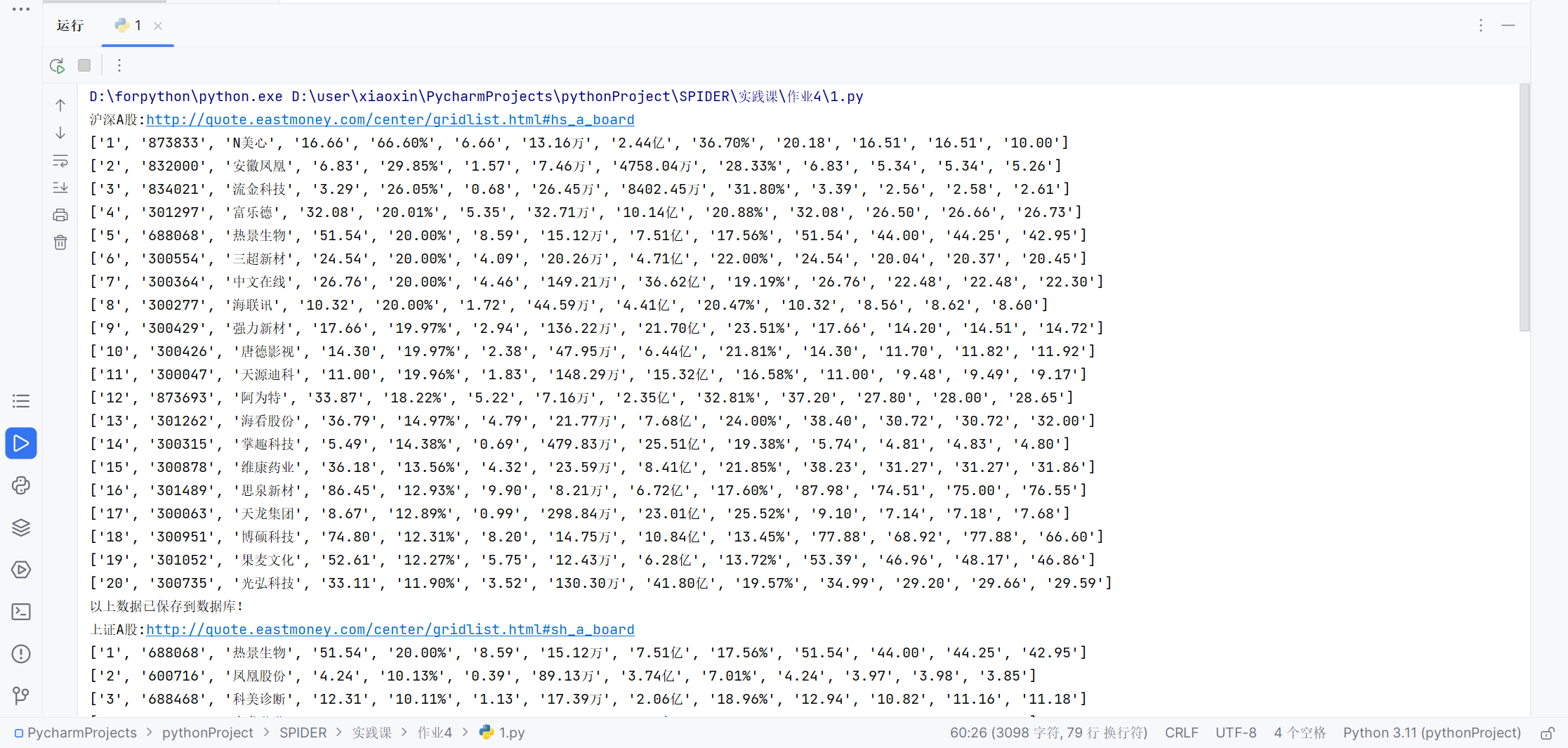
- 运行结果截图
实验4.2
2.py代码
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
import random
import pymysql
def start_spider():
# 请求url
driver.get(url)
WebDriverWait(driver, 1000).until(
EC.presence_of_all_elements_located(
(By.ID, "j-courseCardListBox")
)
)
# 将滚动条拉到最下面的位置,因为往下拉才能将这一页的信息全部加载出来
driver.execute_script('document.documentElement.scrollTop=10000')
# 随机延迟,等下元素全部刷新
time.sleep(random.randint(3, 6))
driver.execute_script('document.documentElement.scrollTop=0')
id = 0
for link in driver.find_elements(By.XPATH,'//div[@class="u-clist f-bgw f-cb f-pr j-href ga-click"]'):
id += 1 # 课程号
course_name = link.find_element(By.XPATH,'.//span[@class=" u-course-name f-thide"]').text # 课程名称
print("课程名称", course_name)
school_name = link.find_element(By.XPATH,'.//a[@class="t21 f-fc9"]').text # 学校名称
print("学校名称", school_name)
m_teacher = link.find_element(By.XPATH,'.//a[@class="f-fc9"]').text # 主讲教师
print("主讲教师:", m_teacher)
try:
team_member = link.find_element(By.XPATH,'.//span[@class="f-fc9"]').text # 团队成员
except Exception as err:
team_member = '无'
print("团队:",team_member)
join = link.find_element(By.XPATH,'.//span[@class="hot"]').text # 参加人数
join.replace('参加', '').replace('、','').strip()
print("参加人数", join)
process = link.find_element(By.XPATH,'.//span[@class="txt"]').text # 课程进度
print("课程进度:", process)
brief = link.find_element(By.XPATH,'.//span[@class="p5 brief f-ib f-f0 f-cb"]').text # 课程简介
print(brief)
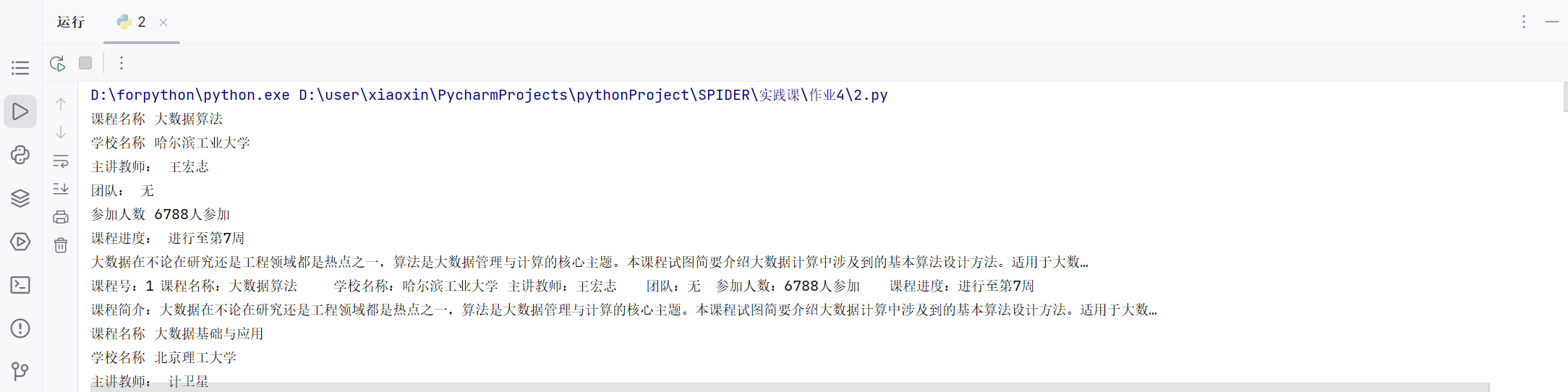
print(f"课程号:{id}\t课程名称:{course_name}\t学校名称:{school_name}\t主讲教师:{m_teacher}\t团队:{team_member}\t参加人数:{join}\t课程进度:{process}")
print(f"课程简介:{brief}",end="\n")
conn = pymysql.connect(host="127.0.0.1",
port=3306,
user="root",
password="123456",
database="spider",
charset='utf8')
# 获取游标
cursor = conn.cursor()
# 插入数据,注意看有变量的时候格式
try:
cursor.execute(
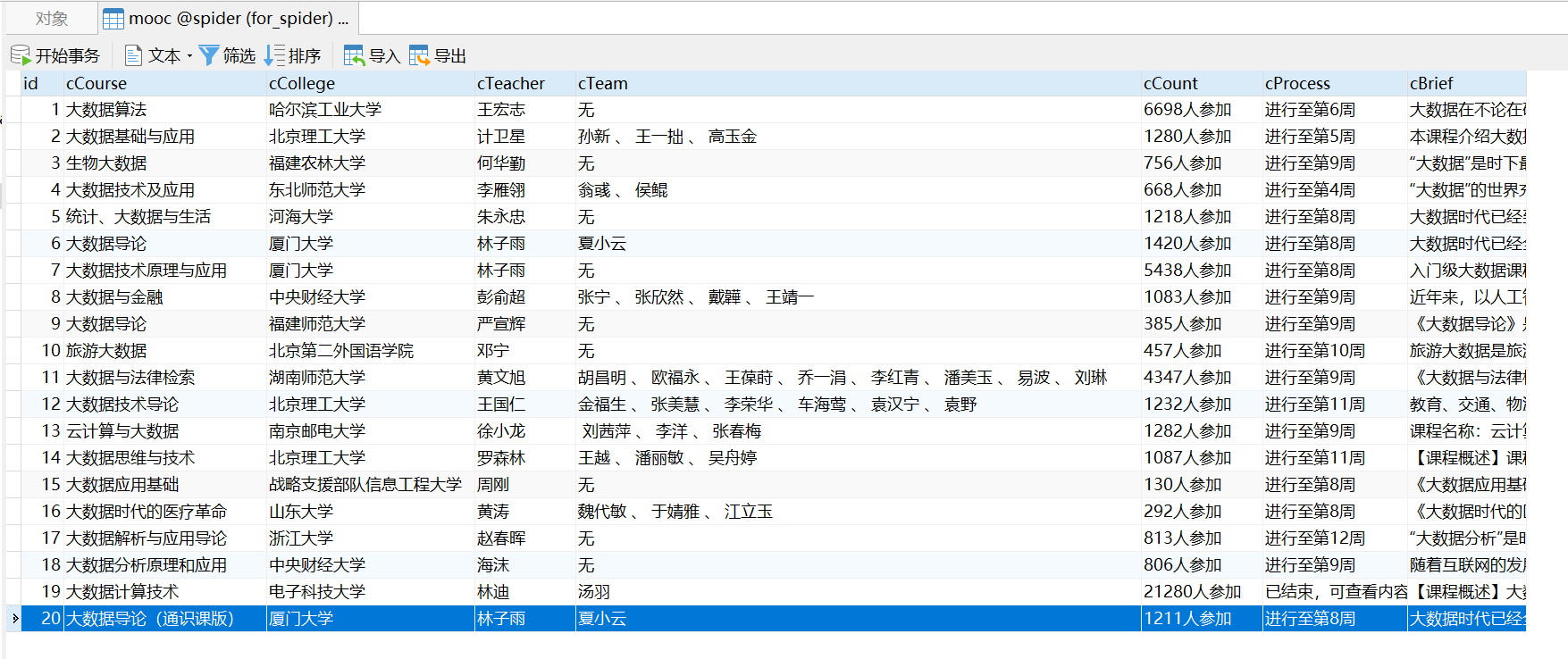
"INSERT INTO mooc (`id`,`cCourse`,`cCollege`,`cTeacher`,`cTeam`,`cCount`,`cProcess`,`cBrief`) VALUES (%s,%s,%s,%s,%s,%s,%s,%s)",
(str(id), course_name, school_name, m_teacher, team_member, join, process, brief))
except Exception as err:
pass
conn.commit()
conn.close()
driver = webdriver.Chrome()
url = "https://www.icourse163.org/search.htm?search=%E5%A4%A7%E6%95%B0%E6%8D%AE#/"
# 声明一个list,存储dict
data_list = []
start_spider()
driver.quit()
- 运行结果截图
实验4.3
- 要求:
- 掌握大数据相关服务,熟悉 Xshell 的使用
- 完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部
分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
环境搭建:
任务一:开通 MapReduce 服务
实时分析开发实战:
任务一:Python 脚本生成测试数据
任务二:配置 Kafka
任务三: 安装 Flume 客户端
任务四:配置 Flume 采集数据
- -输出信息:实验关键步骤或结果截图。
- 任务一:开通 MapReduce 服务
根据实验手册完成华为云中MapReduce的部署

- 任务一:Python 脚本生成测试数据
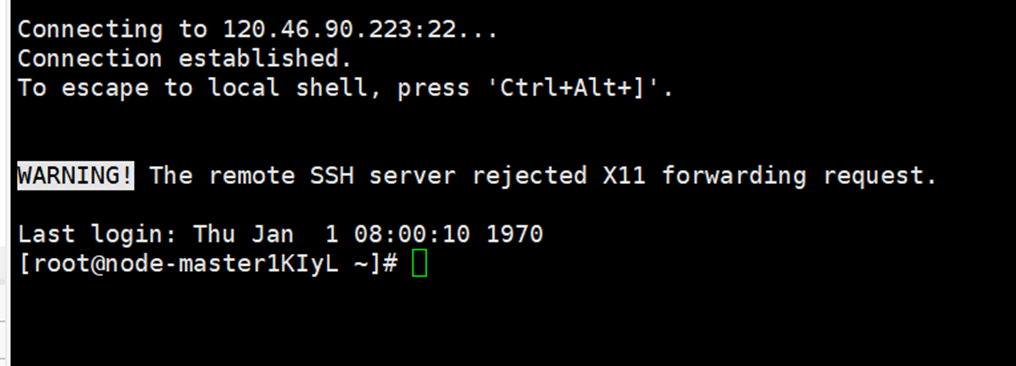
使用XShell7连接服务器
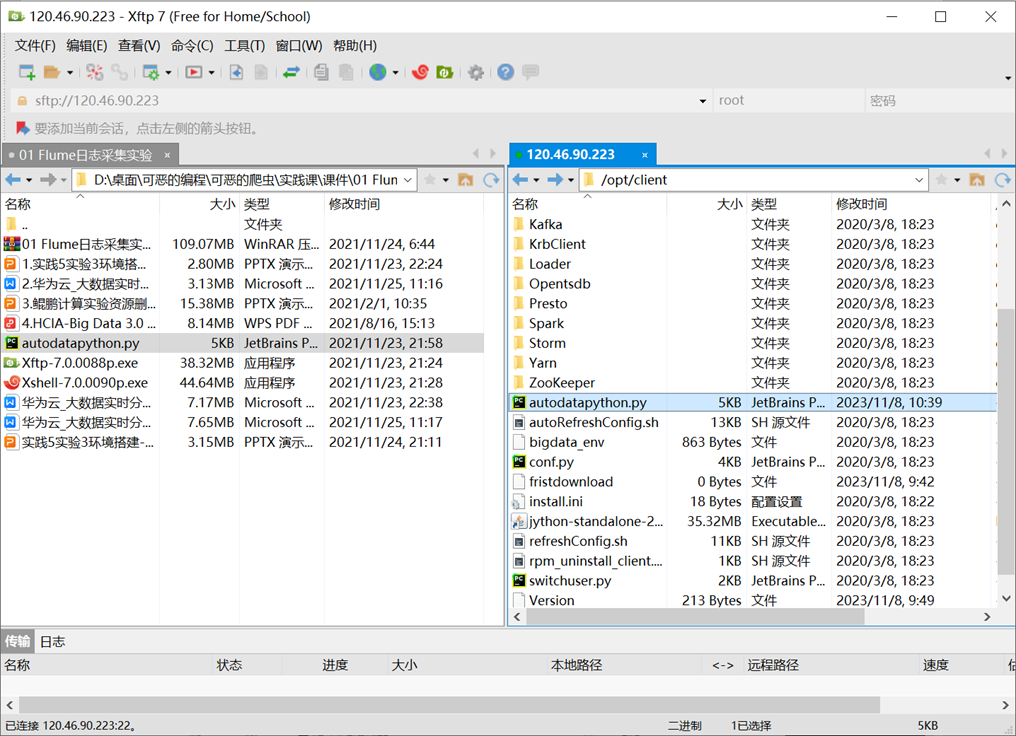
通过Xftp7将文件同步上传至服务器中opt/client/文件夹下
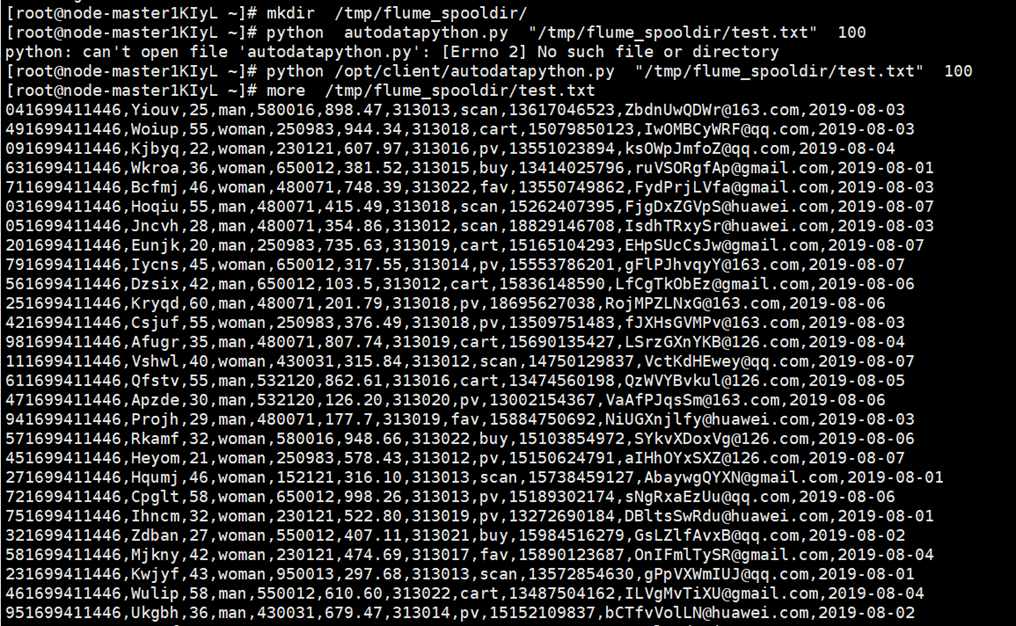
创建目录并执行python命令,最后查看数据
- 任务二:配置 Kafka
首先设置环境变量,执行source命令,使变量生效;接着在kafka中创建topic;最后查看topic信息

- 任务三: 安装 Flume 客户端
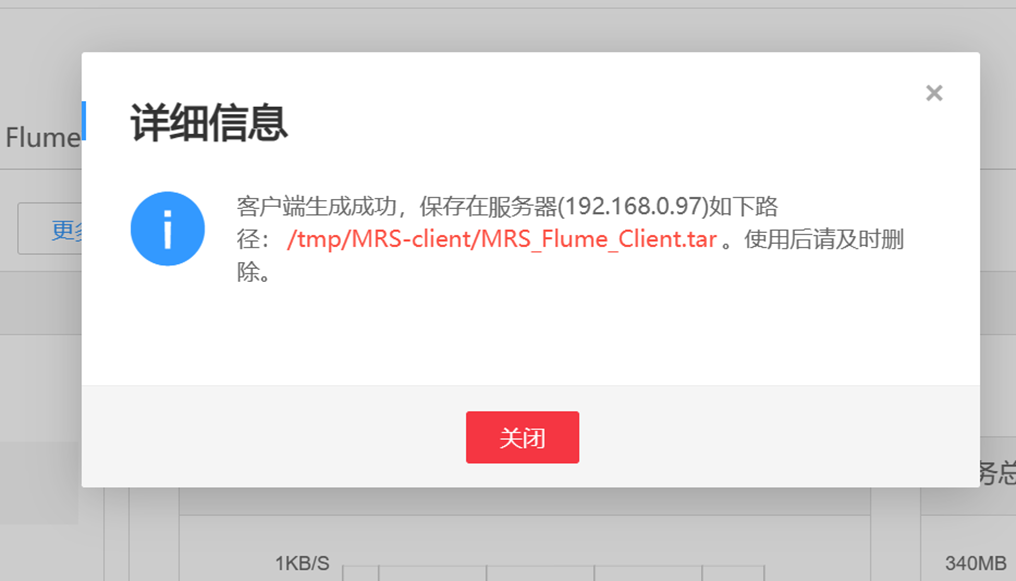
根据实验手册操作,完成Flume客户端下载,下载完成后会有弹出框提示下载到哪一台服务器上(这台机器就是Master节点),路径就是/tmp/MRS-client
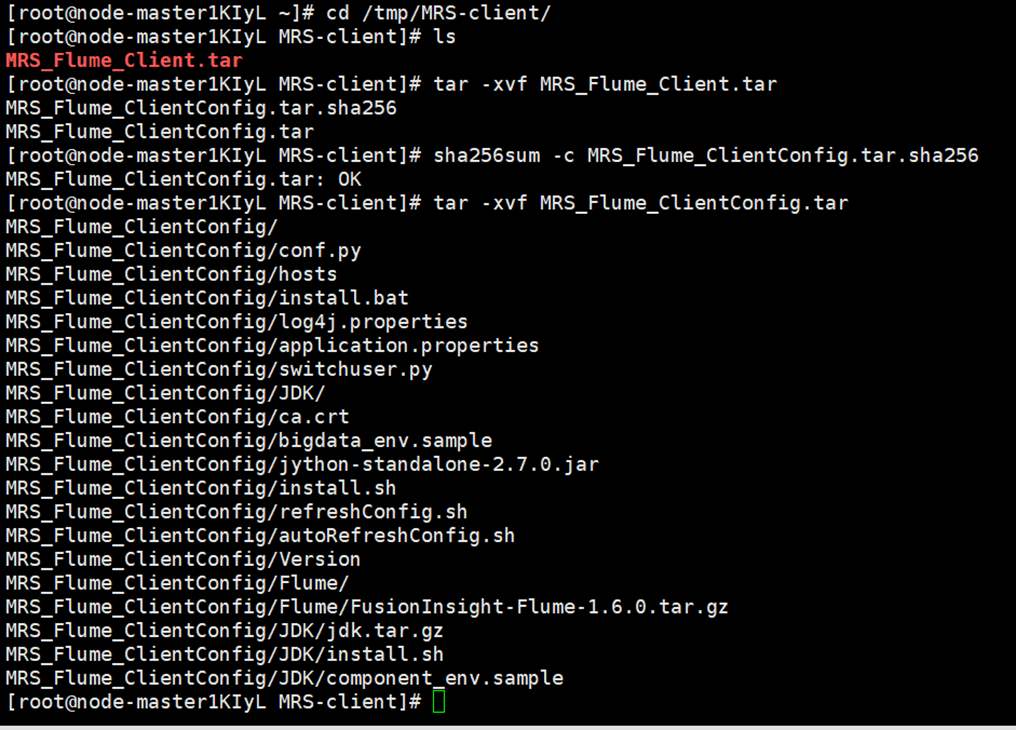
接着解压下载的flume客户端文件;解压压缩包获取校验文件与客户端配置包;校验文件包最后解压“MRS_Flume_ClientConfig.tar”文件
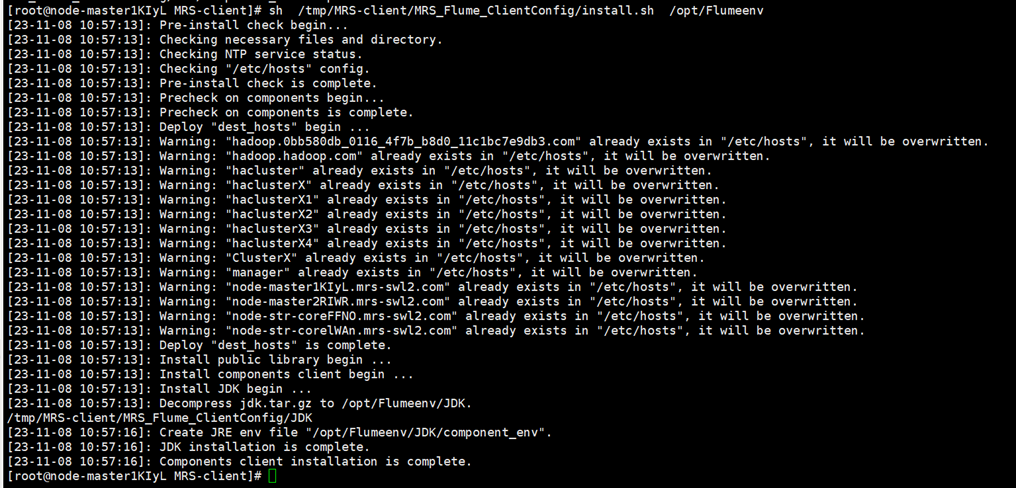
进一步安装Flume环境变量,执行相应命令,安装客户端运行环境到新的目录“/opt/Flumeenv”,安装时自动生成目录
接着解压Flume客户端
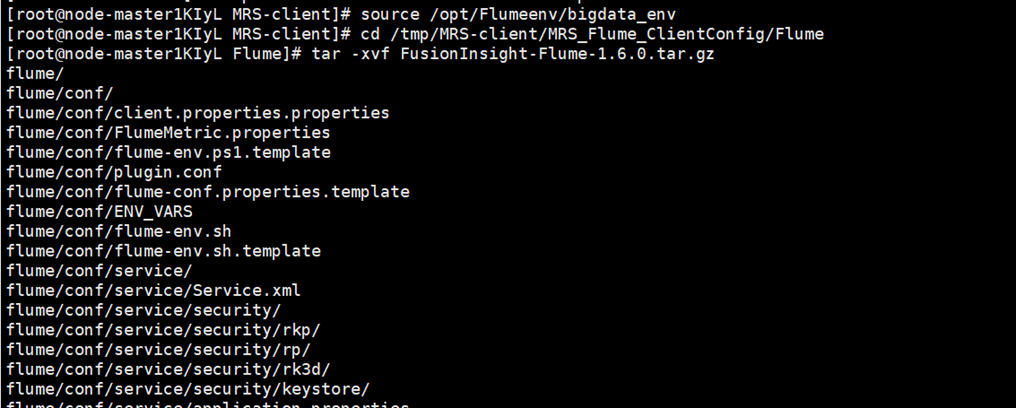
最后安装Flume客户端并重启Flume服务

- 任务四:配置 Flume 采集数据
首先修改配置文件,进入Flume安装目录在conf目录下编辑文件properties.properties;接着创建消费者消费kafka中的数据,登录Master节点,source环境变量后,执行相关命令。
执行完毕后,在新开一个Xshell 7窗口(右键相应会话-->在右选项卡组中打开),执行2.2.1步骤三的Python脚本命令,再生成一份数据,查看Kafka中是否有数据产生,可以看到,已经消费出数据了
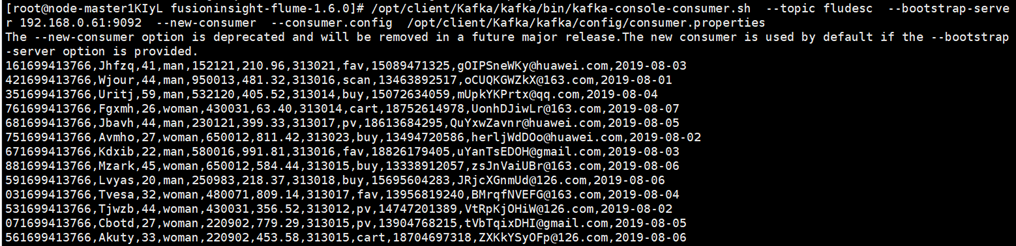 (ps:上图包括新开Xshell7窗口前后的全过程)
(ps:上图包括新开Xshell7窗口前后的全过程)
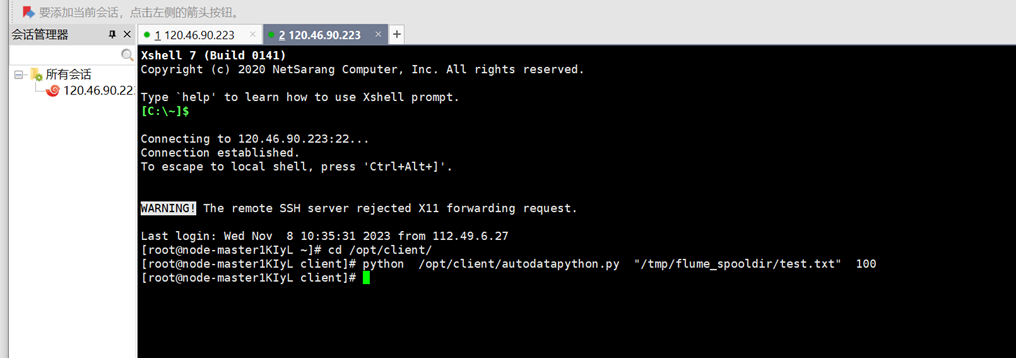 (ps:上图为新开一个Xshell 7窗口执行Python脚本命令,再生成一份数据)
(ps:上图为新开一个Xshell 7窗口执行Python脚本命令,再生成一份数据)
实验心得
- 体会:通过本次实践让我加深了对selenium爬取数据过程的知识的理解,同时紧接上次课作业对于将数据存储到数据库当中更加熟练!对华为云的相关服务有了初步认识、拓宽自己的眼界与认知!但在根据实践手册一步一步进行操作时还是有碰到些许问题,应该是自己较为粗心在配置时出现问题,今后做事应当更加细腻~