Starrocks v2.5.5
官方文档地址:https://docs.starrocks.io/zh-cn/2.5/introduction/StarRocks_intro
前言:
Starrocks并非传统的mysql数据库,而是一个列存的分布式olap数据库,列式存储对比行存的优势是可以更快的定位数据和更高的数据压缩比。对应的缺点是无法感知是哪一行的数据有新增,从而无法进行数据感知下发。
数据存储案例:假设集群的副本数为2 ,表内设置的分桶数为3(最小分桶为3)
则对应的一个表文件就会分为 2×3 = 6 ,共6个文件。
如图:
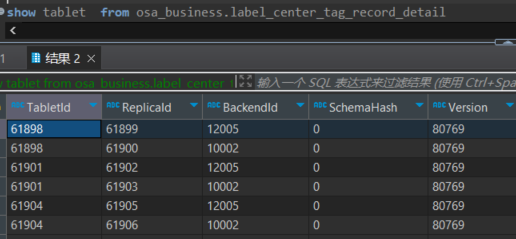
目前集群现状:FE : 1 BE:2
只有一套生产集群,做账号的权限和资源分离,来区分dev和生产,生产又区分为大数据使用和java开发使用的区别。
注:除test库外,所有drop权限被收回。
常用命令:
清空表数据:
TRUNCATE table ads_osa_mds_salesman_return_cost_base_test1;
列转行:
with abc as(
select 'a;b;c;d' origins
)
select t2.unnest from abc t1, unnest(split(origins, ";")) t2;
时间格式化:
select DATE_FORMAT(now(), '%Y-%m-%d')
分页:
SELECT * FROM label_center_tag_record_detail order by id LIMIT 10 OFFSET 20;
Json转换:
SELECT parse_json('{A:A,B:B}')
select a->'a'
,get_json_string(parse_json(all_parent_address),'$.a')
from (
select json_object('a', 4, 'b', false) as a
) t1
建表:
明细模型:
明细模型的优势场景为,需要查询的数据较多,且不需要进行太多的聚合操作的时候非常适用。
表内部会提前根据排序键对数据生成排序索引,顾名思义,它适合于明细数据查询,但是它对于行级更新的支持不是很友好,它仅适合于这些数据导入后不会再做变更的场景。
CREATE TABLE IF NOT EXISTS ads_osa_mds_salesman_return_cost_base (
add_date date comment '加粉日期',
fans_id bigint comment '粉丝id',
paydate date comment '支付日期',
brand_name string comment '营销单元',
brand_id string comment '营销ID',
region string comment '地区',
region_id string comment '地区ID',
large_group string comment '大组',
large_group_id string comment '大组ID',
small_group string comment '小组',
small_group_id string comment '小组ID',
org_chain string comment '组织链路ID',
flower_name string comment '花名',
wx_number string comment '微信号',
wx_account string comment '手机号',
fans_wx_id string comment '粉丝微营销微信号ID',
during_id bigint comment '',
member_id bigint comment '会员ID',
order_no string comment '平台订单号',
pay_time string comment '支付时间',
payamount decimal(38,18) comment '实付金额',
feeamount decimal(38,18) comment '推广消耗金额',
diffdays bigint comment '支付时间与加粉时间间隔天数',
week_first_day date comment '本周第一天_周一',
week_last_day date comment '本周最后一天_周日'
)
DUPLICATE KEY(add_date,fans_id,paydate) --排序键: 将这些字段进行组合排序,适合于常用于where的字段
DISTRIBUTED BY HASH(brand_name) BUCKETS 3 –-分桶键,适合便于区分整表数据的字段,均匀分为三份
PROPERTIES ( 注:目前数据量较小,统一为最小值3
"replication_num" = "2" --副本数,不可超过BE的数量,默认为3,现因节点不够,所以固定为2.
);
聚合模型:
聚合模型的优势场景为,需要查询的场景需要更多的聚合操作,且不需要进行明细查询的时候使用。
在聚合模型内,所有的数据会根据聚合维度和聚合值来区分,它会将聚合值以所有的维度数量的二次方去生成预聚合数据,全部维度的组合都会生成一遍。(类似于grouping sets)
CREATE TABLE IF NOT EXISTS ads_label_center_customer_day (
customer_id string comment '客户ID'
,fans_id string comment '粉丝ID'
,member_id string comment '会员id'
,customer_type string comment '1:会员;2:粉丝+会员;3:粉丝'
,day_tot DATE comment '日期YYYY-mm-dd'
,is_buy string comment '当日是否消费'
,uin string COMMENT '微信多开uin 唯一 '
,wx_id string COMMENT '微信id'
,brand_id string COMMENT '品牌ID'
,brand_name string COMMENT '品牌名称'
,td_ledger_amt decimal(20,5) SUM DEFAULT "0" comment '当日消费金额(流水)'
,td_accounts_receivable_amt decimal(20,5) SUM DEFAULT "0" comment '当日消费金额(应收)'
,td_actual_receipts_amt decimal(20,5) SUM DEFAULT "0" comment '当日消费金额(实收)'
,td_avg_price decimal(20,5) SUM DEFAULT "0" comment '当日消费平均价'
,td_buy_cnt int SUM DEFAULT "0" comment '当日购买次数'
,td_clothing_cnt int SUM DEFAULT "0" comment '当日购买私服次数'
,td_other_cnt int SUM DEFAULT "0" comment '当日购买好物次数'
)
AGGREGATE KEY(customer_id,fans_id,member_id,customer_type,day_tot,is_buy,uin,wx_id,brand_id,brand_name)
DISTRIBUTED BY HASH(customer_id) BUCKETS 3
PROPERTIES (
"replication_num" = "2"
);
更新模型:弃用
主键模型:
主键模型的优势场景为,支持实时和频繁更新等场景,相对于更新模型,主键模型在查询时不需要执行聚合操作,提供高效查询。
主键模型采用了 Delete+Insert 的策略,使设置的主键一直保持唯一性,避免Merge 以实现sql优化引擎的谓词下推,保证了查询性能的高效。
CREATE TABLE `label_center_basic_tag_category` (
`id` string NOT NULL COMMENT '主键ID',
`name` string NOT NULL COMMENT '标签分类名称',
`create_time` datetime NOT NULL COMMENT '创建时间',
`update_time` datetime NOT NULL COMMENT '更新时间',
`brand_id` bigint COMMENT '品牌id',
`sort_order` int NOT NULL COMMENT '排序',
`is_del` tinyint(1) NOT NULL COMMENT '是否删除 0:否 1:是'
) PRIMARY KEY (id)
COMMENT "基础标签类别表"
DISTRIBUTED BY HASH(id) BUCKETS 3
PROPERTIES (
"replication_num" = "2",
"enable_persistent_index" = "true"
);
备注:分区在非特殊情况下禁用
因为现在的场景数据量较少,分桶完全可以适用于大部分场景,所以表分区在非特殊情况下禁用,未宣讲。
有兴趣的话可以自行去官网查看。
新增字段:
ALTER TABLE [database.]table
ADD COLUMN column_name column_type [KEY | agg_type] [DEFAULT "default_value"]
[AFTER column_name|FIRST]
[TO rollup_index_name]
[PROPERTIES ("key"="value", ...)]
聚合模型如果增加 value 列,需要指定 agg_type。
非聚合模型如果增加 key 列,需要指定 KEY 关键字。
普通字段添加示例:
ALTER TABLE orders ADD COLUMN (column_name int COMMENT "新增字段注释" )
物化视图:(生产若非必要,禁止随便建立)
因物化视图建立后会持续检查表内数据更新,然后预排序或预计算后加载到内存中。目前集群资源较为有限,过多的物化视图可能会导致集群内存占用过多,影响生产任务。
创建物化视图:
同步物化视图:单表
排序型物化视图:
ALTER TABLE table_name ADD ROLLUP view_1(add_date,fans_id,paydate) ;
聚合型物化视图:(不可带where语句,将where字段加入group by中即可)
原始查询聚合函数 | 物化视图构建聚合函数 |
|---|---|
sum | sum |
min | min |
max | max |
count | count |
bitmap_union, bitmap_union_count, count(distinct) | bitmap_union |
hll_raw_agg, hll_union_agg, ndv, approx_count_distinct | hll_union |
CREATE MATERIALIZED VIEW view_2 AS
select
fans_id,add_date,
sum(payamount)
from ads_osa_mds_salesman_return_cost_base
group by fans_id,add_date
异步物化视图:多表 (业务场景不满足,暂时禁用)
查看物化视图:
DESC table_name ALL
查看物化视图是否生效:
explain
select count(1) from table_name