一、什么是数据分析:
数据分析是指对数据进行收集、处理、转换和挖掘,以发现数据中的规律、趋势和关联性,为决策提供支持和指导的过程。数据分析涵盖了数据预处理、数据建模、数据可视化、数据挖掘等多个方面的技术和方法。
二、pandas的初步使用:
2.1 安装模块
# 安装第三方库
pip install pandas
# 在读写Excel文件中还需要安装额外pandas依赖库xlrd、xlwt
pip install xlrd
pip install xlwt
2.2 初步使用
import pandas as pd
theater = pd.read_csv(r'D:\学习资料\数据分析学习\课程3.0补丁【先学2.0再学3.0】\4.2 SQL基础语句运行原理\城市信息.csv')
print(theater)
三、Series对象
- Pandas库中的一种数据结构,类似于一维数组
- 由一组数据以及与这组数据有关的标签(索引) 组成
- Series对象可以存储整数、浮点数、字符串、Python对象等多种数据类型的数据
3.1 如何创建Series对象
import pandas as pd
data = ['岳云鹏', '展光华', '中泰上例']
index = [1, 2, 3]
# 创建Series对象,data为数据,index为索引,若传了index则为手动创建索引,若无index传入,则index默认从0开始
s = pd.Series(data=data,index=index)
print(s)
print(type(s)) '<class 'pandas.core.series.Series'>'
3.2 Series的索引
-
位置索引
import pandas as pd
data = ['岳云鹏', '展光华', '中泰上例']
s = pd.Series(data=data)
按索引位置取值
print(s[0]) #输出:岳云鹏
print(s[1]) #输出:展光华
print(s[2]) #输出:中泰上例
-
标签索引
import pandas as pd
index = ['岳云鹏', '展光华', '中泰上例']
data = [88, 89, 90]
s = pd.Series(data=data, index=index)
print(s['岳云鹏']) # 输出:88
print(s['展光华']) # 输出:89
print(s['中泰上例']) # 输出:90
# 可以一次性取出多个
print(s[['岳云鹏', '展光华']])
-
切片索引
import pandas as pd
# 如果是按照位置索引进行切片,顾头不顾尾
data = ['岳云鹏', '展光华', '中泰上例']
s = pd.Series(data=data)
print(s[0:2])
'''
0 岳云鹏
1 展光华
'''
# 如果按照标签索引进行切片,顾头也顾尾
index = ['岳云鹏', '展光华', '中泰上例']
data = [88, 89, 90]
s = pd.Series(data=data, index=index)
print(s['岳云鹏':'中泰上例'])
'''
岳云鹏 88
展光华 89
中泰上例 90
'''
-
获取Series的索引和值
import pandas as pd
index=[1,2,3]
data = ['岳云鹏', '展光华', '中泰上例']
s = pd.Series(data=data,index=index)
print(s.index) #获取索引
print(s.values) #获取值
四、DataFrame对象
- DataFrame对象是Pandas库中的一种数据结构,类似于二维表由行和列组成
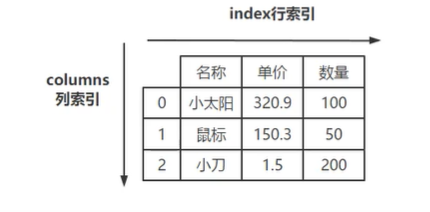
- 与Series一样支持多种数据类型
4.1 创建DataFrame对象
4.1.1 列表方式创建DataFrame对象
import pandas as pd
data = [['小太阳', 320.9, 100], ['鼠标', 150.3, 50], ['小刀', 1.5, 200]]
columns = ['名称', '价格', '数量']
f = pd.DataFrame(data=data, columns=columns)
print(f)
4.1.2 字典方式创建DataFrame对象
import pandas as pd
data = {
'名称': ['小太阳', '鼠标', '小刀'],
'价格': [320.9, 150.3, 1.5],
'数量': [100, 50, 200]
}
f = pd.DataFrame(data=data)
print(f)
4.2 DataFrame对象的重要属性
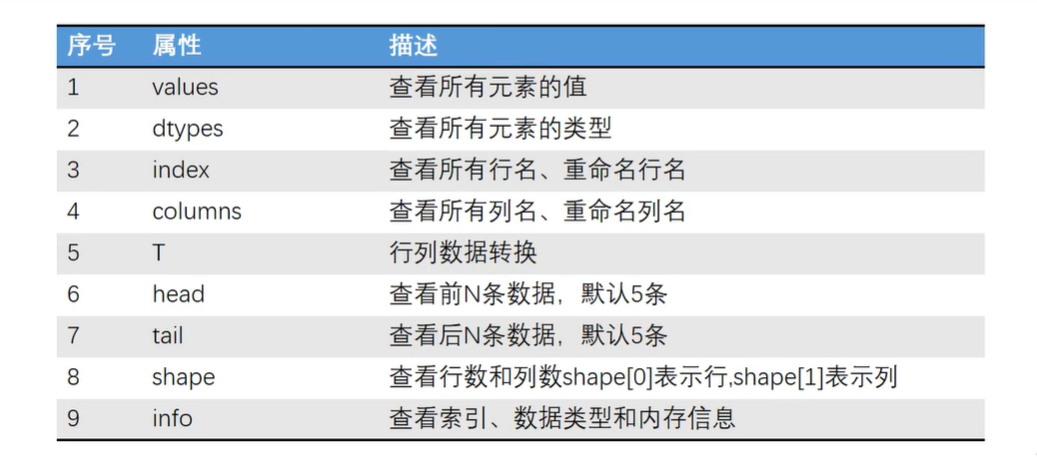
4.3 DataFrame对象的重要函数
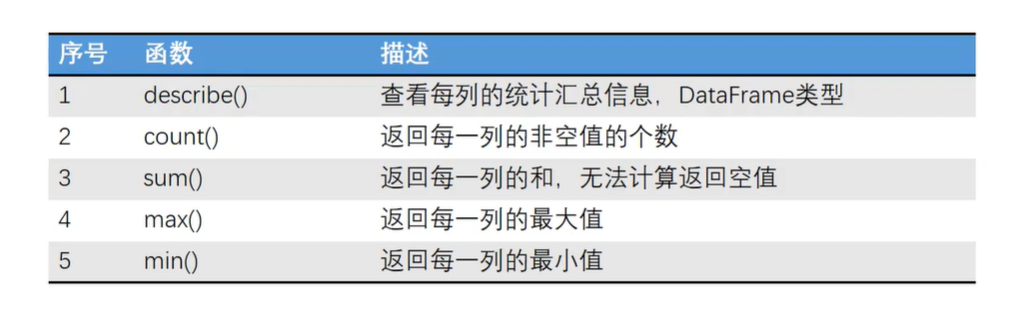
五、导入外部数据
5.1导入.xls或.xlsx文件:pd.read_excel(io,sheet_name,header)
常用参数说明:
io:表示.xls或.xlsx文件路径或类文件对象
sheet_name:表示工作表
usecols:指定读取的列
header:默认值为0,取第一行的值为列名,数据为除列名以外的数据,如果数据不包含列名,则设置header=None

import pandas as pd
pd.set_option('display.unicode.east_asian_width', True) # 使列名对齐
f = pd.read_excel(io=r'D:\学习资料\数据分析学习\课程3.0补丁【先学2.0再学3.0】\3.2-BI工具可视化原理\3.2-8月成交数据.xlsx',usecols=[2, 3]) #指定第2,3列
print(f)
5.2 导入.csv文件:pd.read_csv(filepath_or_buffer,sep=',',header,encoding=None)
常用参数说明:
filepath_or_buffer:字符串,文件路径或url链接
sep:字符串、分隔符
header:默认值为0,取第一行的值为列名,数据为除列名以外的数据,如果数据不包含列名,则设置header=None
encoding:字符串,默认为None,文件的编码格式
5.3 导入.txt文件:pd.read_csv(filepath_or_buffer,sep='\t',header,encoding=None)
5.4 导入HTML网页:pd.read_html(io,match,flavor,header,encoding)
常用参数说明:
io:字符串、文件路径,了可以是URL链接,网址不接受https
match:正则表达式
flavor:解释器默认为lxml
header:指定列标题所在的行
encoding:文件的编码格式
import pandas as pd
url = 'http://www.espn.com/nba/salaries'
f=pd.DataFrame()
f =pd.read_html(url)[0]
f.to_csv('nba.csv',index=False)
六、数据抽取
DataFrame对象的loc属性与iloc属性iloc属性
loc属性:以列名 (columns) 和行名(index)作为参数,当只有一个参数时,默认是行名,即抽取整行数据,包括所有列。
iloc属性:以行和列位置索引 (即:0,1,2...) 作为参数,0表示第一行,1表示第2行,以此类推。当只有一个参数时,默认是行索引,即抽取整行数据,包括所有列。
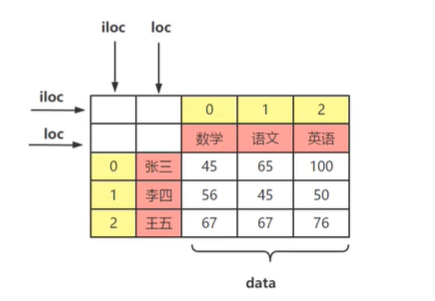
6.1 创建DataFrame对象
import pandas as pd
data = [[45, 65, 100], [56, 45, 50], [67, 67, 76]]
index = ['张三', '李四', '王五'] # 行索引
columns = ['数学', '语文', '英语'] # 列索引
pd.set_option('display.unicode.east_asian_width', True)
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
6.2 提取行数据
print(df.loc['张三']) # 使用行索引名称提取
print(df.iloc[0]) # 使用行索引编号提取
print(df.loc[['张三', '王五']]) # 提取多行数据
print(df.iloc[[0, 2]]) # 提取多行数据
print(df.loc['张三':'王五']) # 切片提取多行数据,使用行索引名称顾头也顾尾
print(df.iloc[0:3]) # 使用行索引编号切片,顾头不顾尾
6.3 提取列数据
print(df[['数学','语文']]) #直接使用列名提取
# 提取所有行和英语,语文列
print(df.loc[:, ['英语', '语文']]) #逗号左侧表示行,右侧表示列
print(df.iloc[:,[1,2]])
print(df.loc[:, '数学':]) # 提取连续的列
print(df.iloc[:, 0:])
6.4 提取区域部分
# 提取张三的数学成绩
print(df.loc['张三', '数学'])
print(df.iloc[0, 0])
# 提取张三和王五的数学,语文成绩
print(df.loc[['张三', '王五'], ['数学', '语文']])
print(df.iloc[[0, 2], [0, 1]])
6.5 提取指定条件的数据
# 提取语文成绩大于60的
print(df.loc[df['语文'] > 60])
# 提取语文和数学成绩都大于60的
print(df.loc[(df['语文'] > 60) & (df['数学'] > 60)])