前言
Redis作为目前使用最广泛的缓存,相信大家都不陌生。但是使用缓存并没有这么简单,还要考虑缓存雪崩,缓存击穿,缓存穿透的问题,什么是缓存雪崩,击穿,穿透呢,又怎么解决这些问题呢。
缓存雪崩
什么是缓存雪崩?
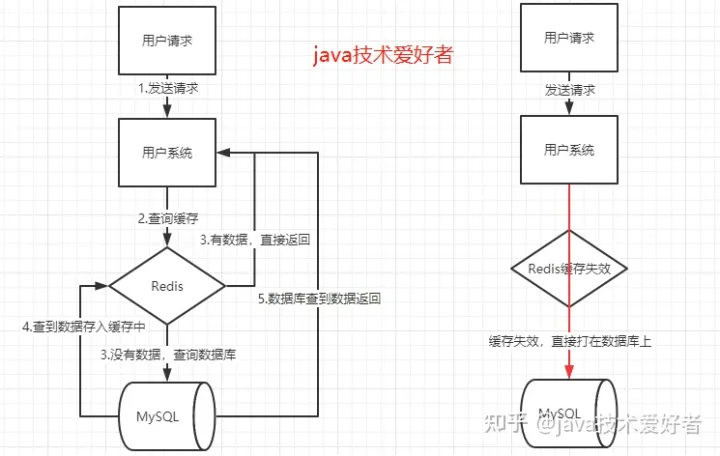
当某一个时刻出现大规模的缓存失效的情况,那么就会导致大量的请求直接打在数据库上面,导致数据库压力巨大,如果在高并发的情况下,可能瞬间就会导致数据库宕机。这时候如果运维马上又重启数据库,马上又会有新的流量把数据库打死。这就是缓存雪崩。
分析
造成缓存雪崩的关键在于在同一时间大规模的key失效。为什么会出现这个问题呢,有几种可能,第一种可能是Redis宕机,第二种可能是采用了相同的过期时间。搞清楚原因之后,那么有什么解决方案呢?
解决方案
起因:redis挂了或者大量热点数据同时过期,导致大量请求 打到数据库引发系统奔溃。
1、在原有的失效时间上加上一个随机值,比如1-5分钟随机。这样就避免了因为采用相同的过期时间导致的缓存雪崩。
2、为了防止Redis宕机导致缓存雪崩的问题,采取redis高可用,可以搭建Redis集群,提高Redis的容灾性。
3、使用熔断机制。当流量到达一定的阈值时,就直接返回“系统拥挤”之类的提示,防止过多的请求打在数据库上。至少能保证一部分用户是可以正常使用,其他用户多刷新几次也能得到结果。
4、提高数据库的容灾能力,可以使用分库分表,读写分离的策略。
5、开启redis持久化机制aof/rdb,尽快恢复缓存集群。
如果是热点数据过期可参考缓存击穿解决方案。
缓存击穿
什么是缓存击穿?
其实跟缓存雪崩有点类似,缓存雪崩是大规模的key失效,而缓存击穿是一个热点的Key,有大并发集中对其进行访问,突然间这个Key失效了,导致大并发全部打在数据库上,导致数据库压力剧增。这种现象就叫做缓存击穿。
分析
关键在于某个热点的key失效了,导致大并发集中打在数据库上。所以要从两个方面解决,第一是否可以考虑热点key不设置过期时间,第二是否可以考虑降低打在数据库上的请求数量。
解决方案
1、上面说过了,如果业务允许的话,对于热点的key可以设置永不过期的key。
2、使用互斥锁。如果缓存失效的情况,只有拿到锁才可以查询数据库,降低了在同一时刻打在数据库上的请求,防止数据库打死。当然这样会导致系统的性能变差。
代码示例
缓存击穿是原来有缓存,由于缓存失效,造成缓存被击穿了,然后大量请求涌入到数据库,造成系统卡死。
解决方法是热点key不设置失效时间,或者加锁。下面看加锁方案
private final static String GET_BY_ID_LOCK = "GET_BY_ID_LOCK";
@GetMapping("getById")
@ApiOperation(value = "根据id获取用户")
public Result<User> getById(int id) {
String key = USER_KEY + id;
//先从缓存中取
User user = (User) redisTemplate.opsForValue().get(key);
if (user == null) {
//此时有1W个请求到这,不加锁的话1W个请求会直接打到数据库
synchronized (GET_BY_ID_LOCK) {
//高并发下需要双重检查,如果还是空说明真的没有缓存
user = (User) redisTemplate.opsForValue().get(key);
if (user == null) {
//user不存在则从数据库取出并放入缓存,并且设置过期时间
user = userService.getById(id);
redisTemplate.opsForValue().set(key, user, Duration.ofHours(6));
}
}
}
return resultOk(user);
}
缓存穿透
什么是缓存穿透?
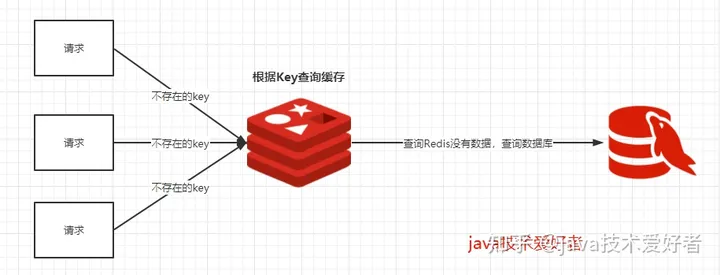
我们使用Redis大部分情况都是通过Key查询对应的值,假如发送的请求传进来的key是不存在Redis中的,那么就查不到缓存,查不到缓存就会去数据库查询。假如有大量这样的请求,这些请求像“穿透”了缓存一样直接打在数据库上,这种现象就叫做缓存穿透。
分析
关键在于在Redis查不到key值,这和缓存击穿有根本的区别,区别在于缓存穿透的情况是传进来的key在Redis中是不存在的。假如有黑客传进大量的不存在的key,那么大量的请求打在数据库上是很致命的问题,所以在日常开发中要对参数做好校验,一些非法的参数,不可能存在的key就直接返回错误提示,要对调用方保持这种“不信任”的心态。
解决方案
起因:缓存穿透指缓存和数据库都没有数据,请求直接穿透了。
1、把空对象进行缓存。如果Redis查不到数据,数据库也查不到,我们把这个Key值保存进Redis,设置value="null",当下次再通过这个Key查询时就不需要再查询数据库。这种处理方式肯定是有问题的,假如传进来的这个不存在的Key值每次都是随机的,那存进Redis也没有意义。
2、使用布隆过滤器。布隆过滤器的作用是某个 key 不存在,那么就一定不存在,它说某个 key 存在,那么很大可能是存在(存在一定的误判率)。于是我们可以在缓存之前再加一层布隆过滤器,在查询的时候先去布隆过滤器查询 key 是否存在,如果不存在就直接返回。
使用布隆过滤器解决缓存穿透
布隆过滤器有点像hashmap,由一个大数组和多个hash函数构成,它会把hash值取模后的位置置为1,由于hash冲突,如果他判断元素不存在则一定不存在,如果他判断元素存在则元素有可能存在,会有一定的误判。
布隆过滤器就是用来快速判断某个数据是否存在的
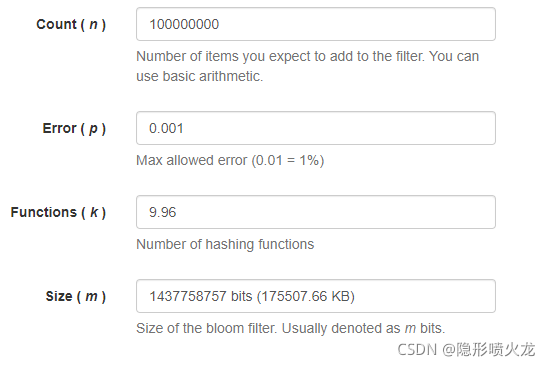
首先创建一个过滤器,预估数据量和可接受的错误率,然后把所有id放进去,后面新增数据的时候也需要放入id,https://krisives.github.io/bloom-calculato,这个网站可以看指定数据量和错误率的情况下所需要的空间。
@GetMapping("init")
@ApiOperation(value = "初始化")
public Result init() {
RBloomFilter bloomFilter = redissonClient.getBloomFilter("userIdFilter");
//预估数据量和可接受的错误率
bloomFilter.tryInit(1000000, 0.001);
List<User> users = userService.list();
for (User user : users) {
//放入布隆过滤器
bloomFilter.add(user.getId());
}
return resultOk();
}
接下去请求的时候判断id存不存在,不存在直接返回,解决了缓存穿透问题
@GetMapping("getById")
@ApiOperation(value = "根据id获取用户")
public Result<User> getById(int id) {
RBloomFilter bloomFilter = redissonClient.getBloomFilter("userIdFilter");
//判断该id是否存在
if (!bloomFilter.contains(id)) {
//布隆过滤器特点,判断结果为不存在的时候则一定不存在,可放心返回
return resultOk();
}
//存在的情况布隆过滤器有一定误判可能,
// 但没关系,错误率为0.001的情况下1W个请求只会有10个打到数据库,可以接受
String key = USER_KEY + id;
//先从缓存中取
User user = (User) redisTemplate.opsForValue().get(key);
if (user == null) {
//user不存在则从数据库取出并放入缓存,并且设置过期时间
user = userService.getById(id);
redisTemplate.opsForValue().set(key, user, Duration.ofHours(6));
}
return resultOk(user);
}
总结
这三个问题在使用Redis的时候是肯定会遇到的,而且是非常致命性的问题,所以在日常开发中一定要注意,每次使用Redis时,都要对其保持严谨的态度。还有一个需要注意的是要做好熔断,一旦出现缓存雪崩,击穿,穿透这种情况,至少还有熔断机制保护数据库不会被打死。