1. 实验
1.1 背景介绍
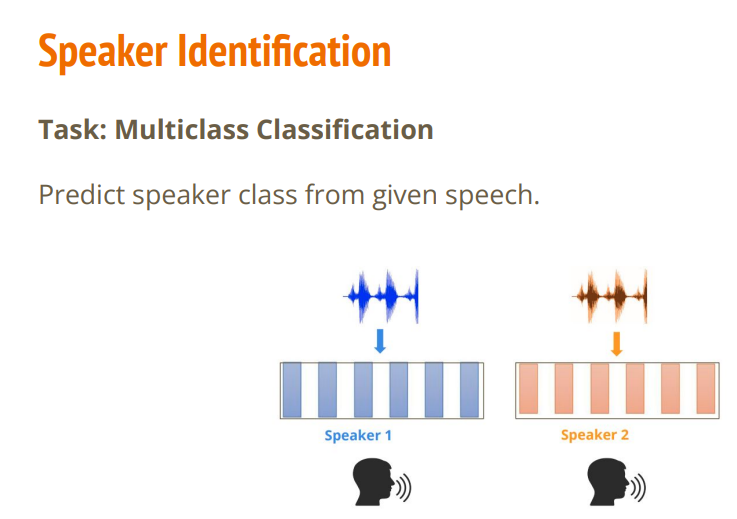
根据输入音频判断是哪个讲话者.
1.2 数据集
数据集采用的是\(VoxCeleb2\).

1.2.1 Data formats
目录下有三个json文件和很多pt文件,三个json文件作用标注在下图中,pt文件就是语音内容.

1.3 Model Architecture
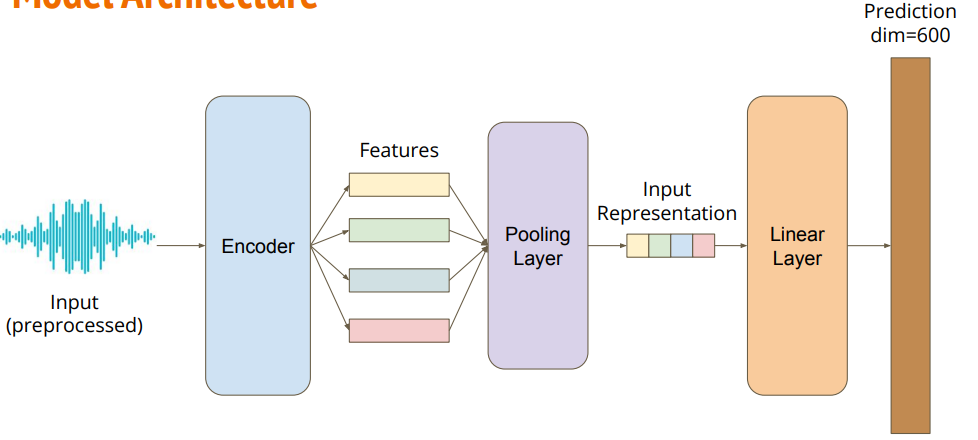
模型结构如下图所示,输入最后变成一个600维的向量.
1.3 Hint
对于如何达到4条基本线,助教已经给予了提示.

1.3.1 Requirements - Simple
对于\(Simple\)线,直接输入助教代码即可.

1.3.2 Requirements - Medium
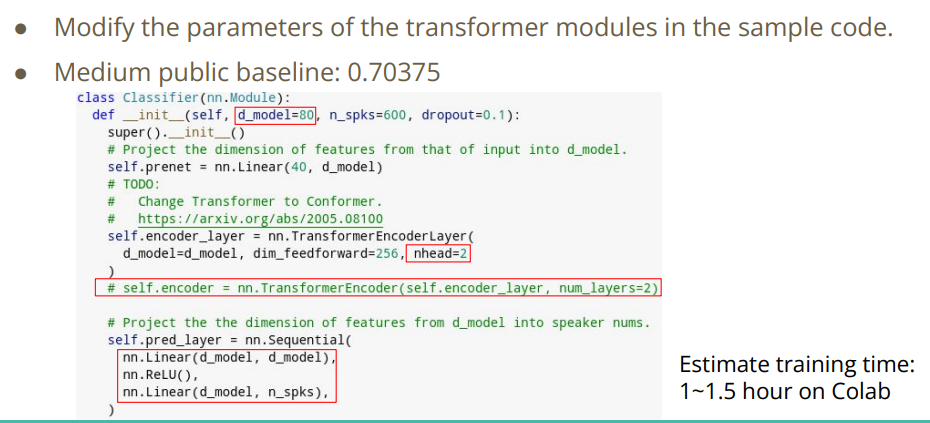
当要达到Medium线时,需要调参.
1.3.3 Requirements - Strong
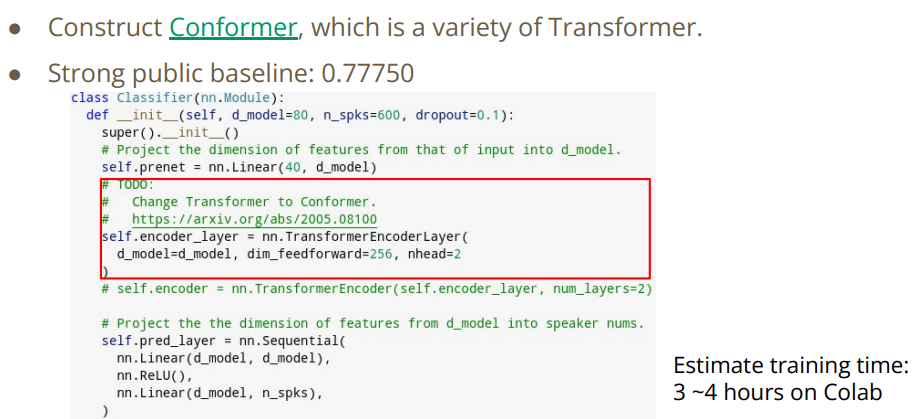
改变模型结构,将Medium转为Strong.
1.3.4 Requirements - Boss

1.4 Submission Format
提交的文件格式如下.
